-
【腾讯云原生降本增效大讲堂】Kubernetes资源拓扑感知调度

嘉宾 | 方睿
出品 | CSDN云原生
在云原生场景下,为了使CPU利用率更高,以及各容器之间不会由于激烈竞争而引起性能下降,容器的资源分配需要更精细化。
2022年8月11日,中国信通院、腾讯云、FinOps产业标准工作组联合发起的《原动力x云原生正发声 降本增效大讲堂》系列直播活动第6讲上,腾讯星辰算力平台高级工程师方睿分享了Kubernetes资源拓扑感知调度。

资源竞争与资源感知问题
从CPU的体系结构上来看,现代CPU多采用NUMA架构和方式。
NUMA架构是非对称的,每个NUMA node上会有自己的物理CPU内核,以及每个NUMA node之间也共享L3 Cache。同时,内存也分布在每个NUMA node上的。某些开启了超线程的CPU,一个物理CPU内核在操作系统上会呈现两个逻辑的核。
实际上,CPU内核是分布在NUMA node上,NUMA node内本身就有一些亲和性的元素。
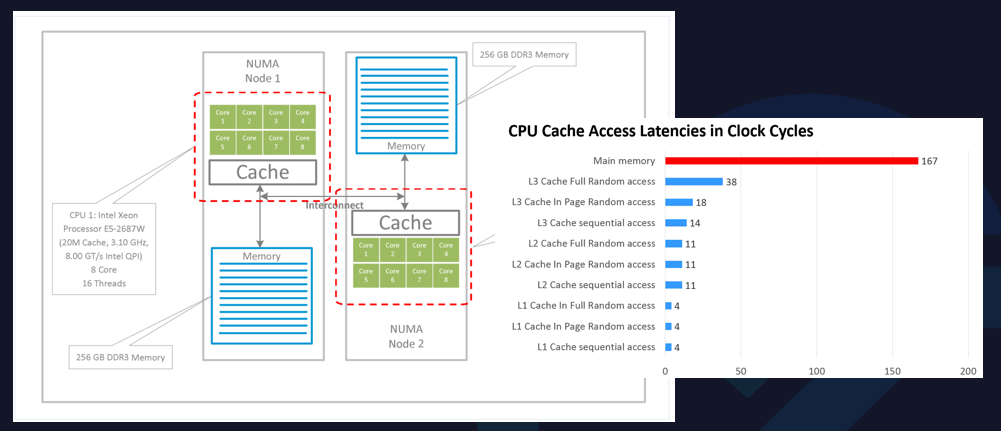
右图中,CPU开始的访问速度是不一样的。
如果程序都跑在同一个NUMA node上,可以更好地去共享一些L3 Cache,L3 Cache的访问速度会很快。如果L3 Cache没有命中,可以到内存中读取数据,访存速度会大大降低。
因此,从CPU体系结构中可以看到,如果采用一些错误的CPU分配方式,可能会导致进程访存速度急剧下降,严重影响应用程序的性能。
在这样的体系结构下,存在云计算中常见的吵闹的邻居问题。当多个容器在节点上共同运行时,由于资源分配的不合理,会对CPU本身的性能造成影响。

从理想的使用方式来看,如果每个进程都使用各自的CPU内核,并且不会跨NUMA node访问,相互之间不会有太多争抢。
从糟糕的使用方式来看,如果两个进程的CPU内核在分配时,可能会没有遵循NUMA的亲和性,会带来很大的性
-
相关阅读:
牛客月赛c(简单推理,以及对set的灵活运用)
MyCat 管理及监控
拉美巴西阿根廷媒体宣发稿墨西哥哥伦比亚新闻营销如何助推跨境出海推广?
基于SSM+Vue的医院住院综合服务管理系统的设计与实现
Asp .Net Core 系列:Asp .Net Core 集成 NLog
C/C++输入输出流函数大全
记录vite下使用require报错和解决办法
走进人工智能|自动驾驶 开启智能出行新时代
【CSDN话题挑战赛第2期】web组态可视化领域分享
数学建模学习(92):Jaya 算法对定位问题进行寻优
- 原文地址:https://blog.csdn.net/m0_46700908/article/details/126518766