-
B+树索引(8)之索引适用场景(下)
B+树索引(8)之索引适用场景(下)
前言
在上篇文章中提到了索引适用场景的一部分包括全值匹配原则、最左匹配原则、匹配列前缀原则这三个适用场景,相关文章参考如下
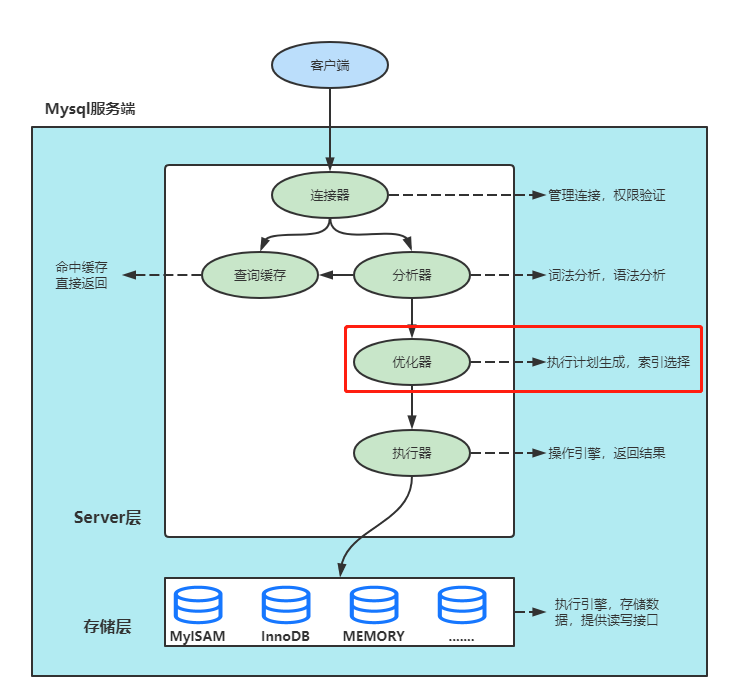
为方便理解还需要提到上篇文章的演示表person_info以及组合索引idx_name_birthday_phone_number的B+索引树基本结构
CREATE TABLE person_info( id INT NOT NULL auto_increment, name VARCHAR(100) NOT NULL, birthday DATE NOT NULL, phone_number CHAR(11) NOT NULL, country varchar(100) NOT NULL, PRIMARY KEY (id), KEY idx_name_birthday_phone_number (name, birthday, phone_number) );- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
匹配范围值
顾名思义就是范围查询,查询某个范围的值可以采用索引,如上idx_name_birthday_phone_number索引结构示意图
就是按照name、 birthday、phone_number顺序大小排序,所以当我们采用如下SQL查询时(仅限于name列)
select * from person_info where name > 'Asa' and name < 'Barlow';- 1
直接在索引树上搜索可以极大减少搜索成本。
但是!我们需要注意的是带组合条件的范围查询,如下
select * from person_info where name > 'Asa' and name < 'Barlow' and birthday > '1980-01-01';- 1
上面的查询条件可以拆分为两个部分
name > ‘Asa’ and name < ‘Barlow’
这部分同样还可以使用索引,因为B+树本来就是优先name属性值进行排序,所以可以通过索引减少检索成本。
birthday > ‘1980-01-01’;
而birthday部分不能通过索引,因为name属性范围内的birthday值并不一定是按照顺序排列(这里的分析一定要和匹配左边的列原则区分开来,这个原则是确定了name值相等后那么一定是根据birthday值排序,而查询范围值不确定name值是否相等所以birthday可能无序)。
也就是说在采用联合索引作为范围查找时,如果对多个列进行范围查找,只有对索引最左边的列进行范围查找才能用到B+树索引。
精确匹配某一列并范围匹配另外一列
这个情况就是和匹配范围值类似了,不过是精确匹配了某一列,如下所示
select * from person_info where name = 'Ashburn' and birthday > '1980-01-01' and birthday < '2000-12-31' and phone_number > '15100000000';- 1
- 2
- 3
根据idx_name_birthday_phone_number组合索引,可以得知该索引按照name、birthday、phone_number列排序,所以查询步骤如下
-
**name = ‘Ashburn’ **:按照索引排序顺序所以该条件肯定是走索引的。
-
**birthday > ‘1980-01-01’ and birthday < ‘2000-12-31’ **:因为name的精确匹配,也就是说当name相同时会按照birthday列值排序,所以该列的范围查找会直接走索引。
-
**phone_number > ‘15100000000’**:该列解释就和匹配范围值类似了,因为birthday列是范围查找,所以phone_number列不一定有序,所以不会走索引。
所以根据分析如下SQL会全部走索引
select * from person_info where name = 'Ashburn' and birthday = '1980-01-01' and phone_number > '15100000000';- 1
- 2
- 3
排序
因为B+索引树本来就是有序的,数据页与数据页之间采用主键值或者索引列排序,记录与记录之间采用同样方式排序,所以我们可以直接沿用此特点轻松排序,如下
-- 排序顺序先按照name值排序,name值相同按照birthday列排序 -- birthday值相同按照phone_number列排序,order by规则和组合索引规则类似 select * from person_info order by name, birthday, phone_number;- 1
- 2
- 3
-
相关阅读:
应用软件漏洞排名
基于SSM的宿舍公共财产管理系统设计与实现
Selenium - Tracy 小笔记2
发票识别神器推荐,告别繁琐手动录入,轻松管理财务
线性表的单链表
work环境配置
java 写excel文件
Arthas
到底什么是拓扑空间,拓扑
【Java成王之路】EE初阶第十七篇: maven 工具
- 原文地址:https://blog.csdn.net/zzf1233/article/details/126503482