-
一些可以参考的文档集合8
一些可以参考的文档集合7_xuejianxinokok的博客-CSDN博客
之前的文章集合:
一些可以参考文章集合1_xuejianxinokok的博客-CSDN博客
一些可以参考文章集合2_xuejianxinokok的博客-CSDN博客
一些可以参考的文档集合3_xuejianxinokok的博客-CSDN博客
一些可以参考的文档集合4_xuejianxinokok的博客-CSDN博客
一些可以参考的文档集合5_xuejianxinokok的博客-CSDN博客
一些可以参考的文档集合6_xuejianxinokok的博客-CSDN博客
一些可以参考的文档集合7_xuejianxinokok的博客-CSDN博客
20221011
- #include
- #include
- #include
- #include
- #include
- using namespace cv;
- using namespace std;
- string PATH = "funk.jpg"; //Image Path
- int AREA_FILTER = 1000;
- Mat imgOrg, imgProc, imgWarp;
- vector
initialPoints, docPoints; - int w = 420, h = 596;
- Mat preProcessing(Mat img)
- {
- cvtColor(img, imgProc, COLOR_BGR2GRAY); // to gray scale
- GaussianBlur(imgProc, imgProc, Size(3,3), 3, 0); // blurring for better canny performance
- Canny(imgProc, imgProc, 25, 75); // edge detection
- Mat kernel = getStructuringElement(MORPH_RECT, Size(3, 3));
- dilate(imgProc, imgProc, kernel);
- return imgProc;
- }
- vector
getContours(Mat imgDil) { - //detects the biggest rectangle in image
- vector
- vector
hierarchy; - findContours(imgDil,contours,hierarchy,RETR_EXTERNAL,CHAIN_APPROX_SIMPLE); //finding contours
- vector
- vector
boundRect(contours.size()) ; - vector
biggest; - int maxArea=0;
- for (int i=0;i
- int area = contourArea(contours[i]);
- string objectType;
- if(area>AREA_FILTER){ //filter small rectangles
- float peri = arcLength(contours[i],true);
- approxPolyDP(contours[i],conPoly[i],0.02*peri,true);
- if(area>maxArea && conPoly[i].size()==4){ //find biggest (4 for rectangle)
- maxArea = area;
- biggest = {conPoly[i][0],conPoly[i][1],conPoly[i][2],conPoly[i][3]};
- }
- }
- }
- return biggest;
- }
- void drawPoints(vector
points, Scalar color) { - for(int i=0;i
- {
- circle(imgOrg,points[i], 5,color,FILLED);
- putText(imgOrg, to_string(i),points[i],FONT_HERSHEY_PLAIN,4,color,4);
- }
- }
- vector
reorder(vector {points ) - vector
newPoints; - vector<int> sumPoints, subPoints;
- //get corners
- for(int i = 0;i<4;i++){
- sumPoints.push_back(points[i].x + points[i].y);
- subPoints.push_back(points[i].x - points[i].y);
- }
- newPoints.push_back(points[min_element(sumPoints.begin(),sumPoints.end()) - sumPoints.begin()]);
- newPoints.push_back(points[max_element(subPoints.begin(),subPoints.end()) - subPoints.begin()]);
- newPoints.push_back(points[min_element(subPoints.begin(),subPoints.end()) - subPoints.begin()]);
- newPoints.push_back(points[max_element(sumPoints.begin(),sumPoints.end()) - sumPoints.begin()]);
- return newPoints;
- }
- Mat getWarp(Mat img, vector
points, float w, float h) - {
- Point2f src[4] = {points[0],points[1],points[2],points[3]};
- Point2f dst[4] = {{0.0f,0.0f},{w,0.0f},{0.0f,h},{w,h}};
- Mat matrix = getPerspectiveTransform(src,dst);
- warpPerspective(img, imgWarp, matrix, Point(w, h));
- return imgWarp;
- }
- void main() {
- //sample
- imgOrg = imread(PATH);
- resize(imgOrg,imgOrg,Size(),0.5,0.5); // reduce the size of the photo in half
- //preprocessing
- imgProc = preProcessing(imgOrg);
- //get contours
- initialPoints = getContours(imgProc);
- //drawPoints(initialPoints,Scalar(0,0,255));
- docPoints = reorder(initialPoints);
- //drawPoints(docPoints,Scalar(0,255,0));
- //warp
- imgWarp = getWarp(imgOrg, docPoints, w, h);
- imshow("Image imgWarp",imgWarp);
- waitKey(0);
- }
在 C++ 中使用 OpenCV 对图像中的对象进行扭曲透视如题
https://mp.weixin.qq.com/s/YmxImnAXSsQ56QrVVfJvoA
mAP(Mean Average Precision)即为所有类的 AP(平均精度) 的平均值。
准确率(Precision)| 查准率
准确率(Precision)也称为精度,它是衡量在所有预测为正类中(TP+FP),找到真阳性(TP)的能力,即


在目标检测任务中,结合上面讲的 IoU 阈值来判断其真阳性(TP)、假阳性(FP),从而来计算精度(Precision),比如:

20221007
数据层的负载均衡
随着MySQL官方的不断发力,在基于MySQL复制的基础上,推出了一系列的高可用方案,例如,主从半同步复制、InnoDB ReplicaSet、组复制(MGR)、InnoDB Cluster,及目前最新的InnoDB ClusterSet。



低精度优化
一般模型训练过程中都是采用 FP32 或者 FP64 高精度的方式进行存储模型参数,主要是因为梯度计算更新的可能是很小的一个小数。高精度使得模型更大,并且计算很耗时。而在推理不需要梯度更新,所以通常如果精度从 FP32 降低到 FP16,模型就会变小很多,并且计算量也下降,而相对于模型的推理效果几乎不会有任何的变化,一般都会做 FP16 的精度裁剪。
而 FP32 如果转换到 INT8,推理性能会提高很多,但是裁剪不是直接裁剪,参数变动很多,会影响模型的推理效果,需要做重新的训练,来尽可能保持模型的效果
内存优化的方向,通常是减少频繁的设备内存空间的申请和尽量做到内存的复用。
一般的,可以根据张量生命周期来申请空间:
-
静态内存分配:比如一些固定的算子在整个计算图中都会使用,此时需要再模型初始化时一次性申请完内存空间,在实际推理时不需要频繁申请操作,提高性能
-
动态内存分配:对于中间临时的内存需求,可以进行临时申请和释放,节省内存使用,提高模型并发能力
-
内存复用:对于同一类同一个大小的内存形式,又满足临时性,可以复用内存地址,减少内存申请。
20221006
统计学习中的一个很重要的假设就是输入的分布是相对稳定的。如果这个假设不满足,则模型的收敛会很慢,甚至无法收敛。所以,对于一般的统计学习问题,在训练前将数据进行归一化或者白化(whitening)是一个很常用的trick。
但这个问题在深度神经网络中变得更加难以解决。在神经网络中,网络是分层的,可以把每一层视为一个单独的分类器,将一个网络看成分类器的串联。这就意味着,在训练过程中,随着某一层分类器的参数的改变,其输出的分布也会改变,这就导致下一层的输入的分布不稳定。分类器需要不断适应新的分布,这就使得模型难以收敛。
对数据的预处理可以解决第一层的输入分布问题,而对于隐藏层的问题无能为力,这个问题就是Internal Covariate Shift。而Batch Normalization其实主要就是在解决这个问题。
除此之外,一般的神经网络的梯度大小往往会与参数的大小相关(仿射变换),且随着训练的过程,会产生较大的波动,这就导致学习率不宜设置的太大。Batch Normalization使得梯度大小相对固定,一定程度上允许我们使用更高的学习率。

20220928

PyTorch下的可视化工具(网络结构/训练过程可视化)
20220923
一个 Go 语言写的微服务后端管理系统。

20220922
http2.0
3.1、特点
3.1.1、二进制分帧
http1.x 在应用层是以纯文本的方式通信,注定了每次请求 &响应的数据包特别大,这是第一个影响其通信效率的原因。http2.0 针对此做了改造,将所有的传输信息分割为更小的帧和消息,并对此采用二进制编码,所以 http2.0 的客户端和服务端都需要引进新的二进制编解码机制。
http2.0 并没有改写 http1.x 之前的各种在应用层上的语义,只是用分帧的技术将原来的数据包重新封装了一下,比方说:http1.x 的传输信息主要为 headers+body,http2.0 的传输信息就是 headers 帧和 body 帧;
3.1.2、帧
最小的传输单位,http2.0 定义了帧的模板(跟协议模板类似),也有头部,头部标明了帧长度,类型,标志位……其中帧类型如下所示:
-
DATA:用于传输 http 消息体;
-
HEADERS:用于传输首部字段;
-
SETTINGS:用于约定客户端和服务端的配置数据。比如设置初识的双向流量控制窗口大小;
-
WINDOW_UPDATE:用于调整个别流或个别连接的流量
-
PRIORITY: 用于指定或重新指定引用资源的优先级。
-
RST_STREAM: 用于通知流的非正常终止。
-
PUSH_ PROMISE: 服务端推送许可。
-
PING: 用于计算往返时间,执行“ 活性” 检活。
-
GOAWAY: 用于通知对端停止在当前连接中创建流。
-

20220920
从上面的代码中,您可以看到一个 lambda 表达式包含几个部分,这些部分指定了它的操作方式。以下是每个组件的快速概述。
- 捕获子句(Capture Clause):这是 lambda 表达式的第一部分,您可以在其中指定预先存在的变量或定义要在表达式主体中使用的新变量。有不同的方法来指定捕获,例如:
复制
- auto addTwo = [foo](){ return foo + 2; }; // by value
- auto addThree = [&bar](){ return bar + 3; }; // by reference
- auto addAllVal = [=](){ return foo + bar; }; // all by value
- auto addAllRef = [&](){ return foo + bar; }; // all by reference
- // create a variable in capture clause
- auto createVarInCapture = [fooBar = foo + bar](){ return fooBar * 5; };
- // no capture - returns error because foo is not accessible
- auto errorExpression = [](){ return foo + 2; };
- 参数(Parameters):这部分 lambda 表达式也是可选的。它包含 lambda 所需的函数参数。这与您在 C++ 中定义函数参数的通常方式没有任何不同。
- 选项(Options):您还可以在定义 lambda 表达式时指定选项。您可以使用的一些选项是:mutable、exception(例如第一个示例代码中的noexcept )、 ->return_type(例如->int)、requires、attributes等。经常使用mutable选项,因为它允许在内部修改捕获拉姆达。下面的代码演示了这一点。
复制
- int value = 10;
- // returns an error - value is a const inside the expression
- auto decrement = [value](){ return --value; };
- auto increment = [value]() mutable { return ++value; };
- increment(); // 11
- 尽管其他选项很少使用,但您可以在cppreference.com的 lambdas 页面上获得有关它们的更多信息。
- 表达式主体(Expression body):这是 lambda 表达式的主体,它执行并返回一个值,就像函数一样。如有必要,您可以将 lambda 表达式的主体拆分为多行。但是,最好的做法是尽可能简短,以防止代码混乱。
20220919

20220915
GPU

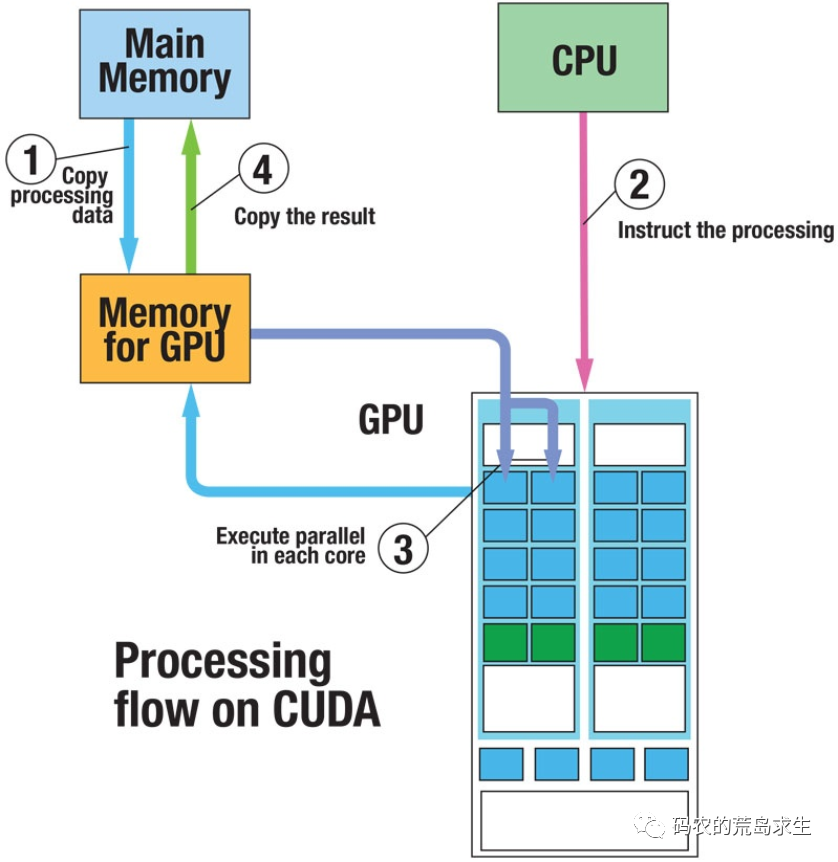
相比于CPU架构,在相同的面积上,GPU将更多的晶体管用于数值计算,取代了缓存(Cache紫色)和流控(Flow Control 黄色),GPU的计算单元Core(绿色)数量远多于CPU,但Cache和Control都要少。
如下右图GPU典型架构,每一行一个 黄色control和 绿色cache对应有多个Core,代表着同样指令在同一时刻可由多个Core执行,这样并行的设计使GPU可以并行执行几千个线程,而其内存访问的延时被计算掩盖。
详解巨头英伟达的计算底座GPU架构
https://baijiahao.baidu.com/s?id=1726914155831138673&wfr=spider&for=pc
CPU与GPU到底有什么区别?
GPU是一个流处理器,依次处理有序的相似数据集。比如一组顶点或片元就是相似的数据集。因此GPU可以以大规模并行的方式处理这些数据。另一个重要的因素是,数据处理是尽可能独立的,因此它们不需要来自邻近的(顶点,片元)信息,也不共享可写的内存位置。这个规则有时会被打破,但会带来多余的延迟。
这里以GPU运行时由于读取纹理时遇到的延迟来举例。这是最常见的发生延迟的情况,因为纹理通常存储在外部内存(显存)上而不是靠近shader core 的cache。读取通常需要成百上千个时钟周期。假如现在有100个片元等待计算。处理器正在执行第一个片元着色器,并按以下步骤执行:1.做一个简单的代数计算。2.读取纹理。为了隐藏第二步读取纹理时的延迟,处理器会在等待数据传输时先切换到第二个片元着色器,并执行第二个片元着色器的第一步1.做一个简单的代数计算。然后第二个片元着色器会读取纹理,接着切换到第三个……一直到100个片元着色器的第一步都执行完毕。然后第一个片元着色器的纹理读取此时已经完成,开始执行第一个片元着色器的后续步骤。
在上述例子中,GPU通过切换片元来保持繁忙来隐藏延迟。更进一步,gpu通过将指令执行逻辑与数据分离来使得这个设计更进一步。称为single instruction, multiple data(SIMD)。顾名思义,这种设计使一组固定数量着色程序同步执行相同的指令,虽然计算时它们各自的数据可能有所不同。相比起单个逻辑和调度单元来运行每个程序,这样会节省大量功耗以及减少用以处理,交换数据的芯片。
20220914

20220909
MySQL主从同步延迟问题,数据一致性问题,你如何去解决 (qq.com)
 https://mp.weixin.qq.com/s/YsyxvY-BJyk6-c92yTHfeQ
https://mp.weixin.qq.com/s/YsyxvY-BJyk6-c92yTHfeQ重试框架 Spring-Retry 和 Guava-Retry,你知道该怎么选吗? (qq.com)
https://mp.weixin.qq.com/s/4eKA8YZmV1OK_m5bGcTdGQ
20220906
React 代码:

Vue 代码:

20220905
RPC 被称为“远程过程调用”,表明了一个方法调用会跨越网络,跨越进程,所以传输层是不可或缺的。一说到网络传输,一堆名词就蹦了出来:TCP、UDP、HTTP,同步 or 异步,阻塞 or 非阻塞,长连接 or 短连接...
本文介绍两种传输层的实现:使用 Socket 和使用 Netty。前者实现的是阻塞式的通信,是一个较为简单的传输层实现方式,借此可以了解传输层的工作原理及工作内容;后者是非阻塞式的,在一般的 RPC 场景下,性能会表现的很好,所以被很多开源 RPC 框架作为传输层的实现方式。
RpcRequest 和 RpcResponse
传输层传输的主要对象其实就是这两个类,它们封装了请求 id,方法名,方法参数,返回值,异常等 RPC 调用中需要的一系列信息。
- public class RpcRequest implements Serializable {
- private String interfaceName;
- private String methodName;
- private String parametersDesc;
- private Object[] arguments;
- private Map<String, String> attachments;
- private int retries = 0;
- private long requestId;
- private byte rpcProtocolVersion;
- }
- public class RpcResponse implements Serializable {
- private Object value;
- private Exception exception;
- private long requestId;
- private long processTime;
- private int timeout;
- private Map<String, String> attachments;// rpc协议版本兼容时可以回传一些额外的信息
- private byte rpcProtocolVersion;
- }
20220902
https://github.com/pocketbase/pocketbase

单文件的数据库软件,使用 Go 编写,把数据库(SQLite)、后台 UI、数据管理、用户管理等,都做在一个文件里面。
20220901
JS引擎中有两个任务队列:宏任务队列和微任务队列。

在程序开始时,所有的初始代码都被视为一个宏任务,被推入宏任务队列。

20220831
1 为什么需要权限管理
日常工作中权限的问题时时刻刻伴随着我们,程序员新入职一家公司需要找人开通各种权限,比如网络连接的权限、编码下载提交的权限、监控平台登录的权限、运营平台查数据的权限等等。
在很多时候我们会觉得这么多繁杂的申请给工作带来不便,并且如果突然想要查一些数据,发现没有申请过权限,需要再走审批流程,时间拉得会很长。那为什么还需要这么严格的权限管理呢?
举个例子,一家支付公司有运营后台,运营后台可以查到所有的商户信息,法人代表信息,交易信息以及费率配置信息,如果我们把这些信息不加筛选都给到公司的每一个小伙伴,那么跑市场的都可以操作商家的费率信息,如果一个不小心把费率改了会造成巨大的损失。
又比如商户的信息都是非常隐秘的,有些居心不良的小伙伴把这些信息拿出来卖给商家的竞争对手,会给商家造成严重的不良后果。虽然这么做都是个别人人为的过错,但是制度上如果本身这些信息不开放出来就能在很大程度上避免违法乱纪的事情发生了。
总体来讲权限管理是公司数据安全的重要保证,针对不同的岗位,不同的级别看到的数据是不一样的,操作数据的限制也是不一样的。比如涉及到资金的信息只开放给财务的相关岗位,涉及到配置的信息只开放给运营的相关岗位,这样各司其职能避免很多不必要的安全问题。
如何让各个岗位的人在系统上各司其职,就是权限管理要解决的问题。
2 权限模型
2.1 权限设计
从业务分类上来讲权限可以分为数据查看权限,数据修改权限等,对应到系统设计中有页面权限、菜单权限、按钮权限等。菜单也分一级菜单、二级菜单甚至三级菜单,以csdn文章编辑页面左侧菜单栏为例是分了两级菜单。菜单对应的页面里又有很多按钮,我们在设计的时候最好把权限设计成树形结构,这样在申请权限的时候就可以一目了然的看到菜单的结构,需要哪些权限就非常的明了了。
如下图所示:

按照这个架构,按钮的父级是二级菜单,二级菜单的父级是一级菜单,这样用户申请权限的时候非常清晰的看到自己需要哪些权限。
2.2 为什么需要角色
权限结构梳理清晰之后,需要思考怎么把权限分配给用户,用户少的情况下,可以直接分配,一个用户可以有多个权限,统一一个权限可以被多个用户拥有,用户-权限的模型结构如下所示:

图片这种模型能够满足权限的基本分配能力,但是随着用户数量的增长,这种模型的弊端就凸显出来了,每一个用户都需要去分配权限,非常的浪费管理员的时间和精力,并且用户和权限杂乱的对应关系会给后期带来巨大的维护成本。用户-权限对应关系图:

图片这种对应关系在用户多的情况下基本无法维护了。其实很多用户负责同一个业务模块所需要的权限是一样的,这样的话我们是不是可以借助第三个媒介,把需要相同的权限都分配给这个媒介,然后用户和媒介关联起来,用户就拥有了媒介的权限了。这就是经典的RBAC模型,其中媒介就是我们通常所说的角色。
2.3 权限模型的演进
2.3.1 RBAC模型
有了角色之后可以把权限分配给角色,需要相同权限的用户和角色对应起来就可以了,一个权限可以分配给多个角色,一个角色可以拥有多个权限,同样一个用户可以分配多个角色,一个角色也可以对应多个用户,对应模型如下所示:

这就是经典的RBAC模型了(role-based-access-control),在这里面角色起到了桥梁左右,连接了用户和权限的关系,每个角色可以拥有多个权限,每个用户可以分配多个角色,这样用户就拥有了多个角色的多个权限。
同时因为有角色作为媒介,大大降低了错综复杂的交互关系,比如一家有上万人的公司,角色可能只需要几百个就搞定了,因为很多用户需要的权限是一样的,分配一样的角色就可以了。这种模型的对应关系图如下所示:

用户和角色,角色和权限都是多对多的关系,这种模型是最通用的权限管理模型,节省了很大的权限维护成本, 但是实际的业务千变万化,权限管理的模型也需要根据不同的业务模型适当的调整,比如一个公司内部的组织架构是分层级的,层级越高权限越大,因为层级高的人不仅要拥有自己下属拥有的权限,二期还要有一些额外的权限。
RBAC模型可以给不同层级的人分配不同的角色,层级高的对应角色的权限就多,这样的处理方式可以解决问题,但是有没有更好的解决办法呢,答案肯定是有的,这就引出角色继承的RBAC模型。
2.3.2 角色继承的RBAC模型
角色继承的RBAC模型又称RBAC1模型。每个公司都有自己的组织架构,比如公司里管理财务的人员有财务总监、财务主管、出纳员等,财务主管需要拥有但不限于出纳员的权限,财务总监需要拥有但不限于财务主管的权限,像这种管理关系向下兼容的模式就需要用到角色继承的RBAC模型。角色继承的RBAC模型的思路是上层角色继承下层角色的所有权限,并且可以额外拥有其他权限。
模型如下所示:

图片从模型图中可以看出下级角色拥有的权限,上级角色都拥有,并且上级角色可以拥有其他的权限。角色的层级关系可以分为两种,一种是下级角色只能拥有一个上级角色,但是上级角色可以拥有多个下级角色,这种结构用图形表示是一个树形结构,如下图所示:

图片还有一种关系是下级角色可以拥有多个上级角色,上级角色也可以拥有多个下级角色,这种结构用图形表示是一个有向无环图,如下图所示:

图片树形图是我们比较常用的,因为一个用户一般情况下不会同时有多个直属上级,比如财务部只能有一个财务总监,但是可以有多个财务主管和收纳员。
2.3.3 带约束的RBAC模型
带约束的RBAC模型又成RBAC2模型。在实际工作中,为了安全的考虑会有很多约束条件,比如财务部里同一个人不能即是会计又是审核员,跟一个人同一时间不能即是运动员又是裁判员是一个道理的,又比如财务部的审核员不能超过2个,不能1个也没有。因为角色和权限是关联的,所以我们做好角色的约束就可以了。
常见的约束条件有:角色互斥、基数约束、先决条件约束等。
角色互斥: 如果角色A和角色B是互斥关系的话,那么一个用户同一时间不能即拥有角色A,又拥有角色B,只能拥有其中的一个角色。
比如我们给一个用户赋予了会计的角色就不能同时再赋予审核员的角色,如果想拥有审核员的角色就必须先去掉会计的角色。假设提交角色和审核角色是互质的,我们可以用图形表示:

图片基数约束: 同一个角色被分配的用户数量可以被限制,比如规定拥有超级管理员角色的用户有且只有1个;用户被分配的角色数量也需要被限制,角色被分配的权限数量也可以被限制。
先决条件约束:用户想被赋予上级角色,首先需要拥有下级角色,比如技术负责人的角色和普通技术员工角色是上下级关系,那么用户想要用户技术负责人的角色就要先拥有普通技术员工的角色。
2.4 用户划分
2.4.1 用户组
我们创建角色是为了解决用户数量大的情况下,用户分配权限繁琐以及用户-权限关系维护成本高的问题。抽象出一个角色,把需要一起操作的权限分配给这个角色,把角色赋予用户,用户就拥有了角色上的权限,这样避免了一个个的给用户分配权限,节省了大量的资源。
同样的如果有一批用户需要相同的角色,我们也需要一个个的给用户分配角色,比如一个公司的客服部门有500多个人,有一天研发部研发了一套查询后台数据的产品,客服的小伙伴都需要使用,但是客服由于之前并没有统一的一个角色给到所有的客服小伙伴,这时候需要新加一个角色,把权限分配给该角色,然后再把角色一个个分配给客服人员,这时候会发现给500个用户一个个添加角色非常的麻烦。但是客服人员又有共同的属性,所以我们可以创建一个用户组,所有的客服人员都属于客服用户组,把角色分配给客服用户组,这个用户组下面的所有用户就拥有了需要的权限。
RBAC模型添加用户组之后的模型图如下所示:

图片很多朋友会问,用户组和角色有什么区别呢?简单的来说,用户组是一群用户的组合,而角色是用户和权限之间的桥梁。 用户组把相同属性的用户组合起来,比如同一个项目的开发、产品、测试可以是一个用户组,同一个部门的相同职位的员工可以是一个用户组, 一个用户组可以是一个职级,可以是一个部门,可以是一起做事情的来自不同岗位的人。
用户可以分组,权限也可以分组,权限特别多的情况下,可以把一个模块的权限组合起来成为一个权限组,权限组也是解决权限和角色对应关系复杂的问题。
比如我们定义权限的时候一级菜单、二级菜单、按钮都可以是权限,一个一级菜单下面有几十个二级菜单,每个二级菜单下面又有几十个按钮,这时候我们把权限一个个分配给角色也是非常麻烦的,可以采用分组的方法把权限分组,然后把分好的组赋予角色就可以了。
给权限分组也是个技术活,需要理清楚权限之间的关系,比如支付的运营后台我们需要查各种信息,账务的数据、订单的数据、商户的数据等等,这些查询的数据并不在一个页面,每个页面也有很多按钮,我们可以把这几个页面以及按钮对应的权限组合成一个权限组赋予角色。加入权限组之后的RBAC模型如下所示:

图片实际工作中我们很少给权限分组,给用户分组的场景会多一些,有的时候用户组也可以直接和权限关联,这个看实际的业务场景是否需要,权限模型没有统一的,业务越复杂业务模型会约多样化。
2.4.2 组织
每个公司都有自己的组织架构,很多时候权限的分配可以根据组织架构来划分。因为同一个组织内的小伙伴使用的大部分权限是一样的。如下所示一个公司的组织架构图:

图片按照这个组织架构,每一个组织里的成员使用的基础权限很可能是一样的,比如人力资源都需要看到人才招聘的相关信息,市场推广都需要看到行业分析的相关信息,按照组织来分配角色会有很多优势:
实现权限分配的自动化: 和组织关系打通之后,按照组织来分配角色,如果有新入职的用户,被划分在某个组织下面之后,会自动获取该组织下所有的权限,无需人工分配。又比如有用户调岗,只需要把组织关系调整就可以了,权限会跟着组织关系自动调整,也无需人工干预。这么做首先需要把权限和组织关系打通。
控制数据权限: 把角色关联到组织,组织里的成员只能看到本组织下的数据,比如市场推广和大客定制,市场推广针对的是零散的客户,大可定制针对的是有一定体量的客户,相互的数据虽然在一个平台,但是只能看自己组织下的数据。
加入组织之后的RBAC模型如下所示:

图片用户可以在多个组织中,因为组织也有层级结构,一个组织里只可以有多个用户,所以用户和组织的关系是多对多的关系,组织和角色的关系是一对一的关系。这个在工作中可以根据实际情况来确定对应关系。
2.4.3 职位
一个组织下面会有很多职位,比如财务管理会有财务总监、财务主管、会计、出纳员等职位,每个职位需要的权限是不一样的,可以像组织那样根据职位来分配不同的角色,由于一个人的职位是固定的,所以用户跟职位的对应关系时一对一的关系,职位跟角色的对应关系可以是多对多的关系。加入职位的RBAC模型如下所示:

2.5 理想的RBAC模型
RBAC模型根据不同业务场景的需要会有很多种演变,实际工作中业务是非常复杂的,权限分配也是非常复杂的,想要做出通用且高效的模型很困难。我们把RBAC模型的演变汇总起来会是一个支撑大数据量以及复杂业务的理想的模型。把RBAC、RBAC1、RBAC2、用户组、组织、职位汇总起来的模型如下所示:

图片按照这个模型基本上能够解决所有的权限问题,其中的对应关系可以根据实际的业务情况来确定,一般情况下,组织和职位是一对多的关系,特殊情况下可以有多对多的情况,需要根据实际情况来定。
理想的RBAC模型并不是说我们一开始建权限模型就可以这么做,而是数据体量、业务复杂度达到一定程度之后可以使用这个模型来解决权限的问题,如果数据量特别少,比如刚成立的公司只有十几个人,那完全可以用用户-权限模型,都没有必要使用RBAC模型。
3 权限系统表设计
3.1 标准RBAC模型表设计 标准RBAC模型的表是比较简单了,要表示用户-角色-权限三者之前的关系,首先要创建用户表、角色表、权限表,用户和角色是多对多的关系,角色和权限是多对多的关系,需要再创建两章关系表,分别是用户-角色关系表和角色-权限关系表。这六张表的ER图如下所示:

3.2 理想RBAC模型表设计
理想的RBAC模型是标准RBAC模型经过多次扩展得到的,表结构也会比较复杂,因为要维护很多关系,如下图所示是理想的RBAC模型的ER图:

图片这里面需要强调的是角色互斥表,互斥的关系可以放在角色上,也可以放在权限上,看实际工作的需求。
4 结语
本文从易到难非常详细的介绍了权限模型的设计,在工作中需要根据实际情况来定义模型,千人以内的公司使用RBAC模型是完全够用的,没有必要吧权限模型设计的过于复杂。模型的选择要根据具体情况,比如公司体量、业务类型、人员数量等。总之最适合自己公司的模型就是最好的模型,权限模式和设计模式是一样的,都是为了更好的解决问题,不要为了使用模型而使用模型。
RBAC2 模型
这里RBAC2模型,在RBAC0模型的基础上,增加了一些功能,以及限制
角色互斥
即,同一个用户不能拥有两个互斥的角色,举个例子,在财务系统中,一个用户不能拥有会计员和审计这两种角色。
基数约束
即,用一个角色,所拥有的成员是固定的,例如对于CEO这种角色,同一个角色,也只能有一个用户。
先决条件
即,对于该角色来说,如果想要获得更高的角色,需要先获取低一级别的角色。举个栗子,对于副总经理和经理这两个权限来说,需要先有副总经理权限,才能拥有经理权限,其中副总经理权限是经理权限的先决条件。
运行时互斥
即,一个用户可以拥有两个角色,但是这俩个角色不能同时使用,需要切换角色才能进入另外一个角色。举个栗子,对于总经理和专员这两个角色,系统只能在一段时间,拥有其一个角色,不能同时对这两种角色进行操作。
什么是权限
权限是资源的集合,这里的资源指的是软件中的所有的内容,即,对页面的操作权限,对页面的访问权限,对数据的增删查改的权限。
万字长文,SpringSecurity实现权限系统设计
为什么需要实现幂等性
在接口调用时一般情况下都能正常返回信息不会重复提交,不过在遇见以下情况时可以就会出现问题,如:
-
前端重复提交表单: 在填写一些表格时候,用户填写完成提交,很多时候会因网络波动没有及时对用户做出提交成功响应,致使用户认为没有成功提交,然后一直点提交按钮,这时就会发生重复提交表单请求。
-
用户恶意进行刷单: 例如在实现用户投票这种功能时,如果用户针对一个用户进行重复提交投票,这样会导致接口接收到用户重复提交的投票信息,这样会使投票结果与事实严重不符。
-
接口超时重复提交: 很多时候 HTTP 客户端工具都默认开启超时重试的机制,尤其是第三方调用接口时候,为了防止网络波动超时等造成的请求失败,都会添加重试机制,导致一个请求提交多次。
-
消息进行重复消费: 当使用 MQ 消息中间件时候,如果发生消息中间件出现错误未及时提交消费信息,导致发生重复消费。
使用幂等性最大的优势在于使接口保证任何幂等性操作,免去因重试等造成系统产生的未知的问题。
Spring Boot 实现接口幂等性的 4 种方案
20220830
G1 回收器有下面几个不同的地方:
-
采用化整为零的分区思想
-
采用标记 - 整理的垃圾回收算法
-
可预测的 GC 停顿时间
分区思想
对于 CMS 及之前的回收器来说,其 JVM 内存空间按照分代的思路划分成物理连续的一大片区域,如下图所示。

但在 G1 回收器中,虽然也采用了分代的思路,但其并没有为其分配一块连续的内存,而是将整块内存化整为零拆分成一个个 Region,如下图所示。

正如上图所示,G1 回收器不再为年轻代和老年代划分大块的内存,而是划分成了一个个的 Region,每个 Region 被标记成年轻代或者老年代。在 G1 中,还多了一个 Humongous 区域,其是为了优化大对象的分配而诞生的。
G1 回收器化整为零的 Region 设计思想,是 G1 回收器比 CMS 回收器强大的核心。 通过将大块的内存化整为零,G1 回收器能够更加灵活地控制 GC 停顿时间,并且也解决了 CMS 回收器存在的内存碎片问题以及大内存下的长 GC 停顿时间问题。
年轻代收集
在应用刚刚启动的时候,流量慢慢进来,JVM 开始生成对象。G1 会选择一个分区并指定 eden 分区,当这块分区用满之后,G1 会选一个新的分区作为 eden 分区。这个操作会一直进行下去,一直到达到 eden 分区的上限,接着触发一次年轻代收集。
年代收集采用的是「复制算法」,其首先使用单 eden、双 survivor 迁移存活对象。在迁移过程中,会根据对象年龄以及其他特性,将对象晋升到老年代分区中,原有的年轻代分区会被整个回收掉。这个过程涉及到的规则和 CMS 回收器类似,只是 G1 回收器将内存化整为零了而已。
混合收集
随着时间推移,越来越多的对象晋升到老年代中。当老年代占比(占 Java 堆内存的比例)达到 InitiatingHeapOccupancyPercent 参数之后,JVM 便会触发「混合收集」进行垃圾收集。要注意的是:混合收集*会收集年轻代和部分老年代的内存,其并不等同于 Full GC。Full GC 会回收整个老年代内存。
对于混合收集方式来说,其收集过程可以分为 4 个阶段:
-
初始标记
-
并发标记
-
最终标记
-
筛选回收
初始标记。 该阶段与 CMS 回收器一样,都只是简单标记一下 GC Roots 能直接关联到的对象,让后续 GC 回收线程能与用户线程并发执行。初始标记阶段是需要「Stop the World」的。
并发标记。 该阶段与 CMS 回收器一样,它从 GC Root 开始对堆中对象进行可达性分析,找出存活的对象,这阶段耗时很长,但可与用户程序并发执行,不需要「Stop the World」。
最终标记。 该阶段与 CMS 回收器一样,它是为了修正在并发标记期间因用户程序继续运作而导致引用发生变化的问题。只是 G1 回收器采用了不同的方式去实现,在这个阶段是需要「Stop the World」的。
筛选回收。 该阶段与 CMS 回收器的并发清除一样,它是去将标记为垃圾的对象清除掉。只是对于 G1 回收器来说,它会维护各个 Region 的回收价值和成本,随后根据用户期望的 GC 停顿时间来指定回收计划。

来自《深入理解 Java 虚拟机》
整体看下来,我们会发现 G1 回收器的混合收集过程与 CMS 回收器非常类似,都经历初始标记、并发标记、最终标记、筛选回收(并发清除)几个阶段。
20220825
当前主流的代码覆盖率工具:
- C/C++→Gcov ,Java→JaCoCo,JavaScript→ Istanbul。
- 考虑到服务器端主要是Java语言,所以CICD平台优先使用JaCoCo来支持 Java 语言的代码覆盖率统计能力。
- 通过JaCoCo官网,我们可以看到JaCoCo的使命是为Java VM 的环境中的代码覆盖分析提供标准技术。重点是提供一个轻量级、灵活且有据可查的库,用于与各种构建和开发工具集成。
2.2 JaCoCo优点
- JaCoCo支持指令(C0)、分支(C1)、行、方法、类和圈复杂度等多维度的覆盖分析;
- 基于 Java 字节码,也可以在没有源文件的情况下工作;
- 性能良好,运行时开销很小,尤其是对于大型项目;
- 比较完整的API,很方便与其他工具进行集成;
- 远程协议和 JMX 控制可在任何时间点从代理请求执行数据下载。
在开发移动端app时,经常会碰到需要这样一种情况 —— 网站滚动到一定高度的时候,让一部分内容作为navbar,也就是置顶显示,我们一般会使用js监听scroll事件来实现,但是新增的css属性position:sticky可以简单实现
position的含义是指定位类型,取值类型可以有:static、relative、absolute、fixed、inherit和sticky,这里sticky是CSS3新发布的一个属性。我今天重点要说的就是sticky属性
position:sticky用法
- position:sticky 被称为粘性定位元素(stickily positioned element)是计算后位置属性为 sticky 的元素。
- 简单的理解就是:在目标区域以内,它的行为就像 position:relative;在滑动过程中,某个元素距离其父元素的距离达到sticky粘性定位的要求时(比如top:100px);position:sticky这时的效果相当于fixed定位,固定到适当位置。
- 可以说是相对定位relative和固定定位fixed的结合
- 元素固定的相对偏移是相对于离它最近的具有滚动框的祖先元素,如果祖先元素都不可以滚动,那么是相对于viewport来计算元素的偏移量。
position:sticky 使用条件
1.父元素不能overflow:hidden或者overflow:auto属性。 2.必须指定top、bottom、left、right4个值之一,否则只会处于相对定位 3.父元素的高度不能低于sticky元素的高度 4、sticky元素仅在其父元素内生效
例子
当鼠标下滑到一定高度时,触发position:sticky定位的要求,让“流行,新款,精选”固定为距离顶部44px的地方。

https://www.jb51.net/css/716126.html
https://www.jb51.net/css/716126.html
20220824
当
ES Module最开始作为一种新的JavaScript模块化方案在ES6中被引入的候,其实是通过在import语句中强制指定相对路径或绝对路径来实现的。- import dayjs from "https://cdn.skypack.dev/dayjs@1.10.7"; // ES modules
- console.log(dayjs("2022-08-12").format("YYYY-MM-DD"));
这和其他常见的模块化系统(例如
CommonJS)的工作方式略有不同,并且在使用像webpack这样的模块打包工具的时候会使用更简单的语法:- const dayjs = require('dayjs') // CommonJS
- import dayjs from 'dayjs'; // webpack
在这些系统里,模块导入语句通过
Node.js运行时或相关构建工具映射到特定(版本)的文件。用户只需要在import语句中直接编写模块说明符(通常是包名),模块就可以自动处理。由于开发人员已经熟悉了这种从
npm导入包的方式,因此必须要先经过一个的构建步骤才能确保以这种方式编写的代码可以在浏览器中运行。Import maps就可以解决这个问题,它可以将模块说明符(包名)自动映射到它的相对或绝对路径。从而让我们不使用构建工具也能使用简洁的模块导入语法。如何使用 Import maps
我们可以通过
HTML中的

 https://xie.infoq.cn/article/680ffd538f9eba1700fe99134
https://xie.infoq.cn/article/680ffd538f9eba1700fe99134 https://github.com/suyuan32/simple-admin-core
https://github.com/suyuan32/simple-admin-core https://zhuanlan.zhihu.com/p/413145211
https://zhuanlan.zhihu.com/p/413145211