-
搜索功能实现遇到的那些坑
大家好,我是前端西瓜哥,今天我们来聊聊搜索的一些坑。
搜索是一个比较常见的业务需求,但里面有些容易踩坑的地方,我们今天来聊一聊。
我们先用 React 实现一个简单的搜索 Demo。
当我们在 input 输入内容时,就会通过 onChange 事件触发请求,将返回结果保存到 resulte 变量并输出到页面上。
// 模拟网络请求 const getSearchResult = (keyword) => { // 假设网络良好,稳定 150ms const wait = 150; return new Promise((resolve) => { setTimeout(() => { resolve(keyword); }, wait); }); }; function App() { const [result, setResult] = useState(''); const searchKeyword = (e) => { // 发送搜索请求 const keyword = e.target.value; getSearchResult(keyword).then((res) => { setResult(res); }); }; return (); }搜索结果:{result}- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
上面的实现有个问题:如果用户连续输入内容,会导致在短时间内发送大量请求给后端,对服务端造成不小压力。
这里其实很多请求都是没用的,只有最后一个才是有用的。
我们可以做一下优化。
防抖
首先我们要对请求做 防抖,就是要用户在停止输入后再等待特定的时间,才发送请求。如果在这段时间内用户再次输入了内容,则重新开始等待。
假设我们 1s 中执行了 6 次函数,它本来应该是下面这样子的:
12 3 456 ----------------------- 1
- 2
添加防抖能力后,我们让函数某次执行后特定的时间没有新的触发,才真正去执行,结果是我们只执行了 2 次:
// 防抖后 3 6 ----------------------- 1
- 2
- 3
使用防抖后,我们就可以让用户疯狂输入过程中的请求不能真正发起,当用户停止输入后才真正发送请求,从而降低服务端压力。
我们对发送请求的 searchKeyword 函数做一个防抖。
import { useDebounceFn } from 'ahooks'; const { run: searchKeyword } = useDebounceFn( (e) => { // 发送搜索请求 const keyword = e.target.value; getSearchResult(keyword).then((res) => { setResult(res); }); }, { wait: 200 } );- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
这里用了 ahooks 的 useDebounceFn 对函数做了防抖,设置等待时间为 200 ms。
useDebounceFn 底层用了 lodash.debouce,并配合 useRef 确保返回的函数引用不变。
你可能奇怪为什么不直接用 debouce,其实这是有原因的。
因为 React 的函数组件 发生状态更新会重新执行函数组件,如果直接用 debounce 方法,每次其实都是生成了一个全新的加了防抖特性的新函数,导致前后多个 onChange 事件触发的是多个独立的函数,最终结果是发送请求数量和触发事件树相同。
我们看下加了防抖的效果,可以看到中间一些像是 1234 的请求被丢弃掉了,确实减少了不要的网络请求。
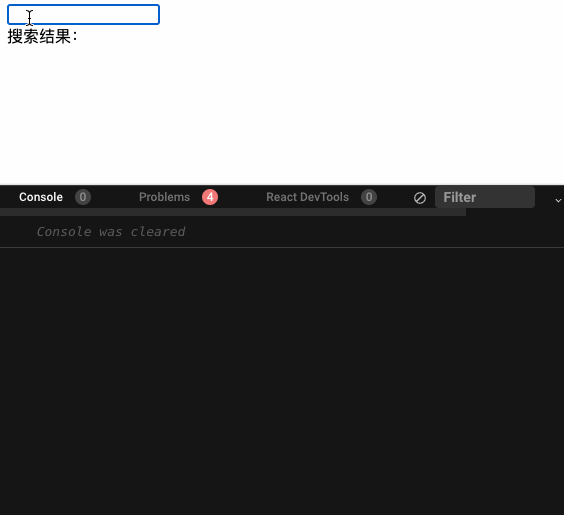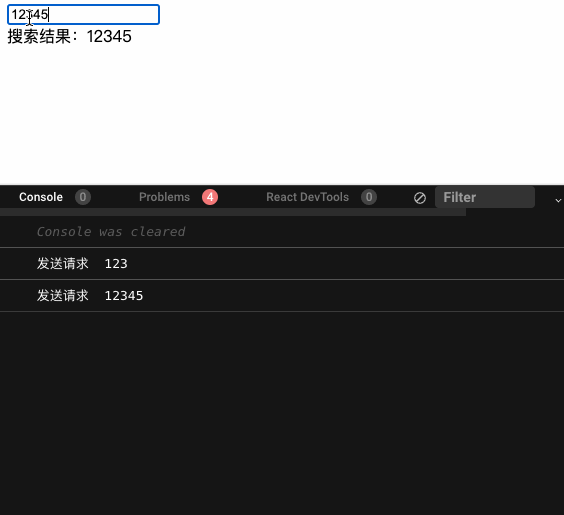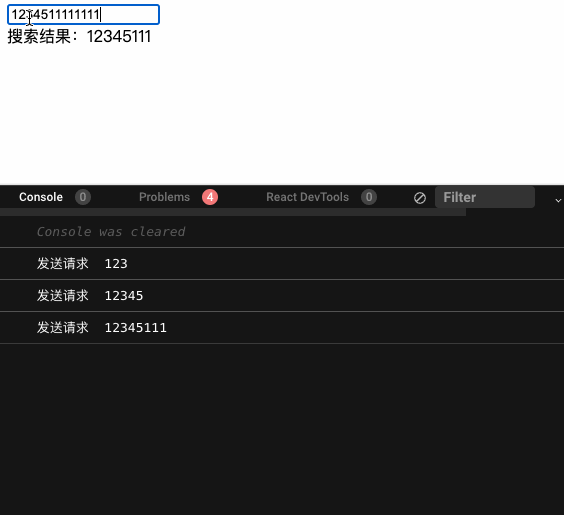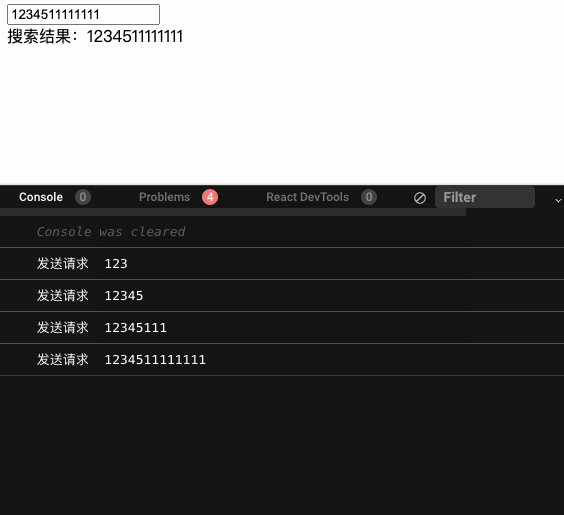
debouce-search
有人说能不能用节流。不推荐,因为用节流的话,用户在持续输入的过程中,还是发送了一些无意义的请求,只是频率比直接请求低了一些罢了。
如果你是使用关键词联想推荐,则可以使用节流。这种方案发起请求其实是在用户回车或点击 “搜索” 按钮触发了,和本文讨论的场景不同。
上一个请求结果覆盖下一个的问题
看起来貌似没啥问题了,但其实我们还忽略了一个问题,就是当网络不稳定的场景。
假设内容为 1 时发送了一个请求 A,然后内容变成 12 又发送了一个请求 B,然后停止输入。
因为网络不稳定,请求 B 先返回了,页面显出出了 12 对应的结果,这没问题。但过了一会,1 的结果接着返回了结果。
此时,你就会看到,明明搜索栏输入的是 12,返回的却是 1 的结果。
为此,我们需要 丢弃最后一个请求之前的所有请求。
我们可以用闭包的方式维护一个请求对应的 currReqId ,并维护一个全局变量 lastReqId 记录最后请求的 id。
当返回请求结果时,如果 currReqId 和 lastReqId 相同才继续执行接下来的逻辑;如果不等,就丢弃。
// 最后请求 id const lastReqId = useRef({}); const { run: searchKeyword } = useDebounceFn( (e) => { const currReqId = {}; lastReqId.current = currReqId; // 发送搜索请求 const keyword = e.target.value; getSearchResult(keyword).then((res) => { // “当前请求 id” 和 “最后一次请求的 id” 相同时才继续接下里的逻辑 if (lastReqId.current === currReqId) { console.log('发送返回结果', res); setResult(res); } }); }, { wait: 200 } );- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
这里我用空对象来作为请求的 id,是因为每次声明
{}都指向一个新的内存地址,可以确保每个请求 id 都不相等。你也可以用一个自增数字来做 id,只要确保唯一即可。还有一种方式就是使用中止 Web 请求的 API:AbortController。它能真正地中止 HTTP 请求,相比 id 对比的方式,能真正地减少网络消耗。
id 对比的方式请求还是在持续的,只是返回的请求不使用而已。
但考虑到浏览器兼容性,不要太依赖 AbortController,可以同时使用 id 对比策略和 AbortController。
完整线上 Demo:
https://codesandbox.io/s/whw2q1
结尾
总结一下,对于输入过程中就请求搜索结果的场景,我们需要做两个特殊处理:
-
使用防抖,减少一些不必要的请求;
-
将最后一次请求之外的请求结果丢弃,防止前一次请求结果覆盖掉后一次。
我是前端西瓜哥,欢迎关注我,学习更多前端知识。
-
相关阅读:
Spring Boot 请求/actuator/beans 无法访问 返回404
Spring【Spring的创建与使用】
HTTP协议及Servlet类笔记
项目经理VS产品经理,二者到底有何不同?
ChatGPT:解释Java中 ‘HttpResponse‘ 使用 ‘try-with-resources‘ 的警告和处理 ‘Throwable‘ 打印警告
【前端】【探究】HTML - input类型为file时如何实现自定义文本以更好的美化
FMEA与人机环境系统中的态势感知
vue2和vue3中 ref/refs 使用示例
快速搭建springcloud项目
【校招VIP】线上实习 推推 书籍详情模块 产品脑图周最佳
- 原文地址:https://blog.csdn.net/fe_watermelon/article/details/126517834
