-
循环神经网络
RNNs的神经元结构
循环神经网络(Recurrent Neural Networks)是一种可以用于预测的神经网络,它可以分析诸如股票价格之类的时序数据,并告诉你何时应该买入/卖出。同时也可以在自动驾驶系统中,预测车辆的行进轨迹,从而避免发生交通事故。与其他许多神经网络不同的是,RNNs对于输入的序列长度没有要求。也就是说,你可以将长短不一的参数序列传入RNNs,比如任意一篇文章,或者任意一段音频的采样。这也是RNNs经常被应用于NLP领域的原因之一。更重要的是,RNNs基于时序数据的预测能力,使得它可以胜任包括自动编曲,文本编写等等创造性工作。
RNNs的视频已上传至我的YouTube频道,懒得看字的朋友可以直接看视频。
循环神经元
对于大部分的神经网络而言,传播方向基本都是一个方向的,也就是比较常见的前馈网络。而对于RNNs来说,它的传播方向是前后双向的。最简单的例子,就是仅由一个循环神经元(recurrent neuron)接收输入 x ( t ) x_{(t)} x(t),以及这个神经元上一时刻的输出 y ( t − 1 ) y_{(t-1)} y(t−1)。如果我们将它在时间上进行延拓,就可以得到下图中展示的效果。
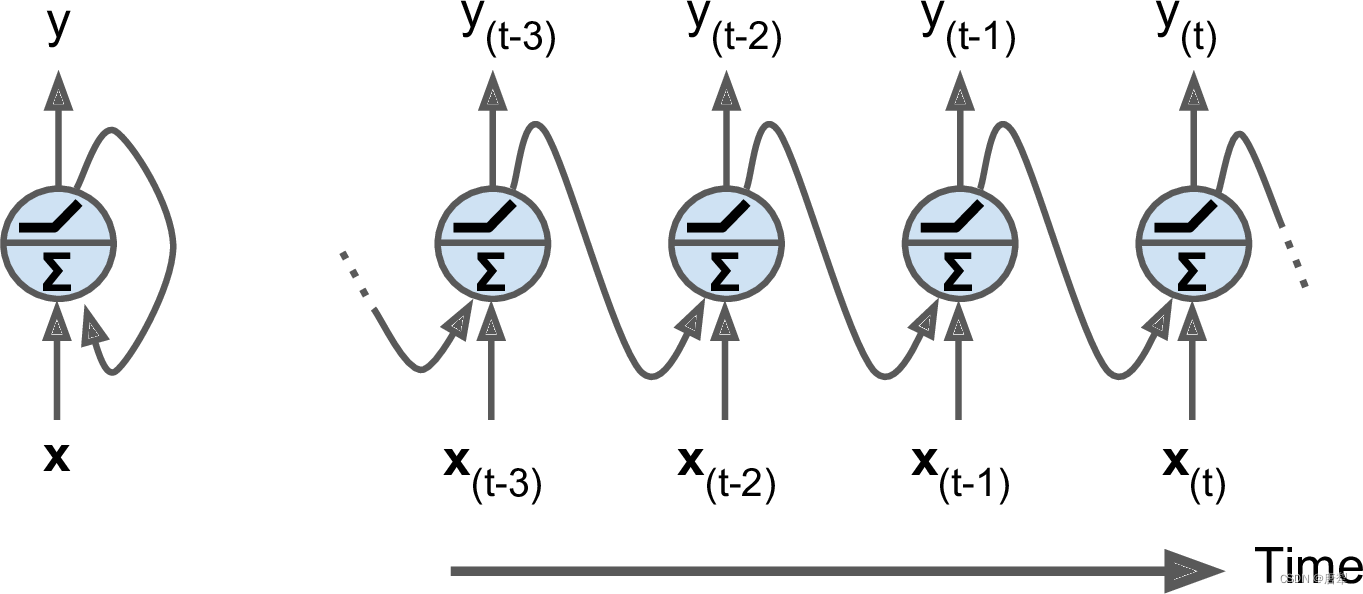
因此,生成一个由循环神经元组成的层十分简单 —— 只需要让每一个神经元在任一时刻,都接收 x t x_{t} xt的传入以及上一时刻的输出 y ( t − 1 ) y_{(t-1)} y(t−1)就可以了。每一个循环神经元都有两组权重,即输入 x ( t ) x_{(t)} x(t)的权重 w x w_x wx以及前一时刻输出 y ( t − 1 ) y_{(t-1)} y(t−1)的权重 w y w_y wy。对于单一循环神经元而言,任一时刻的输出 y ( t ) y_{(t)} y(t),可以被表示为:
y ( t ) = ϕ ( x t T ⋅ w x + y ( t − 1 ) T ⋅ w y + b ) y_{(t)}=\phi(x^T_t\cdot w_x+y^T_{(t-1)}\cdot w_y+b) y(t)=ϕ(xtT⋅wx+y(t−1)T⋅wy+b)
其中 b b b为偏置项, ϕ \phi ϕ为激活函数。循环神经层
将这样的循环神经元组成神经网络中的一个层,就可以得到一个循环神经层。即该层上一时刻的输出将会作为下一时刻输入的一部分:

因此对于整个层的输出可以表示为:
Y ( t ) = ϕ ( X ( t ) ⋅ W x + Y ( t − 1 ) ⋅ W y + b ) Y_{(t)}=\phi(X_{(t)}\cdot W_x+Y_{(t-1)}\cdot W_y+b) Y(t)=ϕ(X(t)⋅Wx+Y(t−1)⋅Wy+b)
化简为:
Y ( t ) = ϕ ( [ X ( t ) Y ( t − 1 ) ] ⋅ W + b ) w i t h W = [ W x W y ] Y_{(t)}=\phi \left(\left[X_{(t)} \ Y_{(t-1)} \right ] \cdot W + b \right )\ with\ W=Y(t)=ϕ([X(t) Y(t−1)]⋅W+b) with W=[WxWy][ W x W y ]
其中:- Y ( t ) Y_{(t)} Y(t)是一个大小为 m × n n e u r o n s m \times n_{neurons} m×nneurons,包含 t t t时刻所有输出的矩阵。其中 m m m是该层mini-batch中所有实例的个数, n n e u r o n s n_{neurons} nneurons是神经元的个数。
- X ( t ) X_{(t)} X(t)是一个大小为 m × n i n p u t s m \times n_{inputs} m×ninputs,包含所有实例的输入的矩阵。其中 n i n p u t s n_{inputs} ninputs是输入特征的数量。
- W x W_x Wx是一个大小为 n i n p u t s × n n e u r o n s n_{inputs} \times n_{neurons} ninputs×nneurons,包含输入对于当前时刻的连接权重的权重矩阵。
- W y W_y Wy是一个大小为 n n e u r o n s × n n e u r o n s n_{neurons} \times n_{neurons} nneurons×nneurons,包含输出对于前一时刻的连接权重的权重矩阵。
- 这两个权重矩阵 W x W_x Wx和 W y W_y Wy经常被拼接成为一个大小为 ( n i n p u t s + n n e u r o n s ) × n n e u r o n s \left ( n_{inputs}+n_{neurons} \right )\times n_{neurons} (ninputs+nneurons)×nneurons的独立的权重矩阵 W W W。
- b b b是一个大小为 n n e u r o n s n_{neurons} nneurons,包含每个神经元的偏置项的向量。
记忆细胞
由于循环神经元在处理 t t t时刻输出时,会涉及到此前时刻的所有输入,因此也可以认为循环神经元是具有记忆的。网络中可以保存时序状态的一部分,被称为记忆细胞(memory cells)。最基础的形式就是一个循环神经元或者一个由循环神经元构成的层。
一般而言一个记忆细胞在 t t t时刻的隐状态记作 h ( t ) h_{(t)} h(t)。 h ( t ) h_{(t)} h(t)与当前时刻的输入以及前一时刻的隐状态相关,可表示为 h ( t ) = f ( h ( t − 1 ) , x ( t ) ) h_{(t)}=f(h_{(t-1)}, x_{(t)}) h(t)=f(h(t−1),x(t))。在 t t t时刻的输出 y ( t ) y_{(t)} y(t)也是由前一时刻的隐状态和当前时刻的输入决定的。在一些复杂的情况下, h ( t ) h_{(t)} h(t)与 y ( t ) y_{(t)} y(t)并不相同。
RNNs的网络结构
RNNs的使用方式非常灵活。一个RNN可以通过模拟一个输入序列来生成一个输出序列,即Seq2Seq。因此可以用于预测时序序列,比如股票的价格。另一种应用方式,是输入一个序列,之后忽略掉其他输出,只保留最后一个输出,这种做法可以讲一个序列进行向量化,即Seq2Vec。比如,可以将一部电影相关的评价做成词语序列输入网络,输出电影的打分。与之相反的方式,是将其他时刻的输入全部置0,只保留第一个输入,然后让网络输出整个序列,这样它就是一个Vec2Seq网络。比如,你可以输入一个图片,然后输出关于它的文字说明。最后一种常见做法是,你可以用一个Seq2Vec网络作为encoder,之后接一个Vec2Seq网络作为decoder,这样就组成了一个delayed Seq2Seq网络。比如,你可以将一种语言翻译成另一种语言。首先,将一种语言输入到encoder部分中,使其转化为一个向量值。之后再用decoder对这个向量解码,转换为另一种语言。这种two-step模型被称为Encoder-Decoder模型,相比于普通的Seq2Seq,这种方式无需等待整句话完全输入再进行翻译。
使用TensorFlow构建简单RNN
在TensorFlow的keras中,有三种内置的RNN层,分别是SimpleRNN,GRU,以及LSTM。GRU和LSTM都是RNN的变形,SimpleRNN则是一个基础的全连接RNN。
from tensorflow.keras.layers import SimpleRNN- 1
-
相关阅读:
网络安全和隐私保护技术
tf.random
SpringBoot--中间件技术-3:整合mongodb,整合ElasticSearch,附案例含代码(简单易懂)
postgres 分割字符串
前后端分离项目,vue+uni-app+php+mysql在线小说电子书阅读小程序系统 开题报告
Bean注入方式:@Autowired、@Resource的区别
论文解析-moETM-多组学整合模型
Memcached对象缓存详解
ArcPy批量对大量遥感影像相减做差
高考相关系列
- 原文地址:https://blog.csdn.net/github_38325884/article/details/126467354