-
Machine learning week 5(Andrew Ng)
Neural network training
1、Neural network training

- Binary cross entropy, which we’ve also referred to as logistic loss, is used for classifying between two classes (two categories).
2、Activation Functions
Some examples:

For the output layer:

For the hidden layer:
When the curve is too flat, the gradient descent is slow, so the relu is more commonly used by people
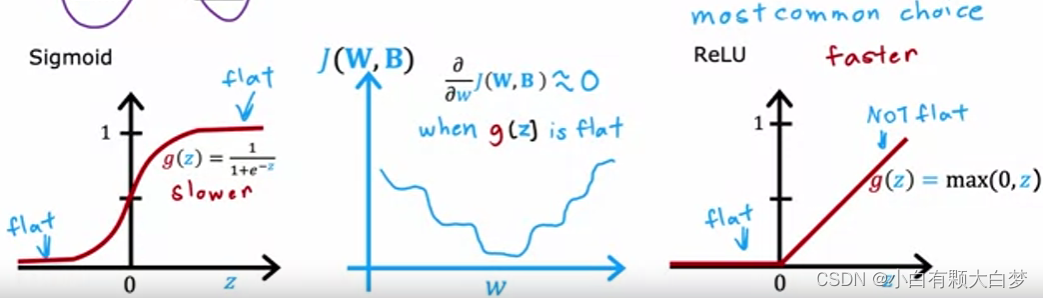
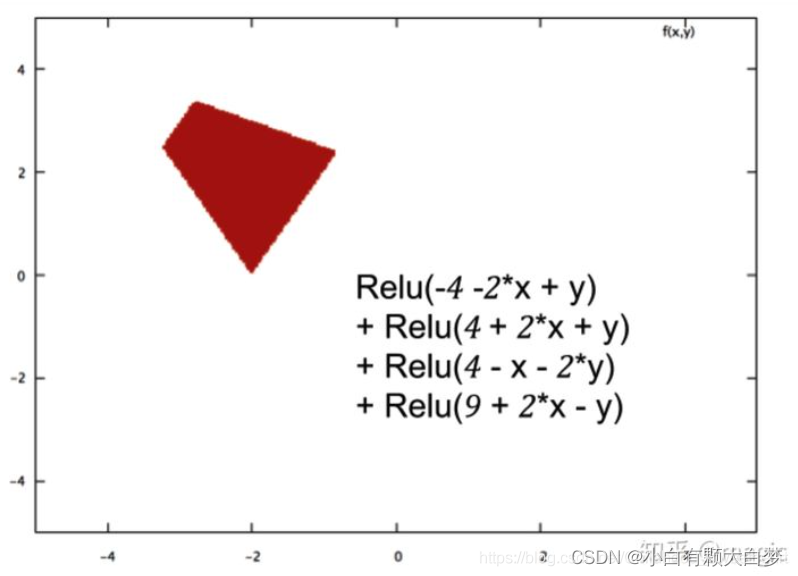
ReLU is a Non-Linear activation. When z z z is equal to zero, w x + b wx+b wx+b equals zero, so x x x is not necessarily equal to zero.RELU
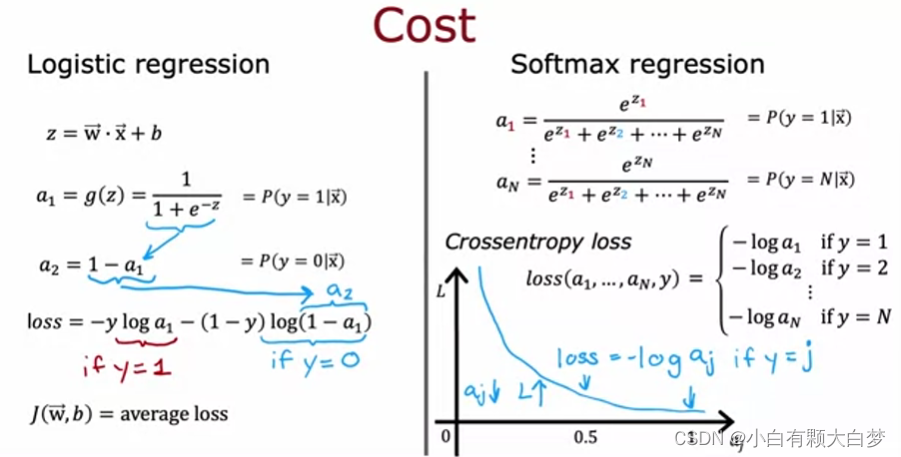
3、Multiclass classification
3.1、Softmax

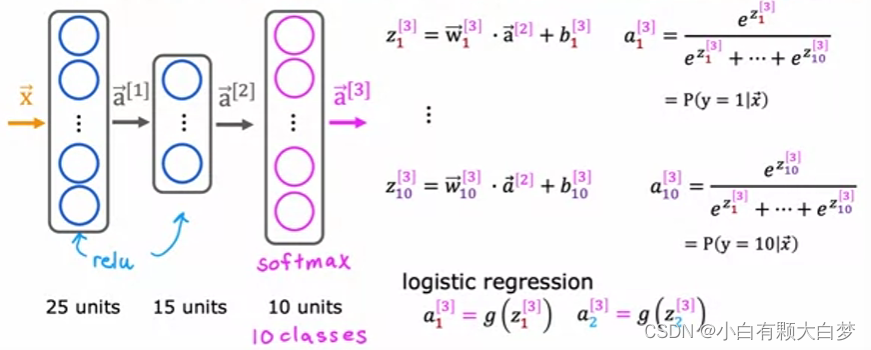
3.2、Neural networks with softmax output
Change the output layer from 1 unit to 10 units.

3.3、Improved implementation of softmax
When we calculate 1 plus 1/10000 minus 1 minus 1/10000, it will be equal to 2/10000 after we simplify it. But the result in the jupyter notebook is 0.000199999999999978. There’s some round-off error. Because the computer has only a finite amount of memory to store each number, called a floating-point number in this case.
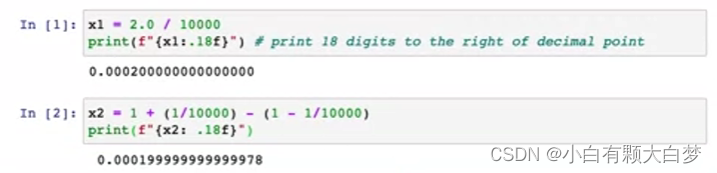
Tensorflow calculates Z as an intermediate value, but it can rearrange the items to make it more accurate.

The origin code
import numpy as np import matplotlib.pyplot as plt plt.style.use('./deeplearning.mplstyle') import tensorflow as tf from tensorflow.keras.models import Sequential from tensorflow.keras.layers import Dense from IPython.display import display, Markdown, Latex from sklearn.datasets import make_blobs %matplotlib widget from matplotlib.widgets import Slider from lab_utils_common import dlc from lab_utils_softmax import plt_softmax import logging logging.getLogger("tensorflow").setLevel(logging.ERROR) tf.autograph.set_verbosity(0) # make dataset for example centers = [[-5, 2], [-2, -2], [1, 2], [5, -2]] # use Scikit-Learn make_blobs function to make a training data set X_train, y_train = make_blobs(n_samples=2000, centers=centers, cluster_std=1.0,random_state=30) model = Sequential( [ Dense(25, activation = 'relu'), Dense(15, activation = 'relu'), Dense(4, activation = 'softmax') # < softmax activation here ] ) model.compile( loss=tf.keras.losses.SparseCategoricalCrossentropy(), optimizer=tf.keras.optimizers.Adam(0.001), ) model.fit( X_train,y_train, epochs=10 ) # Because the softmax is integrated into the output layer, the output is a vector of probabilities. p_nonpreferred = model.predict(X_train) print(p_nonpreferred [:2]) print("largest value", np.max(p_nonpreferred), "smallest value", np.min(p_nonpreferred)) # result:[[5.48e-03 3.50e-03 9.81e-01 9.70e-03] # [9.95e-01 4.42e-03 1.05e-04 7.80e-05]] # largest value 0.9999962 smallest value 1.6942051e-08- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
After improvement
preferred_model = Sequential( [ Dense(25, activation = 'relu'), Dense(15, activation = 'relu'), Dense(4, activation = 'linear') #<-- Note ] ) preferred_model.compile( loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True), #<-- Note optimizer=tf.keras.optimizers.Adam(0.001), ) preferred_model.fit( X_train,y_train, epochs=10 ) p_preferred = preferred_model.predict(X_train) print(f"two example output vectors:\n {p_preferred[:2]}") print("largest value", np.max(p_preferred), "smallest value", np.min(p_preferred)) # result : # two example output vectors: # [[-0.74 -1.18 4.5 0.66] # [ 7.08 1.95 -0.59 -5.32]] #largest value 14.613606 smallest value -9.5557785 # The output predictions are not probabilities!!! sm_preferred = tf.nn.softmax(p_preferred).numpy() print(f"two example output vectors:\n {sm_preferred[:2]}") print("largest value", np.max(sm_preferred), "smallest value", np.min(sm_preferred)) # two example output vectors: # [[5.15e-03 3.33e-03 9.71e-01 2.10e-02] # [9.94e-01 5.91e-03 4.66e-04 4.09e-06]] # largest value 0.99999964 smallest value 3.1869094e-11 for i in range(5): print( f"{p_preferred[i]}, category: {np.argmax(p_preferred[i])}") # [-0.74 -1.18 4.5 0.66], category: 2 # [ 7.08 1.95 -0.59 -5.32], category: 0 # [ 5.1 1.88 -0.5 -4.23], category: 0 # [-2.13 4.49 -1.03 -1.53], category: 1 # [ 1.56 -1.9 6.59 -1.74], ctegory: 2- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
3.4、Adam algorithm

3.5、Convolutional layer
Each single neuron of the layer does not look at all the values of the input vector that is fed into that layer
-
相关阅读:
git 本地多个账号错乱问题解决
工厂方法演进
Codeforces Round #814 (Div. 2)(A~D)
〖Python 数据库开发实战 - Redis篇③〗- Mac系统下通过homebrew安装Redis数据库
从零开始利用MATLAB进行FPGA设计(七)用ADC采集信号教程2
面试官:项目中最大的风险是什么?
C语言每日一题(10):无人生还
《大数据之路:阿里巴巴大数据实践》-第1章 总述
mysql修改字符集
goland 2022 取消自动格式化代码
- 原文地址:https://blog.csdn.net/weixin_62012485/article/details/126342139
