-
构造器模式与原型模式
如果大家觉得文章有错误内容,欢迎留言或者私信讨论~
构造器模式的应用场景
构造器模式,也可以叫做生成器模式,它的原理和实现方式非常简单,难点在于选择合适的应用场景。
在我们的日常开发中,创建一个对象常用的方法就是使用new关键词来调用类的构造函数来完成,你认为在什么场景下就不适用了呢?比如,现在我们需要创建一个连接池的配置对象,我们都知道像这种配置对象,一般都伴随着大量的属性,像是name、maxTotal、maxIdel、minIdel等等,如果我们选择以构造函数的方式去创建对象,那么属性只有 3、4 个还好说,当属性逐渐膨胀到 10 个以上,那么这个构造函数的可读性就很变得很差,并且在日后的迭代还可能会因为参数过多而导致其他不熟悉该配置类的程序员传错参数。
你可能会觉得,那么根据无参构造函数创建对象,随后再 set 属性值就可以显得很简单清晰了啊。如果我们希望连接池对象是不可变类,也就是说,对象在创建之后,就不能再修改内部的属性值,要实现这个对象,我们就不能暴露set方法。除此之外,假设配置项之间有依赖关系,比如用户设置了maxTotal,就必须设置maxIdle或者minIdle其中过一个,我们就需要编写约束条件的校验逻辑。如果继续使用set方法,那么这些约束条件的逻辑就无处安放了。
为了解决这些条件,建造者模式就派上用场了。构造器模式的具体实现
那么现在,我们可以将校验逻辑放到
Builder类中,先创建建造者,并且通过set()方法设置创建者的变量值,然后在使用 build() 方法真正创建对象之前,做集中的校验,校验通过之后才会创建对象。除此之外,我们还需要把类的构造器函数改为private私有权限,并且不提供set方法。
具体代码如下:public class ResourcePoolConfig { private String name; private int maxTotal; private int maxIdle; private int minIdle; private ResourcePoolConfig(Builder builder) { this.name = builder.name; this.maxTotal = builder.maxTotal; this.maxIdle = builder.maxIdle; this.minIdle = builder.minIdle; } //...省略getter方法... //我们将Builder类设计成了ResourcePoolConfig的内部类。 //我们也可以将Builder类设计成独立的非内部类ResourcePoolConfigBuilder。 public static class Builder { private static final int DEFAULT_MAX_TOTAL = 8; private static final int DEFAULT_MAX_IDLE = 8; private static final int DEFAULT_MIN_IDLE = 0; private String name; private int maxTotal = DEFAULT_MAX_TOTAL; private int maxIdle = DEFAULT_MAX_IDLE; private int minIdle = DEFAULT_MIN_IDLE; public ResourcePoolConfig build() { // 校验逻辑放到这里来做,包括必填项校验、依赖关系校验、约束条件校验等 if (StringUtils.isBlank(name)) { throw new IllegalArgumentException("..."); } if (maxIdle > maxTotal) { throw new IllegalArgumentException("..."); } if (minIdle > maxTotal || minIdle > maxIdle) { throw new IllegalArgumentException("..."); } return new ResourcePoolConfig(this); } public Builder setName(String name) { if (StringUtils.isBlank(name)) { throw new IllegalArgumentException("..."); } this.name = name; return this; } public Builder setMaxTotal(int maxTotal) { if (maxTotal <= 0) { throw new IllegalArgumentException("..."); } this.maxTotal = maxTotal; return this; } public Builder setMaxIdle(int maxIdle) { if (maxIdle < 0) { throw new IllegalArgumentException("..."); } this.maxIdle = maxIdle; return this; } public Builder setMinIdle(int minIdle) { if (minIdle < 0) { throw new IllegalArgumentException("..."); } this.minIdle = minIdle; return this; } } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
使用构造器模式,我们需要重点掌握应用场景,避免过度使用。如果拿构造器模式于工厂模式相比的话,网上有一个经典的例子很好地解释了两者的区别。顾客走进一家餐馆点餐,我们利用工厂模式,根据用户不同的选择,来制作不同的食物,比 如披萨、汉堡、沙拉。对于披萨来说,用户又有各种配料可以定制,比如奶酪、西红柿、起司,我们通过建造者模式根据用户选择的不同配料来制作披萨。
原型模式的案例讲解
原型模式同工厂模式、构造器模式一样,也是创建型设计模式,主要是利用已有的对象进行复制(或者叫拷贝)的方式创建新对象,以达到节省创建时间的目的,应用于对象的创建成本比较大的场景。
- 那为何对象的“创建成本比价大”
实际上,创建对象包含的申请内存、给成员变量赋值这一过程,对于大部分的业务系统来说,这点时间完全可以忽略不计。应用一个复杂的设计模式,却只得到一点点的性能提升,这反而得不偿失。
但是,如果对象中的数据需要经过复杂的计算才能得到,或者要从 RPC、网络、数据库、文件系统等非常慢速的 IO 中读取,我们就需要应用到原型模式,从其他已知的对象中拷贝。那么回到我们的案例上,假设数据库中存储了大约 10 万条“搜索关键词”信息,每条信息包含关键词、关键词被搜索的次数、信息最近被更新的时间等。系统 A 在启动的时候会加载这份数据到内存中,用于处理某些其他的业务需求。为了方便快速地查找某个关键词对应的信息,我们给关键词建立一个散列表索引,Java 中可以直接使用 HashMap。
不过,我们还有另外一个系统 B,专门用来分析搜索日志,定期(比如间隔 10 分钟)批量地更新数据库中的数据,并且标记为新的数据版本。比如,在下面的示例图中,我们对 v2版本的数据进行更新,得到 v3 版本的数据。这里我们假设只有更新和新添关键词,没有删除关键词的行为。

为了保证系统 A 中数据的实时性(不一定非常实时,但数据也不能太旧),系统 A 需要定期根据数据库中的数据,更新内存中的索引和数据。
实际上也不难,我们只要再系统 A 中,记录当前数据的版本 Va 对应的更新时间 Ta,从数据库中捞出更新时间大于 Ta 的所有搜索词,也就是找出 Va 版本与最新版本数据的“差集”,然后针对差集中的每个关键词进行处理。如果散列表中已经存在了,我们就更新相应的搜索次数、更新时间等信息;如果它在散列表中不存在,我们就将它插入到散列表中。
按照这个设计思路,我给出的示例代码如下所示:public class Demo { private ConcurrentHashMap<String, SearchWord> currentKeywords = new ConcurrentHashMap<>(); private long lastUpdateTime = -1; public void refresh() { // 从数据库中取出更新时间>lastUpdateTime的数据,放入到currentKeywords中 List<SearchWord> toBeUpdatedSearchWords = getSearchWords(lastUpdateTime); long maxNewUpdatedTime = lastUpdateTime; for (SearchWord searchWord : toBeUpdatedSearchWords) { if (searchWord.getLastUpdateTime() > maxNewUpdatedTime) { maxNewUpdatedTime = searchWord.getLastUpdateTime(); } if (currentKeywords.containsKey(searchWord.getKeyword())) { currentKeywords.replace(searchWord.getKeyword(), searchWord); } else { currentKeywords.put(searchWord.getKeyword(), searchWord); } } lastUpdateTime = maxNewUpdatedTime; } private List<SearchWord> getSearchWords(long lastUpdateTime) { // TODO: 从数据库中取出更新时间>lastUpdateTime的数据 return null; } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
看起来还是很简单的对吧,不过,现在,我们有一个特殊的要求:任何时刻,系统 A 中的所有数据都必须是同一个版
本的,要么都是版本 a,要么都是版本 b,不能有的是版本 a,有的是版本 b。那刚刚的更新方式就不能满足这个要求了。除此之外,我们还要求:在更新内存数据的时候,系统 A不能处于不可用状态,也就是不能停机更新数据。
那么我们应该如何实现呢?
实际上也不难,我们把正在使用的数据的版本定义为“服务版本”,当我们要更新内存中的数据的时候,我们并不是直接在服务版本(假设是版本 a 数据)上更新,而是重新创建另一个版本数据(假设是版本 b 数据),等新的版本数据建好之后,再一次性地将服务版本从版本 a 切换到版本 b。这样既保证了数据一直可用,又避免了中间状态的存在。
按照这个思路,如下:public class Demo { private HashMap<String, SearchWord> currentKeywords=new HashMap<>(); public void refresh() { HashMap<String, SearchWord> newKeywords = new LinkedHashMap<>(); // 从数据库中取出所有的数据,放入到newKeywords中 List<SearchWord> toBeUpdatedSearchWords = getSearchWords(); for (SearchWord searchWord : toBeUpdatedSearchWords) { newKeywords.put(searchWord.getKeyword(), searchWord); } currentKeywords = newKeywords; } private List<SearchWord> getSearchWords() { // TODO: 从数据库中取出所有的数据 return null; } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
到这里,似乎就可以了,但你有没有发现这段代码有个问题。那我们就先必须搞清楚什么是深拷贝,什么是浅拷贝。
深拷贝和浅拷贝
我们先看一下在内存中,用散列表组织的搜索关键词信息是如何存储的:

浅拷贝和深拷贝的区别在于,浅拷贝只会复制图中的索引(散列表),不会复制数据(SearchWord 对象)本身。相反,深拷贝不仅仅会复制索引,还会复制数据本身。浅拷贝得到的对象(newKeywords)跟原始对象(currentKeywords)共享数据SearchWord 对象),而深拷贝得到的是一份完完全全独立的对象。具体的对比如下图所示:
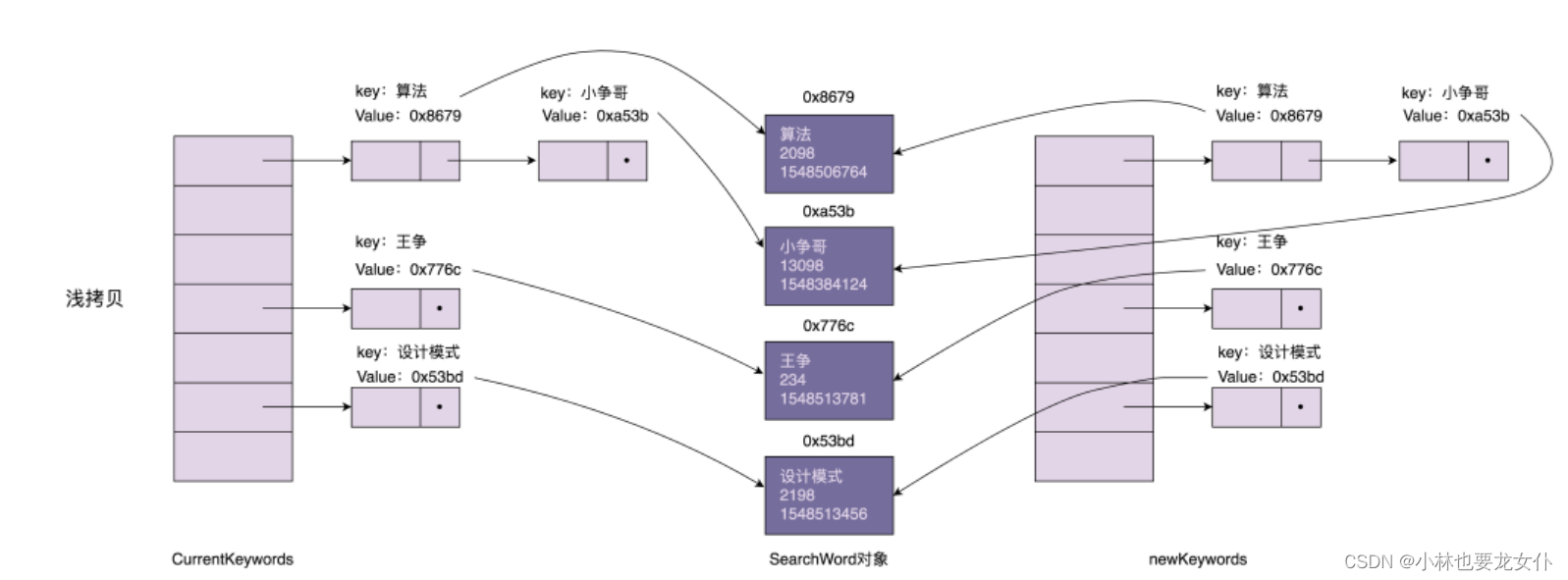

在 Java 语言中,Object 类的 clone() 方法执行的就是我们刚刚说的浅拷贝。它只会拷贝对象中的基本数据类型的数据(比如,int、long),以及引用对象(SearchWord)的内存地址,不会递归地拷贝引用对象本身。
那么,如何实现深拷贝呢?
第一种,递归拷贝对象、对象的引用对象以及引用对象的引用对象……直到要拷贝的对象只包含基本数据类型数据,没有引用对象为止;第二种,先将对象序列化,然后再反序列化成新的对象;第三种也是我比较推荐的一种,直接使用第三方工具,比如Spring 的 BeanUtils或者MapStruct,后者更高效。 -
相关阅读:
Xilinx ISE系列教程(6):ModelSim联合仿真
纯js实现html指定页面导出word
ffmpeg & ffplay
使用 SSH 密钥进行身份验证
golang系统文件路径与文件打开问题
【JavaScript-26】js的内置对象Math,随机数获取随机颜色
MySQL的组成与三种log
centos7安装keepalived 保证Nginx的高可用
AWS SAA C003 #33
Windows系统利用cpolar内网穿透搭建Zblog博客网站并实现公网访问内网!
- 原文地址:https://blog.csdn.net/qq_43654226/article/details/126441556
