-
elasticsearch使用脚本 滚动关闭索引,更新index setting
一 问题
在旧的索引中更新mapping时,新增了分词器(分词器已经在模板中添加),但是在更新mapping时报错:
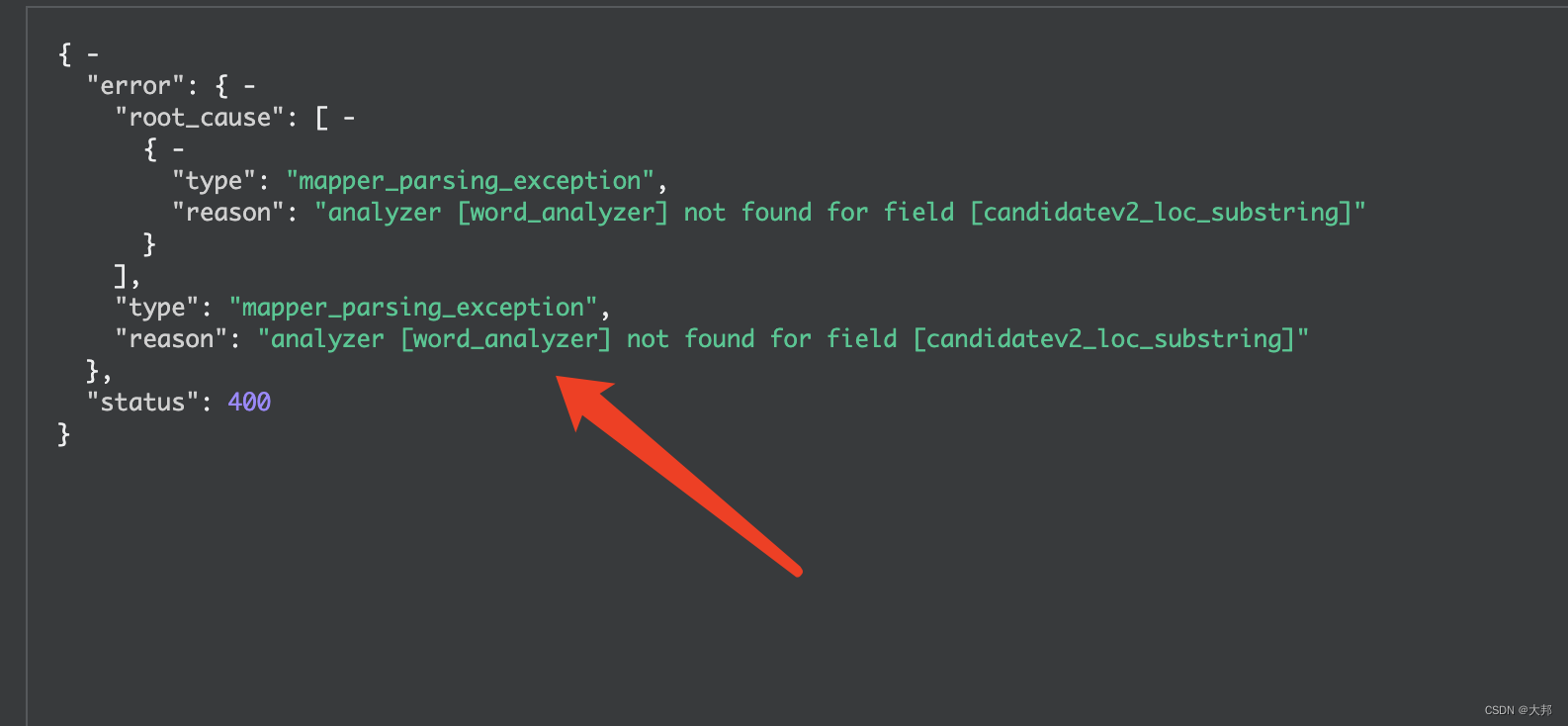
查看elasticsearch官网,发现不允许在已经存在的索引中动态更新分词器,只能先将索引close,更新分词器,然后再打开
Update index settings API | Elasticsearch Guide [8.3] | Elastic
You can only define new analyzers on closed indices. To add an analyzer, you must close the index, define the analyzer, and reopen the index.
二 问题解决方式步骤(已经验证)
2.1 由暂停数据写入&关闭分片分配
暂停数据写入,可以避免恢复阶段translog中大量数据回放,提升索引恢复速度。
关闭分片分配
PUT _cluster/settings { "persistent" : { "cluster.routing.rebalance.enable": "none" } }2.2 对所有需要进行更新分词器的索引执行flush操作。
作用是将内存buffer flush到硬盘中,避免恢复阶段translog中大量数据回放,提升索引恢复速度。
(1)获取所有索引
GET /_cat/indices
(2)获取指定索引对应的setting
GET /prod_candidatev2_chunk_{i}/_settings
根据setting内容判断索引是否包含分词器 back_edge_ngram_analyzer word_analyzer 作为更新索引判断依据
(3)对指定索引进行flush操作以及sync操作,加速恢复,避免从主分片全量拉取数据同步至副本。
POST /index{i}/_flush
POST /index{i}/_flush/synced
2.3 对索引进行关闭操作
POST /index{i}/_close
2.4 更新索引分词器
PUT index{i}/_settings { "analysis": { "filter":{ "back_edge_ngram_filter": { "min_gram": "1", "side": "back", "type": "edgeNGram", "max_gram": "256" } }, "analyzer": { "back_edge_ngram_analyzer": { "filter": [ "standard", "lowercase", "back_edge_ngram_filter" ], "tokenizer": "keyword" }, "word_analyzer": { "filter": [ "standard", "lowercase" ], "tokenizer": "keyword" }, "mk_edge2": { "type": "mk_edge", "extra_prarm": "cb,3,-1" }, "mk_edge1": { "type": "mk_edge", "extra_prarm": "wb,1,-1" } } } }2.5 轮询等待集群恢复green状态
GET _cluster/health
2.6 重复2.2至2.5步骤,直至所有索引恢复
python处理脚本:
- import time
- from tqdm import trange
- from elasticsearch import Elasticsearch
- ES_HOST = ["http://elastic:"]
- client = Elasticsearch(ES_HOST)
- # index_pattern = "thoth_candidatev2_chunk_*"
- index_pattern = "prod_candidatev2_chunk_*"
- # index_pattern = "test_candidatev2_chunk_*"
- put_all_index = False
- def main():
- all_indices = get_all_indices()
- print("Number of indices: ", len(all_indices))
- all_indices = [index for index in all_indices if not is_updated_index_settings(index) ]
- print("Number of not updated indices: ", len(all_indices))
- for index in all_indices:
- if put_all_index or select():
- print(f"Start put {index} settings")
- put_index_settings(index)
- check_cluster_health(index)
- else:
- break
- print('Finished')
- def select():
- global put_all_index
- text = input("continue(all/y/n): ")
- if text == 'y':
- return True
- elif text == 'n':
- return False
- elif text == 'all':
- put_all_index = True
- return True
- def is_updated_index_settings(index):
- settings = client.indices.get_settings(index=index)
- analysis = settings[index]["settings"]["index"]["analysis"]
- if "word_analyzer" in analysis["analyzer"] and "back_edge_ngram_analyzer" in analysis["analyzer"] and "back_edge_ngram_filter" in analysis["filter"]:
- print(f"{index} done")
- return True
- else:
- return False
- def put_index_settings(index):
- if client.cat.indices(index=index,params={"h": "status"}).strip() != 'close':
- print(f"flush {index}")
- client.indices.flush(index=index)
- print(f"flush {index} done")
- close_index(index)
- body = '{"analysis":{"filter":{"back_edge_ngram_filter":{"min_gram":"1","side":"back","type":"edgeNGram","max_gram":"256"}},"analyzer":{"back_edge_ngram_analyzer":{"filter":["standard","lowercase","back_edge_ngram_filter"],"tokenizer":"keyword"},"word_analyzer":{"filter":["standard","lowercase"],"tokenizer":"keyword"},"mk_edge2":{"type":"mk_edge","extra_prarm":"cb,3,-1"},"mk_edge1":{"type":"mk_edge","extra_prarm":"wb,1,-1"}}}}'
- client.indices.put_settings(index=index, body=body)
- if not is_updated_index_settings(index):
- print(f"put index error: {index}")
- put_index_settings(index)
- open_index(index)
- def close_index(index):
- print(f"{index} status: ", client.cat.indices(index=index,params={"h": "status"}).strip())
- client.indices.close(index)
- print(f"{index} status: ", client.cat.indices(index=index,params={"h": "status"}).strip())
- def open_index(index):
- print(f"{index} status: ", client.cat.indices(index=index,params={"h": "status"}).strip())
- client.indices.open(index)
- print(f"{index} status: ", client.cat.indices(index=index,params={"h": "status"}).strip())
- def check_cluster_health(index):
- t = trange(100, desc="recover: ", leave=True)
- last_progress = 0
- while client.cluster.health()["status"] != "green":
- t.set_description(client.cluster.health()["status"])
- current_progress = client.cluster.health()["active_shards_percent_as_number"]
- t.update(current_progress - last_progress)
- last_progress = current_progress
- recovery_status = client.cat.recovery(index=index, params={"h": "index,shard,translog_ops_percent,files_percent,stage", "v": "true"})
- output = []
- for idx, item in enumerate(recovery_status.split('\n')):
- if idx == 0:
- output.append(item)
- else:
- output.append(item) if not item.endswith('done') else None
- if len(output) > 1:
- print('\n'.join(output))
- time.sleep(2)
- t.set_description(client.cluster.health()["status"])
- t.update(100 - last_progress)
- t.close()
- def get_all_indices():
- return client.indices.get_alias(index_pattern)
- def test_put_index():
- index = "test_candidatev2_chunk_{chunk}"
- body = ''
- for chunk in range(0, 10):
- client.indices.create(index=index.format(chunk=chunk), body=body)
- if __name__ == "__main__":
- # test_put_index()
- main()
-
相关阅读:
电源模块最大输出电流怎么测试?测试标准是什么?
初学白盒测试
1 如何入门TensorFlow
Java——基本数据类型
数据结构之二叉树
【JavaWeb】01_Tomcat、Servlet、Thymeleaf
Kafka安装启动(含安装包)
Linux中in、ls、tree、clear的用法
CSP登机牌条码202112-3
阿里P8大牛用实例跟你讲明白“Java 微服务架构实战”
- 原文地址:https://blog.csdn.net/leixingbang1989/article/details/126499251
