-
【Dive into Deep Learning / 动手学深度学习】第十章 - 第三节:注意力评分函数

简介
Hello!
非常感谢您阅读海轰的文章,倘若文中有错误的地方,欢迎您指出~
ଘ(੭ˊᵕˋ)੭
昵称:海轰
标签:程序猿|C++选手|学生
简介:因C语言结识编程,随后转入计算机专业,获得过国家奖学金,有幸在竞赛中拿过一些国奖、省奖…已保研
学习经验:扎实基础 + 多做笔记 + 多敲代码 + 多思考 + 学好英语!
唯有努力💪
本文仅记录自己感兴趣的内容10.3. 注意力评分函数
Note
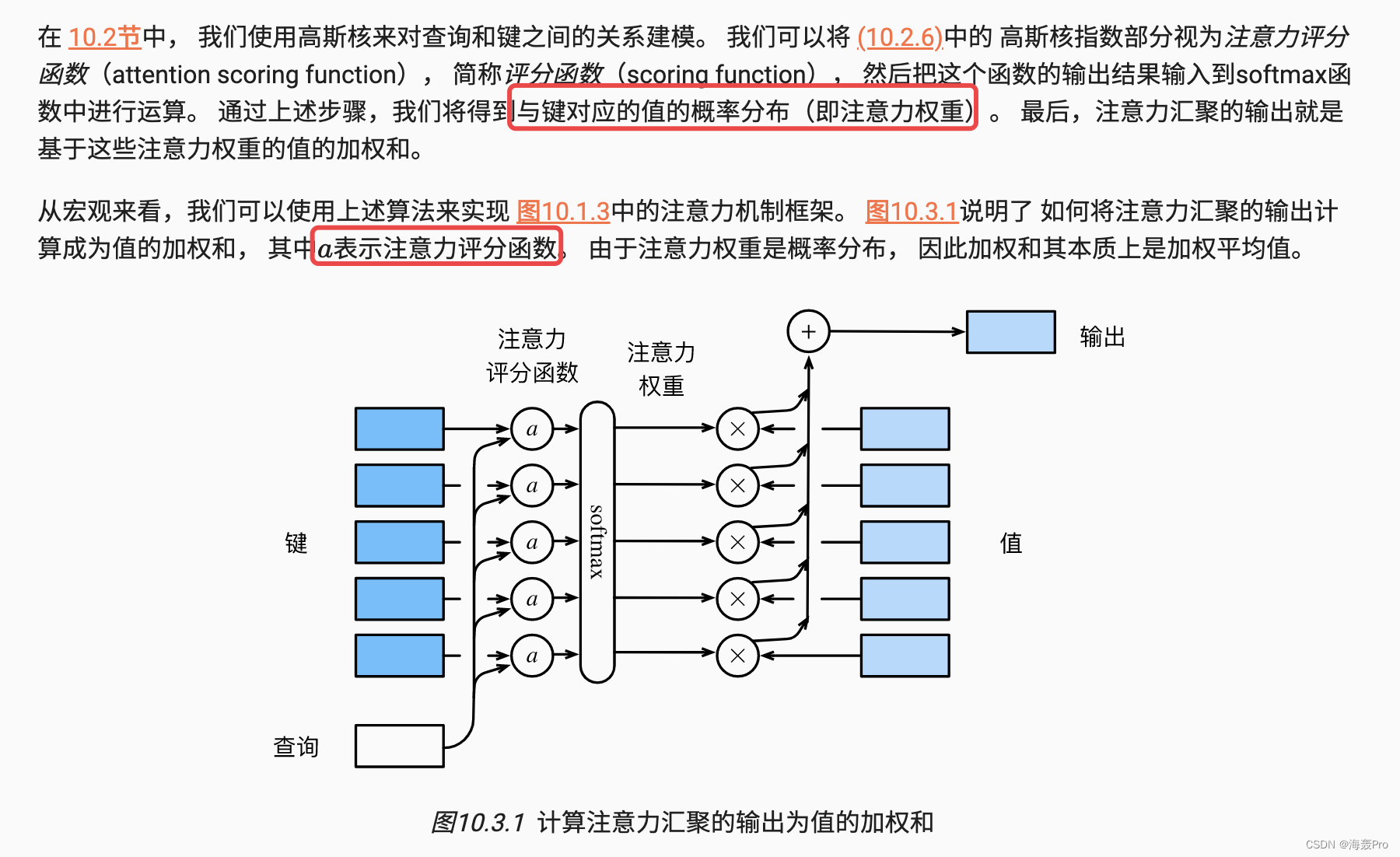
- 利用评分函数计算query与key之间的“分数”
- 在使用softmax归一化(也就是得到概率)
- 再进行加权求和


import math import torch from torch import nn from d2l import torch as d2l- 1
- 2
- 3
- 4
10.3.1. 掩蔽softmax操作

#@save def masked_softmax(X, valid_lens): """通过在最后一个轴上掩蔽元素来执行softmax操作""" # X:3D张量,valid_lens:1D或2D张量 if valid_lens is None: return nn.functional.softmax(X, dim=-1) else: shape = X.shape if valid_lens.dim() == 1: valid_lens = torch.repeat_interleave(valid_lens, shape[1]) else: valid_lens = valid_lens.reshape(-1) # 最后一轴上被掩蔽的元素使用一个非常大的负值替换,从而其softmax输出为0 X = d2l.sequence_mask(X.reshape(-1, shape[-1]), valid_lens, value=-1e6) return nn.functional.softmax(X.reshape(shape), dim=-1)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16

masked_softmax(torch.rand(2, 2, 4), torch.tensor([2, 3]))- 1

同样,我们也可以使用二维张量,为矩阵样本中的每一行指定有效长度

10.3.2. 加性注意力

#@save class AdditiveAttention(nn.Module): """加性注意力""" def __init__(self, key_size, query_size, num_hiddens, dropout, **kwargs): super(AdditiveAttention, self).__init__(**kwargs) self.W_k = nn.Linear(key_size, num_hiddens, bias=False) self.W_q = nn.Linear(query_size, num_hiddens, bias=False) self.w_v = nn.Linear(num_hiddens, 1, bias=False) self.dropout = nn.Dropout(dropout) def forward(self, queries, keys, values, valid_lens): queries, keys = self.W_q(queries), self.W_k(keys) # 在维度扩展后, # queries的形状:(batch_size,查询的个数,1,num_hidden) # key的形状:(batch_size,1,“键-值”对的个数,num_hiddens) # 使用广播方式进行求和 features = queries.unsqueeze(2) + keys.unsqueeze(1) features = torch.tanh(features) # self.w_v仅有一个输出,因此从形状中移除最后那个维度。 # scores的形状:(batch_size,查询的个数,“键-值”对的个数) scores = self.w_v(features).squeeze(-1) self.attention_weights = masked_softmax(scores, valid_lens) # values的形状:(batch_size,“键-值”对的个数,值的维度) return torch.bmm(self.dropout(self.attention_weights), values)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24

queries, keys = torch.normal(0, 1, (2, 1, 20)), torch.ones((2, 10, 2)) # values的小批量,两个值矩阵是相同的 values = torch.arange(40, dtype=torch.float32).reshape(1, 10, 4).repeat( 2, 1, 1) valid_lens = torch.tensor([2, 6]) attention = AdditiveAttention(key_size=2, query_size=20, num_hiddens=8, dropout=0.1) attention.eval() attention(queries, keys, values, valid_lens)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10

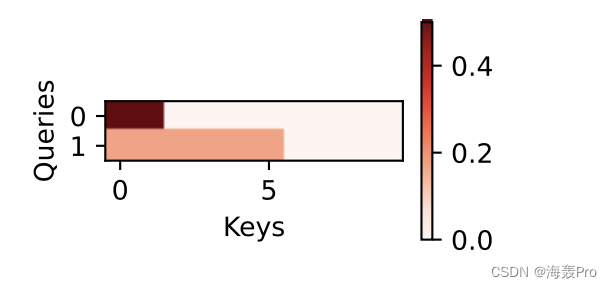
尽管加性注意力包含了可学习的参数,但由于本例子中每个键都是相同的, 所以注意力权重是均匀的,由指定的有效长度决定。d2l.show_heatmaps(attention.attention_weights.reshape((1, 1, 2, 10)), xlabel='Keys', ylabel='Queries')- 1
- 2
10.3.3. 缩放点积注意力

#@save class DotProductAttention(nn.Module): """缩放点积注意力""" def __init__(self, dropout, **kwargs): super(DotProductAttention, self).__init__(**kwargs) self.dropout = nn.Dropout(dropout) # queries的形状:(batch_size,查询的个数,d) # keys的形状:(batch_size,“键-值”对的个数,d) # values的形状:(batch_size,“键-值”对的个数,值的维度) # valid_lens的形状:(batch_size,)或者(batch_size,查询的个数) def forward(self, queries, keys, values, valid_lens=None): d = queries.shape[-1] # 设置transpose_b=True为了交换keys的最后两个维度 scores = torch.bmm(queries, keys.transpose(1,2)) / math.sqrt(d) self.attention_weights = masked_softmax(scores, valid_lens) return torch.bmm(self.dropout(self.attention_weights), values)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
为了演示上述的DotProductAttention类, 我们使用与先前加性注意力例子中相同的键、值和有效长度
对于点积操作,我们令查询的特征维度与键的特征维度大小相同
queries = torch.normal(0, 1, (2, 1, 2)) attention = DotProductAttention(dropout=0.5) attention.eval() attention(queries, keys, values, valid_lens)- 1
- 2
- 3
- 4

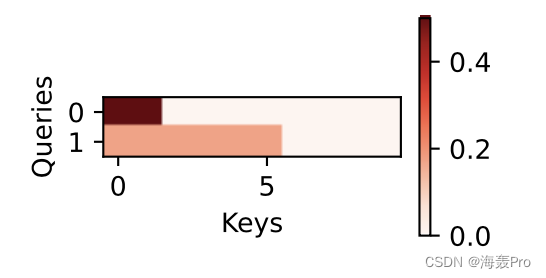
与加性注意力演示相同,由于键包含的是相同的元素, 而这些元素无法通过任何查询进行区分,因此获得了均匀的注意力权重。
d2l.show_heatmaps(attention.attention_weights.reshape((1, 1, 2, 10)), xlabel='Keys', ylabel='Queries')- 1
- 2
10.3.4. 小结

读后总结
2022/08/22 第一次阅读
思路上是理解了两种评分函数的理论
但是代码是还有有些地方不太懂
主要体现在一些函数的使用上
之后再读的时候再理清楚!
结语
学习资料:
http://zh.d2l.ai/文章仅作为个人学习笔记记录,记录从0到1的一个过程
希望对您有一点点帮助,如有错误欢迎小伙伴指正

-
相关阅读:
56、MQ(异步通讯的的缺点/优点)
Nginx 优化
CentOS7.9+Kubernetes1.28.3+Docker24.0.6高可用集群二进制部署
Base64与MD5(数据加密)与ValidateCode(验证码)
拿下跨界C1轮投资,本土Tier 1高阶智能驾驶系统迅速“出圈”
Java线程池Executor详解
React组件进阶--render-props,render props模式的使用步骤,children代替render属性,传递props
弘玑Cyclone荣登2022「Cloud 100 China」榜单
PostgreSQL数据库统计信息——acquire_inherited_sample_rows采样函数
Android项目升级到AndroidX
- 原文地址:https://blog.csdn.net/weixin_44225182/article/details/126456593