论文信息
论文标题:PairNorm: Tackling Oversmoothing in GNNs
论文作者:Lingxiao Zhao, Leman Akoglu
论文来源:2020,ICLR
论文地址:download
论文代码:download
1 Introduction
GNNs 的表现随着层数的增加而有所下降,一定程度上归结于 over-smoothing 问题,重复图卷积操作会使得节点表示最终变得不可区分。为缓解过平滑问题提出了 PairNorm, 一种归一化方法。
比较可惜的时,该论文在使用了 2022 年的 "Mask" 策略,可惜了实验做的不咋好。为什么失败,见文末。太可惜了...
2 Understanding oversmoothing
Definition
˜Asym=˜D−1/2˜A˜D−1/2~Asym=~D−1/2~A~D−1/2
˜Arw=˜D−1˜A~Arw=~D−1~A
2.1 The oversmoothing problem
2.1.1 Oversmoothing
GNN 性能下降的原因:
-
- 参数数量的增加;
- 梯度消失导致训练困难;
- 图卷积而造成的过平滑;
过平滑的考虑方法如下:当多次使用拉普拉斯平滑导致节点特征收敛到一个平稳点。假设 x⋅j∈Rnx⋅j∈Rn 表示 XX 的第 jj 列,对于任意 x⋅j∈Rnx⋅j∈Rn:
limk→∞˜Aksymx⋅j=πj and πj‖πj‖1=πlimk→∞~Aksymx⋅j=πj and πj∥∥πj∥∥1=π
其中,标准化解 π∈Rnπ∈Rn 满足 πi=√degi∑i√degi for all i∈[n]πi=√degi∑i√degi for all i∈[n]。
Note:ππ 不依赖于节点特征矩阵,而是一个单纯依靠图结构度的函数。
2.1.2 Its Measurement
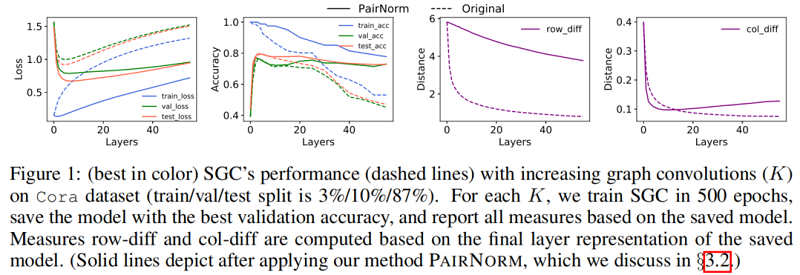
本文提出两种度量过平滑的方式:row-diffrow-diff 和 col-diffcol-diff。
设 H(k)∈Rn×dH(k)∈Rn×d 为第 kk 个图卷积后的节点表示矩阵,即 H(k)=˜AksymXH(k)=~AksymX。设 h(k)i∈Rdh(k)i∈Rd 为 H(k)H(k) 的第 ii 行,h(k).i∈Rnh(k).i∈Rn 为 H(k)H(k) 的第 ii 列。
row-diff(H(k))row-diff(H(k)) 和 col-diff(H(k))col-diff(H(k)) 的定义如下:
row−diff(H(k))=1n2∑i,j∈[n]‖h(k)i−h(k)j‖2(2)row−diff(H(k))=1n2∑i,j∈[n]∥∥h(k)i−h(k)j∥∥2(2)
row-diffrow-diff 量化节点之间的成对距离,而 col-diffcol-diff 特征之间的成对距离。
2.2 Studying oversmoothing with SGC
GCN 过平滑可能由于层数增加导致的性能下降,即添加更多的层导致更多的参数(添加的线性层 存在 W(k)W(k))容易导致过拟合。同样层数增加,容易存在反向传播梯度的消失(应该指的是参数多)。
将层数增加影响过平滑和 使用参数导致过拟合即反向传播梯度消失 解耦。本文使用 SGC ,一种简化的 GCN :去除图卷积层的所有投影参数和所有层间的非线性激活。SGC可写为:
ˆY=softmax(˜AKsymXW)(4)ˆY=softmax(~AKsymXW)(4)
Note:SGC有一个固定数量的参数,不依赖于图卷积的数量(即层),也因此防止了过拟合和消失梯度问题的影响。
Figure 1 中的虚线说明了当增加层数( KK )时,SGC 在 Cora 数据集上的性能。训练(交叉熵)损失随着 KK 的增大而单调地增加,这可能是因为图卷积将节点表示与它们的邻居混合在一起,使它们变得不那么容易区分(训练变得更加困难)。另一方面,至多到 K=4K=4,图卷积(即平滑)提高了泛化能力,减少了训练和验证/测试损失之间的差距,之后,过平滑开始影响性能。row-diffrow-diff 和 col-diffcol-diff 都随 KK 继续单调递减,为过平滑提供了支持证据。
3 Tackling oversmoothing
3.1 Proposed pairnorm
考虑图正则化最小二乘(GRLS):设 ¯X∈Rn×d¯¯¯¯¯X∈Rn×d 是节点表示矩阵,其中 ¯xi∈Rd¯¯¯xi∈Rd 表示 ¯X¯¯¯¯¯X 的第 ii 行,GRLS 问题为:
min¯x∑i∈V‖¯xi−xi‖2˜D+∑(i,j)∈E‖¯xi−¯xj‖22(5)min¯¯¯x∑i∈V∥∥¯¯¯xi−xi∥∥2~D+∑(i,j)∈E∥∥¯¯¯xi−¯¯¯xj∥∥22(5)
其中:
-
- ‖zi‖2˜D=zTi˜Dzi∥zi∥2~D=zTi~Dzi;
第一项可以看作是度加权最小二乘,第二个是一个图正则化项,度量新特征在图结构上的变化。
优化问题的目标可认为是估计新的 “去噪” 特征 ¯xi¯¯¯xi 离输入特征 xixi 不远,并且在图结构上很平滑。
理想情况下,希望获得对同一集群内的节点的平滑,但是避免平滑来自不同集群的节点。Eq.5Eq.5 中的目标通过图正则化项只优化第一个目标。因此,当重复应用卷积时,它容易出现过平滑。为规避这个问题并同时实现这两个目标,可以添加一个负项,如没有边连接对之间的距离之和如下:
min¯x∑i∈V‖¯xi−xi‖2˜D+∑(i,j)∈E‖¯xi−¯xj‖22−λ∑(i,j)∉E‖¯xi−¯xj‖22(6)min¯¯¯x∑i∈V∥∥¯¯¯xi−xi∥∥2~D+∑(i,j)∈E∥∥¯¯¯xi−¯¯¯xj∥∥22−λ∑(i,j)∉E∥∥¯¯¯xi−¯¯¯xj∥∥22(6)
在本文中,没有提出了一个全新的图卷积算子,而是提出了一个通用的、有效的 “补丁”,称为 PAIRNORM,它可以应用于具有过平滑潜力的任何形式的图卷积。
设 ˜X~X(图卷积的输出)和 ˙X˙X 分别为 PAIRNORM 的输入和输出。观察到图卷积 ˜X=˜Asym X~X=~Asym X 的输出实现了第一个目标 度加权,PAIRNORM 作为一个标准化层,在 ˜X~X 上工作,以实现第二个目标,即保持未连接的对表示更远。具体来说,PAIRNORM 将 ˜X~X 归一化,使总成对平方距离 TPSD(˙X):=∑i,j∈[n]‖˙xi−˙xj‖22TPSD(˙X):=∑i,j∈[n]∥∥˙xi−˙xj∥∥22 和 TPSD(X)TPSD(X) 一样:
实践中,不需要时刻关注 TPSD(X) 的值,只需要在所有层使得 TPSD(X) 保持一个恒定的常量 C。
同样地,规范化可以通过一个两步的方法来完成,其中 TPSD 被重写为
TPSD(˜X)=∑i,j∈[n]‖˜xi−˜xj‖22=2n2(1nn∑i=1‖˜xi‖22−‖1nn∑i=1˜xi‖22)(8)
Eq.8 的第一项 表示节点表示的均方长度,第二项描述了节点表示的均值的平方长度。
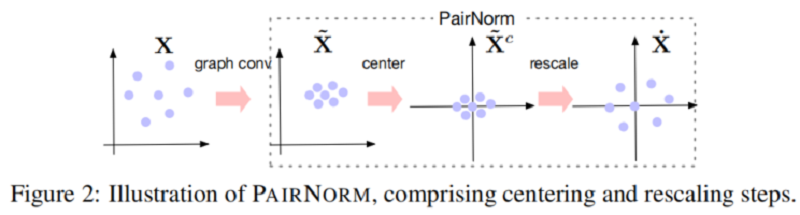
为简化 Eq.8 的计算,令每个 ˜xi 减去行均值 ˜xci=˜xi−1nn∑i˜xi,其中 ˜xci 表示中心表示。这种移动不会影响 TPSD,并且驱动了项 ‖1nn∑i=1˜xi‖22 趋近 0。那么,计算 TPSD(˜X) 可归结为计算 ˜Xc 的 F 范数的平方,并有 O(nd):
TPSD(˜X)=TPSD(˜Xc)=2n‖˜Xc‖2F(9)
Eq.9 可以写成一个两步的、中心和规模的归一化过程:
˜xci=˜xi−1nn∑i=1˜xi(Center)(10)
缩放后,数据保持中心化 ‖n∑i=1˙xi‖22=0 。在 Eq.11 中,s 是一个超参数,它决定了 C。具体来说,
TPSD(˙X)=2n‖˙X‖2F=2n∑i‖s⋅˜xci√1n∑i‖˜xci‖22‖22=2ns21n∑i‖˜xci‖22∑i‖˜xci‖22=2n2s2(12)
然后,˙X:=PAIRNORM(˜X) 拥有行均值为 0 (Center),和恒定的总成对平方距离 C=2n2s2。在 Figure 2 中给出了一对范数的说明。PAIRNORM 的输出被输入到下一个卷积层。
本文还推导出 PAIRNORM 的变体,即通过替换 Eq.11 的 n∑i=1‖˜xci‖22 为 n‖˜xci‖22 ,本文称之为 PAIRNORM-SI ,此时所有的节点都有相同的 L2 范数 s 。
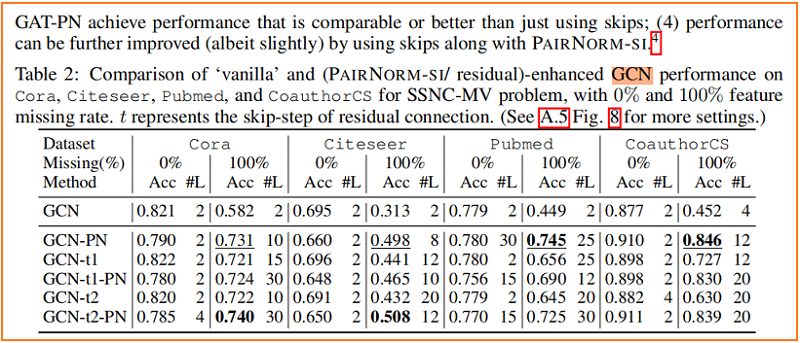
在实践中,发现 PAIRNORM 和 PAIRNORM-SI 对 SGC 都很有效,而 PAIRNORM-SI 对 GCN 和 GAT 提供了更好和更稳定的结果。GCN 和 GAT 需要更严格的归一化的原因可能是因为它们有更多的参数,更容易发生过拟合。在所有实验中,对SGC采用PAIRNORM,对 GCN 和 GAT 采用 PAIRNORM-SI。
Figure 1 中的实线显示了 SGC 性能, 与 “vanilla” 版本相比,随着层数的增加,我们在每个图卷积层之后使用 PAIRNORM。类似地,Figure 3 用于 GCN 和 GAT(在每个图卷积激活后应用PAIRNORM-SI)。请注意,PAIRNORM 的性能衰减要慢得多。

虽然 PAIRNORM 使更深层次的模型对过度平滑更稳健,但总体测试精度没有提高似乎很奇怪。事实上,文献中经常使用的基准图数据集需要不超过 4 层,之后性能就会下降(即使是缓慢的)。
3.2 A case where deeper GNNs are beneficial
假设 M⊆Vu 代表特征缺失子集,其中 ∀m∈M,xm=∅。本文设置 p=|M|/|Vu| 代表缺失比例。将这种任务的变体称为具有缺失向量的半监督节点分类(SSNC-MV)。直观的说,需要更多的传播步骤才能恢复这些节点有效的特征表示。
Figure 4 显示了随着层数的增加,SGC、GCN 和 GAT 模型在 Cora 上的性能变化,其中我们从所有未标记的节点中删除特征向量,即 p=1。与没有PAIRNORM 的模型相比,具有 PAIRNORM 的模型获得了更高的测试精度,它们通常会达到更多的层数。

4 Experiments
在本节中,我们设计了广泛的实验来评估在SSNC-MV设置下的SGC、GCN和GAT模型的有效性。
4.1 Experiment setup

4.2 Experiment results
核心代码:

节点分类


代码以 Deep_GCN 为例子:
5 Conclusion
提出了一种有效防止过平滑问题的 成对范数 ,一种新的归一化层,提高了深度 GNNs 对过平滑的鲁棒性。
6 Reason of failure
即实验对于 mask feature 只处理了一次,并没有在每个 epoch 中进行处理。


__EOF__
