-
0823(037天 集合框架02 Collection/Set/List,List的三个实现类的底层)
0823(037天 集合框架02 Collection/Set/List,List的三个实现类的底层)
每日一狗(田园犬西瓜瓜)
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-gyewc2lZ-1661866139375)(assets/37.png)]](https://1000bd.com/contentImg/2023/06/14/111849293.png)
集合框架02 Collection/Set/List,List的三个实现类的底层
1. List接口
有序、允许重复
1.1 特殊方法
排序
default void sort(Comparator c)@SuppressWarnings({"unchecked", "rawtypes"}) default void sort(Comparator<? super E> c) { Object[] a = this.toArray(); // 获取数组对象 Arrays.sort(a, (Comparator) c); // 使用Arrays工具类进行排序操作 ListIterator<E> i = this.listIterator(); // 获取当前list的迭代器 for (Object e : a) { // 使用forEach结构遍历排序后的数组 i.next(); // 迭代器后移 i.set((E) e); // 将排好序的数据进行覆盖 } } // 前场一下- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
插入操作
void add(int index, E element);插入操作只能操作已经操作过的位置,就是说这个地方之前必须要有值,或者是像当前数组的size位置进行插入操作,但是这个操作应该用boolean add(E e);来进行追加操作
List list = new ArrayList(); list.add(0, 20); for (int i = 0; i < 5; i++) { list.add(i); } for (int i = 0; i < 5; i++) { list.add(0, i); } list.forEach(System.out::print); // 432102001234- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
取出并且删除;
boolean remove(Object o); // 删除指定对象,返回是否成功E remove(int index); // 获取并删除指定索引位置上的数据List list = new ArrayList(); list.add(0, 20); for (int i = 0; i < 5; i++) { list.add(i); } list.forEach(System.out::print); System.out.println(list.remove((Object) 50)); // false System.out.println(list.remove((Object) 20)); // true System.out.println(list.remove(3)); // 3- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
找到指定对象在数组中的定位
int indexOf(Object o);List list = new ArrayList(); list.add(0, 20); for (int i = 0; i < 5; i++) { list.add(i); } System.out.println(list); // [20, 0, 1, 2, 3, 4] System.out.println(list.indexOf(4)); // 5 System.out.println(list.lastIndexOf(3)); // 4- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
1.2 常见的实现类
-
ArrayList:底层存储为数组,线程不安全
-
Vector:底层实现为数组,线程安全
-
LinkedList:底层实现为链表,线程不安全
ArrayList LinkedList Vector 实现方法 数组,按照索引下标访问速度快O(1),但是当删除或添加元素是会导致元素的移动,速度慢O(n) 双向链表,按照索引下标访问速度慢O(n),但是删除或添加操作速度快O(1) // 但是这里的操作指的是你已经定位到了这个节点了,所以用索引对数据及性能添加删除操作就会先有一个索引的操作O(n) 数组,按照索引下标访问O(1),添加或修改操作O(n)。 是否同步 不同步,线程不安全,并发高访问效率高 不同步,线程不安全,并发操作效率高 同步,但是并发访问或操作的效率底 如何选择 经常需要快速访问,较少在中间增加删除元素时使用;如果多线程访问,则需要自行编程解决线程安全问题 经常需要在内部增删元素,但是很少需要通过索引快速访问时使用;如果多线程访问,则需要自行编程解决线程安全问题 一般不使用,多线程中可以直接拿来用 1.3 ArrayList
public class ArrayList<E> extends AbstractList<E> // AbstractList抽象类中定义了所有的共享方法 implements List<E>, RandomAccess, Cloneable, java.io.Serializable- 1
- 2
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-k6qn6iWi-1661866139377)(assets/image-20220823110925412.png)]](https://1000bd.com/contentImg/2023/06/14/111849436.png)
构造方法
**无参构造器;**使用无参构造器,则不会直接创建数组,而是采用空数组,当第一次添加元素时才创建
private static final Object[] DEFAULTCAPACITY_EMPTY_ELEMENTDATA = {}; // 这是一个空数组 public ArrayList() { this.elementData = DEFAULTCAPACITY_EMPTY_ELEMENTDATA; }- 1
- 2
- 3
- 4
**带参构造器:**可以指定容器的容积,最多存储多少个对象
private static final Object[] EMPTY_ELEMENTDATA = {}; // 还是一个空数组 public ArrayList(int initialCapacity) { if (initialCapacity > 0) { // 大于0时按照指定 this.elementData = new Object[initialCapacity]; } else if (initialCapacity == 0) { // 为0时赋值空数组 this.elementData = EMPTY_ELEMENTDATA; } else { // 为负数时抛出 非法参数异常 throw new IllegalArgumentException("Illegal Capacity: "+ initialCapacity); } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
这里在不确定开辟空间的数组的大小时,默认开辟的时空数组,这里是对内存的一种优化处理,等你用的时候在来创建大小。
添加元素
public boolean add(E e)
protected transient int modCount = 0; // 不被序列化 public boolean add(E e) { modCount++; // 用于统计当前集合对象的修改次数(要有对象数量上的修改) /* e:新增元素, elementData:存储数组 size:添加索引 */ add(e, elementData, size); return true; } //10// transient Object[] elementData; // 非私有以简化嵌套类访问 private void add(E e, Object[] elementData, int s) { if (s == elementData.length) // 判定当前集合中存储的元素个数是否和数组长度相等 elementData = grow(); // 相等时扩容,没空间了 elementData[s] = e; // 在数组的指定位置位置存储元素 size = s + 1; // 集合当前存储对象个数加一 } //grow// // 无参扩容方法 private Object[] grow() { return grow(size + 1); // 调用代参扩容方法,容量加一 } //24// // 代餐扩容方法 private Object[] grow(int minCapacity) { /* 使用Arrays.copyOf进行拷贝操作 newCapacity方法来计算所需要的新容积值 */ return elementData = Arrays.copyOf( elementData, newCapacity(minCapacity) ); } //35// private static final int DEFAULT_CAPACITY = 10; // 数组的尺寸下限 private static final int MAX_ARRAY_SIZE = Integer.MAX_VALUE - 8; // 数组的尺寸上限 private int newCapacity(int minCapacity) { // overflow-conscious code 溢出的代码 int oldCapacity = elementData.length; // 获取老数组长度 int newCapacity = oldCapacity + (oldCapacity >> 1); // 1.5倍 // 判定是否满足最小容积的要求 if (newCapacity - minCapacity <= 0) { // 判定存储数据的数组是否时初始化的空数组 if (elementData == DEFAULTCAPACITY_EMPTY_ELEMENTDATA) // 计算默认初始化容积10和所需最小容积值则最大值 return Math.max(DEFAULT_CAPACITY, minCapacity); // 最小容积小于0时内存溢出,超出Integer的范围了 if (minCapacity < 0) // overflow throw new OutOfMemoryError(); return minCapacity; } // 判定新容积是否小于最大容积值,是则返会新容积 return (newCapacity - MAX_ARRAY_SIZE <= 0) ? newCapacity : hugeCapacity(minCapacity); } //60// private static int hugeCapacity(int minCapacity) { if (minCapacity < 0) // overflow throw new OutOfMemoryError(); // 所需容积值大于数组的尺寸上限时,返回整形的最大值,否则返回数组的尺寸上限 return (minCapacity > MAX_ARRAY_SIZE) ? Integer.MAX_VALUE : MAX_ARRAY_SIZE; }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
扩展:数组拷贝
/* 创建一个newLength长度的新数组,将原始数组的数据拷贝到新数组中,返回新数组 T[] original 原始数组 int newLength 所需要的新数组的长度 */ @SuppressWarnings("unchecked") public static <T> T[] copyOf(T[] original, int newLength) { return (T[]) copyOf(original, newLength, original.getClass()); }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
删除并获取元素
- 没有缩容处理
- 底层使用 System.arraycopy 来实现数据的移动操作
public E remove(int index)直接就有public E remove(int index) { // 检查所需要删除的位置下表阐述是否在合理的范围内【0,size】 Objects.checkIndex(index, size); // 获取所存储的 final Object[] es = elementData; @SuppressWarnings("unchecked") E oldValue = (E) es[index]; fastRemove(es, index); // 通过拷贝将index+1位置以后的数据移动到index的位置,没有缩容处理 return oldValue; // 返回需要取出的元素 } 8 / private void fastRemove(Object[] es, int i) { modCount++; // 修改次数加一 final int newSize; if ((newSize = size - 1) > i) // size - 1就是可以删除的元素的最大下标 System.arraycopy(es, i + 1, es, i, newSize - i); // 拷贝数据 ,从i+1 的位置往后的数据 拷贝到i往后的位置上 es[size = newSize] = null; // 将最后一个位置的元素进行数据赋空 }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
public boolean remove(Object o)
// 找到与之相同的第一个元素的索引,把后边的考到前边来 public boolean remove(Object o) { final Object[] es = elementData; final int size = this.size; int i = 0; found: { if (o == null) { for (; i < size; i++) if (es[i] == null) break found; // 跳出 found:代码块 } else { for (; i < size; i++) if (o.equals(es[i])) break found;// 跳出 found:代码块 } return false; } fastRemove(es, i); return true; }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
获取数据
public E get(int index)public E get(int index) { Objects.checkIndex(index, size); // 针对索引下标进行合法性验证 return elementData(index); } /// 2 / @ForceInline public static int checkIndex(int index, int length) { return Preconditions.checkIndex(index, length, null); } // 9 // @HotSpotIntrinsicCandidate public static <X extends RuntimeException>int checkIndex( int index, int length, BiFunction<String, List<Integer>, X> oobef ) { if (index < 0 || index >= length) // 判定索引小于0或>=length时抛出索引越界 throw outOfBoundsCheckIndex( oobef, index, length ); return index; }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
1.4 LinkedList
使用双向链表来实现
理论上讲这个链表的长度是没有限制,但是size是int的那就限定在【0,Integer.MAX_VAULE】
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-cwLQpbIe-1661866139377)(assets/image-20220823161049231.png)]](https://1000bd.com/contentImg/2023/06/14/111849211.png)
实现
属性
transient int size = 0; transient Node<E> first; // 头节点 transient Node<E> last; // 尾节点- 1
- 2
- 3
- 4
- 5
节点的定义
private static class Node<E> { E item; // 节点上存储的数据 Node<E> next; // 下一个节点 Node<E> prev; // 上一个节点 // 在构造时传入了节点的存储的数据,上一个节点,下一个节点 Node(Node<E> prev, E element, Node<E> next) { this.item = element; this.next = next; this.prev = prev; } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
构造器
- 啥也不是
- 在没有数据的情况下链表的存在没有意义
public LinkedList() { }- 1
- 2
// 这个就是将一个Set想转换为列表的时候用一下 // 构造一个包含指定集合元素的列表,按照集合迭代器返回元素的顺序。 public LinkedList(Collection<? extends E> c) { this(); addAll(c); }- 1
- 2
- 3
- 4
- 5
- 6
追加add
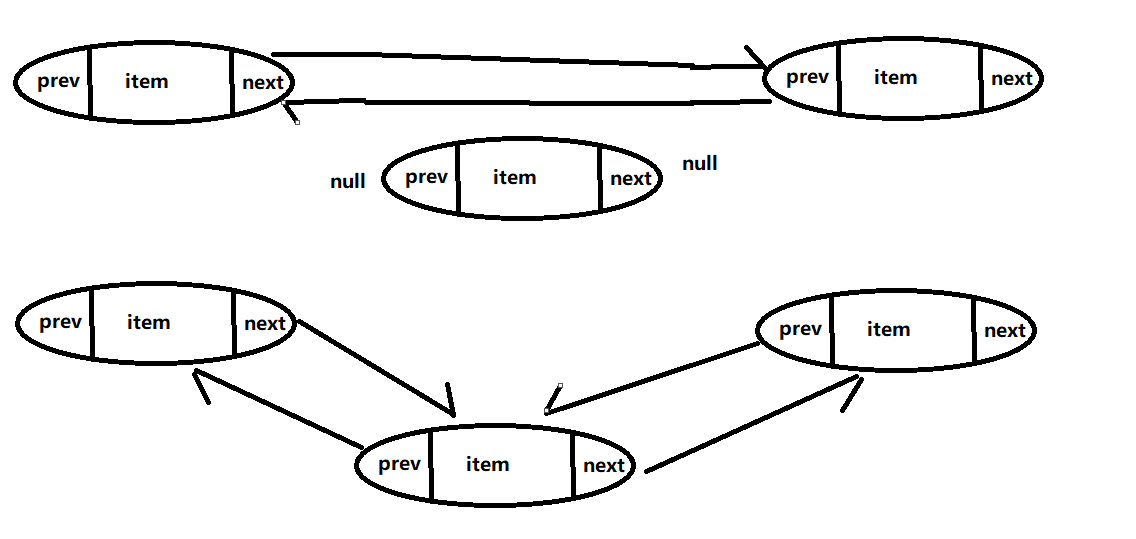
public boolean add(E e)- 判空插入
- 有值插入
public boolean add(E e) { linkLast(e); return true; } 2 void linkLast(E e) { final Node<E> l = last; // 缓存尾节点 final Node<E> newNode = new Node<>(l, e, null); // 创建新的节点 last = newNode; // 将为节点指向为新创建的节点 if (l == null) // 如果尾节点为空 first = newNode; // 则将新增节点设置为头节点 else l.next = newNode; // 否则将缓存尾节点的next指向新增的节点 size++; // 长度加一 modCount++; // 修改次数加一 }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
public boolean add(E e)- 指定索引节点定位
- 新节点插入
public void add(int index, E element) { checkPositionIndex(index); // 索引的合法性检查 if (index == size) // 在末尾追加元素 linkLast(element); else linkBefore(element, node(index)); } / 2 索引的合法性检查// private void checkPositionIndex(int index) { if (!isPositionIndex(index)) throw new IndexOutOfBoundsException(outOfBoundsMsg(index)); } / 12 索引的合法性检查 private boolean isPositionIndex(int index) { return index >= 0 && index <= size; } /// 7 在指定节点的前添加一个新节点/ void linkBefore(E e, Node<E> succ) { // final Node<E> pred = succ.prev; // 获取新节点应该指向的前一个节点 final Node<E> newNode = new Node<>(pred, e, succ); // 新节点 ,同时将新节点的前一个节点和后一个节点传入 succ.prev = newNode; // 将指定的节点的前一个节点指向刚创建的新节点 if (pred == null) // 如果前一个节点为空,指定节点为头节点 first = newNode; // 把当前节点设定为头节点 else pred.next = newNode; // 否则将新节点的前一个节点的next指向新节点 size++; // 链表长度加一 modCount++; // 修改次数加一 } // 7 定位指定索引位置上的节点/// Node<E> node(int index) { // 分两头,靠近那头就从那头开始往中间找 if (index < (size >> 1)) { // 索引里那头进 Node<E> x = first; for (int i = 0; i < index; i++) // 从前向后遍历 x = x.next; return x; } else { Node<E> x = last; for (int i = size - 1; i > index; i--) // // 从后向前遍历 x = x.prev; return x; } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
取出
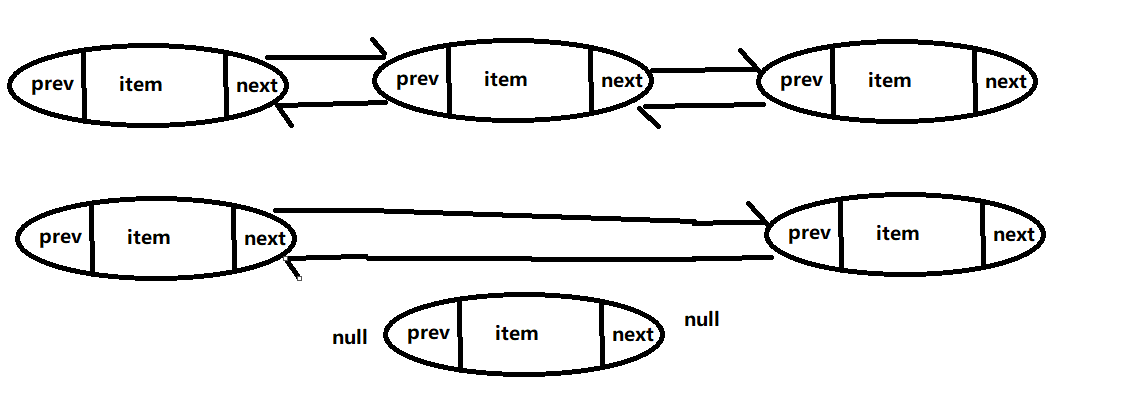
public boolean remove(Object o)循环判定找到存储这个对象的节点是哪一个节点,在用unlink删除指定的那个节点
public boolean remove(Object o) { if (o == null) { // 删除的元素是null for (Node<E> x = first; x != null; x = x.next) { // 从头节点开始找,找到第一个数据为null的节点 if (x.item == null) { // 为空时 unlink(x); // 删除指定节点 return true; // 返回true } } } else { // 当删除的不是null时 for (Node<E> x = first; x != null; x = x.next) { // 遍历定位指定节点 if (o.equals(x.item)) { // 相等时 unlink(x); // 删除指定节点 return true; // 返回true } } } return false; // 没有时返回false } / 5 删除指定的node节点,返回node中存储的数据 E unlink(Node<E> x) { // 1 2 3 final E element = x.item; // 获取节点中的数据 final Node<E> next = x.next; // 获取节点的下一个节点对象的引用 final Node<E> prev = x.prev; // 获取上一个节点 if (prev == null) { // 当2是头节点时 first = next; // 把头接指向3 } else { // 当2不是头节点时 prev.next = next; // 将1的下一个设定为3 x.prev = null; // 将2节点的下一个设定为null } if (next == null) { // 3为空时 last = prev; // 将1设定为尾接待你 } else { // 3不为空时 next.prev = prev; // 将3节点的上一个设定为1 x.next = null; // 将2的下一个设定为null } x.item = null; size--; modCount++; return element; }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
public E remove(int index)使用node获取指定索引上的节点对象,使用unlink来删除这个节点
public E remove(int index) { checkElementIndex(index); // 检查序号是否合法,不合法时抛出异常 return unlink(node(index)); // } 3 node(index))获取指定索引的节点 // 往上找有原码- 1
- 2
- 3
- 4
- 5
- 6
修改操作
获取并覆盖指定索引位置上的数据
先获取指定索引上的节点对象,将节点对象的旧数据进行缓存返回,用新数据将其覆盖
public E set(int index, E element) { checkElementIndex(index); // 索引合法性判定 Node<E> x = node(index); // 获取指定索引的节点 E oldVal = x.item; // 获取原有数据 x.item = element; // 覆盖新数据 return oldVal; // 返回原有数据 }- 1
- 2
- 3
- 4
- 5
- 6
- 7
查询
indexOf(Object o):定位元素索引位置传入为空时遍历判定是否为空,传入不为空时遍历用equals判定相等
public int indexOf(Object o) { int index = 0; if (o == null) { // 为空时一种判定 for (Node<E> x = first; x != null; x = x.next) { if (x.item == null) return index; index++; } } else { // 不为空时一种判定 for (Node<E> x = first; x != null; x = x.next) { if (o.equals(x.item)) return index; index++; } } return -1; }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
1.5 Vector
一个非常古老的一个类,从JDK1.0+就开始提供。很多方法于原始数据有出入
- 线程安全
- 扩容双倍,或固定步长
- 初始化为立即初始化,会立即分配空间
属性
protected Object[] elementData; // 数据存储 protected int elementCount; // 存储的元素个数 protected int capacityIncrement; // 容积增长的步长值- 1
- 2
- 3
构造器
立即初始化,创建即分配空间
public Vector() { this(10); } 2 public Vector(int initialCapacity) { this(initialCapacity, 0); } 6 public Vector(int initialCapacity, int capacityIncrement) { super(); if (initialCapacity < 0) // 初始化容积不能小于0 throw new IllegalArgumentException("Illegal Capacity: "+ initialCapacity); this.elementData = new Object[initialCapacity]; // 立即创建数组 this.capacityIncrement = capacityIncrement; // 设定上限制 }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
方法查看
方法基本都有synchronized,线程安全
public synchronized boolean add(E e) { modCount++; add(e, elementData, elementCount); return true; } 3 private void add( E e, // 需要添加的元素 Object[] elementData, // 存储数组 int s // 元素的个数 ) { if (s == elementData.length) // 容量判定 elementData = grow(); // 扩容 elementData[s] = e; // elementCount = s + 1; // 存储元素个数加一 } 13 private Object[] grow() { return grow(elementCount + 1); } / 19 private Object[] grow(int minCapacity) { return elementData = Arrays.copyOf( elementData, newCapacity(minCapacity) ); } /25 private int newCapacity(int minCapacity) { int oldCapacity = elementData.length; int newCapacity = oldCapacity + // 如果设置了容积增长步长,则按照步长来扩容,如果没有则扩容比为100% ((capacityIncrement > 0) ?capacityIncrement : oldCapacity); if (newCapacity - minCapacity <= 0) { if (minCapacity < 0) // overflow throw new OutOfMemoryError(); return minCapacity; } return (newCapacity - MAX_ARRAY_SIZE <= 0) ? newCapacity : hugeCapacity(minCapacity); }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
2. Set集合
无序、不允许重复
public interface Setextends Collection 没有特殊方法,全部的方法都是Collection接口中的方法
2.1 实现类
- HashSet
- TreeSet
- LinkedHashSet
2.2 一些方法
没有新方法
都是Collection接口中定义过的方法
package com.yang2; import java.util.HashSet; import java.util.Objects; import java.util.Set; public class Test01 { public static void main(String[] args) { Set set = new HashSet(); set.add(new A1(20L, "wcao")); set.add(new A1(20L, "wcao")); set.add(new A1(22L, "wcao")); System.out.println(set); // [A1 [id=20, name=wcao], A1 [id=22, name=wcao]] } } class A1 { private Long id; private String name; @Override public String toString() { return "A1 [id=" + id + ", name=" + name + "]"; } @Override public int hashCode() { return Objects.hash(id, name); } @Override public boolean equals(Object obj) { if (this == obj) return true; if (obj == null) return false; if (getClass() != obj.getClass()) return false; A1 other = (A1) obj; return Objects.equals(id, other.id) && Objects.equals(name, other.name); } public A1(Long id, String name) { super(); this.id = id; this.name = name; } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
3. 整理
List三种实现的区别?
Java已经提供的List接口的实现类有三个分别为ArrayList、Vector、LinkedList
相同点:
全都实现了List接口,实现了接口中的抽象方法,都是Java中的存储数据的容器
元素之间有序且不重复
区别:
-
ArrayList:
- 底层存储为数组,不会存储元素数据,存储的只是元素的引用,真实的数据存储在内存中
- 元素的访问用的是索引下标值,O(1);
- 插入删除操作需要将指定索引位置上后边的元素全部操作一遍(本质上用的是数组的拷贝System.arraycopy),O(n)
- 线程不安全,并发访问操作高效,但是修改操作更容易出现线程安全问题(数组的拷贝操作也是线程不安全的),如有需要请自行实现
-
Vector:
-
底层实现为数组,不会存储元素数据,存储的只是元素的引用,真实的数据存储在内存中
-
线程安全
-
比较古老JDK1.0+,当时对于集合的设定还不态明确,功能比较少
-
访问和插入删除操作于ArrayList的特性一致
-
与ArrayList对比
-
扩容步长确定,没设定则扩容比为100%
-
没有延迟创建的优化,创建Vector对象的时候就已经将数组创建完毕
-
-
-
LinkedList:
-
底层实现为链表,节点会在数据元素的基础上额外维护两个引用,一个指向当前元素的上一个元素,另一个指向下一个元素,所以直接存储的就是数据本身。
-
元素的访问用的遍历判定来定位,O(n);
-
插入删除操作直接修改节点的两个引用值即可O(1)(前提是获取到你要插入或者删除的节点对象,如果只有索引就需要先根据索引获取节点对象)
-
线程不安全
-
选用:
- ArrayList:由于其高效索引的特性,所以肯定要用于存储需要高速访问的数据上,插入和删除操作效率比较低,这里建议只在末尾进行元素的插入和删除操作,当然也不是不让用,改用还是得用,一般用于不会多线程并发访问。
- Vector:一般情况下不会使用,除非你需要线程安全的容器可以使用
- LinkedList:由于高并发高效添加修改的特性,经常用于元素需要高效进行插入删除操作的地方,但是很少用于索引访问的地方。线程不安全,需要则要编码者自行实现
集合的接口Collection/Set/List的区别
- Collection
- 是集合类型的顶层接口,上层接口Iterable可迭代的
- 元素:无序、可重复、可以存在多个null值
- Set
- 继承于Collection
- 元素:不可重复(任意的两个元素e1和e2都有e1.equals(e2)=false),无序
- 由于无序的特性,元素之间并没有明确的先后顺序,访问时无法通过索引来对容器中的元素进行定位,方法中也都没有与索引相关的任何方法。对于元素的操作只能用元素自身来进行操作。
- List
- 继承于Collection
- 元素:可重复,有序
- 通过索引元素下标来访问,类似于Java中的数组的元素访问机制
扩展
forEach方法中传入的参数为Consumer消费者接口,Consumer接口又是一个函数式接口,forEach方法中遍历当前对象,使用函数视
list.forEach(System.out::print); // 特殊写法 / 1 default void forEach(Consumer<? super T> action) { Objects.requireNonNull(action); for (T t : this) { action.accept(t); } } 3 @FunctionalInterface public interface Consumer<T> { void accept(T t); }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
所以说这个写法list.forEach(System.out::print)可以用于所有的函数式接口中
package com.yang2; public class Test02 { public static void main(String[] args) { // 装备写法 Test02.printT(System.out::println, 20); // lambda表达式 Test02.printT((o) -> { System.out.println(o); }, 20); // 匿名内部类 Test02.printT(new Test03() { @Override public void pp(Object obj) { System.out.println(obj); } }, 20); } public static void printT(Test03 test03, Object obj) { test03.pp(obj); } } @FunctionalInterface interface Test03 { void pp(Object obj); }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
-
相关阅读:
Linux——zabbix
如何上传一个已有的Android项目到Gerrit
2101. 引爆最多的炸弹;752. 打开转盘锁;1234. 替换子串得到平衡字符串
ceres解析导数(Analytic Derivatives)进阶
Android基础第一天 | 字节跳动第四届青训营笔记
go exec.Command使用
论文写作笔记
python 之 矩阵相关操作
unity【动画】操作_角色动画控制器 c#
安装angular脚手架
- 原文地址:https://blog.csdn.net/weixin_48015656/article/details/126492136
