-
大数据运维实战第二十五课 HDFS 存储权限 ACL 控制策略以及与系统权限整合应用
POSIX 系统权限模型
POSIX 系统权限模型 是 Linux/Unix 下的一个 权限定义标准,此标准规定了每个文件和目录有一个所有者(Owner)和一个组(Group)。
文件和目录可以通过权限区分是所有者,还是组成员或是其他用户。
-
对于 文件 ,当读取这个文件时,需要有可读(r)权限;当写入到文件时需要有可写(w)权限。
-
对于 目录 ,当列出目录内容时,需要有可读(r)权限;当新建或删除文件或子目录时需要有可写(w)权限;当访问目录的子节点时,需要有可执行(x)权限。
这里面涉及 r、w、x 三种权限,为了对这三种权限进行更方便配置,还可以通过八进制数来表示权限,其中数字 4 代表 r,2 代表 w,1 代表 x。
八进制权限表示法 如下图所示:
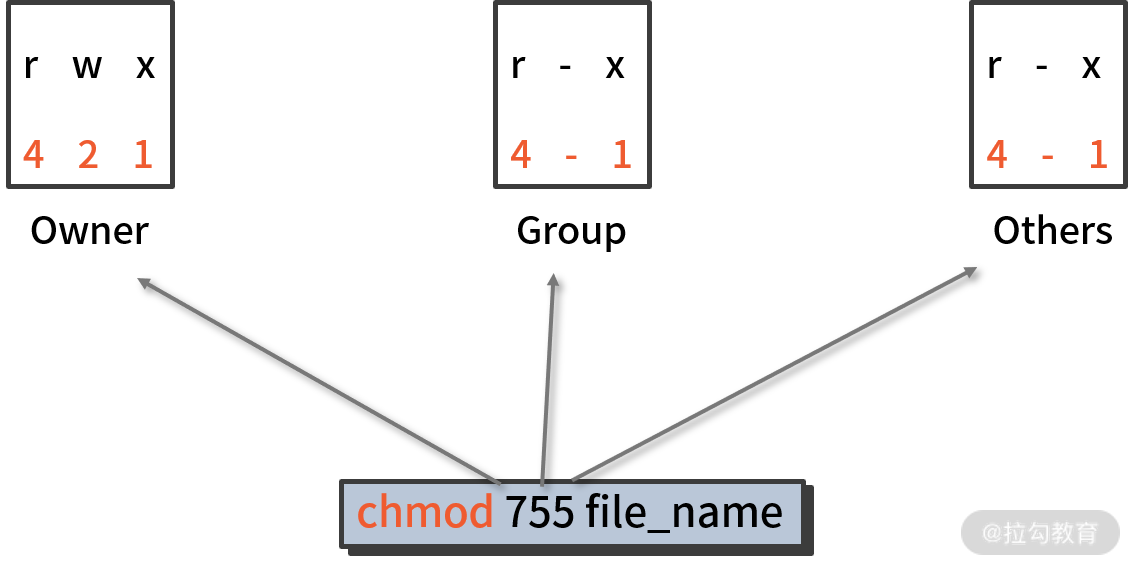
从图中可以清晰地看出,“755”组合的代表含义:
-
第一位“7”显示了文件所有者的权限,是通过 4(r)+2(w)+1(x)=7(rwx) 得到的;
-
第二位“5”显示了文件所属组的权限,是通过 4(r)+0(-)+1(x)=5(rx) 而得到的;
-
同理,最后一位“5”也有类似含义。
熟悉 Linux 系统的朋友对这些权限应该不陌生,而在 Hadoop 中,HDFS 分布式文件系统也采用了 POSIX 系统权限模型来管理文件和目录。同时 HDFS 还提供了对 POSIX ACL(Access Control Lists)的支持,通过 ACL 规则的定义可以使得用户在权限模型之外,提供更灵活的权限控制和管理。
HDFS 中的 POSIX 权限模型
HDFS 借助 POSIX 实现了文件系统更精细化的权限控制,在访问和写入 HDFS 文件系统时,需要明确一下权限规范。
1. 用户与目录权限
在访问 HDFS 某个路径时,用户必须具备该路径上每个目录的执行(x)权限,路径中最后一个目录或文件除外。
例如,执行如下命令:
hadoop fs -ls /user/iivey/data- 1
此操作要求用户必须具有根目录(/)、user 目录及 iivey 目录的执行权限。
2. 默认权限与 umask 约束
当创建一个文件或者目录时,Owner 是客户端进程对应的用户,Group 则继承父目录权限。新建文件或目录的权限由客户端在 RPC 调用时传递给 NameNode,它受配置参数 umask 的约束。此参数在 hdfs-site.xml 文件中定义,内容如下:
<name>fs.permissions.umask-modename> <value>022value> - 1
- 2
- 3
- 4
可以看到,默认 umask 为 022。
默认情况下新文件的权限默认是 666 与 umask 的交集,新目录的权限是 777 与 umask 的交集,如果 umask 为 022,那么新文件的权限就是 644,新目录的权限就是 755。从中可以看出,umask 去掉了 Group 和 Other 的写权限。
如果将 umask 修改为 026,那么新文件的权限就变为 640,新目录的权限就变为 750,这相当于 umask 清除掉了 Group 的写权限,以及 Other 的读、写、执行权限。
3. 通过超级用户授权
只有超级用户才可以调用 chown 参数来修改目录和文件的 owner,例如下面操作:
[hadoop@namenodemaster ~]$ hadoop fs -chown user1 /logs/demo [hadoop@namenodemaster ~]$ hadoop fs -ls /logs|grep demo drwxrwxr-x - user1 supergroup 0 2020-05-09 14:01 /logs/demo- 1
- 2
- 3
此命令将 /logs/demo 目录的 owner 修改为 user1 用户,这里没有指定 group 的权限,因此它将继承 /logs 目录对应的 group 权限。
注意: 这里的 user1 用户需要在 HDFS 的 NameNode 所在节点的系统上进行创建,也就是说 HDFS 权限认证是读取 NameNode 所在主机的系统用户信息。
HDFS ACL 基础介绍
普通的权限控制模式,有时候可能无法满足多用户、多环境的使用需求。例如,HDFS 上的一个目录 /user/user1/logs,此目录要求对 A、B、C 用户可读写,要实现这个需求,有以下两种方式。
第一种方式是通过 普通权限控制 实现。首先,将 A、B、C 三个用户加入一个组中;然后将 /user/user1/logs 目录授权为 775 权限,这样,目录所属的组也就有写此目录的权限了。虽然这个方法能够实现此需求,但是权限过于大了,无法做到精细化控制,操作也过于烦琐。
第二种方式是通过 POSIX ACL 实现。通过 ACL 机制,可以实现 HDFS 文件系统更精细化的权限控制,默认情况下对 HDFS 的 ACL 支持是关闭的,可以通过在 hdfs-site.xml 文件中设置如下配置项来打开:
<name>dfs.permissions.enabledname> <value>truevalue> <property> <name>dfs.namenode.acls.enabledname> <value>truevalue> property>- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
第一个配置项的含义是开启 HDFS 的权限控制机制,第二个是开启 ACL 精细化控制,添加完毕,重启 HDFS 服务,以使配置生效。
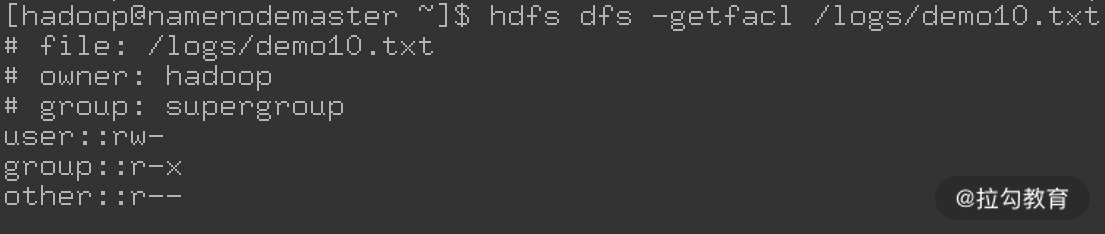
1.最小 ACL 和扩展 ACL
如果 ACL 规则与文件、目录权限位完全对应,则称为最小 ACL(Minimal ACL),它们有 3 个 ACL 规则(即 Owner、Group 和 Others 三种类型,由于与传统的 POSIX 权限模型完全对应,因此不需要指定用户名,称为无名规则),如下图所示:
拥有超过 3 个规则的 ACL 称为扩展 ACL(Extended ACL),扩展 ACL 会包含一个 Mask 规则以及给 Owner、Group 和 Others 授权的规则,如下图所示:
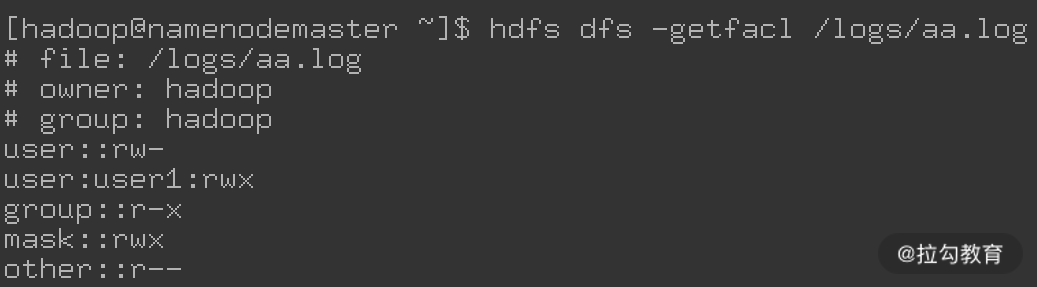
上图中 /logs/aa.log 这个文件就使用了一个扩展 ACL 规则。
2. 缺省 ACL
我们还可以为某个目录设置一个缺省的 ACL 权限。这样之后,在该目录中新建的文件或目录的 ACL 权限可以与之前设置好的 ACL 保持相同,相当于子目录可以从父目录那里直接继承权限。
注意: 只有目录可以被设置默认 ACL,默认 ACL 不会用于权限检查,仅用于权限继承。
当创建一个新的目录时,如果父目录设置了默认 ACL,则新目录会继承父目录的默认 ACL 作为自己的默认 ACL。新的文件也会继承父目录的默认 ACL 作为自己的访问 ACL。
从父目录默认 ACL 继承来的权限并非最终的权限,由于在创建新的目录或文件时,客户端一定会传给 NameNode 一个 umask 权限,两者的计算结果才是最终的权限。计算方式采用与运算,也就是取继承的 ACL 中的权限与 umask 权限中对应类别权限的交集。
访问控制列表(ACL)使用介绍
要在 HDFS 文件系统上使用 ACL,则需要借助两个 HDFS 指令,即 setfacl 和 getfacl,下面介绍下如何使用这两个参数。
1. setfacl 参数
setfacl 主要用来设置文件和目录的访问控制列表(ACL),它的用法如下:
hdfs dfs -setfacl -R|[--set<path>] - 1
下表是一些常用选项以及含义:
常用选项 含义 -b 删除基本 ACL 条目以外的所有条目,保留用户,组和其他以与权限位兼容 -k 删除缺省 ACL -R 以递归方式将操作应用于所有文件和目录 -m 修改 ACL,新条目将添加到 ACL,并保留现有条目 -x 删除指定的 ACL 条目,保留其他 ACL 条目 --set 表示完全替换 ACL,丢弃所有现有条目 acl_spec 表示通过逗号分隔的 ACL 条目列表 path 要修改的文件或目录 下面是几个操作示例:
-
hdfs dfs -setfacl -m user:hive:rw- /logs/nignx.log:将 /logs/nignx.log 文件授权给 Hive 用户可读、写权限。
-
hdfs dfs -setfacl -x user:hive /logs/nignx.log:清除 Hive 用户对 /logs/nignx.log 文件的可读、写权限。
-
hdfs dfs -setfacl -b /logs/nignx.log:清除 /logs/nignx.log 文件基本 ACL 规则以外的所有规则。
-
hdfs dfs -setfacl -k /hivedata/data/mv.db:清除 /hivedata/data/mv.db 目录默认 ACL 规则。
-
hdfs dfs -setfacl --set user::rw-,user:hue:rw-,group::r-x,other::r-- /hivedata/data/mv.db:重新设置 /hivedata/data/mv.db 目录的 ACL 规则,此操作会丢弃所有现有规则。
-
hdfs dfs -setfacl -R -m user:hue:r-x /hivedata/data/mv.db:以递归方式将 ACL 规则应用于 /hivedata/data/mv.db 目录下的所有文件和子目录中。
-
hdfs dfs -setfacl -m default:user:hdfs:r-x /hivedata/data/mv.db:用来设置 /hivedata/data/mv.db 目录的缺省 ACL 规则。
需要注意,关于权限标志位的顺序, 在执行上面的命令中,权限标志位 rwx 的顺序不能改变,否则会报错,正确的写法有 rwx、r-x、r-- 等,错误的写法有 wrx、w-x 等。
下面看一个操作实例,如下图所示:
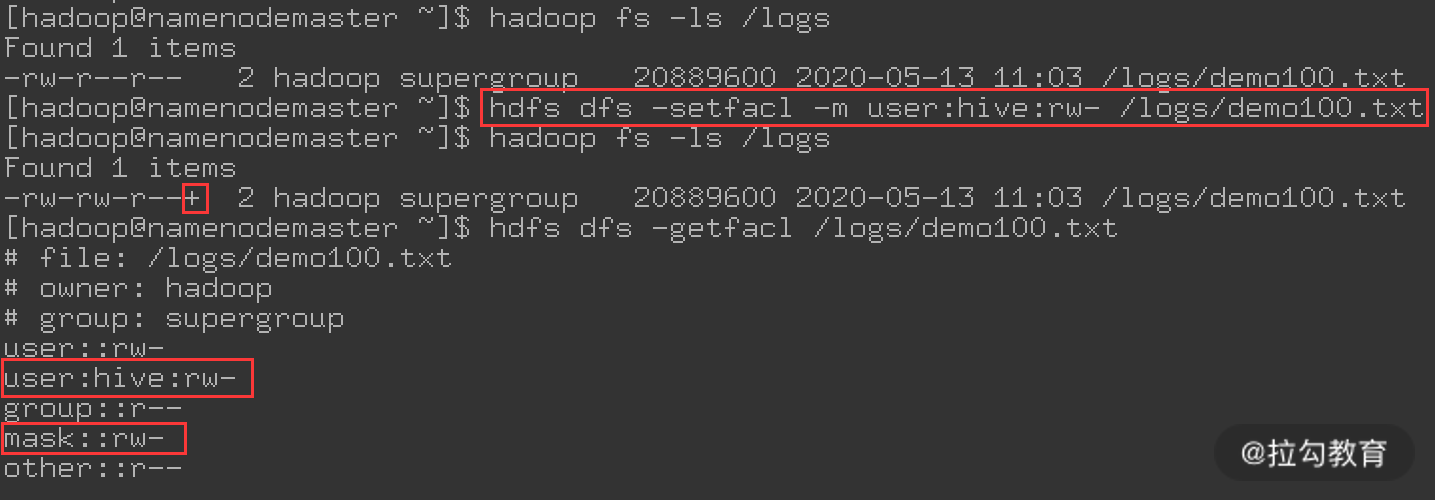
这里对 HDFS 上的文件 /logs/demo100.txt 设置了 ACL 规则,默认情况下此文件的 owner 是 Hadoop,Group 是 supergroup,对应的权限是 644,即只有 Hadoop 用户对此文件有写权限。此时我通过 ACL 规则添加了另一个用户 Hive,对此文件拥有读、写权限,规则设置完成后,通过 Hive 用户就可以向此文件中追加内容。
2. getfacl 参数
getfacl 用来显示文件和目录的访问控制列表,如果目录具有默认 ACL,则 getfacl 还会显示默认 ACL。此参数用法如下:
hdfs dfs -getfacl [-R]- 1
getfacl 常用的几个选项如下:
-
-R,以递归方式列出所有文件和目录的 ACL;
-
path,要列出的文件或目录。
下面看几个示例。
下面操作用来查看 /logs/nignx.log 文件的 ACL 规则:
hdfs dfs -getfacl /logs/nignx.log- 1
下面操作以递归方式列出 /hivedata/data/mv.db 目录下所有文件和子目录的 ACL 规则:
hdfs dfs -getfacl -R /hivedata/data/mv.db- 1
3. ACL 应用实例
假如有这么一个场景,线上有一个 Hive 库 mvlog.db,此库的默认权限属于 usera 用户所有。现在由于业务需要,mvlog.db 库中有一张表(mvcount)需要 userb 用户也有读写权限,要实现这个需求,通过设置 mvcount 这张表的 ACL 规则即可轻松实现。
在 HDFS 分布式文件系统中,每个访问 HDFS 的用户都要在 HDFS 上有个默认目录,即 /user/ 用户名。例如,上面的 usera 和 userb 用户,对应到 HDFS 上需要创建 /user/usera 和 /user/userb 目录,并进行授权,操作方法如下:
[hadoop@namenodemaster ~]$ hadoop fs -mkdir /user/usera [hadoop@namenodemaster ~]$ hadoop fs -mkdir /user/userb [hadoop@namenodemaster ~]$ hadoop fs -chown -R usera:supergroup /user/usera [hadoop@namenodemaster ~]$ hadoop fs -chown -R userb:supergroup /user/userb- 1
- 2
- 3
- 4
用户对应的 HDFS 目录创建完成后,就可以做相关的 ACL 授权操作了。这里假定 Hive 库mvlog.db 的路径为 /user/hive/warehouse/mvlog.db,对此目录做下图授权即可:

从上图中可以看出,若直接通过 userb 去追加内容到 mvcount 表中的 2020-07-15 文件时,提示没有写权限,这是正常的。因为 userb 对此表本来就没有写权限,接着进行 acl 授权,执行如下图操作:

在上图操作中,对 mvcount 目录下的文件和子目录递归的授权给 userb 用户有读、写操作权限,接着再通过 userb 去追加内容到 mvcount 表,操作过程如下图所示:

从上图可知,这次操作还是未成功,但提示错误有了变化,这次提示 userb 用户对 mvcount 目录没有执行权限。很显然,要在 mvcount 目录下写文件,必须对 mvcount 目录要有可执行权限,再次修改 mvcount 目录的权限,其操作如下图所示:
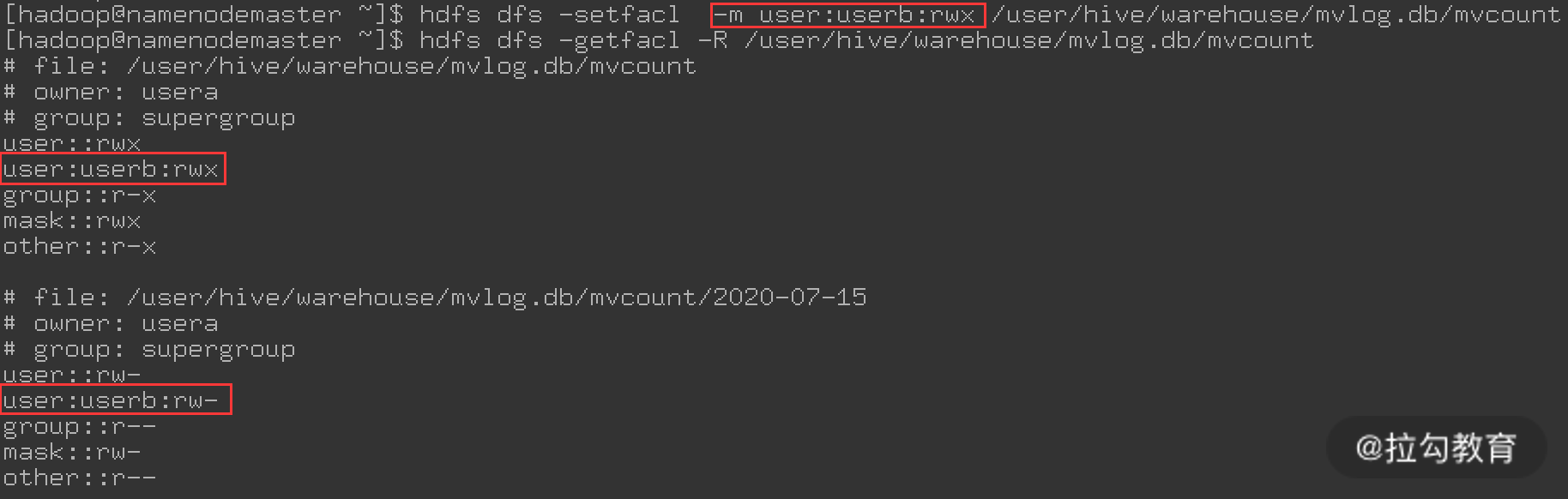
在此操作中,主要是对 mvcount 目录添加了可执行权限,最后查看 ACL 规则,发现 mvcount 目录对 userb 用户有读、写、执行权限;而 mvcount 目录下面的文件对 userb 用户有读、写权限,这样就满足了权限需求,再通过 userb 用户来读、写 mvcount 这张表,发现已经可以对此表进行读、写操作了。
小结
本课时主要介绍了在 HDFS 中 POSIX 权限以及 POSIX ACL 的使用。在多用户使用场景中,权限控制至关重要,而通过 ACL 规则控制 HDFS 文件的读、写、执行权限,可以做到更加精细化的权限控制,并且简单、高效。
精选评论
hamburgduo:
老师,ranger是如何做的权限控制?
讲师回复:
要使用ranger控制权限的话,可以通过ambari来实现,已经集成了此工具,使用更简单。
-
-
相关阅读:
【Python机器学习】零基础掌握LinearDiscriminantAnalysis判别分析
2022杭电多校第一场
数字转型新动力,开源创新赋能数字经济高质量发展
Redis五个使用场景
FPGA - Verilog题目: 非整数倍数据位宽转换24to128
青少年软件编程(Python语言)等级考试试卷目录一览
SM4国密4在jdk1.7版本和jdk1.8版本中的工具类使用
Mysql事务原理
MySQL数据库基础知识要点总结
Convert Office Documents to PDF/A Formats
- 原文地址:https://blog.csdn.net/fegus/article/details/126435889