-
[TOG2022]DCT-Net: Domain-Calibrated Translation for Portrait Stylization
标题:DCT-Net: Domain-Calibrated Translation for Portrait Stylization
链接:https://arxiv.org/pdf/2207.02426
本文做的是基于人脸的风格迁移,效果非常惊艳。特点就是在迁移了局部纹理和整体颜色的基础上,进一步融入了对应风格的细节表达。模型最有意思的点就是域之间的对齐,这为少样本的图像迁移提供了一个思路。
模型构建

在文章中,作者想要完成的风格迁移,并不是像adain那些对细节纹理和整体颜色进行拟合,而是要真正的进行语义层面上的迁移。因此比起风格迁移,这其实更像图像翻译的任务,即将图像从一个域迁移到另一个域。在图像翻译的任务中通常我们都需要成对的图像来训练,虽然后来有人提出了cycle-consistency从而允许了从不成对的两个域间学到对应性,但是这通常需要足够大的样本量。而且cycle-consistency构建的对应性是比较弱的,很容易在结果中出现无法预料的错误细节。
而这里作者提出了一个新的两阶段方案,即先扩充数据库,再学习域迁移。其中扩充数据库所用到的方法就是上图中的内容对齐网络(content calibration network,CCN)。
内容对齐网络
从图中可以看出CCN中有两个生成器,
 和
和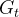 。其中 就是预训练过的stylegan2,不参与训练,就是负责不断地根据随机变量z输出真实的图像。而则是在的基础上使用目标域(风格)的图像进行进一步的finetune,目标是使其可以输出足够真实的漫画脸。
。其中 就是预训练过的stylegan2,不参与训练,就是负责不断地根据随机变量z输出真实的图像。而则是在的基础上使用目标域(风格)的图像进行进一步的finetune,目标是使其可以输出足够真实的漫画脸。在finetune时作者使用了两个约束,一个是gan loss,就是将目标域图像与
的输出丢到判别器里做真假损失。还有一个是身份损失,就是将和的输出丢到人脸检测器里,保证人脸的身份一致(因为这里和输入的随机量z是相同的)。这里之所以要用身份损失是因为目标域的图像太少了(作者文中只用了100个),因此借助身份损失可以在一定程度上增加约束,避免模式崩塌。按照上述方法训练完后
就可以输出足够真实的漫画脸了,进而我们可以使用 和 输出无限多的原域和目标域的图像,进行域迁移学习。不过在此之前,由于stylegan2是在FFHQ上训练的,面部角度非常有限,因此作者添加了一个随机旋转和缩放的扰动,称之为geometry expansion,用以提升模型对于不同角度人脸的鲁棒性。
纹理迁移网络
在我们已经有了足够多的原域和目标域的图像的情况下,最后要做的事情就很简单了,即按照风格迁移的模式分别对风格和内容进行约束。往常的风格迁移模型中使用的style loss都是对VGG抽取的特征进行统计值层面的拟合,但这无法达到语义级的风格迁移效果。而这里作者使用了gan loss作为style loss。众所周知,gan的特色就是擅长域拟合,但问题就是通常都需要很多数据,而由于我们使用CCN构造了无限的数据,因此这一点再也不是问题。
另外作者使用了基于vgg的content loss来保证语义对齐。之后还加了一个facial perception loss,目的是通过眼睛和嘴巴的特征点来约束结果图中眼睛和嘴巴的效果,这个就完全属于提升效果的小trick了,没有什么实际意义。
-
相关阅读:
我的编程之路
Docker安装Oracle及Win10安装PLSQL远程
“看看人家苹果和亚马逊”,嫌薪酬太低,谷歌员工“炮轰”高管
2000-2020上市公司全要素生产率OLS和固定效应方法含原始数据和Stata代码
宏观上理解blazor中的表单验证
Python基本语法_集合setfrozenset_内建方法详解
face_alignment.FaceAlignment AttributeError: _2D
一元函数极值问题
1.Vue简介
C++ Lambda表达式
- 原文地址:https://blog.csdn.net/wrk226/article/details/126517524