-
机器学习sklearn——day02
随机森林
集成算法概述


森林控制基评估器重要参数

随机森林是非常具有代表性的Bagging集成算法,它的所有基评估器都是决策树
分类树组成的森林就叫做随机森林分类器,回归树所集成的森林就叫做随机森林回归器
参数 n_estimators

建立一片森林
1.. 导入我们需要的包
- %matplotlib inline #将数据导入matplotlib库中
- from sklearn.tree import DecisionTreeClassifier
- from sklearn.ensemble import RandomForestClassifier
- from sklearn.datasets import load_wine #datasets是可以生成各种数据的模块
2.导入需要的数据集
- wine = load_wine()
- wine.data.shape #红酒数据形状
- wine.target #红酒数据集标签
- #实例化
- #训练集带入实例化后的模型去进行训练,使用接口是fit
- #使用其他接口将测试集导入我们训练好的模型,去获取我们希望获取的结果(socre,Y_test)
sklearn建模的基本流程
- #导入库
- from sklearn.model_selection import train_test_split
- Xtrain, Xtest, Ytrain, Ytest = train_test_split(wine.data,wine.target,test_size=0.3)
- #实例化
- clf = DecisionTreeClassifier(random_state=0)
- rfc = RandomForestClassifier(random_state=0)
- #导入训练集训练
- clf = clf.fit(Xtrain,Ytrain)
- rfc = rfc.fit(Xtrain,Ytrain)
- #查看精确性
- score_c = clf.score(Xtest,Ytest)
- score_r = rfc.score(Xtest,Ytest)
- #打印结果
- print("Single Tree:{}".format(score_c)
- ,"Random Forest:{}".format(score_r)
- )
复习: “字符串{ }” . format:(此内容是换括号里的内容)
复习:交叉验证
- #交叉验证:是数据集划分为n分,依次取每一份做测试集,每n-1份做训练集,多次训练模型以观测模型稳定性的方法
- from sklearn.model_selection import cross_val_score
- import matplotlib.pyplot as plt
- rfc = RandomForestClassifier(n_estimators=25)
- rfc_s = cross_val_score(rfc,wine.data,wine.target,cv=10)
- clf = DecisionTreeClassifier()
- clf_s = cross_val_score(clf,wine.data,wine.target,cv=10)
- plt.plot(range(1,11),rfc_s,label = "RandomForest")
- plt.plot(range(1,11),clf_s,label = "Decision Tree")
- plt.legend()
- plt.show()
画出随机森林和决策树在十组交叉验证下的效果对比
- cfc_l = []
- clf_l = [] #建列表放数据
- for i in range(10):
- rfc = RandomForestClassifier(n_estimators=25)
- rfc_s = cross_val_score(rfc,wine.data,wine.target,cv=10).mean()
- rfc_l.append(rfc_s)
- clf = DecisionTreeClassifier()
- clf_s = cross_val_score(clf,wine.data,wine.target,cv=10).mean()
- clf_l.append(clf_s)
- plt.plot(range(1,11),rfc_l,label = "Random Forest")
- plt.plot(range(1,11),clf_l,label = "Decision Tree")
- plt.legend()
- plt.show()
随机森林的本质是一种装袋集成算法(bagging),装袋集成算法是对基评估器的预测结果进行平均或用多数表决 原则来决定集成评估器的结果。
random_state
的红酒例子中,我们建立了25棵树,对任何一个样本而言,平均或多数表决 原则下,当且仅当有13棵以上的树判断错误的时候,随机森林才会判断错误。单独一棵决策树对红酒数据集的分类 准确率在0.85上下浮动,假设一棵树判断错误的可能性为0.2(ε),那20棵树以上都判断错误的可能性是:
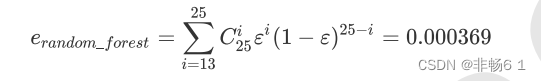
其中,i是判断错误的次数,也是判错的树的数量,ε是一棵树判断错误的概率,(1-ε)是判断正确的概率,共判对 25-i次。采用组合,是因为25棵树中,有任意i棵都判断错误。
- import numpy as np
- from scipy.special import comb
- np.array([comb(25,i)*(0.2**i)*((1-0.2)**(25-i)) for i in range(13,26)]).sum()
bootstrap & oob_score
bootstrap就是用来控制抽样技术的参数,bootstrap参数默认True,代表采用这种有放回的随机抽样技术,如果希望用袋外数据来测试,则需要在实例化时就将oob_score这个参数调整为True,训练完毕之后,我们可以用 随机森林的另一个重要属性:oob_score_来查看我们的在袋外数据上测试的结果
机器学习中调参的基本思想


-
相关阅读:
00后最关注程序员,超8成人接受灵活就业,视频UP主是最想从事的职业
【静态代码质量分析工具】上海道宁为您带来SonarSource/SonarQube下载、试用、教程
Python+AI给老照片上色
湖南软件测评公司简析:软件功能测试和非功能测试的联系和区别
深入理解指针(三)
实用的Visual Studio插件
android kotlin学习
湘江新区:金融活水赋能实体经济
VINS中的观测性问题
洛谷P1518 [USACO2.4]两只塔姆沃斯牛 The Tamworth Two
- 原文地址:https://blog.csdn.net/weixin_44267765/article/details/126429526
