-
BLISS: A Billion scale Index using Iterative Re-partitioning
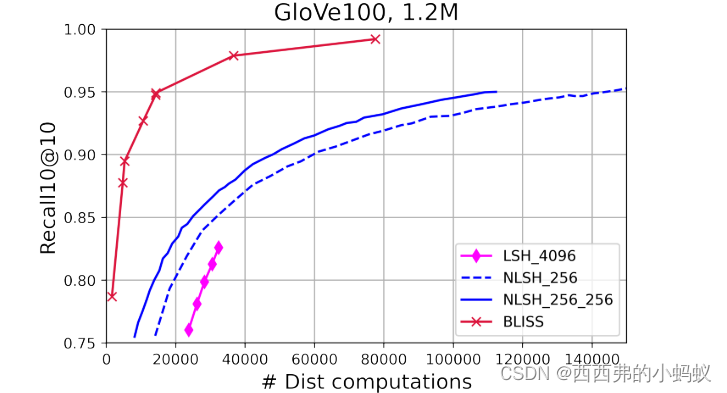
表示学习已将信息检索问题转化为在高维向量空间中寻找近似最近邻集的问题。由于有限的硬件资源和时间关键查询,检索引擎面临延迟、准确性、可扩展性、紧凑性和分布式负载平衡能力之间的内在矛盾。为了改善这种权衡,本文提出了一种新的算法,称为平衡可扩展搜索索引(BLISS),一种高度可调的索引算法,具有令人羡慕的小索引大小,可以轻松扩展到数十亿向量。它通过直接从查询项相关性数据中学习相关桶,迭代地细化项的划分。为了确保桶的平衡,BLISS使用了-𝐾选择策略。我们证明BLISS在高概率下(以及非常良性的假设下)提供了优越的负载平衡。BLISS可同时用于近邻检索(ANN问题)和极端分类(XML问题)。以ann为例,我们训练和索引了4个数据集,每个数据集有十亿向量。将BLISS的查全率、推理时间、索引时间和索引大小与两个最流行和优化最好的库——分层可导航小世界(HNSW)图和Facebook的FAISS进行了比较。BLISS需要比HNSW少100倍的RAM,使其适合于普通机器上的内存,同时在相同的召回情况下,推理时间与HNSW相似。与FAISS-IVF相比,BLISS实现了类似的性能,内存需求减少了3-4倍。BLISS是数据和模型并行的,使其成为训练和推理的分布式实现的理想选择。以XML为例,BLISS超过了最佳基线的精度,同时在具有50万个类别的流行多标签数据集上的推理速度快了5倍。
阅读者总结:这篇论文是典型的学习索引,但是主要用在了hash函数上。文中对hash函数的学习,其实没有什么新颖的地方,虽然文中提到了很多,只是基于hash函数本身的特点而言的。干货就是对每个划分的桶,训练一个神经网络,建立起labels数据和桶位置之间的关系,但是文中没有提到使用什么神经网络,并且说为每个桶训练一个神经网络,这个做法值得考虑,因为训练神经网络需要花费大量的时间和标签数据,
本文的主要贡献:
本文提出了一种新的学习索引算法——BLISS (BaLanced Index for Scalable Search)。它采用迭代训练和重新划分的方法,每次做两件事:1)学习将查询映射到相关的桶,2)每次以平衡的方式将点重新分配到桶,以实现更好的索引
BLISS是随机化力量的一个例证。它打破了deterministic assignment所不可能实现的障碍。我们可以将BLISS与Balanced K-Means[23]等聚类方法进行比较。然而,我们通过使用三个设计选择打破了前面提到的“集群诅咒”:1)将一个标签映射到多个集群,而不是单个分配,2)对桶分配进行概率解释,3)从随机分区开始进行多次独立的索引重复。这些选择使我们能够平衡分区,其中每个部分的元素具有高度的相关性
框架:


BALANCED INDEX FOR SCALABLE SEARCH
BLISS (BaLanced Index for Scalable Search)首先是基于随机池化的索引初始化,然后是交替训练和重新划分步骤的迭代过程。我们训练𝑅独立的这样的索引,并使用它们进行有效的项目检索。图1和图2用一个包含5个桶的玩具示例来说明我们的算法。
1)Initialization
 Re-partitioning:
Re-partitioning: 需要注意的是,对于相似的标签,网络将提供非常相似的𝑎𝑟𝑔𝑚𝑎𝑥值,导致太多的向量被汇集到几个bucket中。
Load Balancing:为了克服这种不平衡,我们为每个标签选择𝐾 top bucket,从这些桶中选择占用最少的桶,并为它分配标签。它可以确保标签先填满较轻的桶,以跟上顶部类似标签桶的负荷。正如我们在后面的第4节中所看到的,我们只需要一个很小的𝐾(<10)就可以保持近乎完美的负载平衡
2.2 Alternative Training and Re-partitioning:

相当于 每个partition 存在一个神经网络,大概需要大量的训练过程。
2.3 Inference/Query:
训练之后,我们存储所有𝑅重复的训练模型和倒索引。在查询过程中,向量𝑞∈R𝑑独立并行地通过𝑅训练网络,每个网络给出一个𝐵维概率向量。此外,我们计算每个候选对象在总𝑚×𝑅集合中的出现频率。候选标签出现的频率越高,表示与查询点的相关性越高 。最终,我们通过过滤和拒绝池中低于特定频率阈值的候选对象,只保留更高相关性的候选对象。如果候选人人数超过要求,通过对驻留在磁盘上的数据进行真实距离计算,我们会重新排名它们,。我们将它们作为memmap数组,以便快速获取


-
相关阅读:
C++ LibCurl 库的使用方法
web:[极客大挑战 2019]Http
【初阶数据结构】详解树和二叉树(一) - 预备知识(我真的很想进步)
今年跳槽成功测试工程师原来是掌握了这3个“潜规则”
Web3.0与区块链有何不同?现在处于哪个阶段?
30C++编程提高篇-----1、函数模板原理
3种等待方式,让你学会Selenium设置自动化等待测试脚本!
【技术美术知识储备】图形渲染管线2.0-GPU管线概述&几何阶段
Linux: 会话登录超时的一些改动
面试准备-设计模式-待更新
- 原文地址:https://blog.csdn.net/zj_18706809267/article/details/126466356