一、背景
部门成立专项组,对数智平台和站务系统做性能优化,其中目标之一为降低服务端硬件成本,即在32G内存、CPU银牌的配置下,能支撑1万+发客量。要达到此目标,需通过压力测试并配合监控系统,以QPS、RPS、接口响应时间、接口成功率、SQL耗时、JVM运行情况、CPU和内存运行情况等数据指标为依据,找出系统中存在的性能瓶颈。
二、压测准备工作
1、测试服务器
1.1、准备一台测试服务器,配置如下:
| 硬件类型 | 硬件配置 | 备注 |
|---|---|---|
| CPU | i5-9400 CPU @ 2.90GHz @ 6 Core 6 Thread | 普通办公电脑 |
| 内存 | DIMM DDR4 @ 16G 2400Mhz + 8G 2400Mhz | --- |
| 硬盘 | KINGSTON SA400M8 SSD 240G | 性能优于机械硬盘50% |
| 网卡 | RTL8111/8168/8411 PCI Express Gigabit Ethernet Controller | --- |
1.2、准备千兆交换机
因压力机的网卡为100M,当请求超过100user后数据量超过压力机带宽限制,压测数据突发提升,因此更换千兆交换机。
2、CAT监控
为了在压测过程中,实时监控业务系统运行情况,采用了目前中心系统已成熟使用的cat监控,其原理是通过埋点数据上送,并生成各类可视化报表,可监控的指标包括JVM、接口、SQL、异常告警等。
cat官方地址:https://github.com/dianping/cat
三、压测关键过程
1、第一次压测情况
| 用户数 | QPS | 压测情况说明 | 出票量 |
|---|---|---|---|
| 10 | 33 | CPU80%,tomcatA占用15%;影响正常业务 | 10分钟/3540张 |
| 20 | 27 | CPU80%,tomcatA占用15%;影响正常业务 | 10分钟/4440张 |
CPU负载情况:

通过以上数据可以看出,在10个并发请求情况下,CPU基本打满,业务系统已无法正常运行。提升到20个并发请求后,QPS不增返降,说明系统已无法支撑更多请求。
2、数智平台性能排查及解决过程
2.1、接口缓存
- 以上数据显示,站务系统tomcatA仅占用了15%的CPU,需要找到其他65%消耗在哪。
- 通过top命令发现station-base占用CPU超过tomcatA,按照业务复杂度划分来看,及其不合理,于是需要找出station-base占用高的原因。
- 首先,找到station-base的进程ID:ps -ef | grep station-base

- 再查看进程ID找到占用高的线程ID:top -Hp 1061
- 再根据线程ID找到具体堆栈信息
线程ID转化为16进制(TID):printf "%x\n" TID;
JVM堆栈中查找线程信息:jstack PID | grep TID -A100;- 发现较多线程在执行以下两个接口,但未做缓存:
/base/openApi/line/getAllLineDownSiteBySiteNos
/base/openApi/line/getStationLineByLineNo
2.2、网关优化
2.2.1、spring gateway向/tmp文件夹创建大量临时文件夹,导致/tmp目录卡死
- 使用jstack命令查看吃cpu的线程运行情况如下图:
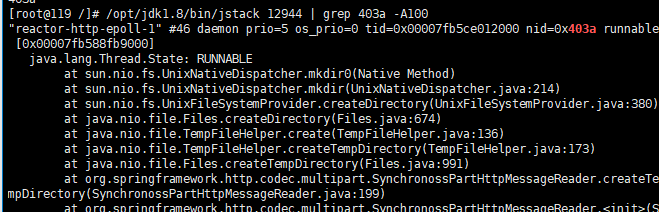
- 登录服务器查看/tmp目录大小,发现存在大量临时文件,乃至ls /tmp 命令卡死

- 执行rm -rf /tmp情况文件夹,因文件夹太多无法删除,因此更换删除命令find . -name "*" -print | xargs rm -rf,10秒清空文件夹。
- 查看相关资料及源码后,确认数智平台当前使用的Hoxton.SR12(依赖的spring-web 5.2.15版本)版本存在此类问题:
-官网证实链接1:https://github.com/spring-projects/spring-framework/issues/27094
-官网证实链接2:https://github.com/spring-projects/spring-framework/issues/27092

- 解决措施:将spring-web 5.2.15升级到5.2.16
2.2.2、自定义过滤器代码本身问题排除
- 因gateway需要对请求和响应进行参数重新包装,故需要自定义过滤器,分别是请求过滤器(ModifyRequestGatewayFilterFactory)和响应过滤器(ModifyResponseGatewayFilterFactory)进行拦截处理,为避免网关响应时间受自定义过滤器的影响,直接将过滤器取消,对spring cloud gateway原生代码进行请求压测,经实测后,性能并为明显提升,可以排除自定义过滤器的问题。
2.2.3、Reactor(netty)工作线程组及epoll请求处理线程配置

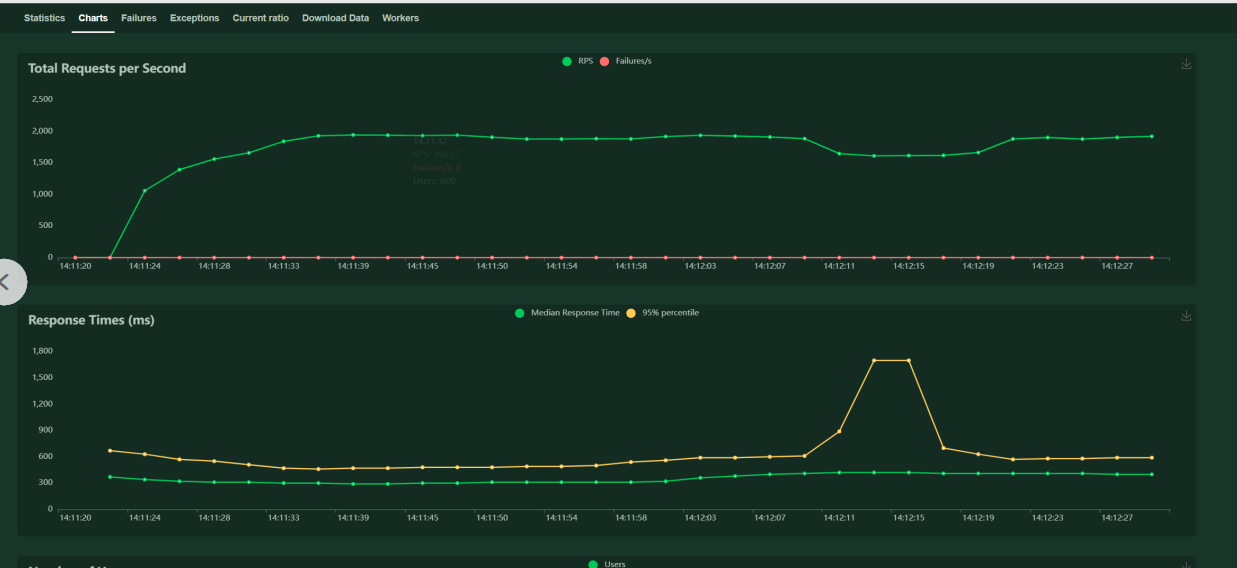
但从接口的平均响应时间来看,依然在500ms左右。于是通过资料查找,怀疑为netty问题,netty源码的配置为:
DEFAULT_IO_WORKER_COUNT:如果环境变量有设置reactor.ipc.netty.workerCount,则用该值;没有设置则取Math.max(Runtime.getRuntime().availableProcessors(), 4)))
DEFAULT_IO_SELECT_COUNT:如果环境变量有设置reactor.ipc.netty.selectCount,则用该值;没有设置则取-1,表示没有selector thread
默认配置下,通过artha可以看出Reactor-http-epoll处理线程如下图:

可以看出,netty框架默认情况下,按测试服务器配置,工作线程为6且未使用selector线程组。于是增加以下环境变量:
@Bean
public ReactorResourceFactory reactorClientResourceFactory() {
// 配置线程组
System.setProperty("reactor.netty.ioSelectCount","1");
// 这里工作线程数为2-4倍都可以。看具体情况
int ioWorkerCount = Math.max(Runtime.getRuntime().availableProcessors()*3, 4));
System.setProperty("reactor.netty.ioWorkerCount",String.valueOf(ioWorkerCount);
return new ReactorResourceFactory();
}
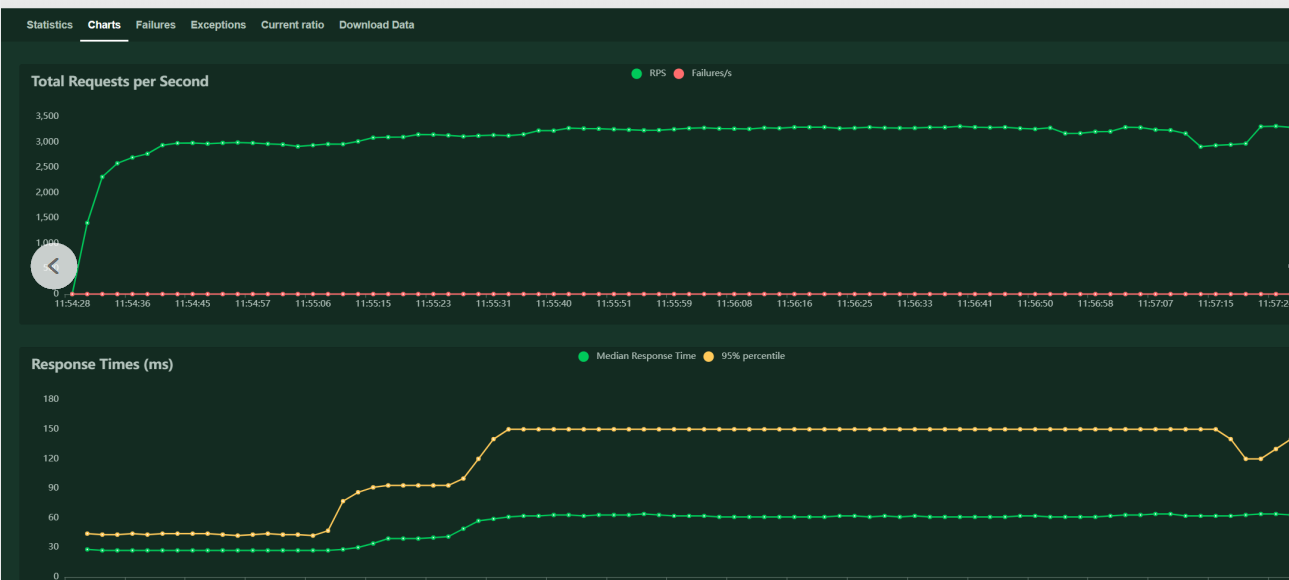
再次通过arthas可以看出Reactor-http-epoll处理线程如下图:

配置完成后,再次压测,RPS达到3300,平均响应时间降低到150ms以内
2.2.4、logback同步写日志改为异步
通过cpu火焰图发现在处理大量请求时,自定义的sql打印插件频繁的输出sql语句,而且logback在默认情况下采用同步写日志,而同步阻塞写,会拖慢业务方法执行速度,下图是将logback改成异步的配置

2.2.5、网关优化总结
- 1、自定义过滤器本身问题排除
- 2、使用centos系统提供的一些硬件资源命令来分析高消耗cpu或者io线程,使用查此线程在jvm中的运行详情以此来寻找问题解决方向
- 3、分析jvm中的线程来判断定位可能出问题的代码(比如2.2.1)
- 4、通过关键信息寻找问题原因或解决方案(最好是来自官网或者github官方仓库的issues)
- 5、透过现象看本质,通过各种辅助工具或命令来排查cpu和io高占用的线程,以此数据作为解决问题的基础支撑
3、站务系统性能排查及解决过程
3.1 全局filter校验token未做缓存
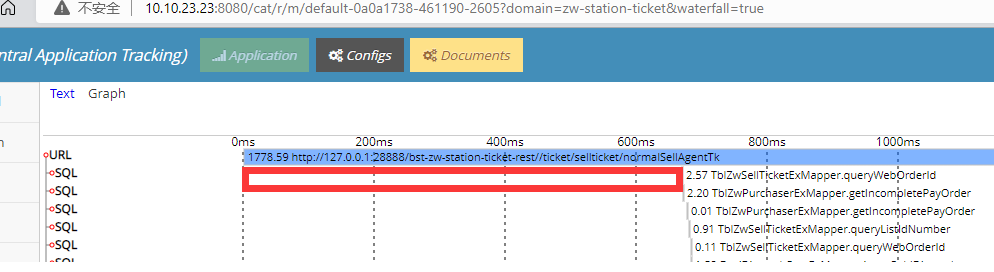
通过链路监控发现,zw-station-ticket模块在接收到购票请求到第一次执行SQL查询之间,有大约600ms损耗。通过查看代码发现,可能是因为全局token校验接口未做缓存导致。优化完成后查看监控数据,token校验耗时正常。
3.2 Transaction注解问题

再次压测,观测调用链路,仍然发现在进入购票接口后,有时间损耗,通过排查代码发现,在购票和锁票方法上面有@Transaction注解,时间损耗的可能原因是:
当 Spring 遇到该注解时,会自动从数据库连接池中获取 connection,并开启事务然后绑定到 ThreadLocal 上,对于@Transactional注解包裹的整个方法都是使用同一个connection连接 。如果我们出现了耗时的操作,比如第三方接口调用,业务逻辑复杂,大批量数据处理等就会导致我们我们占用这个connection的时间会很长,数据库连接一直被占用不释放。
因此去掉事务注解后,再次观测数据,空白时间损耗问题解决。
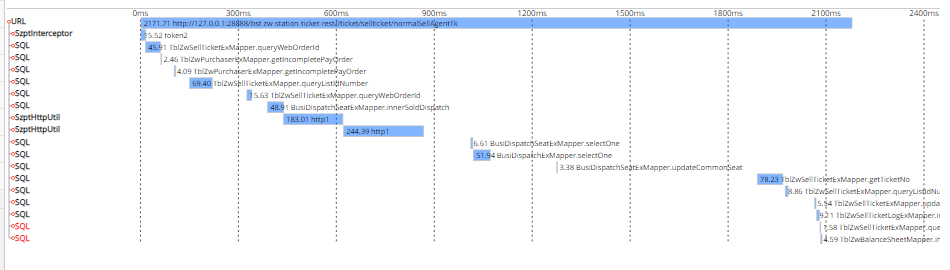
后续解决思路:对事务方法进行拆分,尽量让事务变小,变快,减小事务的颗粒度。否则,可能出现:
- 数据库连接池被占满,应用无法获取连接资源;
- 容易引发数据库死锁;
- 数据库回滚时间长;
- 在主从架构中会导致主从延时变大。
3.3 logback日志问题
通过以上方式优化完成后,发现tomcatA模块依然占用比较大的CPU,在150%-300%之间。于是,准备通过async-profiler工具,查看耗CPU的详细堆栈信息。
- 第一步,下载async-profiler-2.8.3-linux-x64.tar.gz,并解压
- 第二步,执行数据采集命令,生成CPU运行火焰图:./profiler.sh -d 60 -f ./nacos.html PID

通过火焰图发现,基本所有CPU都在执行logback日志打印。
于是,对logback配置文件进行优化:
- 去掉控制台打印
- 改为异步合并写日志

优化完成后再次压测,RPS由原23.7提高到222;平均响应时间由原1447ms降低为1082ms;
优化前:

优化后:

4、其他优化
- 为减少CPU消耗,JVM垃圾收集器由CMS改为G1