-
【论文】《Identity Mappings in Deep Residual Networks》论文阅读笔记
论文:https://arxiv.org/pdf/1603.05027.pdf
代码:GitHub - KaimingHe/resnet-1k-layers: Deep Residual Networks with 1K Layers
fb.resnet.torch/pretrained at master · facebookarchive/fb.resnet.torch · GitHub
1.摘要
在本文中,分析了残差构建块背后的传播公式。以及通过更深的网络结构resnet1001,得到了更好的效果。
2.介绍
ResNets的中心思想是学习与h(xl)有关的加性残差函数F,其中一个关键选择是使用映射h(xl) = xl . 这是通过附加一个跳过连接("捷径")来实现的。
分析深层残余网络时,重点是创造一条传播信息的 "直接 "路径--不仅是在一个残余单元内,而且是通过整个网络。
发现(1):
在调查的所有变体中,[1]中选择的映射h(xl)=xl实现了最快的错误减少和最低的训练损失,而缩放、门控[5,6,7]和1×1卷积的跳过连接都导致了更高的训练损失和错误。实验表明,保持一个 "干净 "的信息路径。
发现(2):
(b)中的预激活方式比(a)中后激活方式效果更好。获得更低的训练与测试loss,与更高的精度。
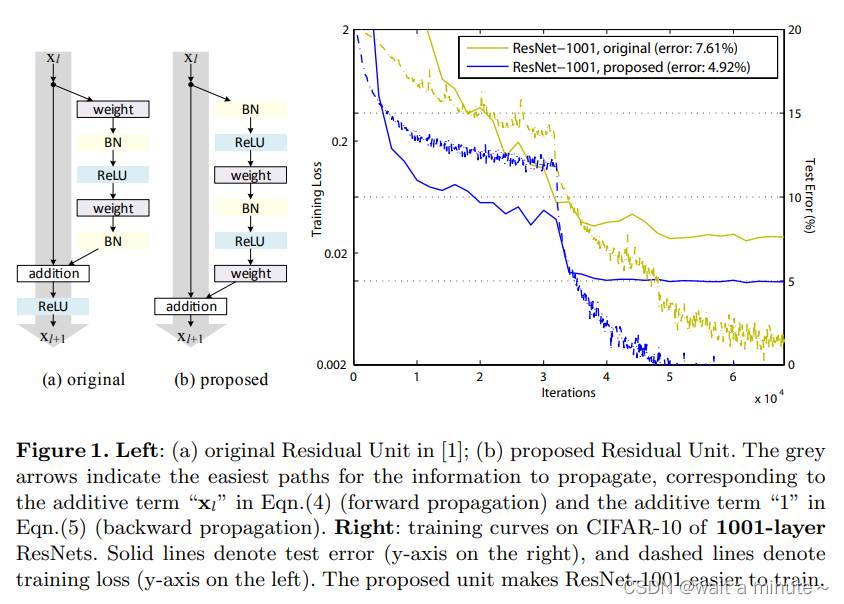
3.深度残差网络的分析
当h(xl)=xl时,任意深层特征XL可以由任意浅层特征Xl加上残差函数。

求导之后,
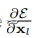 与weights无关,所以也梯度反向传播的过程中不会出现梯度消息现象。
与weights无关,所以也梯度反向传播的过程中不会出现梯度消息现象。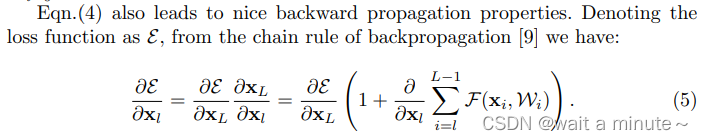
这表明信号可以从任何单元直接传播到另一个单元,包括向前和向后传播。
4.论直接跳过连接的重要性
如果在Xl前添加一个调制参数,会阻碍反向传播与训练。可能会丢失信息或者反向传播时,会出现梯度消失(调制参数<1)或者爆炸(调制参数>1)。

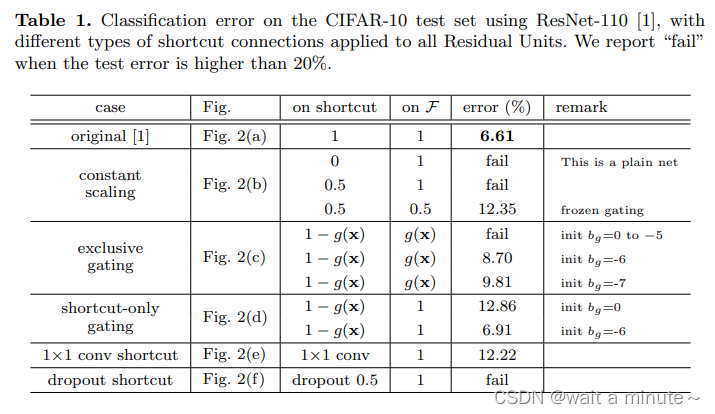
实验(给以不同的调制方式):

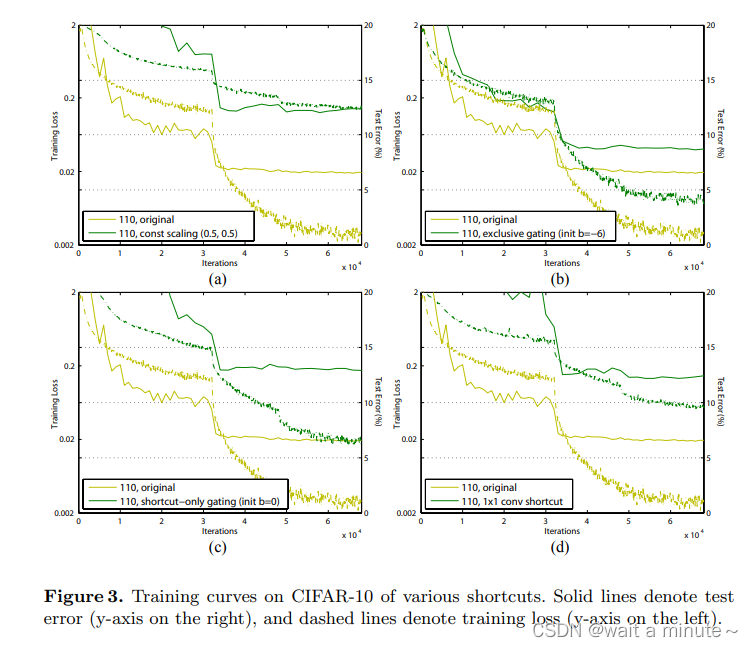
后面就是大面积的通过消融实验证明“预激活”比“后激活”好。
结论:对捷径进行乘法操作(缩放、门控、1×1卷积和剔除)会妨碍信息传播并导致优化问题。
5.关于激活功能的使用
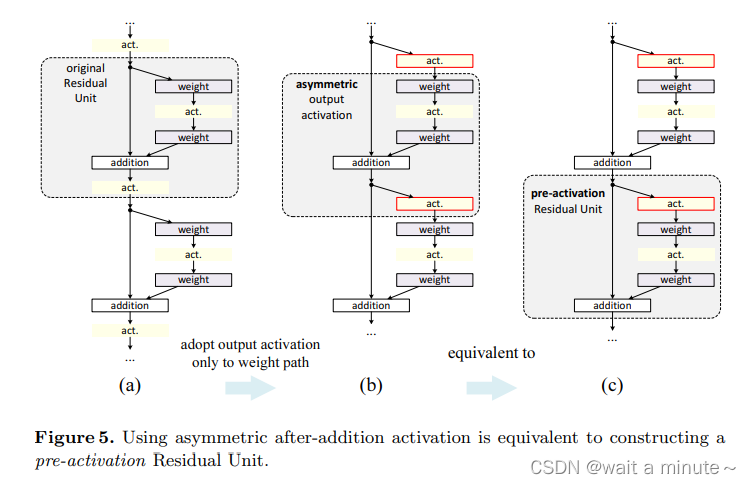
其中b与c等价
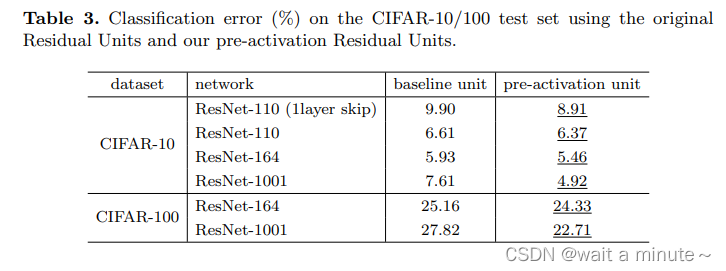
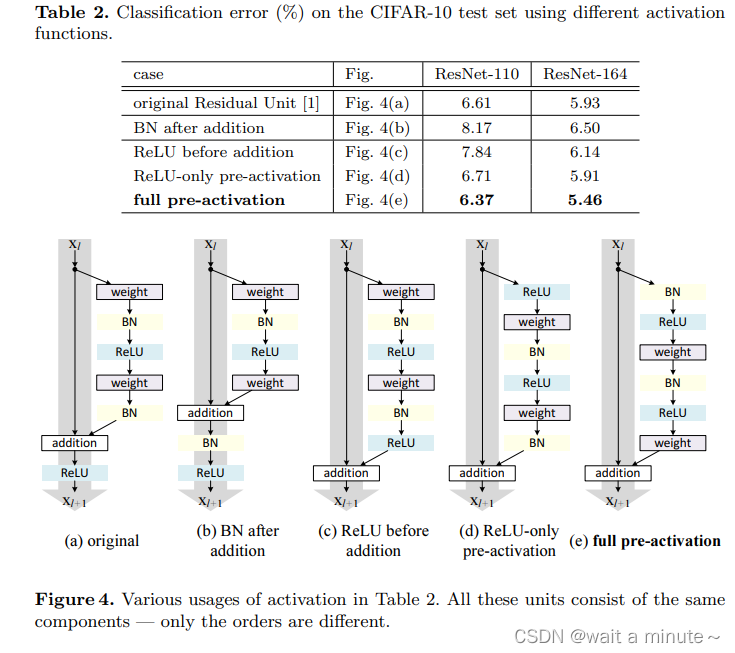
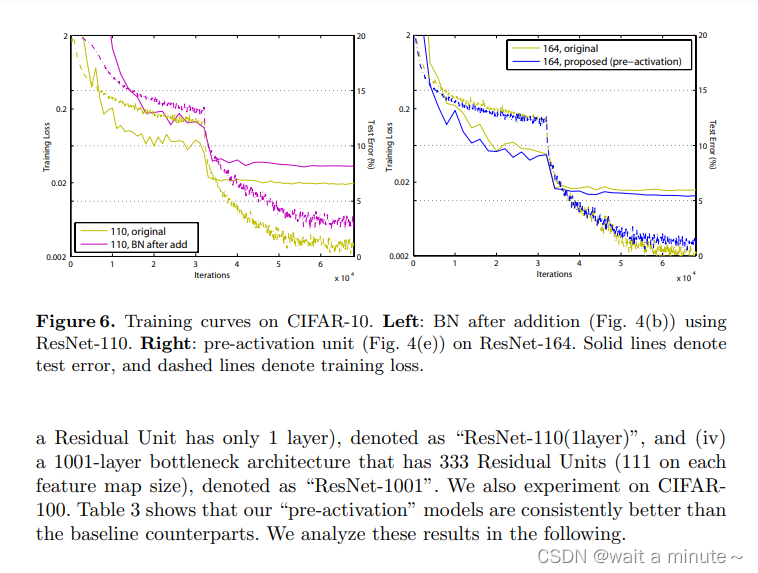 上面一表一图主要说明pre-activation有效。更容易优化,也可以缓解过拟合。
上面一表一图主要说明pre-activation有效。更容易优化,也可以缓解过拟合。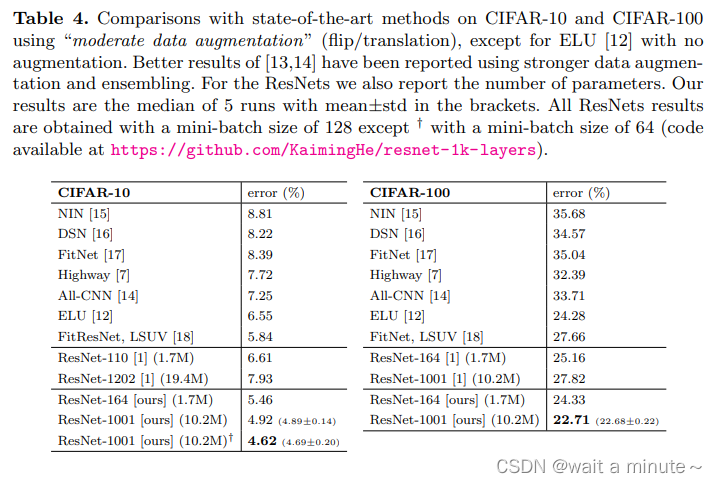
-
相关阅读:
C++ //练习 15.4 下面哪条声明语句是不正确的?清解释原因。
Flink cdc 2.3.0 日前发布,支持众多新特性
HarmonyOS 自定义抽奖转盘开发(ArkTS)
全文解读 | 五部委印发:元宇宙产业创新发展三年行动计划(2023-2025年)
NPDP考试需要携带什么?文具携带说明
Zookeeper选举Leader源码剖析(二)
Python 实战:用 Scrapyd 打造个人化的爬虫部署管理控制台
Baichuan 2: Open Large-scale Language Models
macbook电脑磁盘满了怎么删东西?
流程图如何制作?好用的11款流程图软件盘点!
- 原文地址:https://blog.csdn.net/qq_35975447/article/details/126335842