-
Python+OpenCV4马赛克图片合成
前言
看了一篇c++通过opencv中sift算子寻找相似点然后拼接全景图片的一张文章,有点意思。寻找图片的相似特征,我好想在以前写过一篇文章吧,快速指路=>O.
想起来b站何同学做过600万粉丝名称合照的视频,属于360度全景拼接,也比较有意思,给个链接,感兴趣的看。
有点意思之后就是,我要做什么了。出门的世界经典海报,浅模仿一下吧。

思路
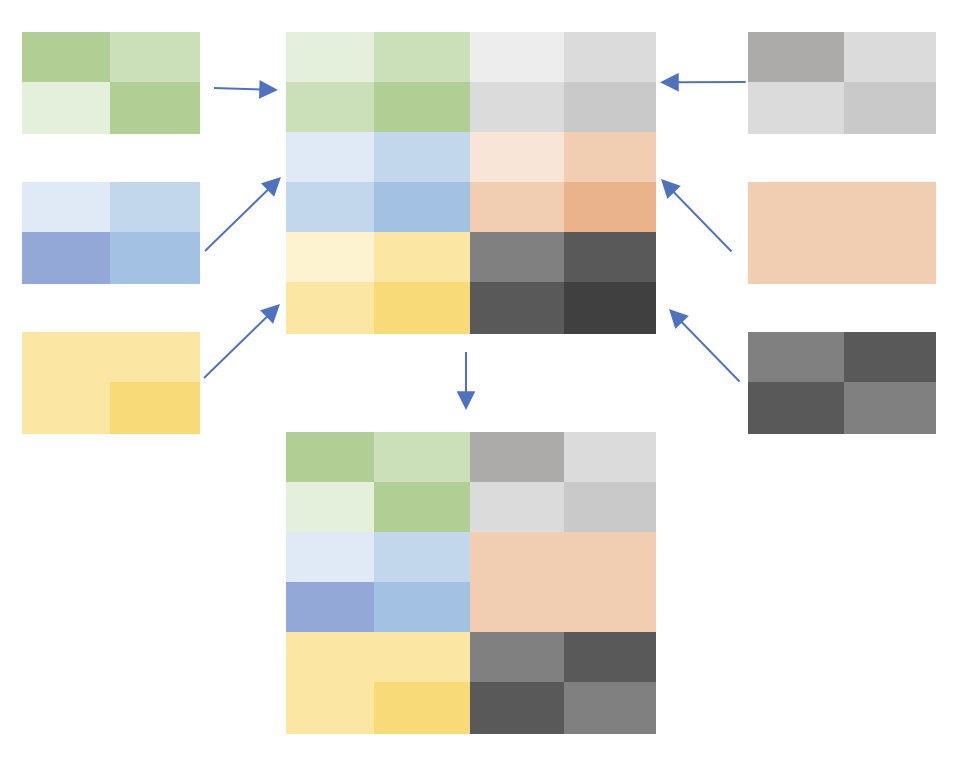
前面是图像特征点相似匹配,后者是图像色彩特征匹配。本篇文章说说后者:将目标图片划分为m * n的特征点,每张特征点足够小就可以得到一个像素单元的色彩特征,多个m * n的特征点可以构成一幅图片。

再将目标图片色彩平均特征点用其他图片的平均色彩特征点去替换:
实现

环境
每次都得先对环境呀,安装还是没安装,先对齐一下版本,这样可以避免无谓的摔跤。
mac os + jupyter notebook + python3.9.12 + opencv 4.6.0
pip install opencv-python pip install opencv-contrib-python- 1
- 2
源码
相关python运行示例:https://gitee.com/cungudafa/Python-notes
方便学习,从百度根据关键词下载图片(如果有下载的图片imread读不出来,那就删掉就好了,图片格式存的有可能不支持读取)
import requests # 从网络获取图片(保存图片路径,图片名称,数量) def getPicFromBaidu(imgPath,name,count): #进行UA伪装 header = { 'User-Agent':'Mozilla/5.0 (Macintosh; Intel Mac OS X 11_1_0) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.88 Safari/537.36' } url = 'https://image.baidu.com/search/acjson?' param = { 'tn': 'resultjson_com', 'logid': '11941270206720072198', 'ipn': 'rj', 'ct': '201326592', 'is': '', 'fp': 'result', 'queryWord': '猫', 'cl': '2', 'lm': '-1', 'ie': 'utf-8', 'oe': 'utf-8', 'adpicid': '', 'st': '', 'z':'', 'ic':'', 'hd': '', 'latest': '', 'copyright': '', 'word': '猫', 's':'', 'se':'', 'tab': '', 'width': '', 'height': '', 'face': '', 'istype': '', 'qc': '', 'nc': '1', 'fr': '', 'expermode': '', 'force': '', 'pn': str(count), 'rn': str(count), 'gsm': '1e', } #将编码形式转换为utf-8 page_text = requests.get(url=url,headers=header,params=param) page_text.encoding = 'utf-8' page_text = page_text.json() # 先取出所有链接所在的字典,并将其存储在一个列表当中 info_list = page_text['data'] # 由于利用此方式取出的字典最后一个为空,所以删除列表中最后一个元素 del info_list[-1] # 定义一个存储图片地址的列表 img_path_list = [] for info in info_list: img_path_list.append(info['thumbURL']) #再将所有的图片地址取出,进行下载 #n将作为图片的名字 for i, img_path in enumerate(img_path_list): img_data = requests.get(url=img_path,headers=header).content # .content获取真正的图片内容 img_path = str(imgPath)+'cat_' + str(i+120) + '.jpg' with open(img_path,'wb') as fp: print(img_path) fp.write(img_data) print('ok') folder_name = '/Users/admin/Desktop/project/python/pic/' name = "猫猫" count = 50 getPicFromBaidu(folder_name,name,count)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
根据图片色彩内容匹配相关联的图片并拼接:
import cv2 import glob import argparse import matplotlib.pyplot as plt import numpy as np from tqdm import tqdm # 进度条 from itertools import product # 迭代器 plt.rcParams['font.sans-serif'] = ['Arial Unicode MS']#mac 中文 def parseArgs(tagetImg, showImg, filePath): parser = argparse.ArgumentParser('拼接马赛克图片') parser.add_argument('--targetpath', type=str, default=tagetImg, help='目标图像路径') parser.add_argument('--outputpath', type=str, default=showImg, help='输出图像的路径') parser.add_argument('--sourcepath', type=str, default=filePath, help='用来拼接图像的所有源图像文件路径') parser.add_argument('--blocksize', type=int, default=40, help='马赛克快的大小') # args = parser.parse_args() # 其他编译器 args = parser.parse_known_args()[0] # jupyter 编译器 return args def readSourceImages(sourcepath, blocksize): print('开始读取图像') sourceimages = [] # 图像 avgcolors = [] # 平均颜色列表 files = []#图片路径 for path in tqdm(glob.glob("{}/*.jpg".format(sourcepath))): # print(path) image = cv2.imread(path, cv2.IMREAD_COLOR) if image.shape[-1] != 3: continue # 缩放尺寸 image = cv2.resize(image, (blocksize, blocksize)) # 图像颜色平均值 avgcolor = np.sum(np.sum(image, axis=0), axis=0) / \ (blocksize * blocksize) sourceimages.append(image) avgcolors.append(avgcolor) files.append(path) print('结束读取') return sourceimages, np.array(avgcolors) ,files def getLists(args): targetimage = cv2.imread(args.targetpath) targetimage = cv2.resize(targetimage, (1000, 1000))# 原始画布尺寸越大,渲染时间越长 # int8 int16 int32 int64 outputimage = np.zeros(targetimage.shape, np.uint8) sourceimages, avgcolors, files = readSourceImages(args.sourcepath, args.blocksize) print('开始制作') for i, j in tqdm(product(range(int(targetimage.shape[1]/args.blocksize)), range(int(targetimage.shape[0]/args.blocksize)))): block = targetimage[j * args.blocksize: ( j + 1) * args.blocksize, i * args.blocksize: (i + 1) * args.blocksize, :]#目标单cell avgcolor = np.sum(np.sum(block, axis=0), axis=0) / \ (args.blocksize * args.blocksize)#目标单cell的平均颜色 distances = np.linalg.norm(avgcolor - avgcolors, axis=1) idx = np.argmin(distances)#取平均颜色最接近的值 outputimage[j * args.blocksize: (j + 1) * args.blocksize, i * args.blocksize: (i + 1) * args.blocksize, :] = \ sourceimages[idx]#取出符合此cell的图片 cv2.imwrite(args.outputpath, outputimage)#所有cell替换原图 plt.figure(num=1, figsize=(200, 200)) plt.subplot(1,2,1) plt.xlabel("原始图片") plt.imshow(cv2.cvtColor(targetimage, cv2.COLOR_BGR2RGB)) # BGR转RGB plt.subplot(1,2,2) plt.xlabel("target") image = cv2.imread(args.outputpath, cv2.IMREAD_COLOR) plt.imshow(cv2.cvtColor(image, cv2.COLOR_BGR2RGB)) # BGR转RGB plt.show() if __name__ == '__main__': tagetImg = 'pic/cat_55.jpg' showImg = '1.jpg' filePath = 'pic' getLists(parseArgs(tagetImg, showImg, filePath)) getLists(parseArgs('pic/cat_30.jpg', '2.jpg', filePath))- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
-
相关阅读:
卡尔曼滤波器的通俗理解
日 志
uni-app:实现简易自定义下拉列表
STM32CubeMX教程6 TIM 通用定时器 - 生成PWM波
AI图书推荐:AI驱动的图书写作工作流—从想法构思到变现
基于Kylin的数据统计分析平台架构设计与实现
2308,2314,2324,2329,2339,2346
消费品企业会员运营系统 品牌会员流失解决方案
Comparator.nullsLast 处理空值
【数据结构】自写简易顺序表ArrayList
- 原文地址:https://blog.csdn.net/cungudafa/article/details/126411792
