-
LoadRunner下载与安装
本文来介绍一下笔者
安装与使用LoadRunner的过程。笔者安装过程参考的教程:LoadRunner2020下载、安装步骤和简单使用
下载链接
- 打开官网:https://my.microfocus.com/myproducts
- 填写一下注册信息
- 注册完成后,邮箱中会给一个链接,跳转到如下界面
【专业版试用一年,嗯……还可以,先用着】

在跳转页面里点击download

安装
- 双击
.exe文件,出现如下界面:

- 选择想要安装的路径(注意:
目录名建议全英文),点击next等待安装即可。 - 出现如下界面,点
确定


- 选择
LoadRunner,点确定

- 全部勾选,然后
next

- 更换成自己的目录(可以保持默认目录),
下一步

安装


- 安装完成
Virtual User Genertor:开发性能测试脚本
Controller:提供多线程并发操作
Analysis:结果分析
[可选项]Load Generator:负载生成器

使用VUGen
- 右键
virtual User Generator,以管理员身份运行

- 新建脚本,
create

- 创建完成(默认使用
C语言)

- 录制

抓取的脚本为空

- 解决办法:
安装并打开fiddler,然后重新打开VUGen(virtual User Generator)录制。
解决乱码问题
GB-X:2byte=16bit, 65535组合,0000 0000 0000 0000 ~ 1111 1111 1111 1111
UTF-8:3byte = 24bit, 2^24, 16777216种组合,对全世界的文字进行统一编码。
ASCII码只会占用1个字节1.
录制过程中乱码解决- 更改设置

举例:
更改设置后重新录制- 评论

- 对应的录制结果

2.
运行过程中乱码解决- 更改设置


参数化
- 更改设置

- 添加参数

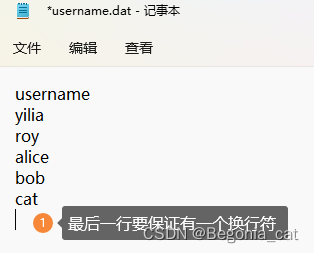
保存并关闭记事本文件后,发现添加成功。

添加列

两列之间用逗号间隔

- 第一行数据(选择第
n行作为第一行)


参数要用
{}括起来lr_eval_string("{...}")- 定义参数分隔符:
- 定义参数
random

设置运行次数(注意:要把action从Run Logic Tree中删掉)

code
result

- 建议用
unique number
事务
- 插入事务的
开始与结束代码脚本

- 插入之后如图:

passed transcation通过的事务failed transcation失败的事务LR_AUTO是根据响应的状态码来判断事务是否成功,没有深入到业务逻辑层面,所以,这种方式统计事务是否成功是不准确的。所以需要引入检查点。Duration:事务持续时间Wasted time:事务执行时浪费的时间(思考时间)
检查点
检查点单独使用没有意义,要和事务结合起来使用。- 检查点函数
web_reg_find,从响应当中查找特定内容、特定标识,来决定请求是否成功提交。
思考时间
什么是思考时间?
- 用户用于思考的时间——
没有对服务器施加压力的时间
即:用户暂停发送请求的时间
为什么需要思考时间?
- 模拟真实场景
思考时间函数
lr_think_time(秒);
思考时间在LR中的应用
- 思考时间应该不一样(真实使用时,不同用户的思考时间不一样)
- 不能设置得太长(尽可能对系统有更严格的要求)
集合点
-
适用场景:并发测试(主要关注大量用户并发的时候)
- 所有用户都在
发请求 - 所有用户都在
提交同一个请求
- 所有用户都在
-
模拟真实场景
- 集合点
不能模拟真实场景 - 集合点用于发现
系统的瓶颈,是压力测试的一个子集- 负载测试:评估性能指标(真实场景)
- 并发测试、压力测试:相对严格的并发。压力测试不需要思考时间。
- 并发处理能力:海量用户使用系统,在系统不崩溃的情况下,能够支撑多少人同时使用。
- 稳定性测试:长时间,标准用户数
- 最佳用户
【处于比较好的利用率,但又没有到达瓶颈。如:3/4】:系统处于最佳状态 - 最大用户数:某一指标出现极限
- 最佳用户
- 容量测试:模拟系统长时间运行后的性能状态(如:关系型数据库,有1亿条记录)
- 集合点
-
插入
集合点脚本

-
注意:
集合点要放在事务的外面,否则,事务会统计集合点的等待时间。

如图所示是集合点的等待时间:

使用Controller
全自动的功能不要用,使用价值很低。
不建议把所有脚本放在一起做性能测试。
做性能测试时,尽可能评估最少的模块,用户使用频率最高的模块。

-
控制性能测试场景

RAMP UP和RAMP DOWN应遵循的原则:- 越慢越好(太快的话,收集到的数据跨度太大,Analysis时趋势不准确);
- 平衡好运行时间。
-
控制性能测试场景的难点在于:
- 到底
并发多少用户是合理的。 多少时间Duration是合理的。
- 到底
负载生成器

输入IP地址:

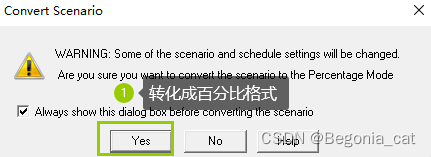
Scenario -> Convert Scenario
监控指标
windows指标:



Analysis
把学习资料当成字典!我们没有必要去背字典,我们需要掌握查字典的方法,需要的时候会用就行。
结果分析时,用得最多的是
关联分析(将多个图表放在一起对比查看)

前端性能指标
从用户角度感受到的性能指标
- 响应时间(response time)
- 从用户体验角度:快不快
- 一个请求从用户发起 到收到服务器响应 所需要的时间
- 页面:打开响应的时间
- 具体单个资源的响应时间(html、css)
- 响应的吞吐率:每秒钟服务器的响应的大小。
- 服务器带宽
- 客户端带宽(响应时间/用户数量)
- 1字节 = 8bit。1M网络带宽
- 吞吐量
- TPS(每秒钟处理的事务数)
- TPM(每分钟处理的事务数)
- TPH(每小时处理的事务数)😊😂🤣
- HPS(每秒点击数),作用不大,用于评估客户端发请求的频率。取决于用户数量和服务器处理速度。
- QPS(每秒处理的请求query数)
- TPS(每秒钟处理的事务数)
后端性能指标
- CPU
- CPU使用率
%Processor Time - 处理器队列长度
Processor Queue Length 2*内核数 - 处理频率,内核数量,一级缓存,二级缓存,三级缓存的大小
- CPU使用率
- 带宽
- 每秒
接收的数据量,低于下行带宽/8 - 每秒
发送的数据量,低于上行带宽/8
- 每秒
- 内存
- 内存使用率(或:可用内存数(M))
- 内存的页交换频率
page/sec,越低越好页是内存的管理单位- 页交换:内存和硬盘之间的数据交换
- 缓存(处理速度:内存>硬盘>网络):
- 进行
系统级性能优化的时候:重点利用缓存,可以提升不少性能。 - 进行
代码级性能优化的时候:SQL语句,算法(减少内存,用好内存,减少运算次数【减少CPU消耗】)
- 进行
- 虚拟内存:利用一块
硬盘区域模拟内存模块- 硬盘便宜,容量大。内存比硬盘贵100倍,内存的速度比硬盘快100倍。
- 硬盘直接读写,对硬盘的伤害是很大的。所以要利用好缓存,利用好内存。
- 磁盘 I/O
- 硬盘使用率
- 硬盘队列长度
- 硬盘自身带有缓存:16M,32M;固态硬盘:512M,1G
- 线程池
线程:主要消耗的是CPU资源。CPU资源是有限的。- 内存满了,系统会直接崩溃
- CPU满了,系统不会崩溃,只不过要排队等待
多线程- 下载软件:多线程
- CPU:多核多线程
- 边听歌曲,边上网,边聊天,边工作
- 分布式应用服务器:多线程,每个线程负责一个用户请求
- 数据库:多线程,每个线程处理一个SQL请求
线程池:本质上还是线程。是用于管理多线程的一种机制- 动态影响
- Q:
响应时间RT为3秒,60秒时间内可以发送20个。问:每发一个帖子后,暂停2秒,请问60秒可以发几个帖子? - A:理解动态影响。当暂停2秒时,对服务器的压力变小,服务器得到休息。因此,
动态影响到响应时间RT,此时,响应时间可能会减小,比如RT=2.5秒。因此,这种情况下所能发的帖子数量是大于12个。 - Q:三层架构:
C-S-D:瓶颈可能出现在任意一层。问:S端线程数量是100,调整成1000个,可以吗? - A:要考虑到
服务器的硬件资源(主要是CPU)所能承受的相对合理的指标。- 如果线程量设置很大,而服务器又没有办法支撑这么多,导致响应很慢,这样用户体验也不好。因此,还不如让线程先排队等候,不要并发运行那么多线程。
- Q:假设修改为1000个线程,
服务器可以支撑,这时没有其他的问题? - A:要测试
数据库能处理的量。- 只有当CPU/内存/硬盘、服务器传输过程中的带宽、数据库达到一个平衡点,处于最佳状态时,用户并发访问的线程数量才是被允许的,才是合理的。
- Q:
性能测试方案
性能测试顺序:
设计方案、开发脚本、执行场景、结果分析、测试报告
网上找到的并发用户的计算方法是错误的,无任何参考价值。Discuz和Phpwind性能对比:
测试目标: -
相关阅读:
工业互联网与智能控制
hive统计页面停留时间
【图像检测】基于K-L实现人脸检测附matlab代码
Redis从入门到放弃(2):数据类型
Word格式处理控件Aspose.Words for .NET教程——使用DOM插入字段
利用grafana展示Zabbix数据可视化
Docker-基本了解
《机器人学一(Robotics(1))》_台大林沛群 第 5 周【机械手臂 轨迹规划】 Quiz 5
cuda编程基础:基于cuda的简单加法和基于cuda的矩阵相加算法实现,以及对应的cpu实现对比
【C语言】空指针&野指针学习小结
- 原文地址:https://blog.csdn.net/qq_44250700/article/details/126470951