-
【语音识别入门】概述
1、语音识别的定义
Automatic Speech Recognition(ASR)或Speech to Text(STT),将语音转换为文本的任务。
2、语音识别的常用评估标准:
(1)Accuracy(准确率)
- 音素错误率(Phone Error Rate)
- 词错误率(Word Error Rate,WER)
- 字错误率(Character Error Rate,CER)
- 句错误率(Sentence Error Rate,SER)
(2)Efficiency(效率)
- 实时率(Real-time Factor,RTF)
3、语音生成
(1)音素:一种语言中语音的“最小”单元。音素可以分为辅音音素和元音音素,不同的语言中音素的数量不完全相同
(2)词素:一种语言中最小的具有语义的结构单元
(3)共振峰:指声音的频谱中能量相对集中的一些区域
(4)协同发音:人的发音过程中,受类似惯性的影响,每一个发音都会受到前面发音和后面发音的影响,音素在声学上的实现和上下文是强相关的
(5)音节:一个更大颗粒度的单位,元音和辅音结合构成一个音节
在中文中,一个汉字读音为一个带调音节,普通话约1300多个带调音节,如果去掉声调,即基础音节,普通话约400个基础音节。
4、语音感知
(1)响度:人主管感受不同频率成分声音的物理量
(2)音色:由声音波形的谐波频谱和包络决定
(3)音调:对于频率的感知,非线性的,近似对数函数
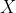
f:物理频率
Tmel:音调
Mel:单位5、语音识别的深度学习时代
2006年,多伦多大学Geoffrey Hinton教授在Nature上发表论文,为神经网络提供了有效的预训练算法,标志着语音识别进入深度学习时代。这个阶段声学架构从GMM-HMM转变为DNN-HMM,语言模型也转变为ngram+NNLM。在深度学习时代,语音识别错误率在众多Benchmark上取得新低,目前在IBM,Switchboard数据集上词错误率已达到5.0%,语音系统开始逐步从混合系统(Hybrid)发展到端到端系统。
6、现代语音识别框架
(1)统计模型:
如果
是指声学特征向量(观测向量)的序列,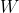 表示一个单词序列,则最有可能的单词序列由以下公式计算而来:
表示一个单词序列,则最有可能的单词序列由以下公式计算而来: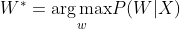
应用贝叶斯定理推导:
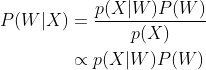
其中,
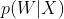 为声学模型,
为声学模型,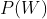 为语言模型。
为语言模型。现代的统计模型使用声学模型、语言模型、发音词典,通过给定的声学特征向量X,获取最有可能的词序列
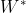 。
。(2)端到端系统:
用一个神经网络直接讲输入声学特征向量X映射为词序列
。7、语料库与工具包
(1)英文数据:
- TIMIT:音素识别,LDC版权
- WSJ:新闻播报,LDC版权
- Switchboard:电话对话,LDC版权
- Librispeech:有声读物,1000小时,开源(http://openslr.org/12/)
- AMI:会议,开源(http://openslr.org/16/)
- TED-LIUM:演讲,开源(http://openslr.org/19/)
- CHiME-4:平板远讲,需申请
- CHiME-5/6:聚会聊天,需申请
(2)中文数据:
- THCHS-30,30小时,开源(http://openslr.org/18/)
- HKUST,150小时,电话对话,LDC版权
- AIShell-1,178小时,开源(http://openslr.org/33/)
- AIShell-2,1000小时,开源需申请(http://www.aishelltech.com/aishell_2)
- aidatatang_200zh,200小时,开源(http://openslr.org/62/)
- MAGICDATA,755小时,开源(http://openslr.org/68/)
(3)工具包:
- HTK:http://htk.eng.cam.ac.uk/(C)
- Kaldi:http://kaldi-asr.org/(C++,Python)(目前使用最广泛的工具包)
- ESPNet:https://github.com/espnet/(Pytorch based)(主要针对端到端系统)
- Lingvo:https://github.com/tensorflow/lingvo.git(Tensorflow based)
-
相关阅读:
小程序商城免费搭建之java商城 电子商务Spring Cloud+Spring Boot+二次开发+mybatis+MQ+VR全景+b2b2c
PRML 概率分布
如何在Windows 10上安装Go并搭建本地编程环境
关于稳定扩散最详细的介绍
ThingsBoard IoT Gateway 实战(二)- 通过 Request Connector 获取天气
博客园页面风格+代码块美化+分类+深色模式+Mac代码
文心一言api接入如何在你的项目里使用文心一言
【纯手工打造】时间戳转换工具(python)
Python 笔记02 (网络交互 TCP/UDP)
2023年【烟花爆竹经营单位主要负责人】考试及烟花爆竹经营单位主要负责人新版试题
- 原文地址:https://blog.csdn.net/weixin_51293984/article/details/126500612