-
flink故障恢复的流程(从检查点恢复状态)
在运行流处理程序时,Flink 会周期性地保存检查点。当发生故障时,就需要找到最近一次成功保存的检查点来恢复状态。例如在word count 示例中,我们处理完三个数据后保存了一个检查点。之后继续运行,又正常处理了一个数据“flink”,在处理第五个数据“hello”时发生了故障,如图 10-3所示。
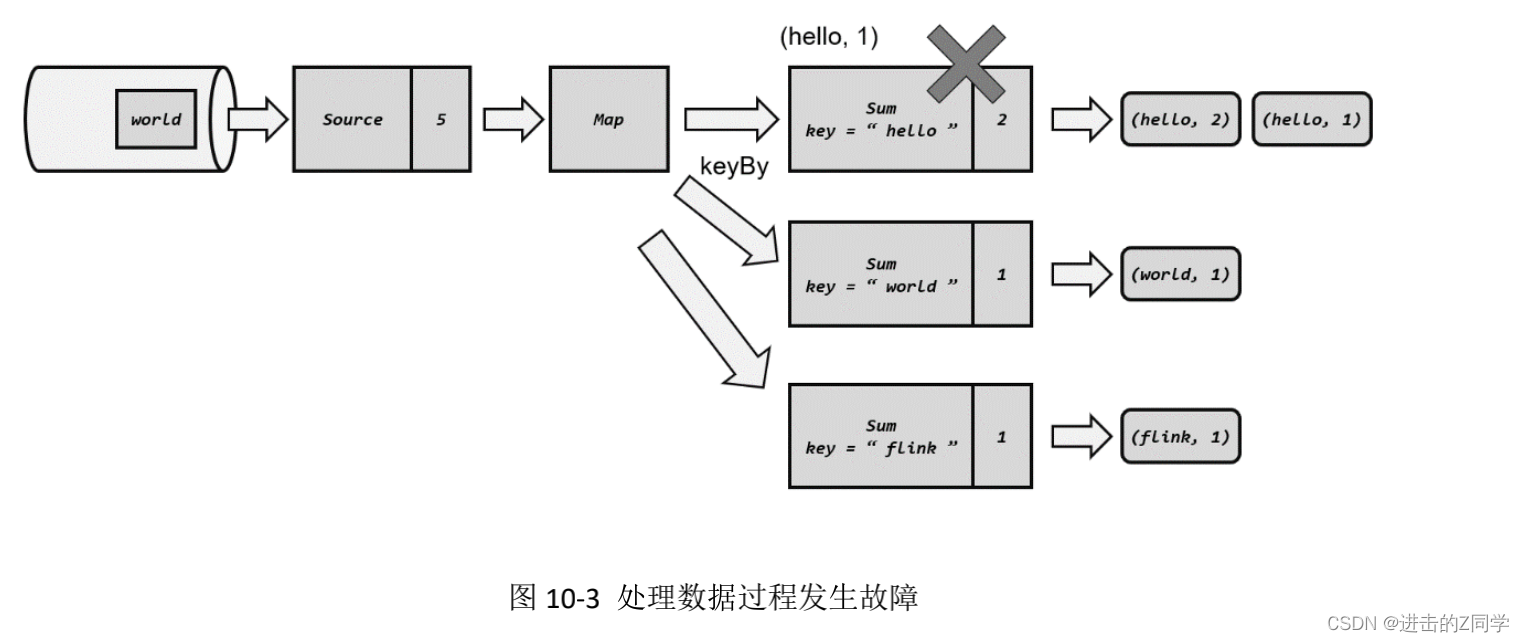
这里 Source 任务已经处理完毕,所以偏移量为 5;Map 任务也处理完成了。而 Sum 任务在处理中发生了故障,此时状态并未保存。接下来就需要从检查点来恢复状态了。具体的步骤为:
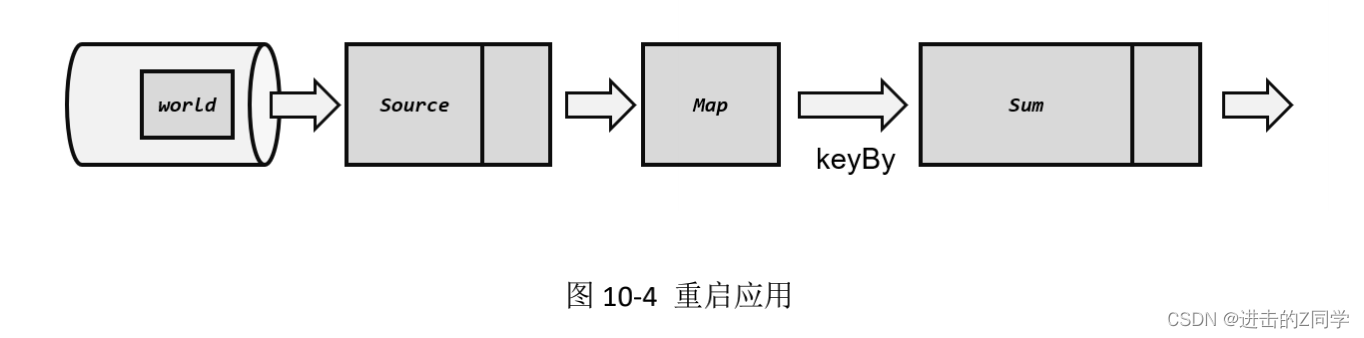
(1)重启应用
遇到故障之后,第一步当然就是重启。我们将应用重新启动后,所有任务的状态会清空,如图 10-4 所示。
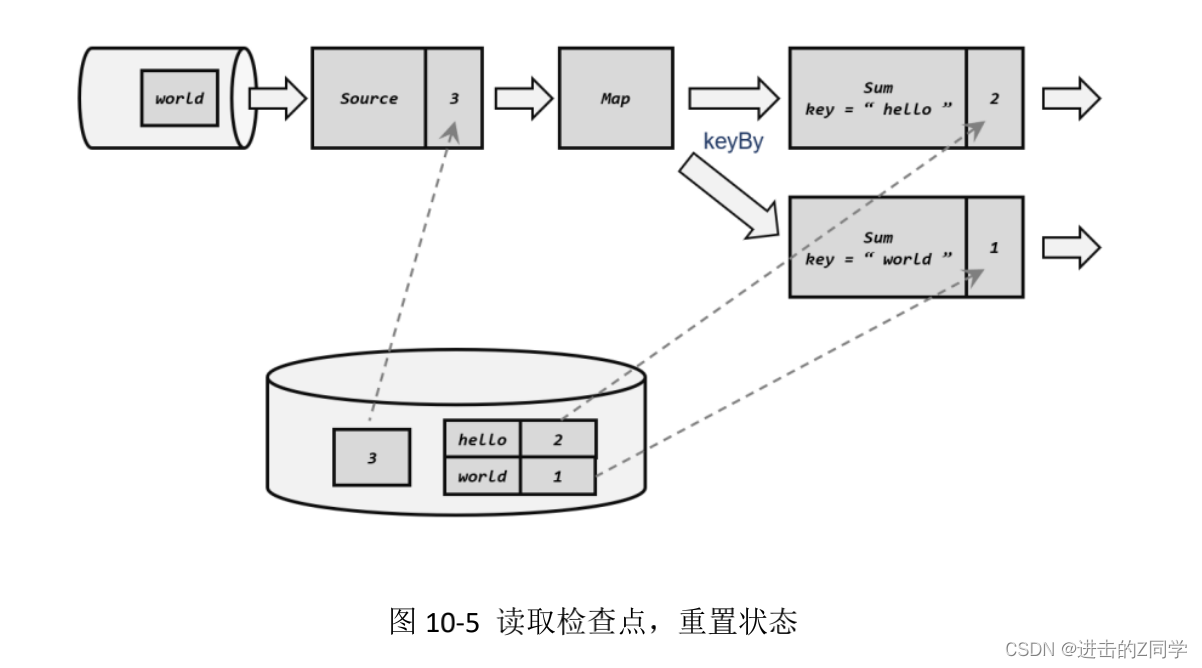
(2)读取检查点,重置状态
找到最近一次保存的检查点,从中读出每个算子任务状态的快照,分别填充到对应的状态中。这样,Flink 内部所有任务的状态,就恢复到了保存检查点的那一时刻,也就是刚好处理完第三个数据的时候,如图 10-5 所示。这里 key 为“flink”并没有数据到来,所以初始为 0。
(3)重放数据
从检查点恢复状态后还有一个问题:如果直接继续处理数据,那么保存检查点之后、到发生故障这段时间内的数据,也就是第 4、5 个数据(“flink”“hello”)就相当于丢掉了;这会造成计算结果的错误。
为了不丢数据,我们应该从保存检查点后开始重新读取数据,这可以通过 Source 任务向外部数据源重新提交偏移量(offset)来实现,如图 10-6 所示。
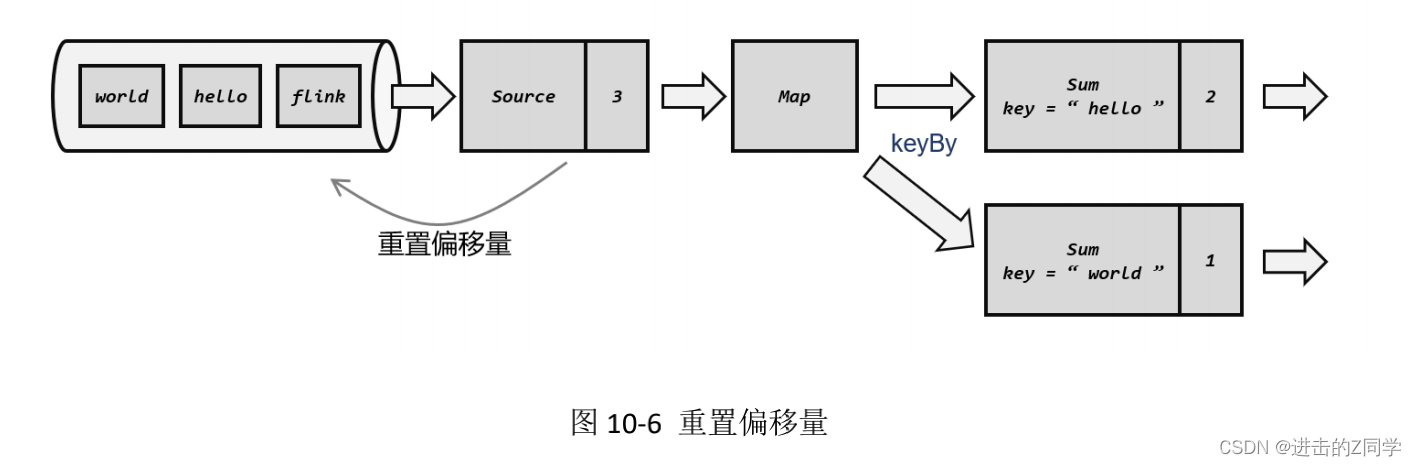
这样,整个系统的状态已经完全回退到了检查点保存完成的那一时刻。(4)继续处理数据
接下来,我们就可以正常处理数据了。首先是重放第 4、5 个数据,然后继续读取后面的数据,如图 10-7 所示。
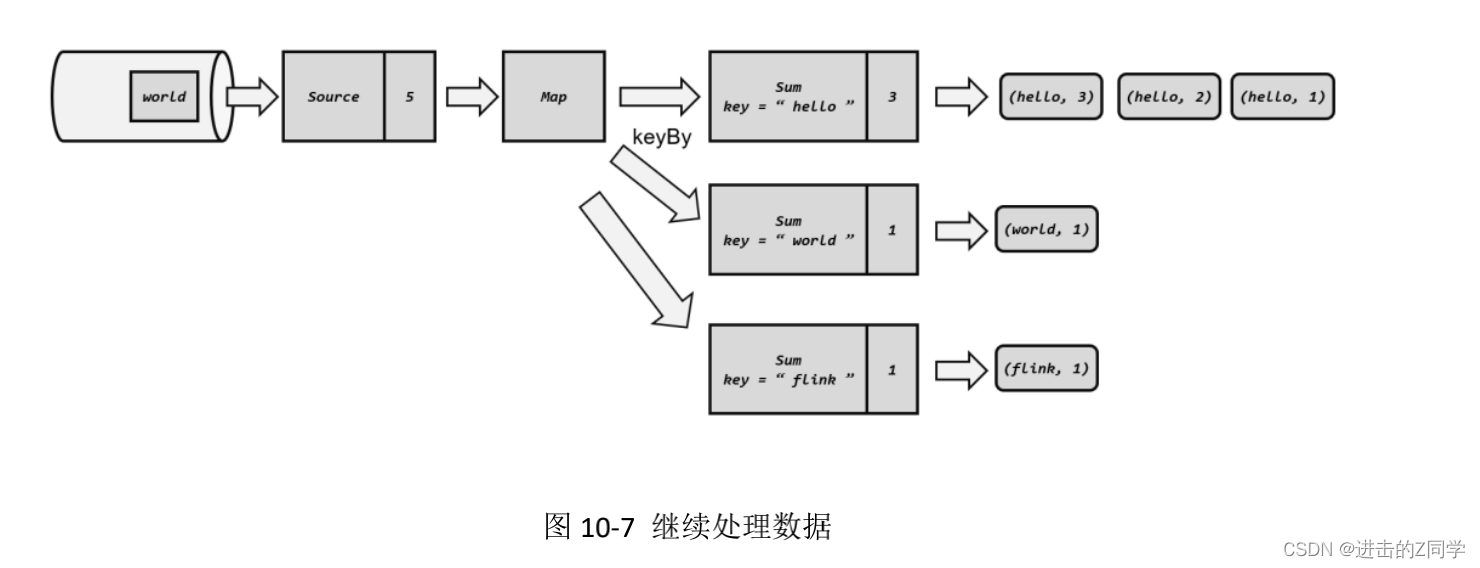
当处理到第 5 个数据时,就已经追上了发生故障时的系统状态。之后继续处理,就好像没有发生过故障一样;我们既没有丢掉数据也没有重复计算数据,这就保证了计算结果的正确性。在分布式系统中,这叫作实现了“精确一次”(exactly-once)的状态一致性保证。这里我们也可以发现,想要正确地从检查点中读取并恢复状态,必须知道每个算子任务状态的类型和它们的先后顺序(拓扑结构);因此为了可以从之前的检查点中恢复状态,我们在改动程序、修复 bug 时要保证状态的拓扑顺序和类型不变。状态的拓扑结构在 JobManager 上可以由 JobGraph 分析得到,而检查点保存的定期触发也是由 JobManager 控制的;所以故障恢复的过程需要 JobManager 的参与。
-
相关阅读:
初识MySQL
java计算机毕业设计游泳馆信息管理系统源码+数据库+系统+部署+lw文档
解决:PowerDesigne找不到右边表的工具栏
二十七、java版 SpringCloud分布式微服务云架构之Java 枚举(enum)
nginx降权+匹配php
高通Android随身WIFI屏蔽商家远程控制断网
抖音实战~实现App端视频上传与发布
组件安全概述
ES6 入门教程 17 Promise 对象 17.1 Promise 的含义
Eureka如何处理网络分区和服务雪崩问题?
- 原文地址:https://blog.csdn.net/qq_24095055/article/details/126437784