-
NeuralProphet之七:NeuralProphet + Optuna
时间序列论文: NeuralProphet: Explainable Forecasting at Scale
NeuralProphet之一:安装与使用
NeuralProphet之二:季节性(Seasonality)
NeuralProphet之三:回归(Regressors)
NeuralProphet之四:事件(Events)
NeuralProphet之五:多时序预测模型
NeuralProphet之六:多元时间序列预测
NeuralProphet之七:NeuralProphet + Optuna
NeuralProphet之八:NeuralProphet部署
NeuralProphet官方示例一:建筑物用电量预测(Building load forecasting)
NeuralProphet官方示例二:日照辐射强度预测(Forecasting hourly solar irradiance)NeuralProphet之七:NeuralProphet + Optuna
数据来自真实园区数据,
训练集为2022年8月01日到2022年8月14日园区的耗电量,每隔5分钟采集一次;
测试集为2022年8月15日到2022年8月21日园区的耗电量,每隔5分钟采集一次;
要求:预测接下来1H的耗电量。代码和数据地址:https://github.com/shanglianlm0525/TimeSeries
导入库
from copy import deepcopy import optuna import pandas as pd import matplotlib.pyplot as plt from neuralprophet import NeuralProphet, set_log_level set_log_level("ERROR")- 1
- 2
- 3
- 4
- 5
- 6
导入数据
df_train = pd.read_csv("shenghuoqu0815.csv") df_test = pd.read_csv("shenghuoqu0821.csv") print(df_train.info()) print(df_test.info())- 1
- 2
- 3
- 4
1 Baseline
n_lags = 12 n_forecasts=12*1 # n_lags = n_lags,n_forecasts= n_forecasts, # changepoints_range=0.85, n_changepoints=20, m = NeuralProphet(n_lags = n_lags,n_forecasts= n_forecasts, yearly_seasonality=False, weekly_seasonality=False, daily_seasonality=True, normalize='minmax') metrics = m.fit(df_train, freq='5min') forecast_train = m.predict(df_train) forecast_test = m.predict(df_test) fig = m.plot(forecast_train) fig = m.plot(forecast_test) fig_param = m.plot_parameters()- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
训练集测试结果:
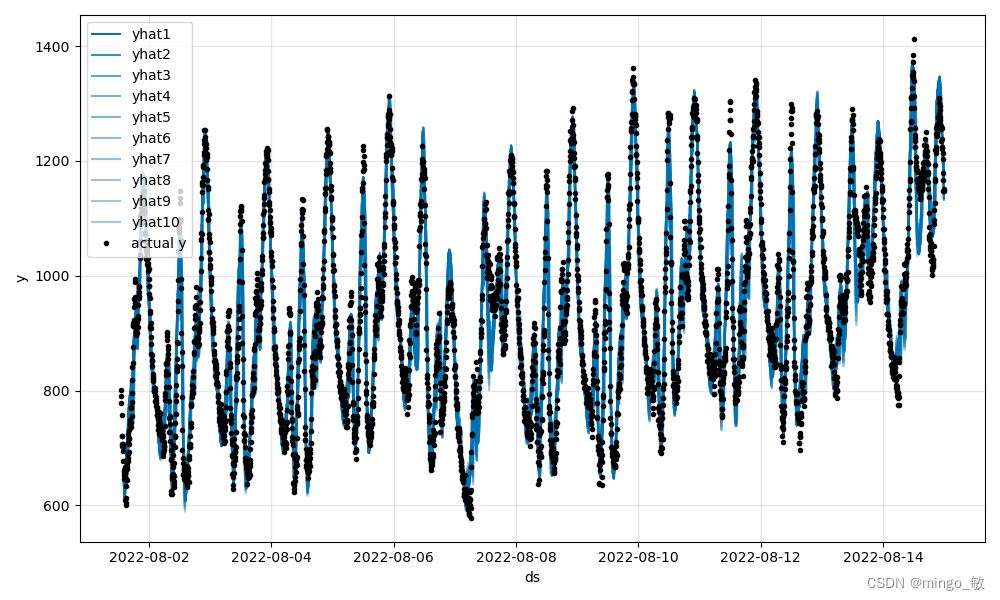
测试集测试结果:
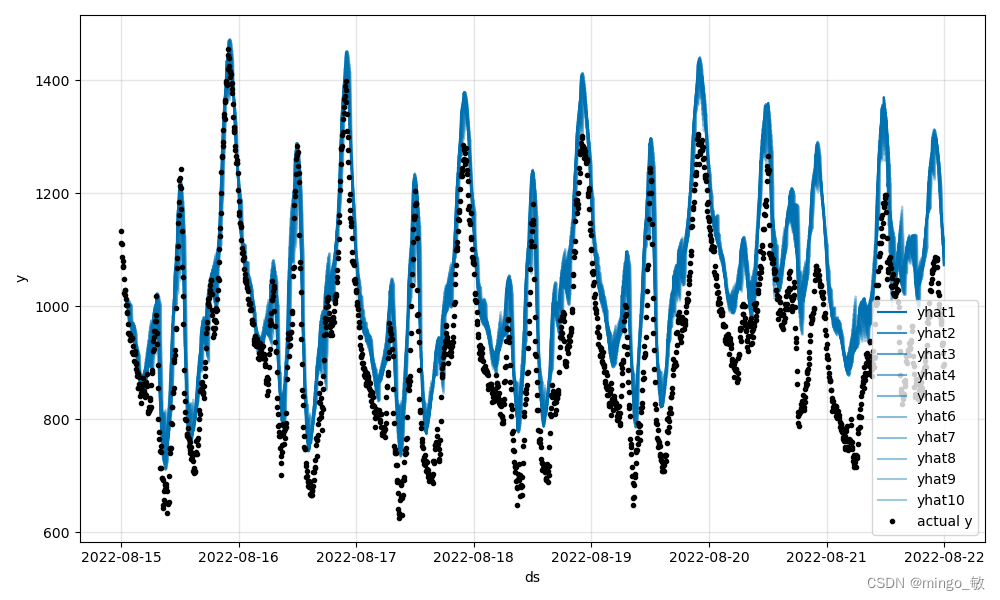
参数可视化:
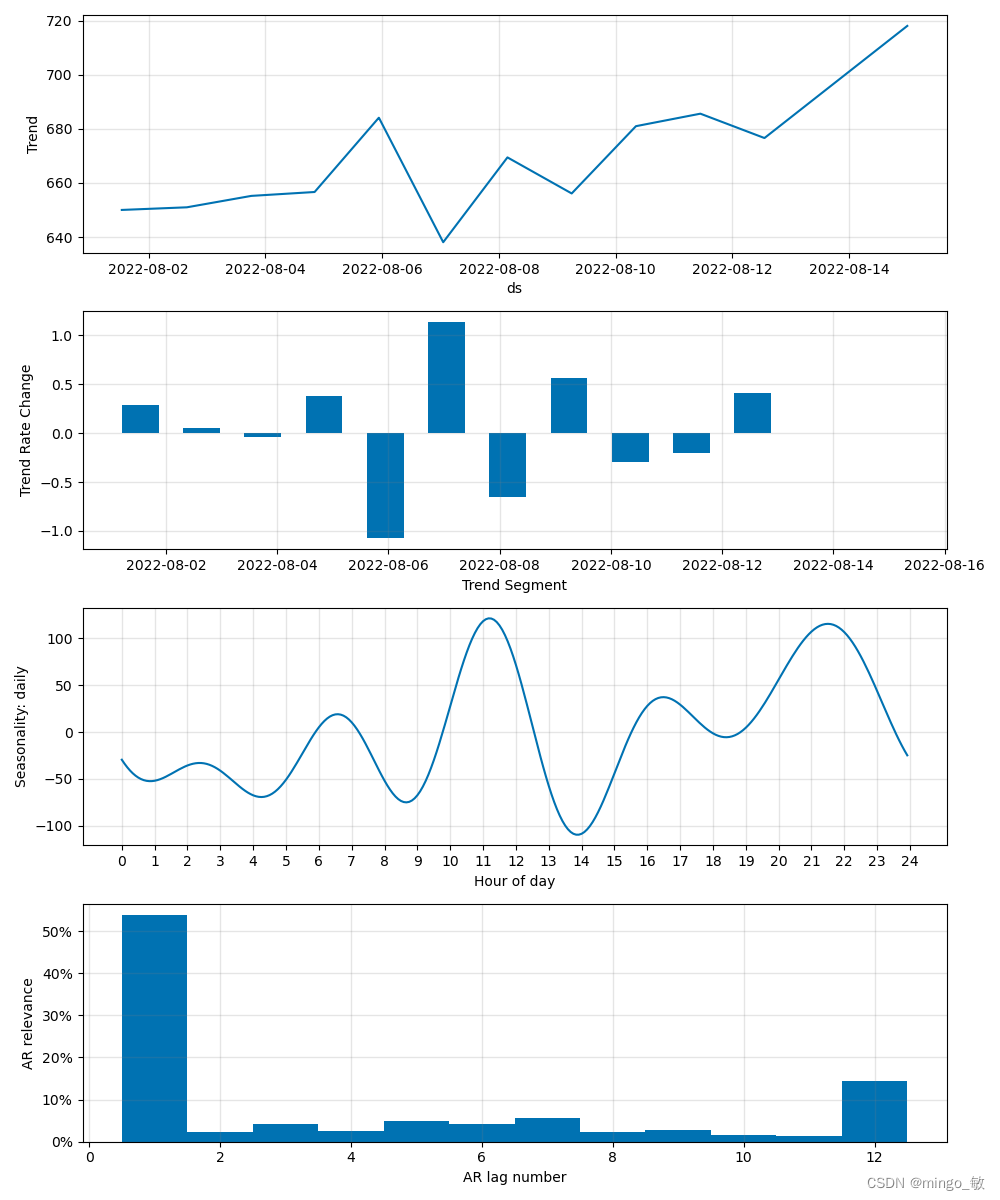
2 加入Optuna
定义Optuna参数的搜索范围
default_para = dict(n_lags = n_lags,n_forecasts= n_forecasts,changepoints_range=0.8,n_changepoints=5, trend_reg=0.1,normalize='minmax',learning_rate =1) param_types = dict(changepoints_range='float',n_changepoints='int',trend_reg='float',learning_rate='float',month_order = 'int',week_order ='int') bounds = {'changepoints_range': [0.6,0.8,0.9], 'n_changepoints': [4, 8], 'trend_reg': [0.001, 1], 'learning_rate': [0.001, 1], 'day_order': [1, 7], }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
定义搜索空间
def create_nph(**para): temp_para = deepcopy(para) day_order = temp_para.pop('day_order') m = NeuralProphet(**temp_para) m = m.add_seasonality('my_day', 24, day_order) return m def nph_warper(trial,ts): params = {} params['changepoints_range'] = trial.suggest_categorical('changepoints_range', bounds['changepoints_range']) params['n_changepoints'] = trial.suggest_int('n_changepoints', bounds['n_changepoints'][0], bounds['n_changepoints'][1]) params['trend_reg'] = trial.suggest_loguniform('trend_reg', bounds['trend_reg'][0], bounds['trend_reg'][1]) params['learning_rate'] = trial.suggest_loguniform('learning_rate', bounds['learning_rate'][0], bounds['learning_rate'][1]) params['day_order'] = trial.suggest_int('day_order', bounds['day_order'][0], bounds['day_order'][1]) temp_para = deepcopy(default_para) temp_para.update(params) METRICS = ['SmoothL1Loss', 'MAE', 'RMSE'] metrics_test = pd.DataFrame(columns=METRICS) m = create_nph(**temp_para) folds = m.crossvalidation_split_df(ts, freq="H", k=5, fold_pct=0.2, fold_overlap_pct=0.5) for df_train, df_test in folds: m = create_nph(**temp_para) train = m.fit(df_train) test = m.test(df=df_test) metrics_test = metrics_test.append(test[METRICS].iloc[-1]) out = metrics_test['MAE'].mean() return out- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
定义objective 函数(目标函数)
def objective(trial): ts = df_train.copy() #select column associated with region return nph_warper(trial,ts)- 1
- 2
- 3
Optuna 调优
study = optuna.create_study(direction='minimize',study_name='nph_tuning', load_if_exists=True, storage="sqlite:///nph.db") study.optimize(objective, n_trials=5) print(study.best_trial) print(study.best_params)- 1
- 2
- 3
- 4
FrozenTrial(number=3, values=[157.7605354309082], datetime_start=datetime.datetime(2022, 8, 22, 18, 48, 27, 661116), datetime_complete=datetime.datetime(2022, 8, 22, 18, 49, 17, 188990), params={‘changepoints_range’: 0.6, ‘day_order’: 1, ‘learning_rate’: 0.005463461412824059, ‘n_changepoints’: 7, ‘trend_reg’: 0.006287378033976726}, distributions={‘changepoints_range’: CategoricalDistribution(choices=(0.6, 0.8, 0.9)), ‘day_order’: IntUniformDistribution(high=7, low=1, step=1), ‘learning_rate’: LogUniformDistribution(high=1.0, low=0.001), ‘n_changepoints’: IntUniformDistribution(high=8, low=4, step=1), ‘trend_reg’: LogUniformDistribution(high=1.0, low=0.001)}, user_attrs={}, system_attrs={}, intermediate_values={}, trial_id=15, state=TrialState.COMPLETE, value=None)
{‘changepoints_range’: 0.6, ‘day_order’: 1, ‘learning_rate’: 0.005463461412824059, ‘n_changepoints’: 7, ‘trend_reg’: 0.006287378033976726}根据最优参数构建NeuralProphet
best_para = deepcopy(default_para) best_para.update(study.best_params) m = create_nph(**best_para)- 1
- 2
- 3
- 4
训练和预测
metrics = m.fit(df_train, freq='5min') forecast_train = m.predict(df_train, decompose=False) forecast_test = m.predict(df_test, decompose=False) fig = m.plot(forecast_train) fig = m.plot(forecast_test) fig_param = m.plot_parameters()- 1
- 2
- 3
- 4
- 5
- 6
- 7
明显可以看出,Optuna找到的参数在测试集上效果更好。
训练集测试结果:
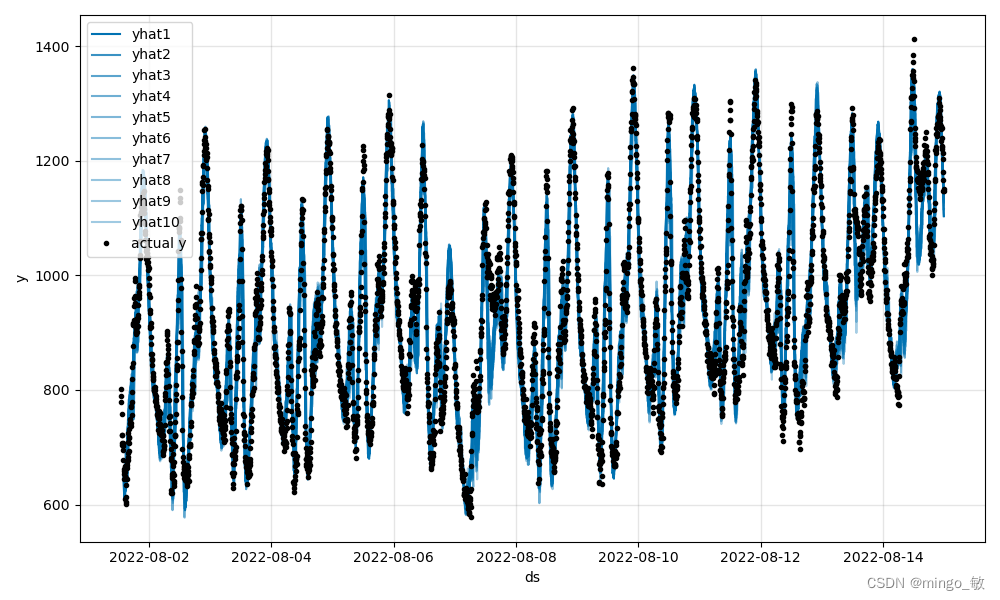
测试集测试结果:
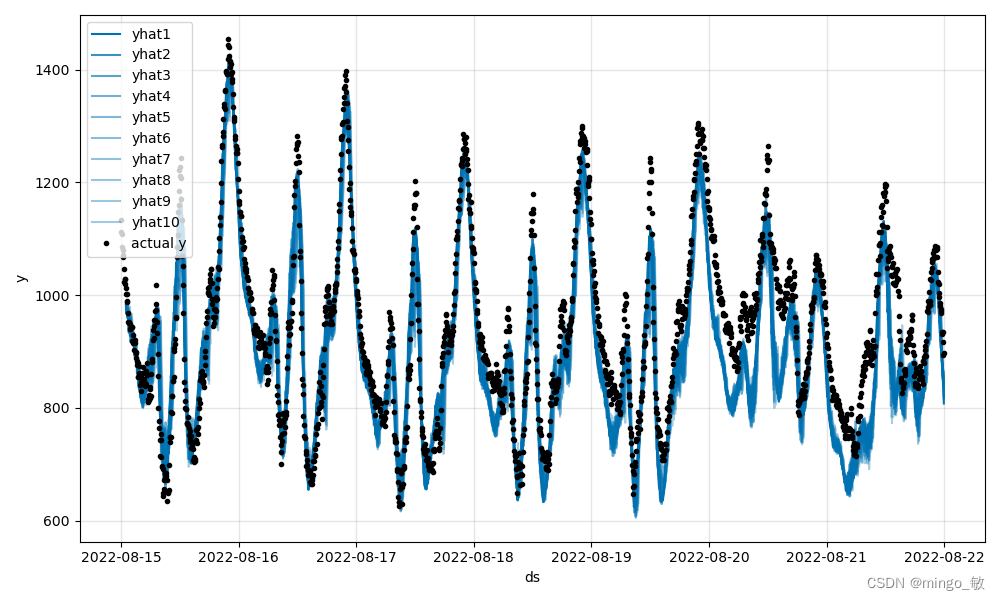
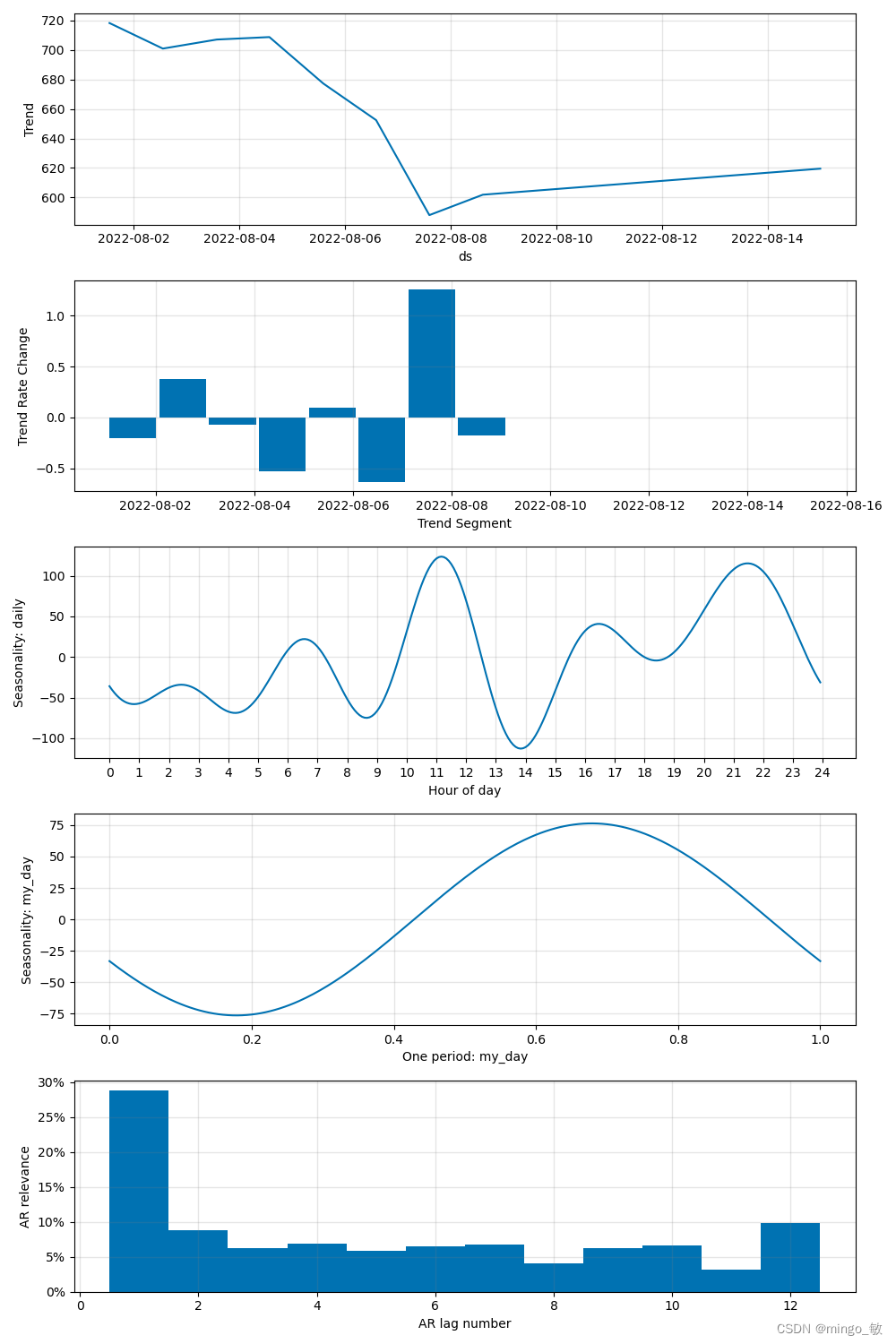
参数可视化:
-
相关阅读:
第7篇 vue的模块化与babel的转换
腾讯叶聪:朋友圈爆款背后的计算机视觉技术与应用
浅谈C++|STL之list+forward_list篇
顶层设计:who适合且能够当大学校长
(王道考研计算机网络)第四章网络层-第二节:路由算法与路由协议概述
快速搭建本地的chatgpt
web自动化测试-webdriver实现
硬件描述语言(HDL)基础——过程块
-贪吃蛇-
CiscoCUCM配置网关协议
- 原文地址:https://blog.csdn.net/shanglianlm/article/details/126473163
