-
Elasticsearch简介
如果用数据库做搜索会怎么样- 如果表记录上千万上亿了这个性能问题,另外一个如果有一个本文字段要在里面模糊配置,这个就会出现严重的性能问题
- 还不能将搜索词拆分开来,比如上面这个只能搜索名字是“张三”开头的员工,如果想搜出“张小三”那是搜索不出来的。
总体来说,用数据库来实现搜索,是不太靠谱的,通常性能也会很差
Elasticsearch 是一个开源的(分布式)搜索引擎 (分析系统)
是一个分布式的开源搜索和分析引擎,在 Apache Lucene 的基础上开发而成。- 一个分布式的实时文档存储,每个字段 可以被索引与搜索
- 一个分布式实时分析搜索引擎
- 能胜任上百个服务节点的扩展,并支持 PB 级别的结构化或者非结构化数据
Elasticsearch是提供持久存储、统计等多项功能的现代搜索引擎
既是搜索引擎又是数据库【非关系型数据库】,不支持事务、复杂的关系(至少1.X版本不支持,2.X有改善,但支持的仍然不好)
全文检索:全文数据库是全文检索系统的主要构成部分。所谓全文数据库是将一个完整的信息源的全部内容转化为计算机可以识别、处理的信息单元而形成的数据集合。全文数据库不仅存储了信息,而且还有对全文数据进行词、字、段落等更深层次的编辑、加工的功能,而且所有全文数据库无一不是海量信息数据库。
举例:当我们输入“全瓦解”,会被拆分成”全”,“瓦解”2个此,用2个词去倒排索引里面去检索数据,检索到的数据返回。整个过程就叫做全文检索倒排索引:根据属性的值来查找记录,由于不是由记录来确定属性值,而是由属性值来确定记录的位置,因而称为倒排索引(inverted index)。
这种索引表中的每一项都包括一个属性值和具有该属性值的各记录的地址。
带有倒排索引的文件我们称为倒排索引文件,简称倒排文件(inverted file)。Lucene 是开源的搜索引擎工具包(就是一个jar包,里面包含了封装好的各种建立倒排索引,以及进行搜索的代码,包括各种算法)
Solr 也是开源的基于Lucene 的分布式搜索引擎,跟Elasticsearch有很多相似之处。
Elasticsearch靠全文检索起步,将Lucene开发包做成一个数据产品,屏蔽了Lucene各种复杂的设置,为开发人员提供了很友好的便利。很多传统的关系型数据库也提供全文检索,有的是基于Lucene内嵌,有的是基于自研,与Elasticsearch比较起来,功能单一,性能也表现不是很好,扩展性几乎没有。ES解决了这些问题
1、自动维护数据的分布到多个节点的索引的建立,还有搜索请求分布到多个节点的执行
2、自动维护数据的冗余副本,保证了一旦机器宕机,不会丢失数据
3、封装了更多高级的功能,例如聚合分析的功能,基于地理位置的搜索- 可以作为一个大型分布式集群(数百台服务器)技术,处理PB级数据,服务大公司;也可以运行在单机上,服务小公司
- Elasticsearch不是什么新技术,主要是将全文检索、数据分析以及分布式技术,合并在了一起
- 对用户而言,是开箱即用的,非常简单,作为中小型的应用,直接3分钟部署一下ES
- Elasticsearch作为传统数据库的一个补充,比如全文检索,同义词处理,相关度排名,复杂数据分析,海量数据的近实时处理;
使用场景
如果开始一个新项目使用Elasticsearch作为唯一的数据存储,可以以帮助保持你的设计尽可能简单。但此种场景不支持包含频繁更新、事务(transaction)的操作。
举例如下:新建一个博客系统使用es作为存储。
1)我们可以向ES提交新的博文;
2)使用ES检索、搜索、统计数据。场景二:在现有系统中增加Elasticsearch
由于ES不能提供存储的所有功能,一些场景下需要在现有系统数据存储的基础上新增ES支持。
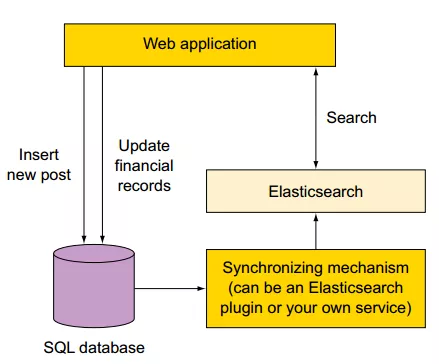
如果你使用了如图所示的SQL数据库和ES存储,你需要找到一种方式使得两存储之间实时同步。需要根据数据的组成、数据库选择对应的同步插件。可供选择的插件包括:1)mysql、oracle选择
logstash-input-jdbc插件。【canal也OK】2)mongo选择 mongo-connector工具
应用查询
Elasticsearch最擅长的就是查询,基于倒排索引核心算法,查询性能强于B-Tree类型所有数据产品,尤其是关系型数据库方面。当数据量超过千万或者上亿时,数据检索的效率非常明显。Elasticsearch在通用查询应用场景,关系型数据库由于索引的左侧原则限制,索引执行必须有严格的顺序,如果查询字段很少,可以通过创建少量索引提高查询性能,如果查询字段很多且字段无序,那索引就失去了意义;相反Elasticsearch是默认全部字段都会创建索引,且全部字段查询无需保证顺序,所以我们在业务应用系统中,大量用Elasticsearch替代关系型数据库做通用查询,自此之后对于关系型数据库的查询就很排斥,除了最简单的查询,其余的复杂条件查询全部走Elasticsearch。
大数据领域
Elasticserach已经成为大数据平台对外提供查询的重要组成部分之一。大数据平台将原始数据经过迭代计算,之后结果输出到一个数据库提供查询,特别是大批量的明细数据。
日志检索
著名的ELK三件套,讲的就是Elasticsearch,Logstash,Kibana,专门针对日志采集、存储、查询设计的产品组合。
5)监控领域
6)机器学习ES组件基本介绍
文档元数据
一个文档不仅仅包含它的数据 ,也包含 元数据 —— 有关 文档的信息。 三个必须的元数据元素如下:
_index文档在哪存放
_type文档表示的对象类别
_id文档唯一标识
# ES在springboot中使用- 引入依赖
在
pom.xml,加入spring-boot-starter-data-elasticsearch<dependency> <groupId>org.springframework.bootgroupId> <artifactId>spring-boot-starter-data-elasticsearchartifactId> dependency>- 1
- 2
- 3
- 4
- 编写配置文件
server: port: 9001 es: schema: http address: 192.168.0.1:9200 connectTimeout: 10000 socketTimeout: 20000 connectionRequestTimeout : 50000 maxConnectNum: 16 maxConnectPerRoute: 20- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 实体类:
@Data @AllArgsConstructor @NoArgsConstructor @Document(indexName = "shen") public class User { @Id private String id; // 用在属性上 代表mapping中一个属性 一个字段 type:属性 用来指定字段类型 analyzer:指定分词器 @Field(type = FieldType.Text,analyzer = "ik_max_word") private String name; @Field(type = FieldType.Integer) private Integer age; @Field(type = FieldType.Text) private Date bir; @Field(type = FieldType.Text,analyzer = "ik_max_word") private String introduce; @Field(type = FieldType.Text,analyzer = "ik_max_word") private String address; }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 向es中插入一条文档
/** * ElasticSearch Rest client操作 * * RestHighLevelClient 更强大,更灵活,但是不能友好的操作对象 * ElasticSearchRepository 对象操作友好 * * 我们使用rest client 主要测试文档的操作 **/ // 复杂查询使用:比如高亮查询 @Autowired RestHighLevelClient restHighLevelClient; @Override public ResponseInfo addUsers(User user) throws IOException { IndexRequest indexRequest = new IndexRequest("shen"); indexRequest.source(JSONObject.toJSONString(user), XContentType.JSON); IndexResponse indexResponse = restHighLevelClient.index(indexRequest, RequestOptions.DEFAULT); return ResponseInfo.ok(indexResponse); }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 调用接口
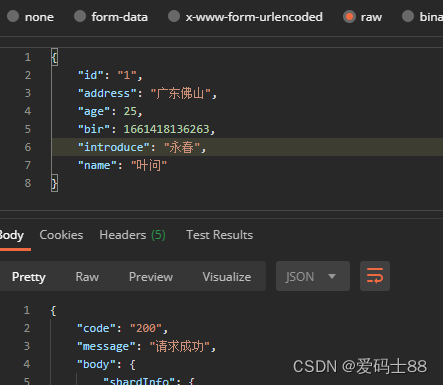
- 使用kibana可以查看es里的结果:

/** * 更新 */ @Override public ResponseInfo updateDoc(User user) throws IOException { Document document = user.getClass().getAnnotation(Document.class); UpdateRequest updateRequest = new UpdateRequest(document.indexName(), user.getId()); updateRequest.doc(JSONObject.toJSONString(user), XContentType.JSON); UpdateResponse updateResponse = restHighLevelClient.update(updateRequest, RequestOptions.DEFAULT); return ResponseInfo.ok(updateResponse); } /** * 删除 */ @Override public ResponseInfo deleteDoc(User user) throws IOException { Document document = user.getClass().getAnnotation(Document.class); DeleteRequest deleteRequest = new DeleteRequest(document.indexName(), user.getId()); DeleteResponse deleteResponse = restHighLevelClient.delete(deleteRequest, RequestOptions.DEFAULT); return ResponseInfo.ok(deleteResponse); } /** * 批量更新 */ @Override public void bulkUpdate() throws IOException { BulkRequest bulkRequest = new BulkRequest(); // 添加 IndexRequest indexRequest = new IndexRequest("shen"); indexRequest.source("{\"name\":\"张三\",\"age\":23,\"bir\":\"1991-01-01\",\"introduce\":\"西藏\",\"address\":\"拉萨\"}", XContentType.JSON); bulkRequest.add(indexRequest); // 删除 DeleteRequest deleteRequest01 = new DeleteRequest("shen","pYAtG3kBRz-Sn-2fMFjj"); DeleteRequest deleteRequest02 = new DeleteRequest("shen","uhTyGHkBExaVQsl4F9Lj"); DeleteRequest deleteRequest03 = new DeleteRequest("shen","C8zCGHkB5KgTrUTeLyE_"); bulkRequest.add(deleteRequest01); bulkRequest.add(deleteRequest02); bulkRequest.add(deleteRequest03); // 修改 UpdateRequest updateRequest = new UpdateRequest("shen","pYAtG3kBRz-Sn-2fMFjj"); updateRequest.doc("{\"name\":\"曹操\"}",XContentType.JSON); bulkRequest.add(updateRequest); BulkResponse bulkResponse = restHighLevelClient.bulk(bulkRequest, RequestOptions.DEFAULT); BulkItemResponse[] items = bulkResponse.getItems(); for (BulkItemResponse item : items) { System.out.println(item.status()); } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
/** * 查询 * @throws IOException */ @Test public void testSearch() throws IOException { //创建搜索对象 SearchRequest searchRequest = new SearchRequest("shen"); //搜索构建对象 SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder(); searchSourceBuilder.query(QueryBuilders.matchAllQuery())//执行查询条件 .from(0)//起始条数 .size(10)//每页展示记录 .postFilter(QueryBuilders.matchAllQuery()) //过滤条件 .sort("age", SortOrder.DESC);//排序 //创建搜索请求 searchRequest.source(searchSourceBuilder); SearchResponse searchResponse = restHighLevelClient.search(searchRequest, RequestOptions.DEFAULT); System.out.println("符合条件的文档总数: "+searchResponse.getHits().getTotalHits()); SearchHit[] hits = searchResponse.getHits().getHits(); for (SearchHit hit : hits) { System.out.println(hit.getSourceAsMap()); } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
-
相关阅读:
微信公众号获取openId——开发阶段
scroll-view 实现滑动分类
【SqlServer】存储过程:批量查询数据库下表的元数据
【两周学会FPGA】从0到1学习紫光同创FPGA开发|盘古PGL22G开发板学习之数码管动态显示(五)
11111111
GANs的优化函数与完整损失函数计算
手把手教你前后分离架构(五) SpringBoot连接数据库
开源的正反面
性能测试系列二 何时介入性能测试
Jetpack Compose学习(11)——Navigation页面导航的使用
- 原文地址:https://blog.csdn.net/JemeryShen/article/details/126488385
