-
知识图谱从入门到应用——知识图谱的存储与查询:基于关系数据库的知识图谱存储
分类目录:《知识图谱从入门到应用》总目录
相关文章:
· 知识图谱的存储与查询:基于关系数据库的知识图谱存储
· 知识图谱的存储与查询:基于原生图数据库的知识图谱存储
图数据存储的特点
知识图谱的存储需要综合考虑知识的结构、图的特点、索引和查询优化等问题。典型的知识图谱存储引擎分为基于关系数据库的存储和基于原生图的存储。图数据库存储对于知识图谱应用并非是必须的,例如著名的知识图谱项目Wikidata后端是MySQL实现的。在实践中,知识图谱存储也多采用混合存储结构。为了探讨知识图谱的存储,首先从知识图谱的图结构模型讲起。前面文章多次提到,不论是属性图,还是RDF图模型,基本的数据模型都是有向标记图。知识图谱中包含两类信息,一类是图的结构信息,另一类是由节点和边的标记所包含的语义类型信息。图的结构和语义类型信息是进一步构建更加复杂知识结构,如公理、逻辑规则的基础。针对知识图谱的特点,需要考虑存储相关的三个方面的问题:存储的物理结构、存储的性能问题和图的查询问题。
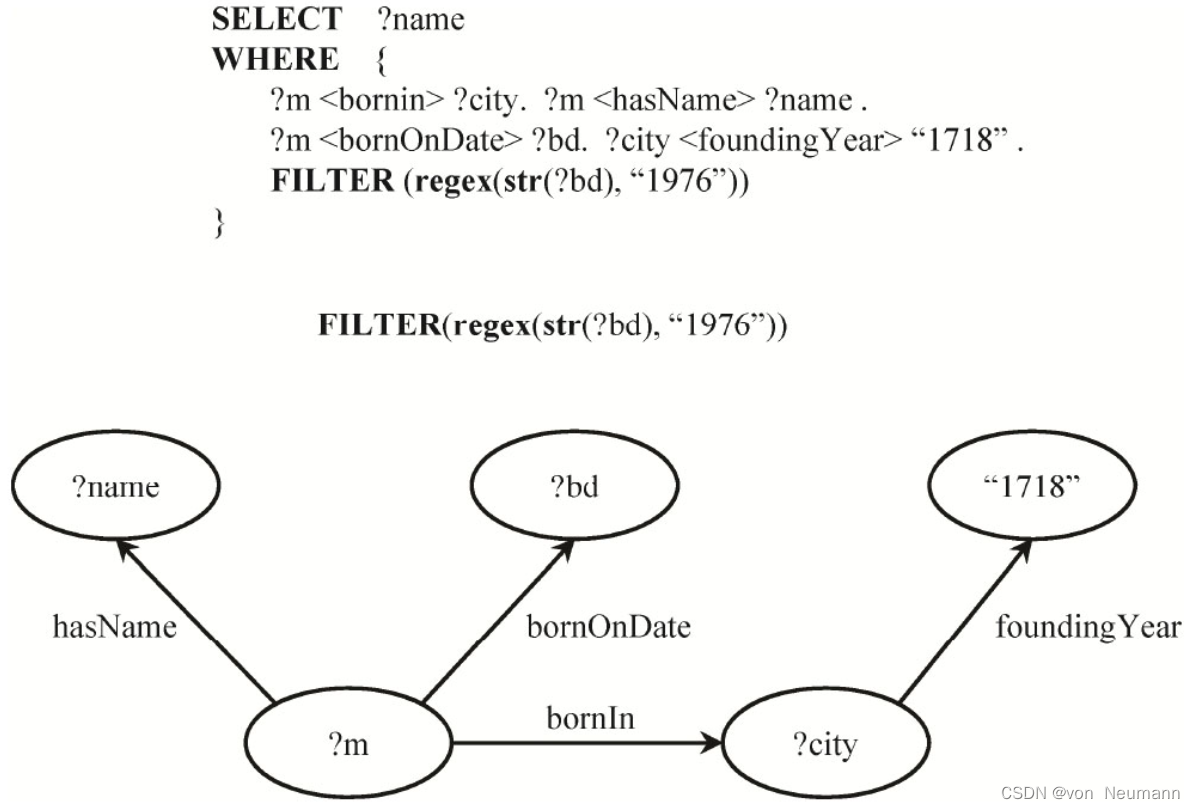
首先介绍图的查询语言。有很多种图的查询语言,SPARQL是针对RDF设计的语义查询语言。SPARQL从语法上和SQL很类似,如下图所示,该例子描述了一个查询:“查询出生在1976年,且出生地所在城市是在1718年创立的人的名字。”本质上,这样一条SPARQL查询语言可以用一个带变量的图来表示,查询计算的问题则可以转化一个子图匹配的问题。
基于三元组表的图谱存储
最简单的知识图谱存储方式就是直接存三元组。利用关系数据库,只建一张包含(Subject, Predicate, Object)三列的表,然后把所有的三元组存入其中。这种方法因为很简单,所以仍然有知识图谱项目采用,但最大的问题是查询计算效率很低。给定一个有多重关联约束的SPARQL查询,需要把它翻译成对应的SQL查询,就会发现这是一个包含非常多的Self-Join的查询,显然效率会十分低下,如下图所示:

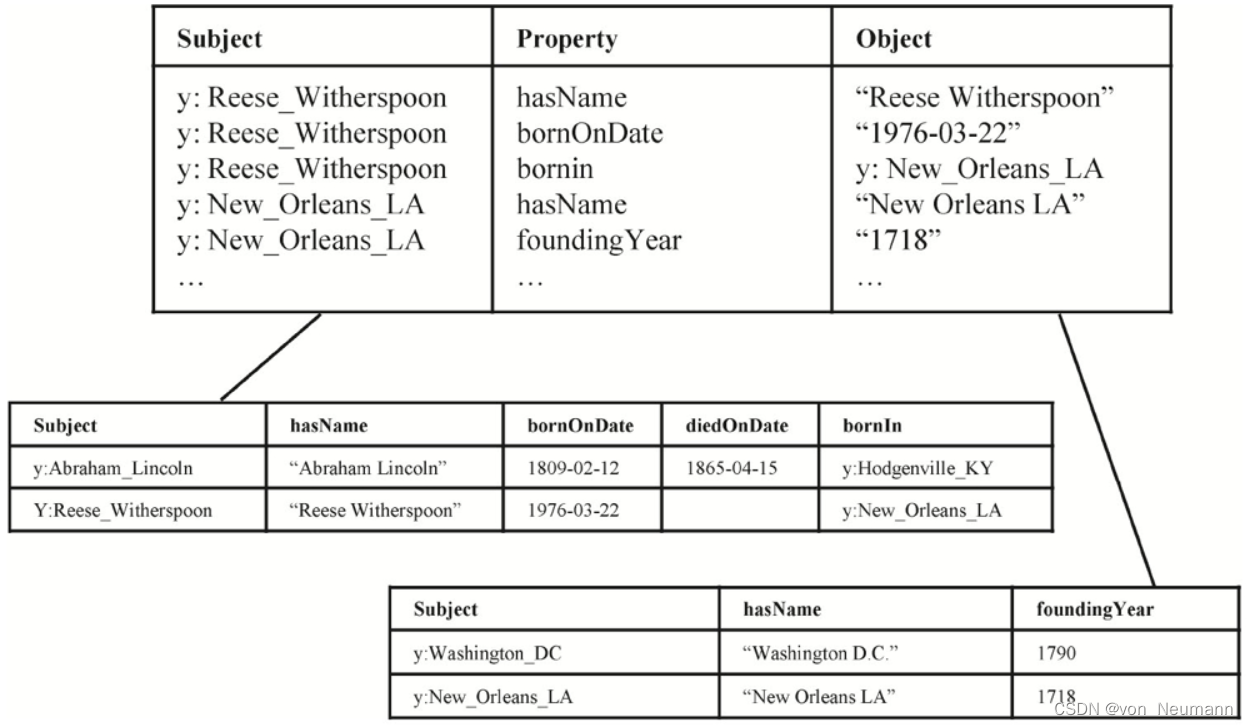
基于属性表的图谱存储
第二种方法称为属性表(Property Tables)。属性表存储仍然基于传统关系数据库实现,典型的如Jena、FlexTable、DB2RDF等都是采用基于属性表的存储方式。其基本思想是以实体类型为中心,把属于同一个实体类型的属性组织为一个表,即属性表进行存储,如下图所示。这样的优点是Join减少了,本质上接近于关系数据库,因而可重用大部分关系数据库的功能。缺点是会产生很多空值,因为知识图谱与关系模型不一样,同一类型的实体包含的属性类型可能差异很大,因而在极端情况下,这种存储方式会产生大量空值。另外一个缺点是它的实现高度依赖基于
Subject的合理聚类,但这个聚类计算并不容易,且对于多值属性,聚类计算更加复杂。
基于全索引结构的知识图谱存储
性能更好的存储方式是基于全索引结构的存储,典型的实现包括RDF-3X和Hexastore等。这种方法也仅维护一张包含(Subject, Predicate, Object)的三列表,但增加了多个方面的优化手段。第一个优化手段是建立Mapping Table,即将所有的字符串首先映射到唯一的数字ID,三列表中不再存储真实的字符串,而是只存储对应的数字ID,这将大大压缩存储空间。进一步建立六重索引:SPO、SOP、PSO、POS、OPS、OSP,即分别建立
Subject-Predicate-Object、Subject-Object-Predicate、Predicate-Subject-Object等六个方面的全索引,如下图所示。显然多种形式的索引覆盖了多个维度的图查询需求,可以方便从Subject检索Object,也可以方便地从Predicate检索Subject等。同时,所有的三元组基于字符串排序,并利用clustered B+树来组织,以进一步优化索引检索的效率。

下面用一个简单例子演示全索引结构下的查询实现。还是以最开始的SPARQL查询语句为例,如下图图所示。给定待匹配条件?m bornin ?city,首先利用PSO索引,以bornIn为中心检索相关元组进行第一轮匹配。再针对第二个匹配条件?m hasName ?name,仍然利用PSO索引,但以hasName为中心检索相关元组进行第二轮匹配。依次完成所有候选条件的处理和候选三元组的过滤,最后筛选得到需要的结果。

本文介绍的几种知识图谱存储方案均是基于关系数据库实现的。这类方法的一个直接的好处是可以充分利用关系数据库本身的存储和优化功能,因而在现实的很多知识图谱项目中仍然被广泛使用。随着原生图数据库的兴起,以及外围工具的逐步完善,原生图数据库逐渐成为知识图谱存储的主要解决方案,将在后面文章中重点对原生图数据库展开介绍。参考文献:
[1] 陈华钧.知识图谱导论[M].电子工业出版社, 2021
[2] 邵浩, 张凯, 李方圆, 张云柯, 戴锡强. 从零构建知识图谱[M].机械工业出版社, 2021 -
相关阅读:
10:00面试,10:06就出来了,问的问题有点变态。。。
shell脚本命令学习
莫名锁表? --- mysql的事务隔离级别
Java基础单元测试
【基于Arduino的垃圾分类装置开发教程四超声波检测】
【SpringMVC】使用Eclipse创建第一个SpringMVC项目
【Maven】<dependencyManagement>详解
【ES6.0】- 扩展运算符(...)
备份服务器数据的重要
Java调用ChatGPT的API接口实现对话与图片生成
- 原文地址:https://blog.csdn.net/hy592070616/article/details/126502539