-
scikit-learn算法精讲 之 层次聚类和树状图
层次聚类(Hierarchical Clustering)是聚类算法的一族算法的总称,它通过连续合并或拆分聚类来构建嵌套聚类。这种聚类的层次结构就像树一样,树的根是收集所有样本的唯一簇,叶子是只有一个样本的簇。
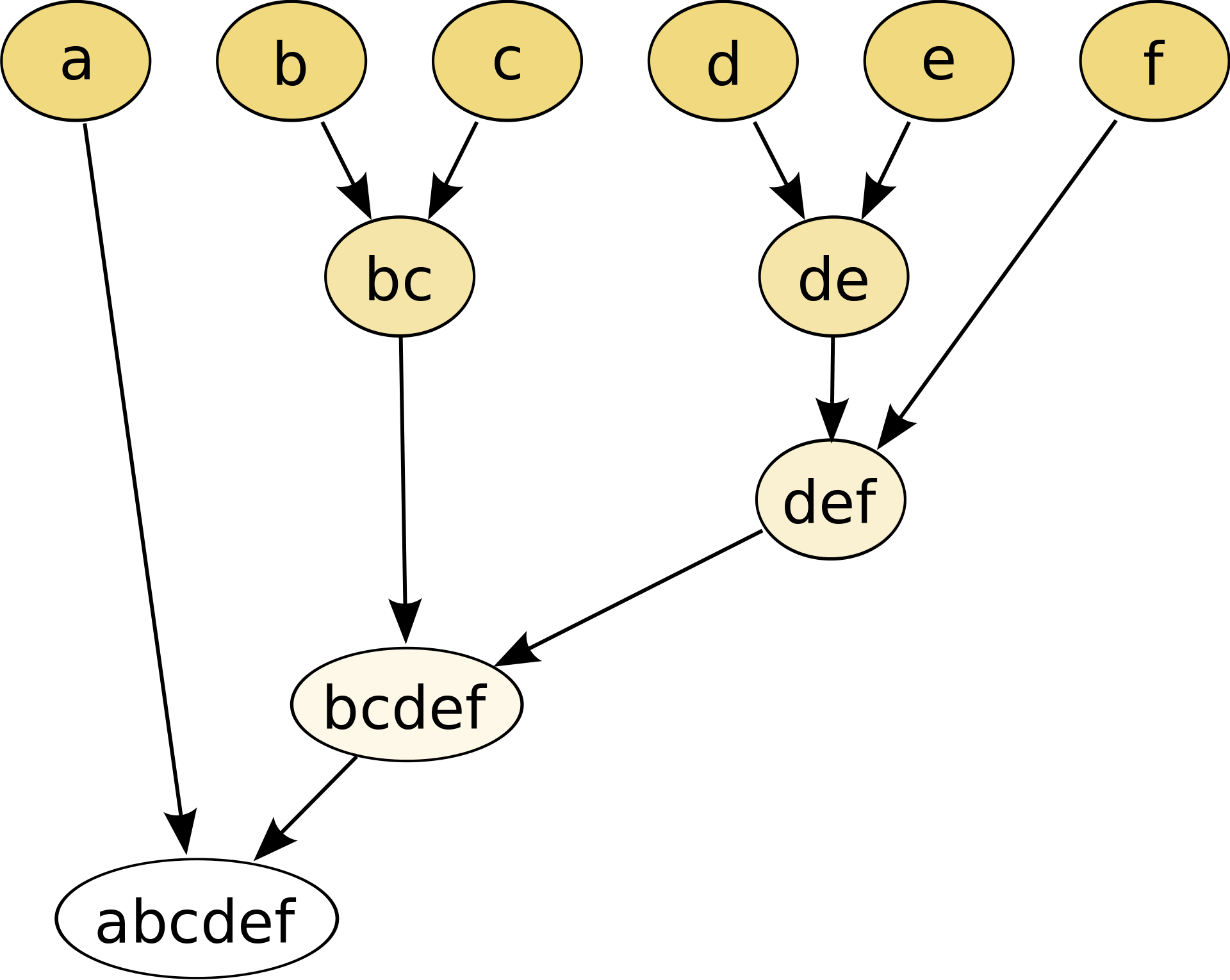
上图中,树根聚类就是abcdef,叶子聚类就是每一个字母的节点。在scikit-learn中,层次聚类可以通过AgglomerativeClustering对象来实现。这个算法使用自下而上的方法执行层次聚类:每次都从其自己的聚类开始,然后将聚类连续合并在一起。
使用鸢尾花数据集,只需要几行代码就通过AgglomerativeClustering完成层次聚类。
先导入NumPy,鸢尾花iris数据集,以及AgglomerativeClustering。
import numpy as np from sklearn.datasets import load_iris from sklearn.cluster import AgglomerativeClustering- 1
- 2
- 3
下面就准备数据并进行聚类。
iris = load_iris() X = iris.data # 准备聚类的数据(鸢尾花的花瓣和花萼长度特征) # 创建AgglomerativeClustering对象 model = AgglomerativeClustering(distance_threshold=0, linkage="ward", n_clusters=None) # 用AgglomerativeClustering进行层次聚类 model = model.fit(X)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
在上面的model创建过程中,因为指定了distance_threshold(簇间距的距离阈值,超过该阈值,簇将不会被合并),所以,算法会自动确定聚成几个类。一旦指定了distance_threshold,n_clusters必须为None。如果显式的指定n_clusters也就是簇的个数,那么就不一定要设定簇间距。
在算法中指定的linkage(链接标准)参数决定了聚类过程中的合并策略。具体说明如下:
- Ward 最小化所有聚类的平方差之和。这是一种方差最小化方法,有点类似于 k-means的目标函数,但使用凝聚层次方法处理。
- Maximum或complete linkage 最小化聚类对之间的最大距离。
- Average linkage 最小化聚类对的距离平均值。
- Single linkage 最小化聚类对的最近距离。
在使用AgglomerativeClustering时,如果样本量巨大,那么就需要通过链接标准进行约束,否则计算量会非常巨大。因为它会在每一步都考虑所有可能的合并。
下面我们继续通过树状图(dendrogram)来完成上面的层次聚类的可视化。
我们这里定义一个能创建树状图的函数。树状图是显示对象之间的层次关系的图表。它最常被创建为层次聚类的输出。
from scipy.cluster.hierarchy import dendrogram def plot_dendrogram(model, **kwargs): # 创建链接矩阵,然后绘制树状图 # 在每个节点下对样本计数 counts = np.zeros(model.children_.shape[0]) n_samples = len(model.labels_) for i, merge in enumerate(model.children_): current_count = 0 for child_idx in merge: if child_idx < n_samples: current_count += 1 # 叶节点 else: current_count += counts[child_idx - n_samples] counts[i] = current_count linkage_matrix = np.column_stack( [model.children_, model.distances_, counts] ).astype(float) # 绘制树状图 dendrogram(linkage_matrix, **kwargs)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
最后,我们通过matplotlib来显示该图。
from matplotlib import pyplot as plt plt.rcParams["font.family"]=['SimHei'] # 用来设定字体样式 plt.rcParams['font.sans-serif']=['SimHei'] # 用来设定无衬线字体样式 plt.title("层次聚类树状图") # 绘制树状图的前三个级别 plot_dendrogram(model, truncate_mode="level", p=3) plt.xlabel("簇中的数据个数") plt.show()- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
层次聚类的树状图显示如下:

本文介绍了层次聚类的概念,简单示例以及树状图的创建。关于不同链接标准的选择和其作用,我们找一篇文章单独探讨。
一个好消息
咖哥新书《数据分析咖哥十话》已经上市,这本书是咖哥数据科学项目实战的总结,良心之作,读这本书,可能是深度扎入数据分析领域的一个快捷方式。链接:https://item.jd.com/13335199.html

咖哥的另一本书,也颇受好评:零基础学机器学习:京东:https://item.jd.com/12763913.html
当当:http://product.dangdang.com/29159728.html
-
相关阅读:
Win10编译chrome
Spring boot使用https协议
微信扫码跳转小程序并传参
win10电脑不小心卸载的软件怎么恢复
使用Pytorch快速训练ResNet网络模型
java计算机毕业设计vue开发一个简单音乐播放器源码+mysql数据库+系统+lw文档+部署
PHP简单实现预定义钩子和自定义钩子
《痞子衡嵌入式半月刊》 第 63 期
谷歌悄悄上线新应用,欲用“Switch to Android”吸引苹果用户
vue高级用法extend,动态生成组件,checkbox选不中问题排除
- 原文地址:https://blog.csdn.net/JackyHuang79/article/details/126507927
