-
数据结构与算法(java版)第二季 - 1 冒泡、选择、堆排序
初识排序
什么叫排序?
排序前:3,1,6,9,2,5,8,4,7 排序后:1,2,3,4,5,6,7,8,9(升序) 或者 9,8,7,6,5,4,3,2,1(降序)排序的应用

十大排序算法

冒泡排序(Bubble Sort)
◼ 冒泡排序也叫做起泡排序◼ 以升序为例子① 从头开始比较每一对相邻元素,如果第1个比第2个大,就交换它们的位置✓ 执行完一轮后,最末尾那个元素就是最大的元素② 忽略 ① 中曾经找到的最大元素,重复执行步骤 ①,直到全部元素有序代码- public class Bubble_Sort {
- public static void main(String[] args) {
- int[] array = {10,9,20,36,89,45,65,15,64,47};
- //进行一个冒泡排序的过程
- for(int end = array.length-1 ; end > 0;end--) {
- for (int begin = 1; begin <= end; begin++) {
- if (array[begin] < array[begin - 1]) {
- int tmp = array[begin];
- array[begin] = array[begin - 1];
- array[begin - 1] = tmp;
- }
- }
- }
- //进行一个遍历的操作
- for(int i = 0;i < array.length;i++)
- {
- System.out.println(" " + array[i]);
- }
- }
- }
冒泡排序 - 优化一
如果给定的数据就是有序的,可以提前终止排序.

- static void bubbleSort2(Integer[] array)
- {
- //生成一个随机数字
- //Integer[] array = Integers.random(10,1,100);
- // 生成一个随机数字,由于jdk的版本,这个版本的java没有这个东西
- //打印可以使用Integers.println(array)
- /*
- Times.test("冒泡排序",null);
- */
- //进行一个冒泡排序的过程
- for(int end = array.length-1 ; end > 0;end--) {
- //标记是否有序,放在这个位置的原因是在扫描的过程可能就是有序的
- boolean sorted = true;
- for (int begin = 1; begin <= end; begin++) {
- //一旦这个条件是有序的,说明这个就是无序的
- if (array[begin] < array[begin - 1]) {
- int tmp = array[begin];
- array[begin] = array[begin - 1];
- array[begin - 1] = tmp;
- sorted = false;//如果要是能进来说明无序
- }
- }
- //只要是检测到排序的过程中,已经排好了,直接跳出即可.
- if(sorted) break;
- }
- //进行一个遍历的操作
- for(int i = 0;i < array.length;i++)
- {
- System.out.println(array[i]);
- }
- }
上述代码用到了一个测试时间的java类,Times.class代码是如下所示:
- import java.text.SimpleDateFormat;
- import java.util.Date;
- public class Times {
- private static final SimpleDateFormat fmt = new SimpleDateFormat("HH:mm:ss.SSS");
- public Times() {
- }
- public static void test(String title, Times.Task task) {
- if (task != null) {
- title = title == null ? "" : "【" + title + "】";
- System.out.println(title);
- System.out.println("开始:" + fmt.format(new Date()));
- long begin = System.currentTimeMillis();
- task.execute();
- long end = System.currentTimeMillis();
- System.out.println("结束:" + fmt.format(new Date()));
- double delta = (double)(end - begin) / 1000.0D;
- System.out.println("耗时:" + delta + "秒");
- System.out.println("-------------------------------------");
- }
- }
- public interface Task {
- void execute();
- }
- }
注意:上述的优化过程,只有在数据是提前有序的时候才会花费的时间更少,否则的话,运行的时间还是非常长的.
冒泡排序 - 优化二
如果序列尾部已经局部有序,可以记录最后1次交换的位置,减少比较次数. 由上图观察可知,最后一个需要进行交换的6位置的数据,如果我们是提前可以观察到相应的示意图,就是可以不用进行理会后面的数据的.
由上图观察可知,最后一个需要进行交换的6位置的数据,如果我们是提前可以观察到相应的示意图,就是可以不用进行理会后面的数据的.- static void bubbleSort3(Integer[] array)
- {
- //进行一个冒泡排序的过程
- for(int end = array.length-1 ; end > 0;end--) {
- //用来记录哪一个是已经替换好的,这里的初始值是存在一些讲究的
- //sortedIndex的初始值在数组完全有序的时候有用
- int sortedIndex = 0;
- for (int begin = 1; begin <= end; begin++) {
- //一旦这个条件是有序的,说明这个就是无序的
- if (array[begin] < array[begin - 1]) {
- int tmp = array[begin];
- array[begin] = array[begin - 1];
- array[begin - 1] = tmp;
- //直接记录最后一次扫描的位置
- sortedIndex = begin;
- }
- end = sortedIndex;
- }
- }
- //进行一个遍历的操作
- for(int i = 0;i < array.length;i++)
- {
- System.out.println(array[i]);
- }
- }
最坏、平均时间复杂度: O(n^ 2 )最好时间复杂度: O(n)空间复杂度: O(1) [没有用到额外的空间]排序算法的稳定性(Stability)
◼ 如果相等的2个元素,在排序前后的相对位置保持不变,那么这是 稳定 的排序算法 排序前: 5, 1, 3 𝑎 , 4, 7, 3 𝑏 稳定的排序: 1, 3 𝑎 , 3 𝑏 , 4, 5, 7 不稳定的排序: 1, 3 𝑏 , 3 𝑎 , 4, 5, 7◼ 对自定义对象进行排序时,稳定性会影响最终的排序效果◼ 冒泡排序属于稳定的排序算法(只有当右边的小于左边的才会进行一个交换)稍有不慎,稳定的排序算法也能被写成不稳定的排序算法,比如下面的冒泡排序代码是不稳定的
原地算法(In-place Algorithm)
◼ 何为原地算法? 不依赖额外的资源或者依赖少数的额外资源,仅依靠输出来覆盖输入 空间复杂度为 𝑂(1) 的都可以认为是原地算法◼ 非原地算法,称为 Not-in-place 或者 Out-of-place◼ 冒泡排序属于 In-place选择排序(Selection Sort)
◼ 执行流程① 从序列中找出最大的那个元素,然后与最末尾的元素交换位置✓ 执行完一轮后,最末尾的那个元素就是最大的元素② 忽略 ① 中曾经找到的最大元素,重复执行步骤 ①◼ 选择排序的交换次数要远远少于冒泡排序,平均性能优于冒泡排序◼ 最好、最坏、平均时间复杂度: O(n^ 2 ) ,空间复杂度: O(1) ,属于稳定排序Asserts.test(判断语句);//可以得到判断语句是否是正确的选择排序还是有优化的空间,使用堆的方式.
选择排序的优化 - 堆数据结构
堆排序是选择排序的一种优化◼ 执行流程① 对序列进行原地建堆(heapify)② 重复执行以下操作,直到堆的元素数量为 1✓ 交换堆顶元素与尾元素✓ 堆的元素数量减 1✓ 对 0 位置进行 1 次 siftDown 操作- 对下面的元素进行原地建堆

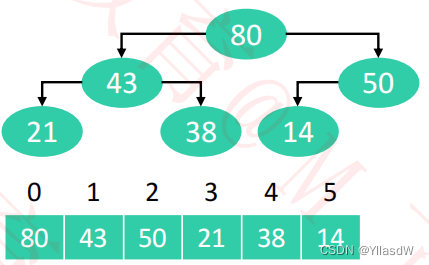
- 将堆顶元素拿出来,放到最后面,并且进行一个下滤操作,操作如下所示

- 重复上一步操作,直到元素0位置是最小的.

- 最好、最坏、平均时间复杂度:O(nlogn),空间复杂度:O(1),属于不稳定排序
原始的比较代码的写法
- protected void sort() {
- for(int end = array.length -1;end > 0;end--)
- {
- int maxIndex = array[0];
- for(int begin = 1;begin <= end;begin++)
- {
- if(array[maxIndex] <= array[begin]) //<=的原因是要使用稳定的排序算法
- {
- maxIndex = begin;
- }
- }
- int temp = array[maxIndex];
- array[maxIndex] = array[end];
- array[end] = temp;
- }
- }
但是上述的代码在使用的过程中,交换和比较函数是可以进行提出来的,因此,可以直接进行一个类的外部声明,然后进行调用即可.
父类Sort的写出
- import com.sun.xml.internal.ws.api.model.wsdl.WSDLOutput;
- import java.util.Arrays;
- public abstract class Sort implements Comparable
{ - protected Integer[] array;
- protected int cmpCount;//进行一个比较的次数
- protected int swapCount;//进行交换的此时
- private long time;//记录执行时间
- public void sort(Integer[] array)
- {
- if(array == null || array.length < 2) return;
- this.array = array;
- long begin = System.currentTimeMillis();
- sort();
- time = System.currentTimeMillis() - begin;
- }
- protected abstract void sort();
- private String numberString(int number)
- {
- if(number < 10000) return number + " ";//注意这里是返回字符串,因此,必须要加一个" "
- if(number < 100000000) return number/10000.0 + "万";
- return number/100000000.0 + "亿";
- }
- /*
- 返回值等于0,代表array[i1] == array[i2]
- 返回值小于0,代表array[i1] < array[i2]
- 返回值大于0,代表array[i1] > array[i2]
- */
- protected int cmp(int i1,int i2)
- {
- cmpCount++;
- return array[i1] - array[i2];
- }
- protected int cmpElements(Integer v1,Integer v2)
- {
- cmpCount++;
- return v1 - v2;
- }
- protected void swap(int i1,int i2)
- {
- swapCount++;
- int tmp = array[i1];
- array[i1] = array[i2];
- array[i2] = tmp;
- }
- @Override
- public String toString() {
- return "Sort{" +
- "array=" + Arrays.toString(array) +
- ", cmpCount=" + cmpCount +
- ", swapCount=" + swapCount +
- ",Consume Time =" + time/1000.000 +
- '}';
- }
- public int compareTo(Sort o) {
- int result = (int)(time - o.time);
- if(result != 0) return result;
- result = cmpCount - o.cmpCount;
- if(result != 0) return result;
- return swapCount - o.swapCount;
- }
- }
子类SelectionSort代码是如下所示:
- public class SelectionSort extends Sort{
- protected void sort() {
- for(int end = array.length -1;end > 0;end--)
- {
- int maxIndex = array[0];
- for(int begin = 1;begin <= end;begin++)
- {
- // if(array[maxIndex] <= array[begin]) //<=的原因是要使用稳定的排序算法
- if(cmp(maxIndex,begin) <= 0)
- {
- maxIndex = begin;
- }
- }
- // int temp = array[maxIndex];
- // array[maxIndex] = array[end];
- // array[end] = temp;
- swap(maxIndex,end);
- }
- }
- }
前面的BubbuleSort也是可以进行一个改正的过程,比较好理解,懒得改了.
堆排序HeapSort
- public class HeapSort extends Sort{
- //1.记录堆里面的数据
- private int heapSize;
- protected void sort() {
- //2.原地建堆 - 将array之中的元素变成一个堆
- heapSize = array.length;
- for(int i = (heapSize >>1) -1;i >= 0;i--)
- {
- siftDown(i);
- }
- //3.交换堆顶的元素与尾部的元素
- while(heapSize > 1)
- {
- swap(0,heapSize-1);
- //4.将堆之中的数据减少
- heapSize--;
- //5.对0位置进行siftDown(恢复堆的性质)
- siftDown(0);
- }
- }
- /**
- * 让index位置的元素下滤
- * @param index
- */
- private void siftDown(int index) {
- Integer element = array[index];
- int half = heapSize >> 1;
- // 第一个叶子节点的索引 == 非叶子节点的数量
- // index < 第一个叶子节点的索引
- // 必须保证index位置是非叶子节点
- while (index < half) {
- // index的节点有2种情况
- // 1.只有左子节点
- // 2.同时有左右子节点
- // 默认为左子节点跟它进行比较
- int childIndex = (index << 1) + 1;
- Integer child = array[childIndex];
- // 右子节点
- int rightIndex = childIndex + 1;
- // 选出左右子节点最大的那个
- if (rightIndex < heapSize && cmpElements(array[rightIndex], child) > 0) {
- child = array[childIndex = rightIndex];
- }
- if (cmpElements(element, child) >= 0) break;
- // 将子节点存放到index位置
- array[index] = child;
- // 重新设置index
- index = childIndex;
- }
- array[index] = element;
- }
- }
-
相关阅读:
NLP模型(一)——word2vec实现
【JavaWeb】案例:使用 Servlet 技术完成一个用户登录
internship:一般的原有项目功能优化的具体步骤
SaaSBase:什么是Asana?
【云原生之kubernetes实战】在k8s环境下部署Monica个人交际关系管理系统
Redis缓存雪崩、击穿、穿透
大数据学习(2)Hadoop-分布式资源计算hive(1)
ardupilot 关于设备车Rover的学习《2》------如何解锁
vue项目优化
探讨Linux CPU的上下文切换原由
- 原文地址:https://blog.csdn.net/m0_47489229/article/details/126436203
