-
【ZeloEngine】OpenGL升级Vulkan
【ZeloEngine】OpenGL升级Vulkan

Vulkan的资料有很多,这里以GDC2016中nvidia的slide作为讨论的基础
Vulkan - 高性能渲染 - 知乎 // 结果发现是文刀秋二做的talk,这就是大佬把
还有一本基础书《Learning Vulkan》
这本书和大部分Packt的书一样有一个问题,有很多流水账一样的线性流程代码

下文中Vulkan简称vk
Scope
最终目标:多线程渲染框架
笔者水平有限,无法一步完成多线程渲染框架,拆解一下,大致分几步:
- GL升级Vulkan,跑通原来的Demo
- 多线程调研:Asio/TaskFlow
- 多线程引擎架构
是什么?不是什么?
vk是图形接口,笔者学习vk主要是理解CPU和GPU协同完成绘制的软件过程
vk不是GPU硬件,也不是图形学,但是有一定辅助理解作用
vk在渲染架构的位置
理想的分层架构如下,实际上由于缺乏经验,笔者无法很好地分离出RHI层,vk call到处飞
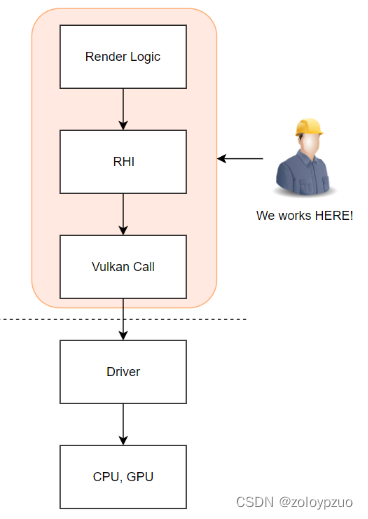
Why not DX12?
换开发框架,数学库,坐标系手性,shader,总之风险比Vulkan大
坑
1. 初始化时序依赖
这里出现新的case了,下面两句不依赖window,尽早初始化
volk就是loader,调了才能调vk call,否则代码段错误
volk < create-window < vk-call
此外,还有一个依赖,所有显卡操作需要走命令队列,因此要先创建命令队列:
command pool < command buffer < vk-command-call
glslang_initialize_process(); volkInitialize();- 1
- 2
2. 多图形接口宏管理
GL,Vulkan,两个宏,用ifdef到处打洞,打补丁,window这种强平台相关其实还不如每个写一个版本
一种比较干净的写法就是派生WindowGL,WindowVulkan类,顶层包一下宏,避免ifdef到处飞
由于SDL的Vulkan扩展总共就5个接口,这里就不派生了,统一放在一个Window类
3. SDL
市面上大部分例程都是glfw的,但是Zelo用的是SDL
SDL封装了窗口 / 平台相关的API,折腾了一会
// 1. native way // Creat empty Window CreateWindowEx(...); /*Windows*/ // Query WSI extensions,store as function pointers. For example: // vkCreateSwapchainKHR, vkCreateSwapchainKHR ..... // Create abstract surface object VkWin32SurfaceCreateInfoKHR createInfo = {}; vkCreateWin32SurfaceKHR(instance, &createInfo, NULL, &surface);- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
// 2. SDL way SDL_CreateWindow(..., SDL_WINDOW_VULKAN); SDL_Vulkan_CreateSurface(m_window, instance, surface);- 1
- 2
- 3
- 4
4. 同步
比较复杂,即使单线程渲染,仍然要手工做CPU和GPU的同步,前面提到了一些,由于不熟悉,不多讨论
Zelo这里简化了,没处理 TODO
同步都暂时不考虑,第二个pass再说
SetImageLayout和vkCreateImageView之间加了一个barrier,表明这两步有时序依赖// Retrieve the Swapchain images foreach swapchainImages{ // Set the implementation compatible layout SetImageLayout(); // Insert pipeline barrier VkImageMemoryBarrier imgMemoryBarrier = { ... }; /* => */ vkCmdPipelineBarrier(cmd,srcStages,destStages,0,0,NULL,0,NULL,1,&imgMemoryBarrier); // Create the image view for the image object SwapChainBuffer scBuffer = {...}; VkImageViewCreateInfo colorImageView = {}; colorImageView.image = sc_buffer.image; vkCreateImageView(device, &colorImageView, NULL, &scBuffer.view); // Save the image view for application use buffers.push_back(scBuffer); }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
惯用法
1. 查询列表 / 枚举(enumerate)
查询一个列表结果,调用两次,第一次传入NULL,返回列表长度,第二次传入列表,填充并返回列表
// Enumerate Instance Layer properties // Get number of instance layers uint32_t instanceLayerCount; // Use second parameter as NULL to return the layer count vkEnumerateInstanceLayerProperties(&instanceLayerCount, NULL); VkLayerProperties *layerProperty = NULL; vkEnumerateInstanceLayerProperties(&instanceLayerCount, layerProperty);- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
// Enumerate physical devices VkPhysicalDevice gpu; // Physical device uint32_t gpuCount; // Pysical device count std::vector<VkPhysicalDevice> gpuList; // List of physical devices // Get number of GPU count vkEnumeratePhysicalDevices(instance, &gpuCount, NULL); // Get GPU information vkEnumeratePhysicalDevices(instance, &gpuCount, gpuList);- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
概念清单
清晰的概念是思考的基石
Understanding Vulkan® Objects - GPUOpen
vk的概念很多,是一个重点
- Instance:全局单例
- Device:设备,指显卡GPU
- Layer:可以理解为钩子
- Extension:扩展功能,可以理解为DLC
- Queue:指令队列
- SwapChain:一个可以透明的概念
- DesciptorSet:Shader资源槽位
电脑可以有多个显卡,一般我们选择最好的那一个

现代GPU其实是“多功能”的,一个功能模块对应一个Queue,比如我们渲染就使用Graphics Queue,通用计算就用Compute Queue,Queue下称q
QueueFamily属于硬件范围概念,略

SwapChain,一般double buffer够用了,其实就是两张图片,一张显示在屏幕上,一张在后台程序绘制,轮替显示
这个图片的特殊在于,不需要我们维护内存,因为独一份
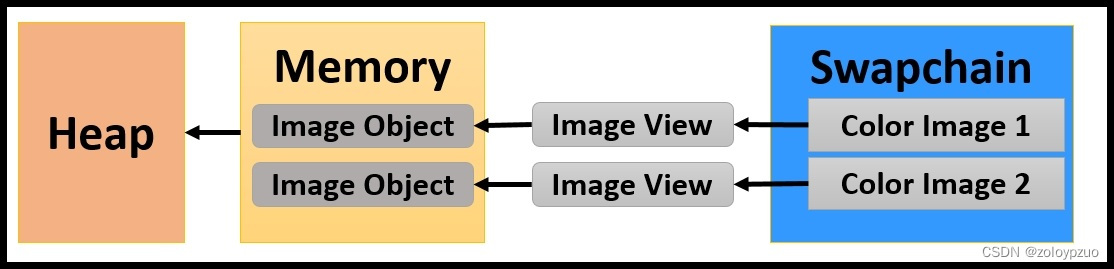
理解管线
一个不太恰当的管线比喻
来看regex的例子
compield-pattern = re.compile("([A-Z])\w+") result1 = re.match(compiled-pattern, "My Str1") result2 = re.match(compiled-pattern, "My Str2") ## i.e. match_word = functools.partial(re.compile, compiled-pattern) result = match_word("My Str")- 1
- 2
- 3
- 4
- 5
- 6
- 7
这里有几个关键的类比:
- 预编译的管线,来提升性能
- 画面 = Σ管线(资源),其中管线是复用的,一帧画面有若干drawcall,一个drawcall绘制一批资源到画布上,最终求和得到整个画面
初始化流程
没什么技巧,找个现成的对照着拼出流程,好的例程对步骤的切分比较清晰
厘清概念,了解清楚每一步在干什么,创建出来的东西是什么,干什么用的
流程
1. Enumerate Instance Layer properties 2. Instance Creation 3. Enumerate physical devices 4. Create Device 5. Presentation Initialization 6. Creating Swapchain 7. Creating Depth buffer 8. Building shader module 9. Creating descriptor layout and pipeline layout 10. Render Pass 11. Creating Frame buffers 12. Populate Geometry storing vertex into GPU memory 13. Vertex binding 14. Defining states 15. Creating Graphics Pipeline 16. Acquiring drawing image 17. Preparing render pass control structure 18. Render pass execute 19. Queue Submission 20. Present the draw result on the display window- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
1. 枚举Instance Layer属性 2. 实例创建 3. 枚举物理设备 4. 创建设备 5. 演示初始化 6. 创建交换链 7. 创建深度缓冲区 8. 构建着色器模块 9. 创建描述符布局和管道布局 10. 渲染通行证 11. 创建帧缓冲区 12. 将存储顶点的几何填充到 GPU 内存中 13. 顶点绑定 14. 定义状态 15. 创建图形管道 16. 获取绘图图像 17. 准备渲染通道控制结构 18. 渲染通道执行 19. 队列提交 20. 在显示窗口中呈现绘制结果- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
流程图例
构造全局单例,启用layer和extension
枚举并创建设备,电脑可以有多个显卡,一般我们选择最好的那一个
现实里可以摸到的称为物理设备,有了物理设备,在程序中创建对应的逻辑设备,进行编程控制
设备scope,也有扩展可以勾选,与全局单例进行对比

显示相关,实时渲染需要一个显示器显示每帧渲染的画面
首先创建一个native窗口,然后再创建一个Surface,Surface是对窗口的抽象

资源
资源是对显存的抽象
vk堆上分的大类有两个,Image和Buffer
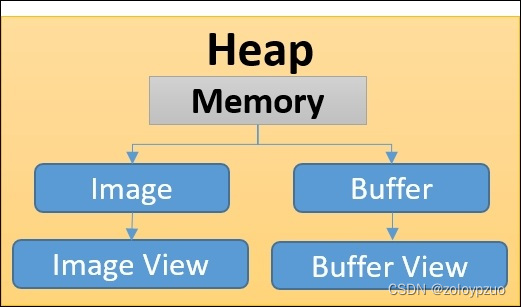
Shader & Shader资源绑定
Shader编译与构造ShaderModule这一步相对独立,比较简单,略
比较麻烦的是Shader资源绑定
一个不太恰当的比喻,一个Shader相当于下图中的一个计算节点,它有一些输入和输出
一般是输入一些资源,输出一些颜色 / 向量 计算结果
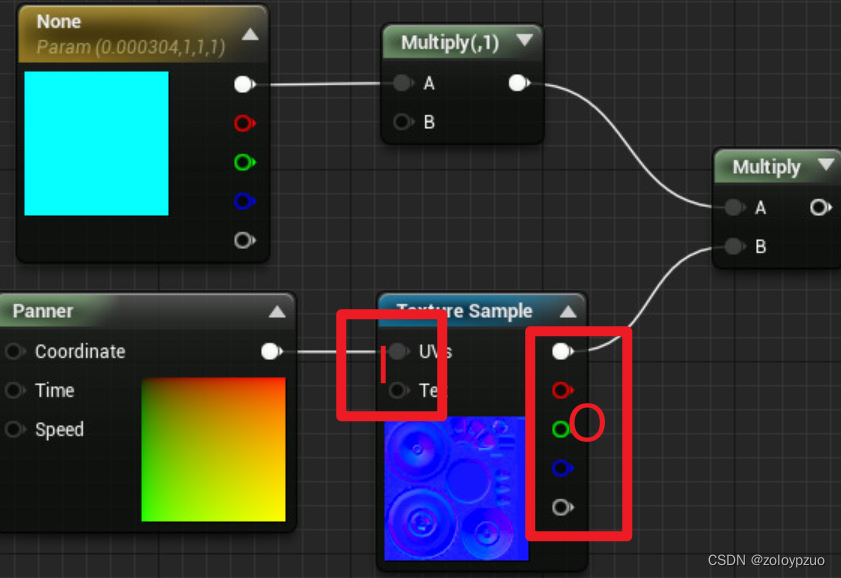
我们怎么用C++代码把资源连接到Shader的槽位上呢?
其实就是槽位需要一个标识,可以是Shader变量名,也可以是一个唯一的索引(0,1,2,etc)
vk里的一个槽位就是一个Descriptor
一个Shader有一组槽位,也就是一个Descriptor Set
一组槽位还有一个Layout,/
一个Pipeline(顶层概念)有多套Shader和Descriptor Set,称为Pipeline Layout
emm,vk的概念真的很复杂:
DescriptorSetLayoutBinding < DescriptorSetLayout < PipelineLayout

Layout相关的编程一般都比较麻烦,还有一处就是顶点Layout,本质上需要描述一个Schema,把C++类型和Shader类型对应起来,还要考虑对齐
RenderPass
还有个SubPass,这块没搞懂
代码结构上,SubPass < RenderPass < FrameBuffer
SwapChain有两张图片,每张都要创建一个FrameBuffer
Mesh & Vertex
顶点数据对应buffer,顶点格式描述对应VkVertexInputBindingDescription,前面提到过,略
Pipeline & PSO
Pipeline是顶层概念,之前提到的所有vk对象都会被Pipeline引用
DrawCall
16. 获取绘图图像 17. 准备渲染通道控制结构 18. 渲染通道执行 19. 队列提交 20. 在显示窗口中呈现绘制结果- 1
- 2
- 3
- 4
- 5
伪代码
accuqire-swapchain-image for render-pass in render-pass-list do begin-render-pass bind-pipeline record-drawcall end submit-drawcall wait-for-swapchain- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
------ Misc ------
RHI
- CommandBuffer
- Memory
- Image
- SwapChain
- Buffer
- RenderPass
- FrameBuffer
- Shader
- Descriptor
- Pipeline
- PSO
调试
- debug layer,好东西,多看log熟悉即可
- nsight
-
相关阅读:
基于单片机的车载太阳能板自动跟踪系统研究
IDEA代码同步到GitHub
Python 图形化界面基础篇:监听按钮点击事件
基于JAVA医院医护人员排班系统计算机毕业设计源码+系统+mysql数据库+lw文档+部署
阿里云OSS、用户认证与就诊人
vscode ssh远程连接服务器,一直正在下载vscode服务器的解决办法
python[sys模块使用]:配置subprocessing实现后台调用python函数,并传递次数
Redis的数据删除策略
测试必备工具 —— Postman实战教程
CSS基础
- 原文地址:https://blog.csdn.net/zolo_mario/article/details/126404805
