-
Python 爬虫之lxml和Xpath提取网页数据
活动地址:CSDN21天学习挑战赛
一、xlml库
1、定义:
lxml是python的一个解析库,支持HTML和XML格式的解析,XPath,全称XML Path Language,即XML路径语言,很明显是通过路径来定位,通俗点你可以想象成一个树状结构,会有很多节点分支。
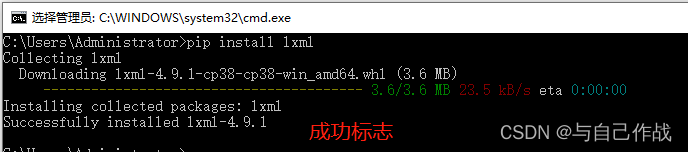
2、安装
pip install lxml- 1
3解析html页面内容
1)解析html页面
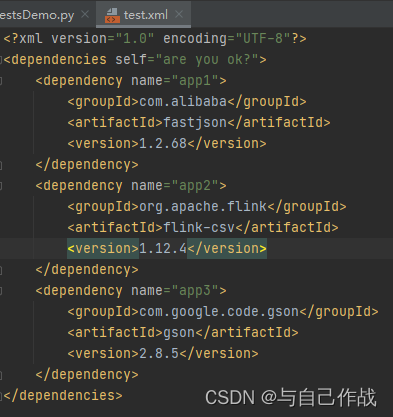
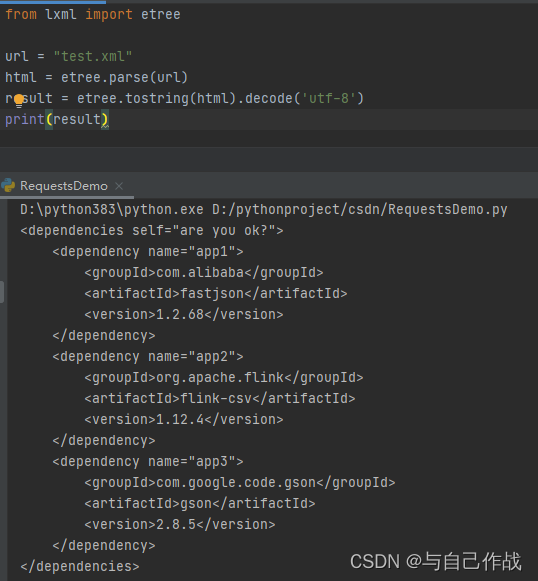
from lxml import etree url = "test.xml" # 读取文本 html = etree.parse(url) # html序列化 result = etree.tostring(html).decode('utf-8') print(result)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
2)解析html文本

from lxml import etree data = """com.alibaba fastjson 1.2.68 - 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
二、XPath库
XPath(XML Path Language - XML路径语言),它是一种用来确定XML文档中某部分位置的语言。
Xpath以XML为基础,提供用户在数据结构树中寻找节点的能力,Xpath被很多开发者亲切的称为小型查询语言。1、语法规则
- 获取路径
表达式 作用 nodename选取此层级节点下的所有子节点 /代表从根节点进行选取 //可以理解为匹配,就是在所有节点中选取此节点,直到匹配为止 .选取当前节点 …选取当前节点上一层(上一级目录) @选取属性(也是匹配) - 路径表达式
/html/body/div|/html/body/div1用|来表示多选路径表达式 解释 /html/body/div /html/body/div1表示从根节点开始寻找,标签与标签之间/表示一个层级 /html//div表示多个层级 作用于两个标签之间(也可以理解为在html下进行匹配寻找标签div) //div从任意节点开始寻找,也就是查找所有的div标签 ./div表示从当前的标签开始寻找div 2、Chrome安装xpath_helper插件
xpath_helper(0积分下载)下载地址:https://download.csdn.net/download/walykyy/86405082
1)解压缩
2)找到里面crx

3)打开谷歌浏览器的扩展程序
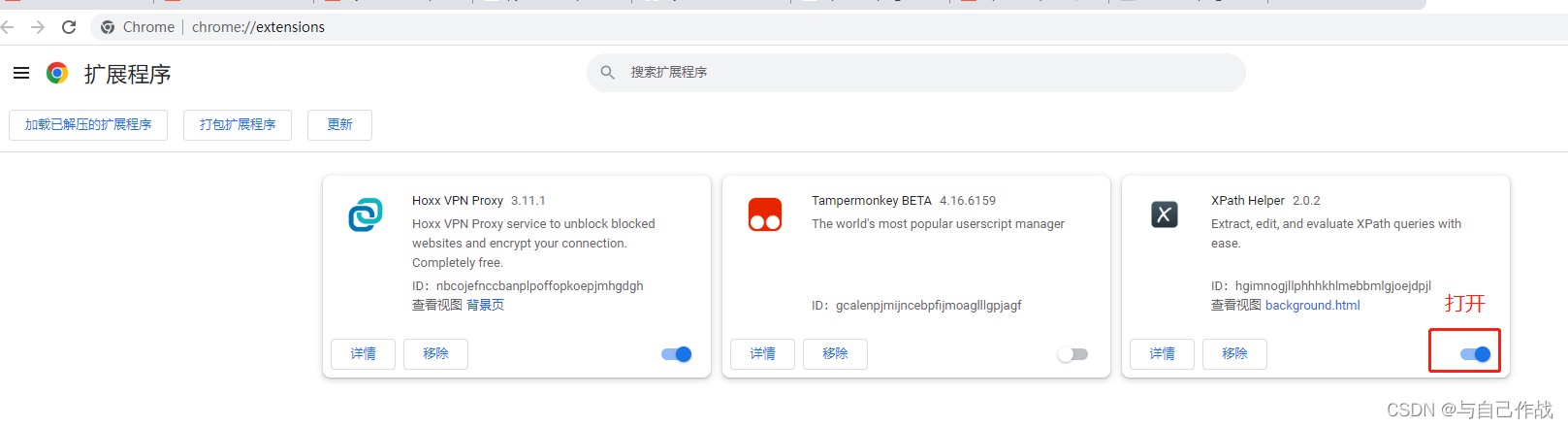
4)直接把crx拖拽到扩展程序即可

5)添加打开使用OK
6)案例
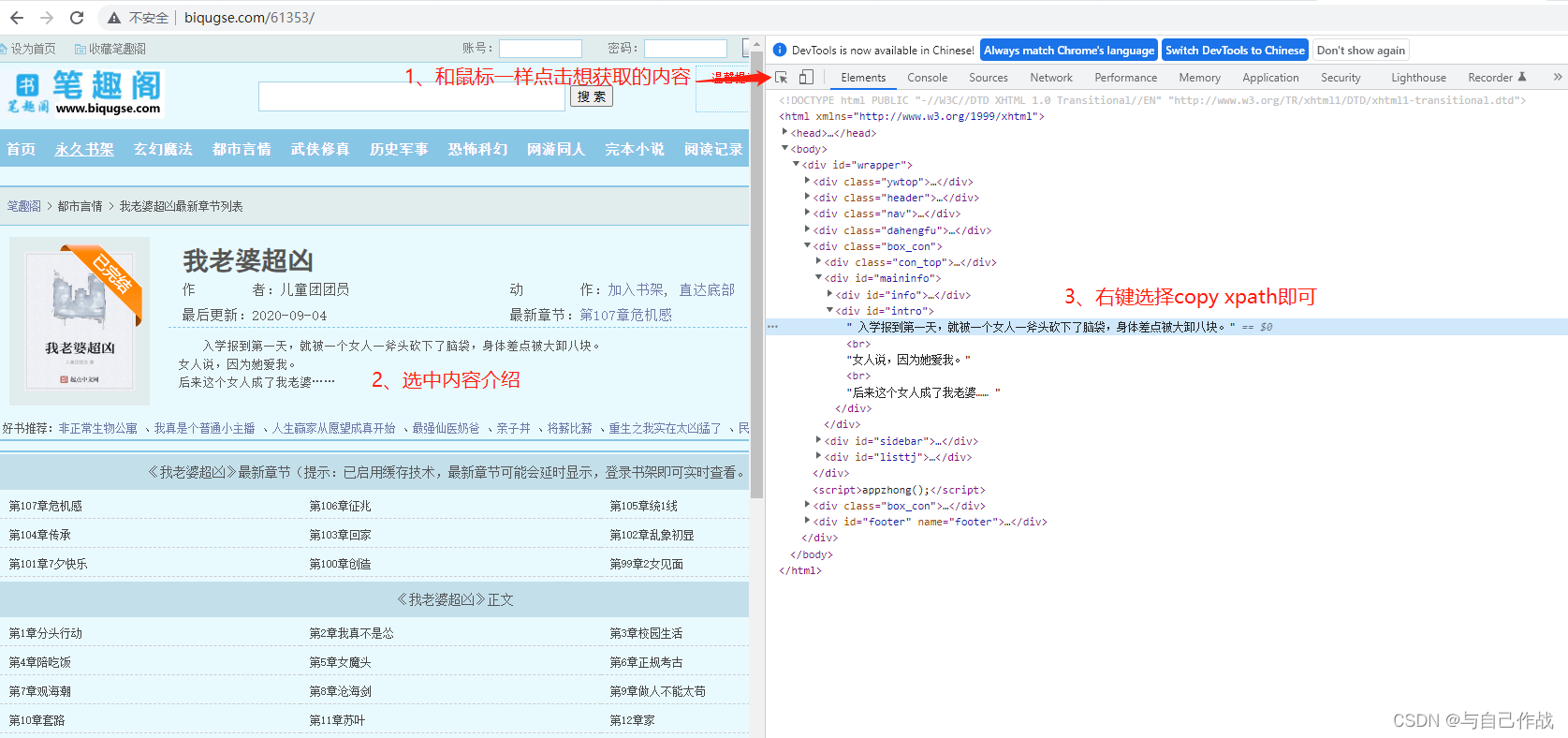
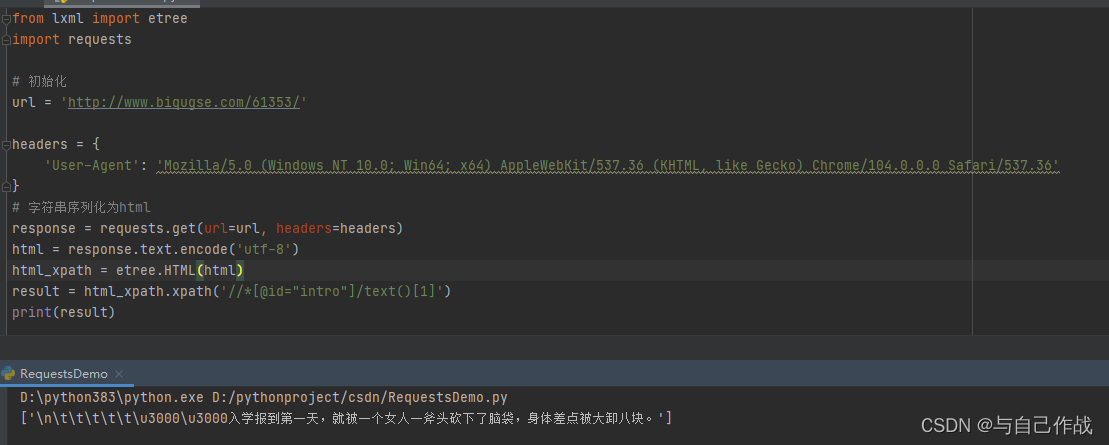
from lxml import etree import requests # 初始化 url = 'http://www.biqugse.com/61353/' headers = { 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/104.0.0.0 Safari/537.36' } # 字符串序列化为html response = requests.get(url=url, headers=headers) html = response.text.encode('utf-8') html_xpath = etree.HTML(html) result = html_xpath.xpath('//*[@id="intro"]/text()[1]') print(result)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
-
相关阅读:
springboot高校学生宿舍水电费报修考勤管理系统
Java Process:另一个程序正在使用此文件,进程无法访问
C++——指针、右左法则、指针和函数的关系、函数指针、函数转移表(函数指针static)
修改datagridView单元格颜色(行颜色,列颜色)
Sqlmap进行http头注入及流量分析
基于springboot实现民宿管理平台项目【项目源码+论文说明】计算机毕业设计
vue3的ref和reactive
Codeforces Round #813 (Div. 2) A~C
Acwing算法心得——猜测短跑队员的速度(重写比较器)
python-flask 登录案例
- 原文地址:https://blog.csdn.net/walykyy/article/details/126432617