-
3. MongoDB存储和索引
3. MongoDB存储和索引
3.1. 存储引擎
3.1.1 wiredTiger
MongoDB 从 3.0 开始引入可插拔存储引擎的概念。目前主要有 MMAPV1、WiredTiger 存储引 擎可供选择。在 3.2 版本之前 MMAPV1 是默认的存储引擎,其采用 linux 操作系统内存映射技 术,但一直饱受诟病;3.4 以上版本默认的存储引擎是 wiredTiger,相对于 MMAPV1 其有如下优 势:
-
读写操作性能更好,WiredTiger 能更好的发挥多核系统的处理能力;
-
MMAPV1 引擎使用表级锁,当某个单表上有并发的操作,吞吐将受到限制。WiredTiger 使用文档级锁,由此带来并发及吞吐的提高
-
相比 M MAP V1 存储索引时 WiredTiger 使用前缀压缩,更节省对内存空间的损耗;
-
提供压缩算法,可以大大降低对硬盘资源的消耗,节省约 60%以上的硬盘资源;
3.1.2. WT 写入的原理
mongodb 数据会丢失?你需要了解 WT 写入的原理
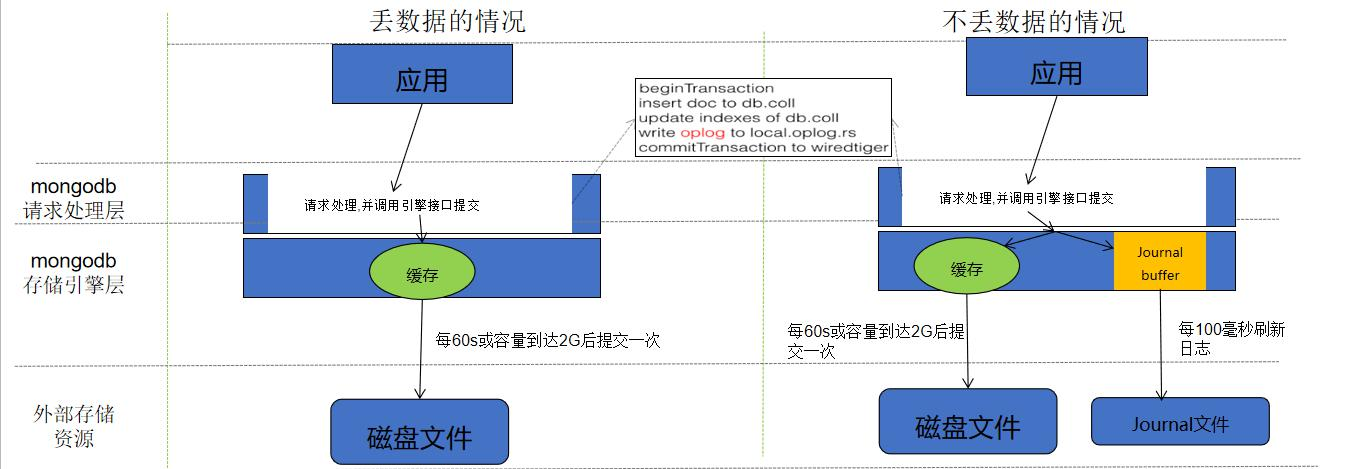
Journaling
类似于关系数据库中的事务日志(redolog)。Journaling 能够使 MongoDB 数据库由于意外故障后快速 恢复。MongoDB2.4 版本后默认开启了 Journaling 日志功能,mongod 实例每次启动时都会检 查 journal 日志文件看是否需要恢复。由于提交 journal 日志会产生写入阻塞,所以它对写入的 操作有性能影响**,但对于读没有影响。在生产环境中开启 Journaling 是很有必要的。**
3.1.3. 写策略解析
//需要等待返回结果 db.users.updateMany({ "username": "lison" }, { "$unset": { "country": "", "age": "" } }, { writeConcern: { w: 1, j: true, wtimeout: 5000 } }); //不需要等待返回结果 db.users.updateMany({ "username": "lison" }, { "$unset": { "country": "", "age": "" } }, { writeConcern: { w: 0, j: true, wtimeout: 5000 } });- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
写策略配置:
{ w:, j: , wtimeout: } w: 数据写入到 number 个节点才向用客户端确认
{w: 0} 对客户端的写入不需要发送任何确认,适用于性能要求高,但不关注正确性的场景
{w: 1} 默认的 writeConcern,数据写入到 Primary 就向客户端发送确认
{w: “majority”} 数据写入到副本集大多数成员后向客户端发送确认,适用于对数据安全性要求比较高的场景,该选项会降低写入性能
j: 写入操作的 journal 持久化后才向客户端确认
默认为{j: false},如果要求写入持久化了才向客户端确认,则指定该选项为 true
wtimeout: 写入超时时间,仅 w 的值大于 1 时有效。
当指定{w: }时,数据需要成功写入 number 个节点才算成功,如果写入过程中有节点故障,可能导致这个条件一直不能满足,从而一直不能向客户端发送确认结果,针对这种情况,客 户端可设置 wtimeout 选项来指定超时时间,当写入过程持续超过该时间仍未结束,则认为 写入失败。
3.1.4. Java 代码实现写策略
Q1:写策略配置相关的类是?
答: com.mongodb.WriteConcern,其中有如下几个常用写策略配置:
- UNACKNOWLEDGED:不等待服务器返回或确认,仅可以抛出网络异常;
- ACKNOWLEDGED:默认配置,等待服务器返回结果;
- JOURNALED:等待服务器完成 journal 持久化之后返回;
- W1 :等待集群中一台服务器返回结果;
- W2 :等待集群中两台服务器返回结果;
- W3 :等待集群中三台服务器返回结果;
- MAJORITY:等待集群中多数服务器返回结果;
Q2:Java 代码中如何加入写策略?
答:Java 客户端可以按两种方式来设置写策略:
在 MongoClient 初始化过程中使用 **MongoClientOptions. writeConcern(writeConcern)**来进 行配置;
MongoClientOptions build = MongoClientOptions.builder().writeConcern(WriteConcern.ACKNOWLEDGED).codecRegistry(registry).build();- 1
- 2
在写操作过程中,也可动态的指定写策略,mongodb 可以在三个层次来进行写策略的 配置,既 MongoClient、 MongoDatabase 、MongoCollection 这三个类都可以通过 WriteConcern 方法来设置写策略;
Q3:Spring 中如何配置写策略
在配置文件中配置
<mongo:mongo-client id="mongo" host="localhost" port="27017"> <mongo:client-options write-concern="ACKNOWLEDGED" threads-allowed-to-block-for-connection-multiplier="5" max-wait-time="1200" connect-timeout="1000"/> mongo:mongo-client>- 1
- 2
- 3
- 4
- 5
- 6
- 7
Q4:WriteConcern 类的几个常用写策略配置满足不了项目的需求,怎么修改?
答:通过配置类,在 Spring 容器中加入自己定制化的 MongoClient,代码如下:
注释 applicationContext.xml
<mongo:mongo-client id="mongo" host="localhost" port="27017"> <mongo:client-options write-concern="ACKNOWLEDGED" threads-allowed-to-block-for-connection-multiplier="5" max-wait-time="1200" connect-timeout="1000"/> mongo:mongo-client>- 1
- 2
- 3
- 4
- 5
- 6
- 7
增加配置类
@Configuration public class AppConfig { @Bean(name = "mongo") public MongoClient mongoClient() { WriteConcern wc = WriteConcern.W1.withJournal(true); MongoClientOptions mco = MongoClientOptions.builder(). writeConcern(wc).connectionsPerHost(100). readPreference(ReadPreference.secondary()). threadsAllowedToBlockForConnectionMultiplier(5). readPreference(ReadPreference.secondaryPreferred()). maxWaitTime(120000).connectTimeout(10000).build(); List<ServerAddress> asList = Arrays.asList(new ServerAddress("localhost", 27031)); MongoClient client = new MongoClient(asList, mco); return client; } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
3.1.5. 配置文件
默认位置:
\bin\mongod.cfg storage: journal: enabled: true dbPath: /data/zhou/mongo1/ ##是否一个库一个文件夹 directoryPerDB: true ##数据引擎 engine: wiredTiger ##WT 引擎配置 wiredTiger: engineConfig: ##WT 最大使用 cache(根据服务器实际情况调节) cacheSizeGB: 1 ##是否将索引也按数据库名单独存储 directoryForIndexes: true journalCompressor:none (默认 snappy) ##表压缩配置 collectionConfig: blockCompressor: zlib (默认 snappy,还可选 none、zlib) ##索引配置 indexConfig: prefixCompression: true- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
压缩算法 Tips:
性能: none > snappy >zlib
压缩比: zlib > snappy > none
- If you installed MongoDB via a downloaded TGZ or ZIP file, you will need to create your own configuration file. The basic example configuration is a good place to start.
3.2. 索引
3.2.1. 索引语法
MongoDB 使用 createIndex () 方法来创建索引, createIndex()方法基本语法格式如下所示:
db.collection.createIndex(keys, options)- 1
语法中 Key 值为要创建的索引字段,1 为指定按升序创建索引,如果你想按降序来创建索引 指定为-1,也可以指定为 hashed(哈希索引)。 语法中 options 为索引的属性
3.2.2. 索引属性

3.2.3. 索引管理实战
3.2.3.1. 创建索引
- 单键唯一索引:
db.users.createIndex({username :1},{unique:true}); - 单键唯一稀疏索引:
db.users. createIndex({username :1},{unique:true,sparse:true}); - 复合唯一稀疏索引:
db.users. createIndex({username:1,age:-1},{unique:true,sparse:true}); - 创建哈希索引并后台运行:
db.users. createIndex({username :'hashed'},{background:true});
对文档中不存在的字段数据不启用索引;这个参数需要特别注意,如果设置为 true 的话, 在索引字段中不会查询出不包含对应字段的文档.。默认值为 false.
3.2.3.2. 删除索引
根据索引名字删除某一个指定索引:
db.users.dropIndex("username_1");删除某集合上所有索引:
db.users.dropIndexs();重建某集合上所有索引:
db.users.reIndex();查询集合上所有索引:
db.users.getIndexes();3.2.4. 索引命令概要与类型
索引通常能够极大的提高查询的效率,如果没有索引,MongoDB 在读取数据时必须扫描集合 中的每个文件并选取那些符合查询条件的记录。索引主要用于排序和检索
- 单键索引
在某一个特定的属性上建立索引,例如:
db.users. createIndex({age:-1});- mongoDB 在 ID 上建立了唯一的单键索引,所以经常会使用 id 来进行查询;
- 在索引字段上进行精确匹配、排序以及范围查找都会使用此索引;
- 复合索引
在多个特定的属性上建立索引,例如:
db.users. createIndex({username:1,age:-1,country:1});-
复合索引键的排序顺序,可以确定该索引是否可以支持排序操作;
-
在索引字段上进行精确匹配、排序以及范围查找都会使用此索引,但与索引的顺序有关;
-
为了内存性能考虑,应删除存在与第一个键相同的单键索引
- 多键索引
在数组的属性上建立索引,例如:
db.users. createIndex({favorites.city:1});针对这个数组的任意值的查询都会定位到这个文档,既多个索引入口或者键值引用同一个文档- 哈希索引
不同于传统的 B-树索引,哈希索引使用 hash 函数来创建索引。
例如:
db.users. createIndex({username : 'hashed'});- 在索引字段上进行精确匹配,但不支持范围查询,不支持多键 hash;
- Hash 索引上的入口是均匀分布的,在分片集合中非常有用;
3.2.5. 索引图示
单键索引
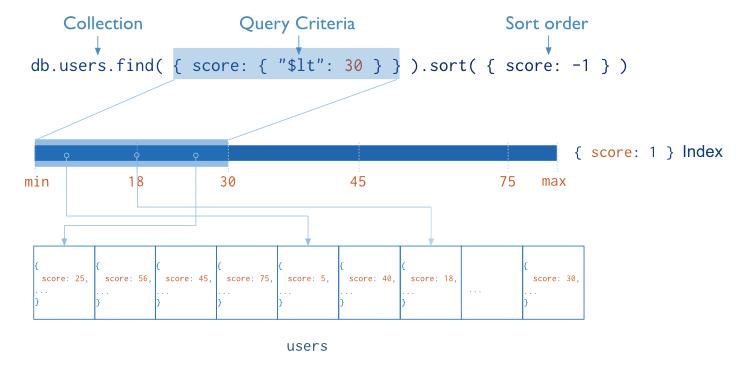
复合索引
{userid:1, score:-1}
3.2.6. 索引优化
3.2.6.1. 找出慢速查询
3.2.6.1.1. 开启慢查询
开启内置的查询分析器,记录读写操作效率:
db.setProfilingLevel(n,{m}),n 的取值可选 0,1,2;0 是默认值表示不记录;
1 表示记录慢速操作,如果值为 1, m 必须赋值单位为 ms,用于定义慢速查询时间的阈值;
2 表示记录所有的读写操作;
例如:
db.setProfilingLevel(1,300)3.2.6.1.2. 查询监控结果
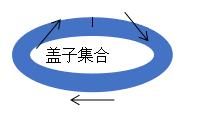
监控结果保存在一个特殊的盖子集合 system.profile 里,这个集合分配了 128kb 的空间,要确保 监控分析数据不会消耗太多的系统性资源;盖子集合维护了自然的插入顺序,可以使用 $natural 操作符进行排序,
如:
db.system.profile.find().sort({'$natural':-1}).limit(5)盖子集合 Tips:
大小或者数量固定;
不能做 update 和 delete 操作;
容量满了以后,按照时间顺序,新文档会覆盖旧文档
3.2.6.2. 分析慢速查询
找出慢速查询的原因比较棘手,原因可能有多个:应用程序设计不合理、不正确的数据模型、硬件配置问题,缺少索引等;接下来对于缺少索引的情况进行分析:
使用 explain 分析慢速查询
例如:
db.orders.find({'price':{'$lt':2000}}).explain('executionStats')explain 的入参可选值为:
-
“queryPlanner” 是默认值,表示仅仅展示执行计划信息;
-
“executionStats” 表示展示执行计划信息同时展示被选中的执行计划的执行情况信息;
-
“allPlansExecution” 表示展示执行计划信息,并展示被选中的执行计划的执行情况信息**,还展示备选的执行计划的执行情况信息;**
3.2.6.3. 解读 explain 结果
queryPlanner(执行计划描述)
winningPlan(被选中的执行计划)
stage(可选项:COLLSCAN 没有走索引;IXSCAN 使用了索引)
rejectedPlans(候选的执行计划)
executionStats(执行情况描述)
executionStages
nReturned (返回的文档个数)
executionTimeMillis(执行时间 ms)
totalKeysExamined (检查的索引键值个数)
totalDocsExamined (检查的文档个数)
优化目标 Tips:
- 根据需求建立索引
- 每个查询都要使用索引以提高查询效率, winningPlan. stage 必须为 IXSCAN ;
- 追求 totalDocsExamined = nReturned
3.2.6.4. 索引实战
- 执行 java 生成模拟订单数据程序,向数据库 orders 表插入 100w 条数据;
- 测试下个语句,执行时间超过 300ms,同时解读执行计划
db.orders.find({ "useCode": "james", "orderTime": { "$lt": new Date("2015-04-03T16:00:00.000Z") } }).explain('executionStats')- 1
- 2
- 3
- 4
- 5
- 6
查看:
db.system.profile.find().sort({'$natural':-1}).limit(5).pretty();- 1
- 新建第一个单键索引,解读执行计划:
db.orders.createIndex({"useCode":-1});- 1
解读:有一定的优化效果, winningPlan.stage 为 IXSCAN,但没有达到 totalDocsExamined = nReturned
- 新建一个复合索引,解读执行计划:
db.orders.createIndex({"useCode":-1,"orderTime":-1});- 1
解读:winningPlan.stage 为 IXSCAN,但没有达到 totalDocsExamined = nReturned
- 演示复合索引的使用和索引的顺序是有关系的
db.users.createIndex({username:1,age:-1})- 1
用了索引:
db.users.find().sort({username:1,age:-1}).explain("executionStats") db.users.find().sort({username:-1,age:1}).explain("executionStats")- 1
- 2
不用索引:
db.users.find().sort({username:-1,age:-1}).explain("executionStats")不用索引:
db.users.find().sort({age:-1,username:1}).explain("executionStats")3.2.7. 关于索引的建议
1.索引很有用,但是它也是有成本的——它占内存,让写入变慢;
2.mongoDB 通常在一次查询里使用一个索引,所以多个字段的查询或者排序需要复合索引才能更加高效;
3.复合索引的顺序非常重要
4.在生产环境构建索引往往开销很大,时间也不可以接受,在数据量庞大之前尽量进行查询优化和构建索引;
5.避免昂贵的查询,使用查询分析器记录那些开销很大的查询便于问题排查;
6.通过减少扫描文档数量来优化查询,使用 explain 对开销大的查询进行分析并优化;
7.索引是用来查询小范围数据的,不适合使用索引的情况:
-
每次查询都需要返回大部分数据的文档,避免使用索引
-
写比读多
-
-
相关阅读:
基础算法:二分查找、异或运算
产品经理考个 PMP 有用吗?
学生管理系统之简化学生版(练习版)
python如何使用IP池
设计模式之十一:代理模式
朝花夕拾——数据库基本概念及Mysql基本命令操作
摄像头种类繁多,需要各自APP
flink安装与基础测试
开发一款抖音小游戏大致的研发成本是多少
光学动作捕捉系统构成
- 原文地址:https://blog.csdn.net/yin18827152962/article/details/126451317
