-
课节2: 目标检测任务综述
1.2 目标检测算法基础知识
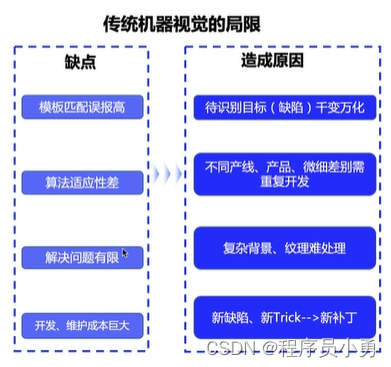
传统目标检测算法

-

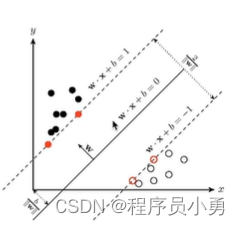
候选区域(Proposal Region):每个AiBj所代表的矩形框,也被称为感兴趣区域(Region of Interest,RoI)
-
SIFT、HOG

-
SVM、Adaboost
-
NMS:过滤框
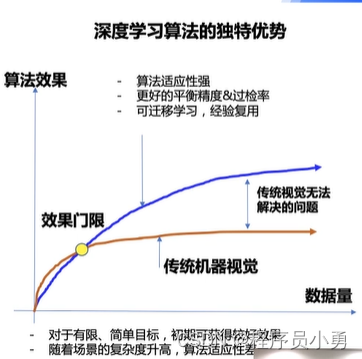
深度学习的优势
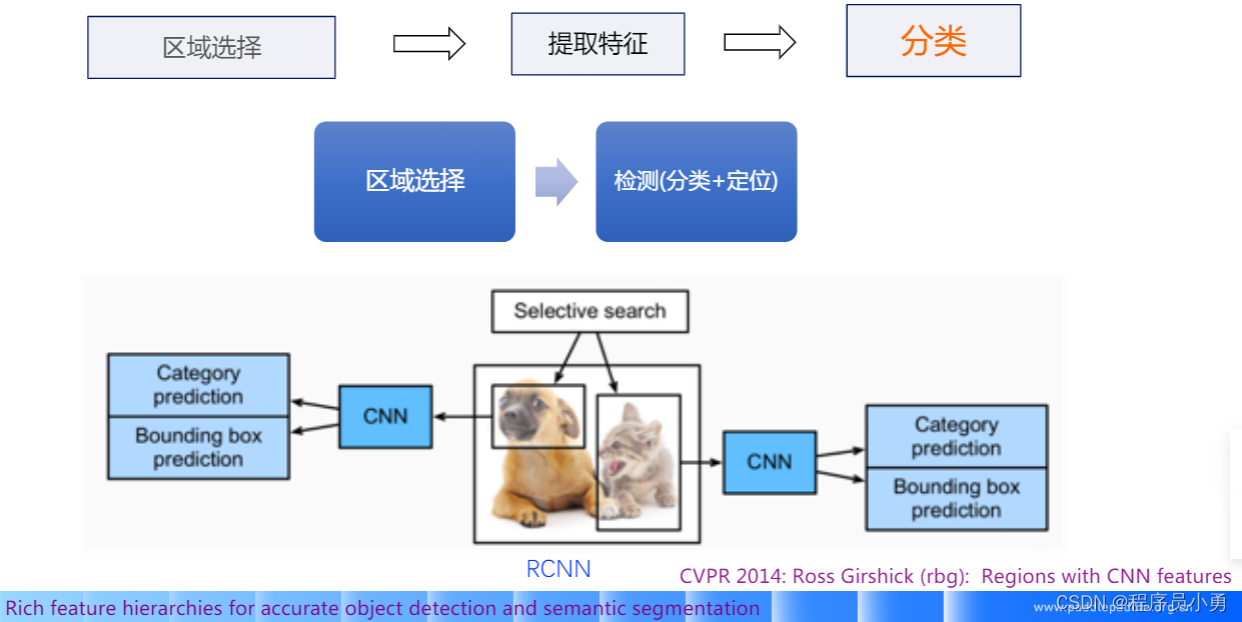
两阶段之RCNN:深度学习方法提取特征
两阶段之Fast/Faster-RCNN
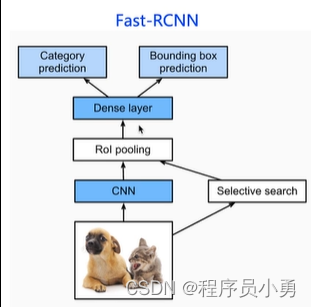
- 引入RoI Pooling操作,解决重复特征提取问题
- 将分类和回归损失统一在同一个框架中
- 通过SS(selective search)提取候选框,速度慢,不是端到端
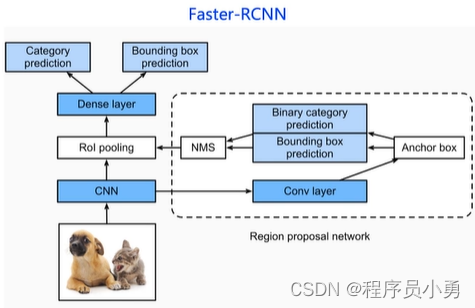
- 通过RPN(Region proposal network)学习候选区域
- 提高了精度,速度快
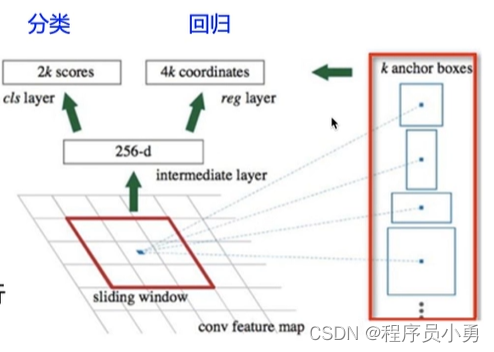
Anchor和Anchor-Based方法
- Anchor(锚框):
- 预先设定好比例的一组候选框集合
- 滑动窗口提取
- Anchor Based Methods:
- 使用Anchor提取候选目标框
- 在特征图上的每一个点,对Anchor进行分类和回归
Anchor-Based方法:两阶段
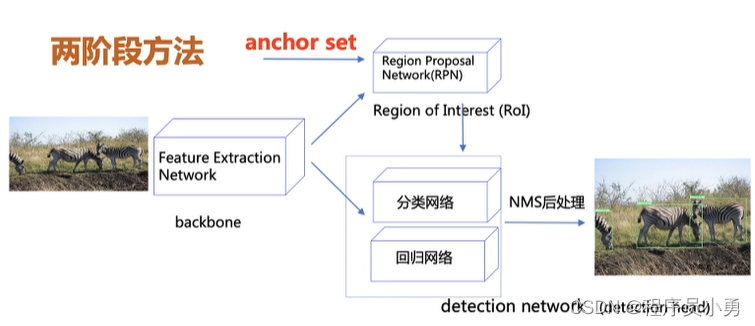
- 两阶段方法:
- 先使用anchor回归候选目标框,划分前景和背景
- 使用候选目标框进一步进行回归和分类,输出最终目标框和对应的类别
- R-CNN系列
- RCNN、Fast-RCNN、FasterRCNN
- FPN、CascadeRCNN、LibraRCNN,…
Anchor-Based方法:一阶段
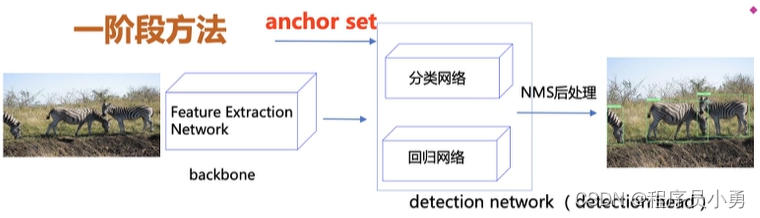
- 一阶段方法:
- 直接对anchor回归和分类最终目标框和类别
- 算法:
- YOLOv2 YOLOv3
- SSD、RetinaNet
Anchor缺点

Anchor-Free方法

- 不再使用预先设定的anchor,通常通过预测目标的中心或者角点,对目标进行检测
- 基于多关键点联合表达的方法:
- CornerNet/CornerNet-lite
- CornerNet:Keypoint Triplets for Object Detection
- RepPoints
- 基于中心区域预测的方法:
- FCOS
- CornerNet:Object as Points
深度学习算法小结
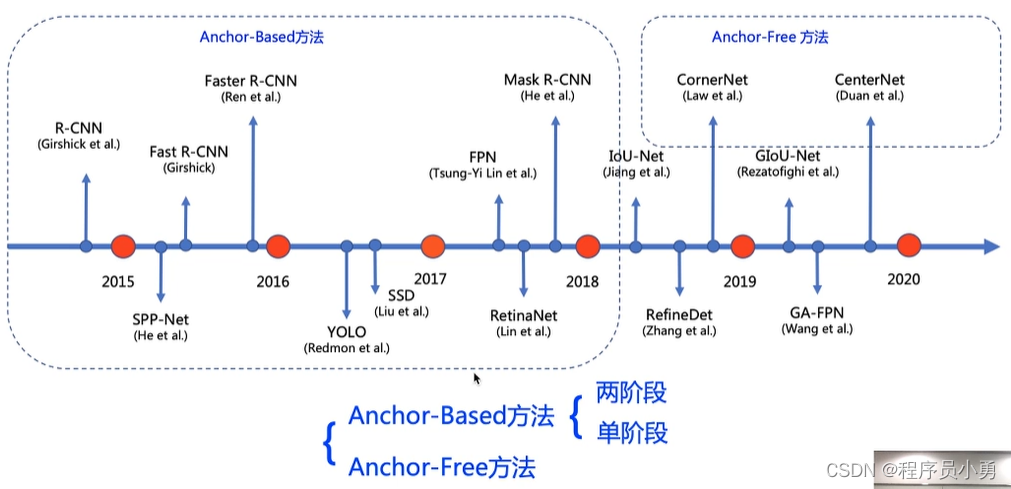
三类算法对比
Anchor-Based单阶段 Anchor-Based两阶段 Anchor-Free 网络结构 简单 复杂 简单 精度 优 更优 较优 预测速度 快 稍慢 快 超参数 较多 多 相对少 扩展性 一般 一般 较好 基础概念
- BBox:Bounding Box,边界框
- 绿色为人工标注的groud-truth,红色为预测结果
- xyxy:左上+右下
- xywh:左上+宽高

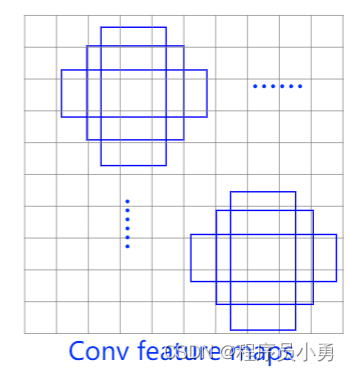
- Anchor:锚框
- 人为设定不同长宽比、面积的先验框
- 在单阶段SSD检测算法中也称Prior box
-
RoI:Region of Interest
- 特定的感兴趣区域
-
Region Proposal
- 候选区域/框
-
RPN:Region Proposal Network
- Anchor-based的两阶段提取候选框的网络
-
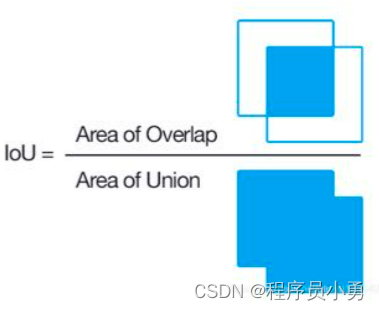
IoU:Intersaction over Union
- 评价预测框的质量,IoU越大则预测框与标注越接近
-
mAP
-
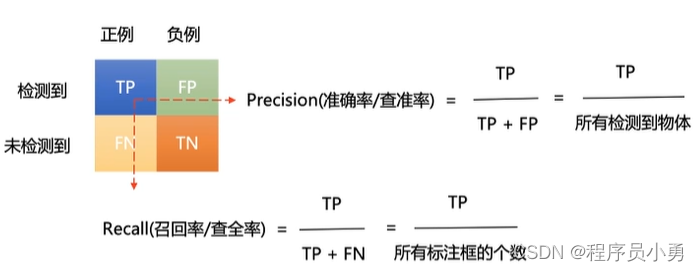
TP:IoU>=阈值(如0.3)检测框数量
-
FP:IoU<阈值(如0.3)检测框数量
-
FN:没有检测到的GT数量
-
举例:
输入样本:某个类别10个框
预测结果:预测到8个框,6个正确,2个错误
Precision:6 / 8 = 0.75
Recall:6 / 10 = 0.6
-
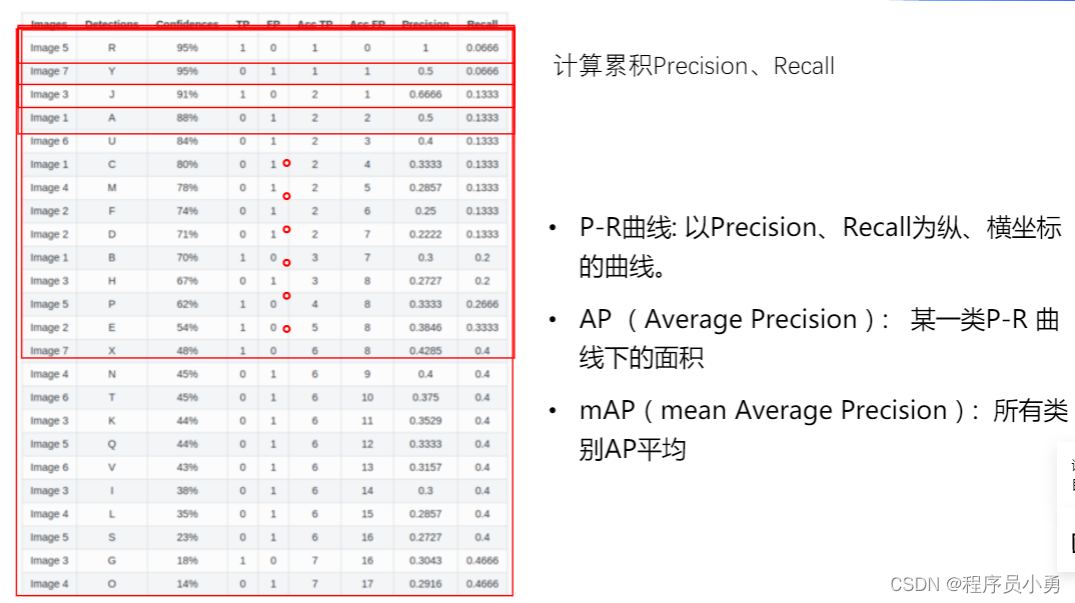
P-R曲线:以Precision、Recall为纵、横坐标的曲线。
-
AP(Average Precision):某一类P-R曲线下的面积
-
mAP(mean Average Precision):所有类别AP平均
-
-
NMS:非极大值抑制,Non-Maximum Suppression

def nms(dets, thresh): # boxes位置 x1 = dets[:, 0] y1 = dets[:, 1] x2 = dets[:, 2] y2 = dets[:, 3] # boxes scores scores = dets[:, 4] areas = (x2 - x1 + 1) * (y2 - y1 + 1) # 各box的面积 order = scores.argsort()[:: -1] # boxes按照score排序 keep = [] # 记录保留下的boxes while order.size > 0; i = order[0] # score最大的box对应的index keep.append(i) # 将本轮score最大的box的index保留 # 计算剩余boxes与当前box的重叠程度IoU xx1 = np.maximum(x1[i], x1[order[1:]]) yy1 = np.maximum(y1[i], y1[order[1:]]) xx2 = np.maximum(x2[i], x2[order[1:]]) yy2 = np.maximum(y2[i], y2[order[1:]]) w = np.maximum(0.0, xx2 - xx1 + 1) h = np.maximum(0.0, yy2 - yy1 + 1) inter = w * h # IoU ovr = inter / (area[i] + area[order[1: ]] - inter) # 保留IoU小于设定阈值的boxes inds = np.where(ovr <= thresh)[0] order = order[inds + 1] return keep- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
常用开源数据集
数据集 类别数 train图片数,box数 val图片数,box数 boxes/Image Pascal VOC-2012 20 5717,1.3万+ 5823,1.3万+ 2.4 COCO 80 118287,4万+ 5000,3.6万+ 7.3 Object365 365 600k,9623k 38k,479k 16 OpenImages18 500 1643042,86万+ 100000,69.6万+ 7.0 - 驱动算法发展
- 业务场景提供预训练
- PaddleDetection提供676类预训练,包含大多数物体,直接使用 或 作为预训练提升业务精度
https://github.com/rafaelpadilla/Object-Detection-Metics
1.3 PaddleDetection
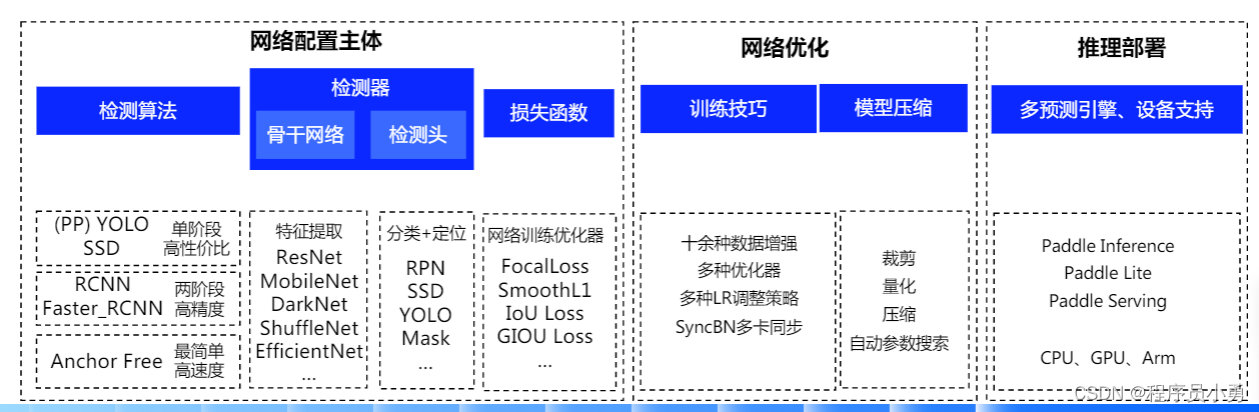
PaddleDetection端到端开发套件

- 自由切换骨干网络、损失函数等,来大幅提升网络性能
- 预置有效优化策略,用户可直接快速试用
PaddleDetection主要特点

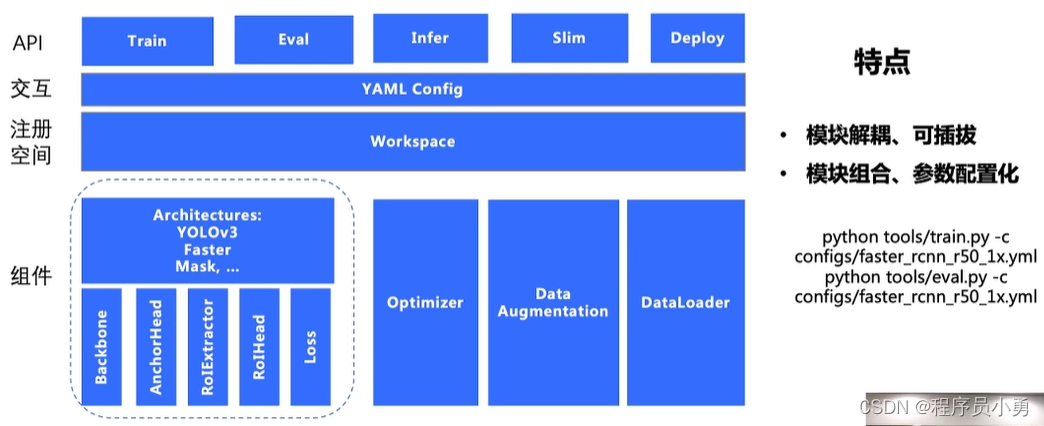
模块化设计
丰富模型库

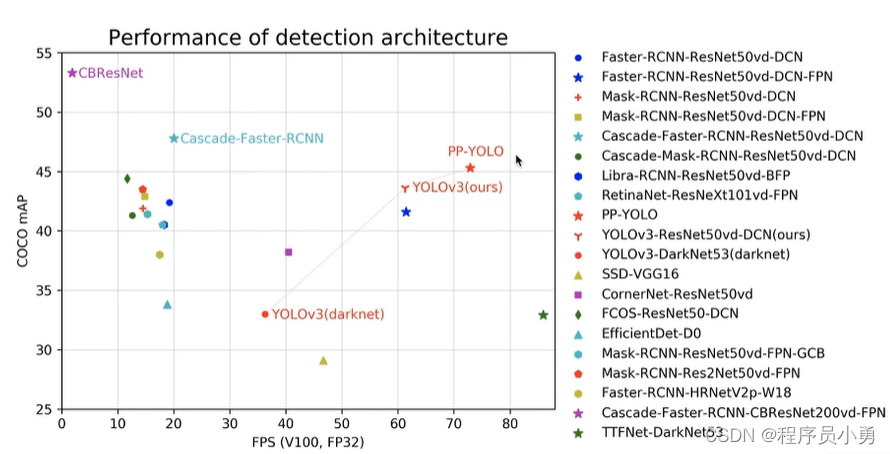
主要模型效果一览
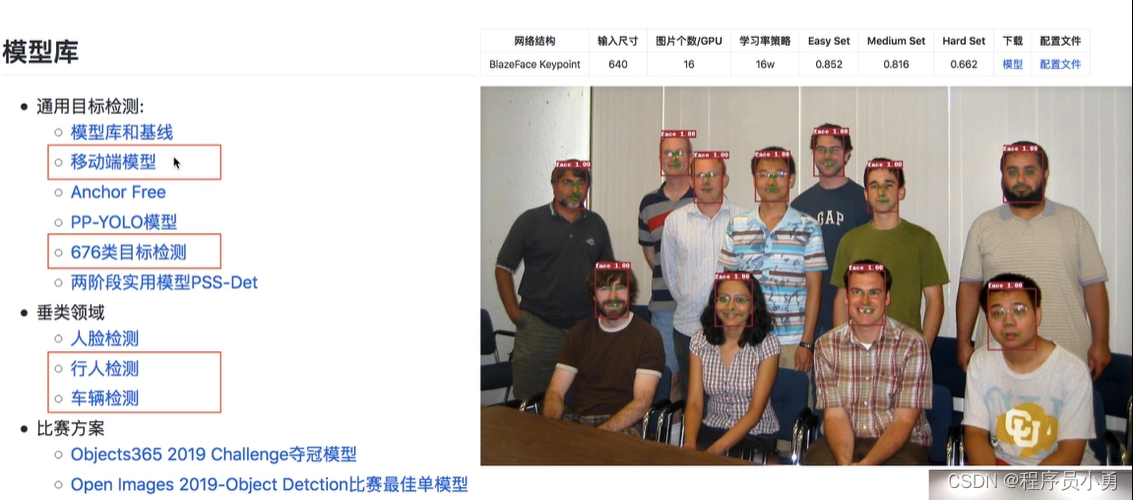
其他特色模型
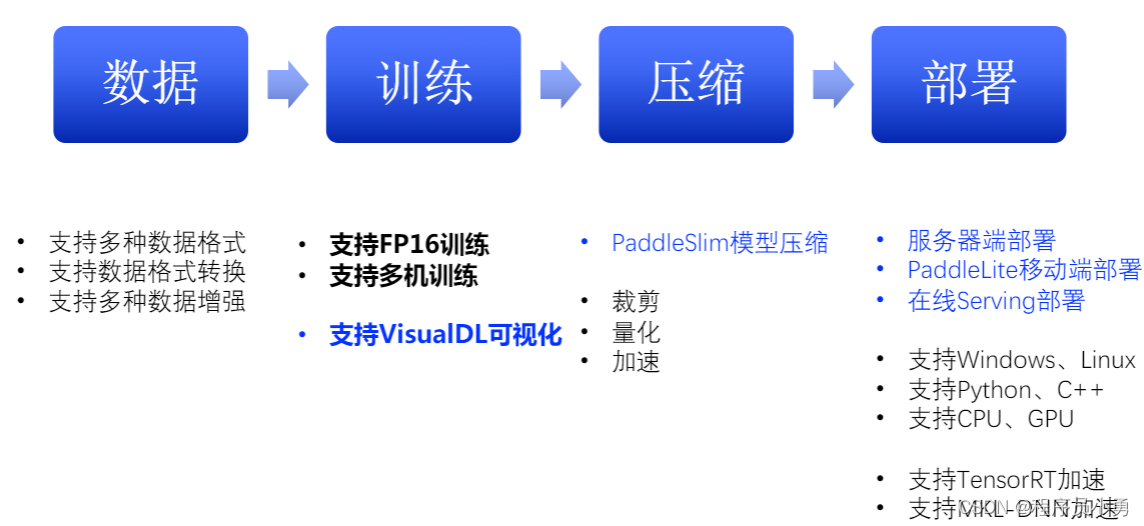
端到端的能力
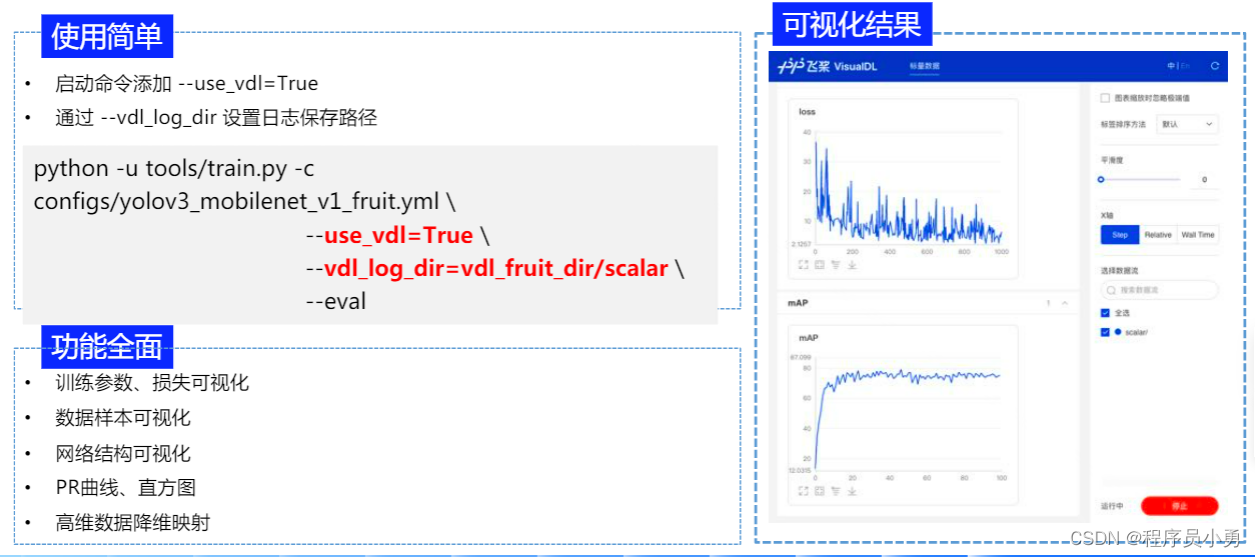
支持VisualDL辅助模型优化
- 可视化训练过程中的指标,如Loss和mAP,实时监控模型训练过程。
支持模型压缩
https://github.com/PaddlePaddle/PaddleSlim
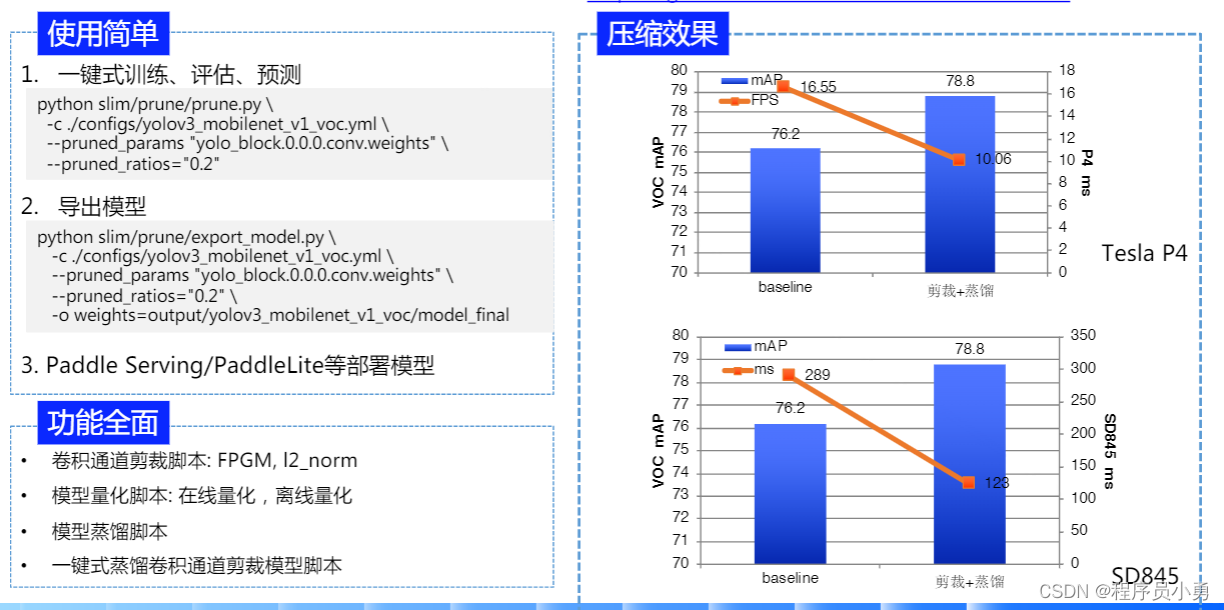
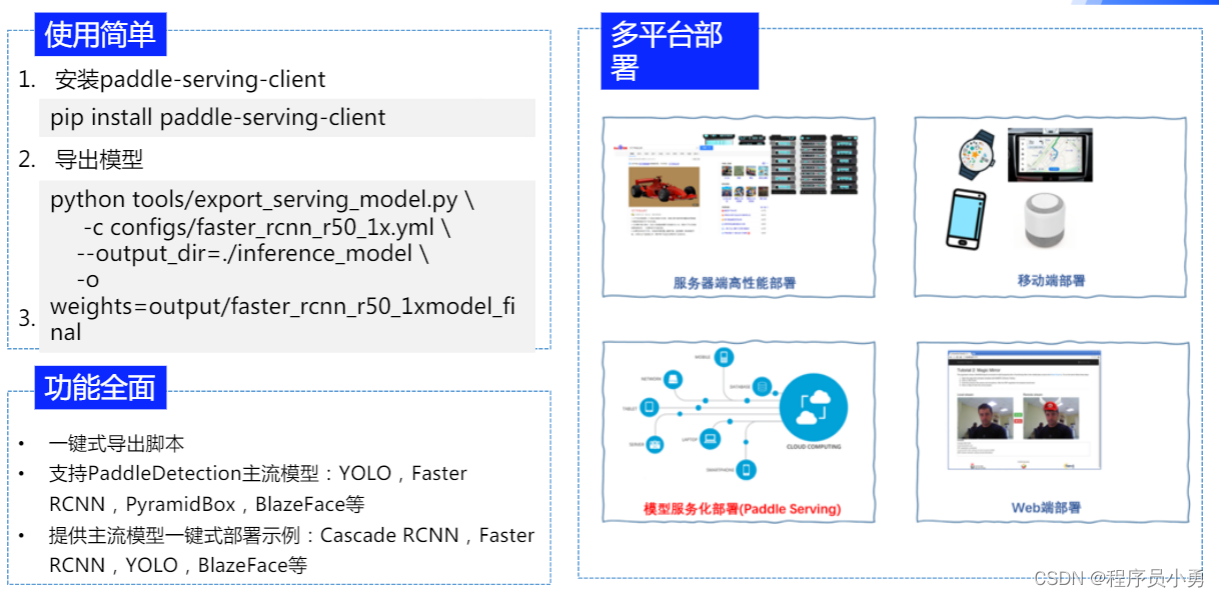
支持移动端部署

支持服务部署
-
-
相关阅读:
大数据常见面试题:1
LeetCode-组合总和 II
矢量绘图软件 Sketch mac中文版介绍
前端研习录(08)——文档流
大模型全情投入,低代码也越来越清晰
25 环形链表
论文阅读——Co-Salient Object Detection with Co-Representation Purification
中国制霸生成器「GitHub 热点速览 v.22.42」
业务及系统架构对发布的影响
dubbo源码解析之服务发布与注册
- 原文地址:https://blog.csdn.net/weixin_43909650/article/details/126448914
