-
Java(集合框架01)
Java(集合框架01) 参考视频:511. 枚举类与注解-集合框架与项目的对比及概述(尚硅谷)
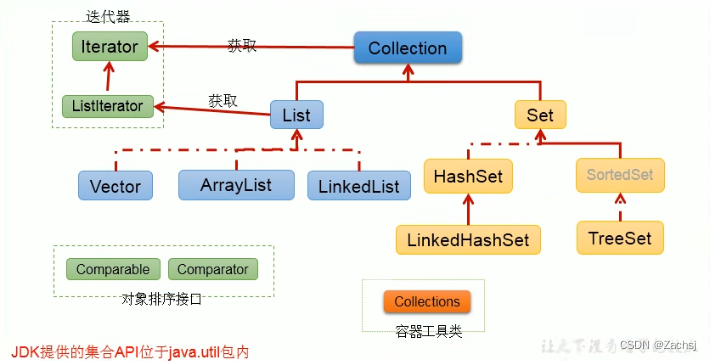
1. 单列集合框架结构
- Collection接口:单列集合,用来存储一个一个的对象
- List接口:存储有序的,可重复的数据。(动态数组)
- ArrayList、LinkedList、Vector
- Set接口:存储无序的,不可重复的数据。(高中集合)
- HashSet、LinkedHashSet、TreeSet
- List接口:存储有序的,可重复的数据。(动态数组)
- Map接口:双列集合,用来存储一对(key-value)的数据。(高中函数y=f(x))
- HashMap、LinkedHashMap、TreeMap、Hashtable、Properties
- 对应图示:
2. Collection接口常用方法
- 五个
package com.zach.day06; import java.util.ArrayList; import java.util.Collection; import java.util.Date; public class Test01 { public static void main(String[] args) { Collection coll = new ArrayList(); //add(Object e):将元素添加到集合coll中 coll.add("AA"); coll.add("BB"); coll.add(11); coll.add(new Date()); //size():获取添加的元素的个数 System.out.println(coll.size());//4 //addAll(Collection coll1):将coll1集合中的元素添加到当前的集合中 Collection coll1 = new ArrayList(); coll1.add(456); coll1.add("CC"); coll1.addAll(coll1); System.out.println(coll.size());//6 System.out.println(coll); //clear(): 清空集合 coll.clear(); //siEmpty(): 判断当前集合是否为空 System.out.println(coll.isEmpty()); } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 十个
- …
3. 集合元素的遍历(使用Iterator接口)
- 推荐使用方式三
package com.zach.day07; import java.util.ArrayList; import java.util.Collection; import java.util.Iterator; /** * @author : Zach * @date : 2022-08-19 10:10 * @description : Iterator迭代器接口 * @modified by : Zach */ //集合元素的遍历操作 public class Test01 { public static void main(String[] args) { Collection coll = new ArrayList(); coll.add(123); coll.add(456); coll.add(new Person("Zach",18)); coll.add(new String("sj")); coll.add(false); Iterator iterator = coll.iterator(); //方式一:不用 // System.out.println(iterator.next()); //方式二:不推荐 // for (int i = 0; i < coll.size(); i++) { // System.out.println(iterator.next()); // } //方式三:推荐 while (iterator.hasNext()){ System.out.println(iterator.next()); } } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
4. Collection集合与数组间的转换
- …
5. List
- ArrayList、LinkedList、Vector
5.1 比较ArrayList、LinkedList、Vector三者的异同
- 同:
- 三个类都实现了List接口,都是List接口的实现类,
- 三个类存储数据的特点相同:都是存储有序的,可重复的数据。
- ArrayList和Vector底层都使用数组Object[] elementData存储数据。
- 不同:
- ArrayList:
- 作为List接口的主要实现类;
- 线程不安全,但效率高;
- 需要线程安全时,会把数组方法放到SynchronizedList中。
- LinkedList:
- 底层使用双向链表存储数据,所以对于频繁地插入和删除操作,效率比ArrayList高。
- 没有下标属性,查询数据效率低。
- Vector:
- 作为List接口的古老实现类;
- 线程安全,但效率低。
- ArrayList:
5.2 源码分析
- …
5.3 List接口中常用方法测试
package com.zach.day07; import java.util.ArrayList; import java.util.Arrays; import java.util.List; /** * @author : Zach * @date : 2022-08-19 14:09 * @description : TODO * @modified by : Zach */ public class Test02 { public static void main(String[] args) { ArrayList list = new ArrayList(); list.add(123); list.add(456); list.add("AA"); list.add(new Person("Zach",18)); list.add(456); System.out.println(list); //void add(int index, Object ele):在index位置插入ele元素 list.add(1,"BB"); System.out.println(list); //boolean addAll(int index, Collection eles):从index位置开始将eles中的所有元素添加进来 List list1 = Arrays.asList(1, 2, 3); list.addAll(list1); System.out.println(list.size()); //Object get(int index):获取指定index位置的元素 System.out.println(list.get(0)); //int indexOf(Object obj):返回obj在集合中首次出现的位置。不存在返回-1 int index = list.indexOf(456); System.out.println(index); //int lastIndexOf(Object obj):返回obj在集合中末次出现的位置。不存在返回-1 System.out.println(list.lastIndexOf(456)); //Object remove(int index):移除指定index位置的元素,并返回此元素 Object obj = list.remove(0); System.out.println(obj); System.out.println(list); //Object set(int index,Object ele):设置指定index位置的元素为ele list.set(0,"CC"); System.out.println(list); //List sublist(int fromIndex,int toIndex):返回从fromIndex到toIndex位置的子集合(左闭右开) List subList = list.subList(2, 5); System.out.println(subList); System.out.println(list); } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
5.4 总结常用方法
- 增:
add(object obj) - 删:
remove(int index) / remove(object obj) - 改:
set(int index, object ele) - 查:
get(int index) - 插:
add(int index, object ele) - 长度:
size() - 遍历:
- Iterator迭代器方式
- 增强for循环
- 普通的循环
- 遍历(三种)
package com.zach.day07; import java.util.ArrayList; import java.util.Iterator; /** * @author : Zach * @date : 2022-08-19 14:34 * @description : TODO * @modified by : Zach */ public class Test03 { public static void main(String[] args) { ArrayList list = new ArrayList(); list.add(123); list.add(456); list.add("AA"); //方式一:Iterator迭代器 Iterator iterator = list.iterator(); while (iterator.hasNext()){ System.out.println(iterator.next()); } System.out.println("*************************"); //方式二:增强for循环 for (Object obj : list) { System.out.println(obj); } System.out.println("*************************"); //方式三:普通for循环 for (int i = 0; i < list.size(); i++) { System.out.println(list.get(i)); } } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
6. Set
- HashSet、LinkedHashSet、TreeSet
6.1 分析
- HashSet:
- 作为Set接口的主要实现类;
- 线程是不安全的;
- 可以存储null值。
- LinkedHashSet: 是HashSet的子类
- 作为HashSet的子类,遍历其内部数据时,可以按照添加的顺序遍历;
- 对于频繁的遍历操作,LinkedHashSet效率高于HashSet。
- TreeSet: (红黑二叉树)
- 可以按照添加对象的指定属性,进行排序。
- 所以数据必须是同一个类创建的。
6.2 HashSet
package com.zach.day07; import java.util.HashSet; import java.util.Iterator; import java.util.Set; /** * @author : Zach * @date : 2022-08-19 14:54 * @description : TODO * @modified by : Zach */ //Set:存储无序的,不可重复的数据 //1.无序性:不是随机性。存储的数据在底层数组中并非按照数组索引的顺序添加, //而是根据数据的哈希值决定的。 //2.不可重复性:保证添加的元素按照equals()判断时(哈希值),不能返回true,即相同元素只能添加一个。 //添加元素的过程:以HashSet为例: //我们向HashSet中添加元素a,首先调用元素a所在的hashCode()方法,计算元素a的哈希值, //此哈希值接着通过某种算法计算出在HashSet底层数组中的存放位置(即索引位置), //判断数组此位置上是否已经有元素: //如果此位置上没有其他元素,则元素a添加成功。 ——情况1 //如果此位置上有其他元素b(或者以链表形式存在的多个元素),则比较元素a与元素b的hash值: //如果hash值不相同,则元素a添加成功。 ——情况2 //如果hash值相同,进而需要调用元素a所在类的equals()方法: //equals()返回true,元素a添加失败。 //equals()返回false,则元素a添加成功。 ——情况3 //对于添加成功的情况2和3而言:元素a与已经存在指定索引位置上的数据以链表的方式存储。 //JDK7:元素a放到数组中,指向原来的元素。 //JDK8:原来的元素在数据中,指向元素a。 //总结:七上八下。 //HashSet底层:数组+链表的结构。 public class Test04 { public static void main(String[] args) { Set set = new HashSet(); set.add(123); set.add(456); set.add("AA"); set.add("BB"); set.add(new Person("Zach",18)); set.add(789); Iterator iterator = set.iterator(); while (iterator.hasNext()) { System.out.println(iterator.next()); } } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
6.3 LinkedHashSet
package com.zach.day08; import com.zach.day07.Person; import java.util.Iterator; import java.util.LinkedHashSet; import java.util.Set; /** * @author : Zach * @date : 2022-08-20 07:38 * @description : TODO * @modified by : Zach */ //LinkedHashSet的使用 //LinkedHashSet作为HashSet的子类,在添加数据的同时,每个数据还维护了两个引用, // 记录此数据前一个数据和后一个数据 //优点:对于频繁的遍历操作,LinkedHashSet效率高于HashSet。 public class Test01 { public static void main(String[] args) { Set set = new LinkedHashSet(); set.add(123); set.add(456); set.add("AA"); set.add("BB"); set.add(new Person("Zach",18)); set.add(789); Iterator iterator = set.iterator(); while (iterator.hasNext()) { System.out.println(iterator.next()); } } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
6.5 TreeSet
package com.zach.day08; import lombok.AllArgsConstructor; import lombok.Data; import lombok.NoArgsConstructor; @Data @AllArgsConstructor @NoArgsConstructor public class User implements Comparable{ private String name; private int age; //按照姓名从大到小排序,年龄从小到大排序。 @Override public int compareTo(Object o) { if (o instanceof User){ User user = (User) o; // return -this.name.compareTo(user.name); int compare = -this.name.compareTo(user.name); if (compare != 0){ return compare; }else { return Integer.compare(this.age,user.age); } }else { throw new RuntimeException("输入的类型不匹配"); } } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
package com.zach.day08; import java.util.Comparator; import java.util.Iterator; import java.util.TreeSet; /** * @author : Zach * @date : 2022-08-20 10:14 * @description : TODO * @modified by : Zach */ //1.向TreeSet中添加的数据,要求是相同类的对象 //2.两种排序方式:自然排序(实现Comparable接口) 和 定制排序(Comparator) //3.自然排序中,比较两个对象是否相同的标准为:compareTo()返回0,不再是equals(). //4.定制排序中,比较两个对象是否相同的标准为:compare()返回0,不再是equals(). public class Test02 { public static void main(String[] args) { TreeSet set = new TreeSet(); //示例一: // set.add(34); // set.add(-34); // set.add(43); // set.add(11); // set.add(8); //示例二; set.add(new User("Zach",18)); set.add(new User("Zachsj",180)); set.add(new User("SJ",1)); set.add(new User("JayChou",28)); set.add(new User("JayChou",38)); set.add(new User("Chou",38)); Iterator iterator = set.iterator(); while (iterator.hasNext()) { System.out.println(iterator.next()); } System.out.println("********** **********"); treeSet2(); } public static void treeSet2(){ Comparator com = new Comparator() { //按照年龄从小到大排序 @Override public int compare(Object o1, Object o2) { if (o1 instanceof User && o2 instanceof User){ User u1 = (User) o1; User u2 = (User) o2; return Integer.compare(u1.getAge(),u2.getAge()); }else { throw new RuntimeException("输入的数据类型不匹配"); } } }; TreeSet set = new TreeSet(com); set.add(new User("Zach",18)); set.add(new User("Zachsj",1800)); set.add(new User("SJ",10)); set.add(new User("JayChou",28)); set.add(new User("JayChou",38)); Iterator iterator = set.iterator(); while (iterator.hasNext()) { System.out.println(iterator.next()); } } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
7. Map
- HashMap、LinkedHashMap、TreeMap、Hashtable、Properties
7.1 HashMap
package com.zach.day08.map; import org.junit.Test; import java.util.HashMap; import java.util.Map; /** * @author : Zach * @date : 2022-08-20 11:55 * @description : TODO * @modified by : Zach */ //一、Map:双列数据,存储key-value对的数据,类似于高中的函数y=f(x) //HashMap:作为Map的主要实现类:线程不安全的,但效率高;可存储null值的key、value //LinkedHashMap:保证在遍历map元素时,可以按照添加的顺序实现遍历。 //原因:在原有的HashMao底层结构基础上,添加了一对指针,指向前一个和后一个元素。 //对于频繁的遍历操作,效率高于HashMap //TreeMap:保证按照添加的key-value对进行排序,实现排序遍历。(此时考虑key的自然排序或定制排序) //底层使用红黑树 //Hashtable:作为古老的实现类:线程安全的,但效率低;不能存储null值的key、value //Properties:常用来处理配置文件。key和value都是String类型。 //HashMap底层: //数组+链表 (JDK7及以前) //数组+链表+红黑树(JDK8) //二、Map结构的理解: //Map中的key:是无序的,且不可重复的,使用Set存储所有的key。 //(key所在的类要重写equals()和hashCode()方法,以HashMao为例) //Map中的value:是无序的,但可重复的,使用Collection存储所有的value //(value所在的类要重写equals()) //一个键值对:key-value构成了一个Entry对象 //Map中的entry:是无序的,不可重复的,使用Set存储所有的entry //三、HashMp的底层实现原理?以jdk7为例说明: //HashMap map = new HashMap(): //在实例化以后,底层创建了长度是16的一维数组Entry[] table。 //...可能己经执行过多次put. . . //map.put(key1,value1): //首先,调用key1所在类的hashCode()计算key1哈希值,此哈希值经过某种算法计算以后,得到在Entry数组中的存放位置。 //如果此位置上的数据为空,此时的key1-value1添加成功。----情况1 //如果此位置上的数据不为空,(意味着此位置上存在一个或多个数据(以链表形式存在)),比较key1和已经存在的一个或多个数据的哈希值: //如果key1的哈希值与已经存在的数据的哈希值都不相同,此时key1-value1添加成功。----情况2 //如果key1的哈希值和已经存在的某一个数据(key2-vaLue2)的哈希值相同,继续比较:调用key1所在类的equals(key2): //如果equals()返回faLse:此时key1-value1添加成功。----情况3 //如果equals()返回true:使用value1替换value2。 //补充:关于情况2和情况3:此时key1-value1和原来的数据以链表的方式存储。 //在不断的添加过程中,会涉及到扩容问题,默认的扩容方式:扩容为原来容量的2倍,并将原有的数据复制过来。 //JDK8相较于JDK7在底层实现方面的不同: //1. new HashMap():底层没有创建一个长度为16的数组 //2. JDK8底层的数组是:Node[],而非Entry[] //3. 首次调用put()方法时,底层创建长度为16的数组(类似ArrayList在7和8的区别) //4. JDK7底层结构只有:数组+链表。JDK8中底层结构:数组+链表+红黑树 //当数组的某一个索引位置上的元素以链表形式存在的数据个数>8,且当前数组长度>64时, //此时此索引位置上的所有数据改为使用红黑树存储。 public class MapTest { @Test public void test1(){ Map map = new HashMap(); map.put(null,123); System.out.println(map); } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- Map:双列数据,存储key-value对的数据,类似于高中的函数y=f(x)
- HashMap:作为Map的主要实现类:线程不安全的,但效率高;可存储null值的key、value
- LinkedHashMap:保证在遍历map元素时,可以按照添加的顺序实现遍历。
- 原因:在原有的HashMao底层结构基础上,添加了一对指针,指向前一个和后一个元素。
- 对于频繁的遍历操作,效率高于HashMap
- LinkedHashMap:保证在遍历map元素时,可以按照添加的顺序实现遍历。
- TreeMap:保证按照添加的key-value对进行排序,实现排序遍历。(此时考虑key的自然排序或定制排序)
- 底层使用红黑树
- Hashtable:作为古老的实现类:线程安全的,但效率低;不能存储null值的key、value
- Properties:常用来处理配置文件。key和value都是String类型。
- HashMap:作为Map的主要实现类:线程不安全的,但效率高;可存储null值的key、value
- HashMap底层:
- 数组+链表 (JDK7及以前)
- 数组+链表+红黑树(JDK8)
- Map结构的理解:
- Map中的key:是无序的,且不可重复的,使用Set存储所有的key。
- (key所在的类要重写equals()和hashCode()方法,以HashMao为例)
- Map中的value:是无序的,但可重复的,使用Collection存储所有的value
- (value所在的类要重写equals())
- 一个键值对:key-value构成了一个Entry对象
- Map中的entry:是无序的,不可重复的,使用Set存储所有的entry
- Map中的key:是无序的,且不可重复的,使用Set存储所有的key。
- HashMp的底层实现原理? 以jdk7为例说明:
- HashMap map = new HashMap():
- 在实例化以后,底层创建了长度是16的一维数组Entry[] table。
- …可能己经执行过多次put. . .
- map.put(key1,value1):
- 首先,调用key1所在类的hashCode()计算key1哈希值,此哈希值经过某种算法计算以后,得到在Entry数组中的存放位置。
- 如果此位置上的数据为空,此时的key1-value1添加成功。----情况1
- 如果此位置上的数据不为空,(意味着此位置上存在一个或多个数据(以链表形式存在)),比较key1和已经存在的一个或多个数据的哈希值:
- 如果key1的哈希值与已经存在的数据的哈希值都不相同,此时key1-value1添加成功。----情况2
- 如果key1的哈希值和已经存在的某一个数据(key2-vaLue2)的哈希值相同,继续比较:调用key1所在类的equals(key2):
- 如果equals()返回faLse:此时key1-value1添加成功。----情况3
- 如果equals()返回true:使用value1替换value2。
- 补充:关于情况2和情况3:此时key1-value1和原来的数据以链表的方式存储。
- 在不断的添加过程中,会涉及到扩容问题,当超出临界值(且要存放的位置非空)时,扩容。默认的扩容方式:扩容为原来容量的2倍,并将原有的数据复制过来。
- JDK8相较于JDK7在底层实现方面的不同:
- new HashMap():底层没有创建一个长度为16的数组
- JDK8底层的数组是:Node[],而非Entry[]
- 首次调用put()方法时,底层创建长度为16的数组(类似ArrayList在7和8的区别)
- JDK7底层结构只有:数组+链表。JDK8中底层结构:数组+链表+红黑树
- 当数组的某一个索引位置上的元素以链表形式存在的数据个数>8,且当前数组长度>64时,此时此索引位置上的 所有数据改为使用红黑树存储。
7.2 LinkedHashMap
- 底层原理(了解)
- …
7.3 TreeMap
- …
7.4 Hashtable
- …
7.5 Properties
- …
—————— THE END —————— - Collection接口:单列集合,用来存储一个一个的对象
-
相关阅读:
淘宝上有深度学习指导,代码复现,算法创新等店铺靠谱吗?
测试工具介绍||Postman的简单使用
各种规模大小企业的360 反馈示例
分类预测 | MATLAB实现基于GRU-AdaBoost门控循环单元结合AdaBoost多输入分类预测
【无标题】esp8266替代产品
2712. 使所有字符相等的最小成本
Android 10.0 Launcher3桌面显示多个相同app图标的解决办法
摩莎(MOXA)NPort 5110串口转网口设定
1688代采系统:解决全球化采购难题的技术创新
Python A 组 G 题,全排列的价值 (AC)
- 原文地址:https://blog.csdn.net/Zachsj/article/details/126404120
