-
论文:Few-shot Named Entity Recognition with Self-describing Networks
、Few-shot Named Entity Recognition with Self-describing Networks
是在few shot NER 的label semanic的基础上,做的改进,前者是利用BIO标签中的NER type,将其转为semantic 的表示。与sentence部分做dot product,生成NER的label。
论文核心
这篇文章是做的改进,提出了实体概念中间层,作为entity type的依据。
模型是:seq2seq,端到端的生成模型。

作者认为在FS-NER中,fewshot-NER任务中,存在两种问题,一是limited information challenge,指从小样本数据中,获取的知识是有限的,二是,knowledge mismatch knowledge,即不同知识库中对于同一个实体的标注会存在冲突的情况。文中举例是:“America” is geographic entity in Wikipedia, GPE in OntoNotes, and location in WNUT17作者,认为,所有的实体类型可以使用概念集来描述,这种方式具有通用性,同一份概念集可以解决不同的实体类型。当小样本时,可以通过该建立新的类型和概念集之间的关系,解决limit knowledge 问题。
模型架构
SD-Net,是一种seq2seq的结构,需要融合相同实体类型的mention的concept,产生concept集合。
识别实体,是通过concept-enriched-prefix prompt。prompt中包含了目标实体类型和concept描述。
上述所有任务均在单一模型中建模,通过前缀提示机制区分不同任务,使模型可控、通用、可连续训练。两个生成任务,一是mention describe,产生mention的concept,前缀是【MD】;二是entity generation,产生mention的entity和type,前缀是【EG】。
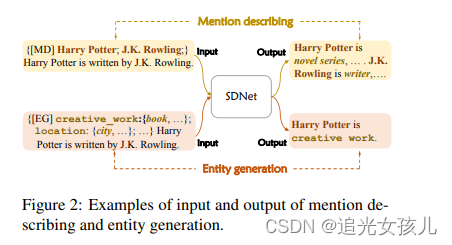
Mention Describing.
输入:sentence
产出:e1 is l1, e2 is l2,…
其中,l1,l2,l3是entity mention ei 映射的semantic concept
Type Description Construction.
输入:type description+sentence
产出:e1 is e1type,e2 is e2type过滤策略
用于description部分。
由于下游新类别的多样性,SDNet 可能没有足够的知识来描述其中一些类别,因此强制 SDNet 描述它们可能会导致描述不准确。为了解决这个问题,文中引入了一种过滤机制,使 SDNet 能够拒绝生成不可靠的描述。具体来说,SDNet 被训练为生成其他作为那些不确定实例的概念描述。给定一种新的类别和一些说明性实例,将从这些实例的概念描述中计算other类别的频率。如果在说明性实例上生成other的频率大于0.5,我们将删除类型描述,直接使用类别名称作为P_{EG}。数据集
X is sentence
来源:维基百科
实体类型:“instance of”, “subclass of” and “occupation”数据集筛选过滤条件:. all entity types except whose instances are <5. For the types whose names are longer than 3 tokens, we use their head words as the final type
1. each mention, we identify its entity types by linking it to its
Wikidata item’s types- This paper uses the collected entity types above as concepts Given an entity type, we collect all its co-occurring entity types as its describing concepts。可以理解为如下,选择共现的实体类型作为描述概念。比如,Person can
be described as {businessman, CEO, musician,
musician…} by collecting the types of “Steve
Jobs”: {person, businessman, CEO} and
“Beethoven”: {person, musician, pianist}
损失函数计算
CE loss
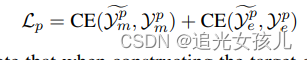
实体识别finetune
给定标注的
.
优化函数:
消融实验
(1)有无description. {[EG] person; location; . . . }
(2)两个generation任务,是否joint实施的
(3)有无filter。在description任务中,是否设置了other。论文在zero-shot实验中,
提出,融合手工制作的description可以提高zero-shot的性能。
总结
这篇文章扩展了concept集合(之前可能是直接以label作为concept的),也提出了concept集合的构建方式,相比于直接label semantic的方式,语义表达能力可能更强。
- This paper uses the collected entity types above as concepts Given an entity type, we collect all its co-occurring entity types as its describing concepts。可以理解为如下,选择共现的实体类型作为描述概念。比如,Person can
-
相关阅读:
React学习(六)— 状态管理Redux
rabbitmq详解
策略模式(Strategy mode)
多线程入门总结
计算机演变过程
19-Echarts 配置系列之: timeline 动态切换
这测试谁爱做谁做,我反正不做了,4年工作经验去面试10分钟就结束了,现在大环境卷成这样了吗?
软件合同保密协议
深入理解node的web stream模块
Flutter 教程之 如何在app中启用 Google 支付
- 原文地址:https://blog.csdn.net/Hekena/article/details/126500302