-
深度学习之 12 循环神经网络RNN 3
本文是接着上一篇深度学习之 12 循环神经网络RNN2_水w的博客-CSDN博客
目录
序列数据处理
(1)序列数据:
(2)读取数据,
DataFrame :一个表格型的数据结构,包含有 一组有序的列,每列可以是不同的值类型(数值、字符串、布尔型等),DataFrame即有行索引也 有列索引,可以被看做是由Series组成的字典。
(3)
处理目标: 将原始序列数据处理为方便模型运算的序列数据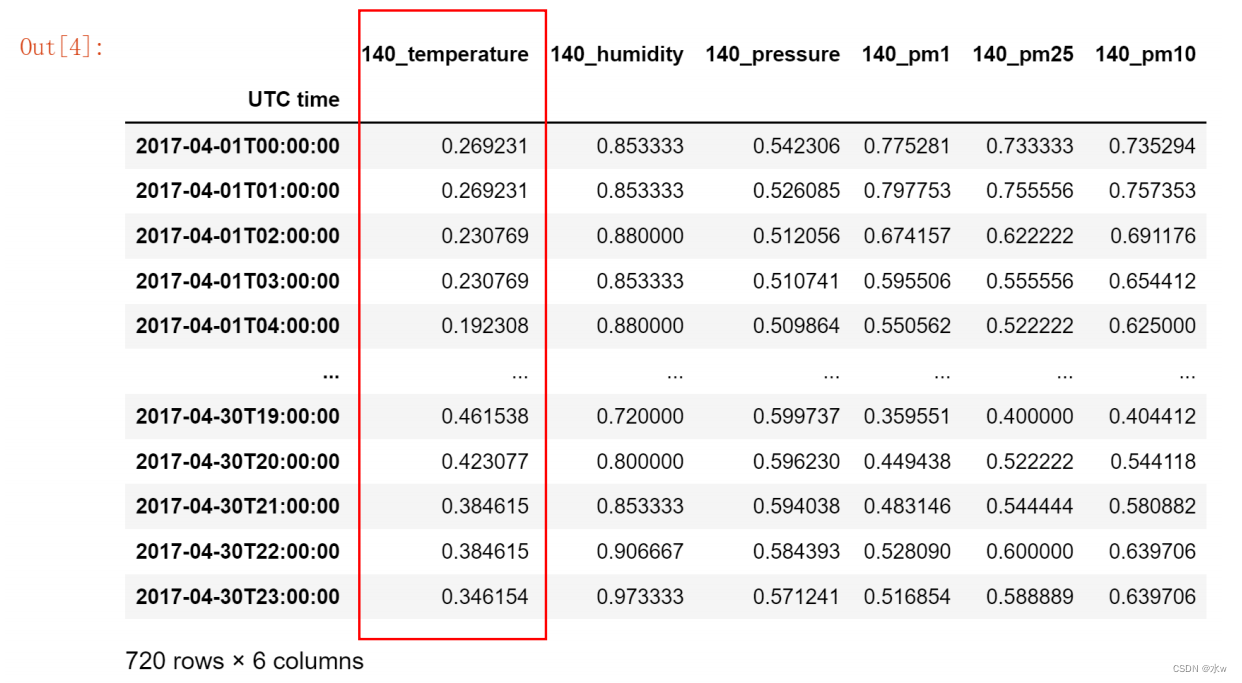
1 基本处理
◼ 固定长度滑动窗口
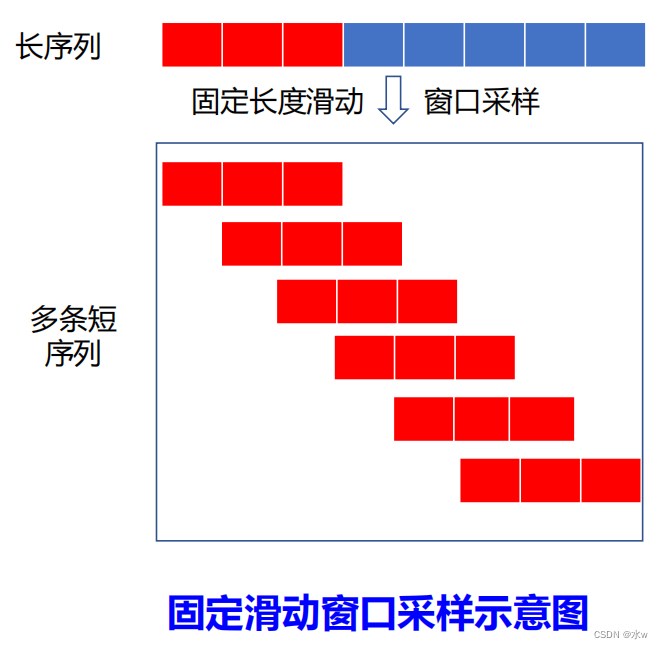

切分之前,只有一条长度为720的长序列。经过切分之后,就变成了709条长度是12的短序列。这样既给我们提供了足够多的样本供模型学习,而且同时也减少了序列的长度,方便我们构造模型。
◼ 数据集划分注意事项
先划分原始长序列,再采样短序列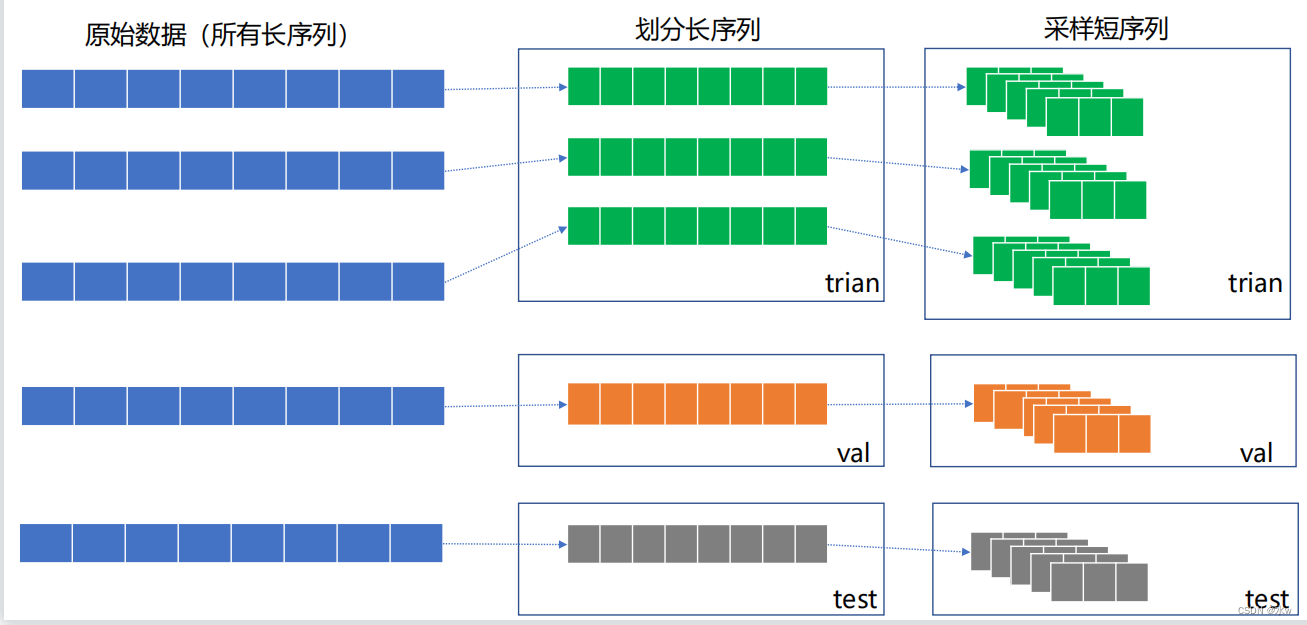
这么做的主要的这个目的就是为了避免交叉,因为我们的划窗操作它是每次向后走一个元素,每次向后滑长度为1,那这样就必然会造成后一个滑窗和前一个滑窗是存在一些交叉部分的,如果说先对整个所有的长序列进行了一个滑窗。那再去对这些得到的短序列进行划分的时候,必然会产生我验证级当中一部分的特征,其实在训练集当中已经出现过了。
当然咱们既然是滑窗,不可能完全出现,但你出现过一部分了。那这其实产生了一种交叉,出现了一种特征层面的数据泄露。那这样其实是我们不希望看到的。这样划分出来验证集和测试集并不能很好的去衡量模型的泛化能力。
所以说我们要一定要先把长序列给切分好,按照训练集,验证集,测试集切分好,然后再在各自内部进行划窗。
◼ 数据集划分示例代码
先对这个长序列进行索引,取出这个三条。短序列分别作为 训练集,验证集,测试集,然后我再对它们各自进行一个划窗。所以说这个先后顺序,大家一定要把握好,绝对不能说我先划窗生成短序列,再划分,那这样就会产生重叠。
2 高级处理
◼ 序列重采样
作为一个时间序列,它很有可能出现那种情况,就是在时间戳上它是不连续的。那这个时候我们可以对它进行 重采样和差分。①序列重采样重采样的操作:首先在时间戳序列上,对它进行一个补齐。那这个时候我们具体的做法呢?用到了几个稍微那个可能复杂一点儿的操作,比如我们要把这个时间出维度,把它转化成这个date time,这个形式。这是一种数据类型。哈date time型,然后把它要设为索引。将原始长序列中缺失的 时间戳 补全, 缺失时间点值被填充为 nan
◼ 序列插分
线性插分 ,将 空缺的值 补全, 使用interpolate进行线性插分- method: 插分方式(线性、零值、指定值);
- axis: 插分维度(默认为0);
- limit: 最大查分长度;

◼ 固定时间跨度滑动窗口
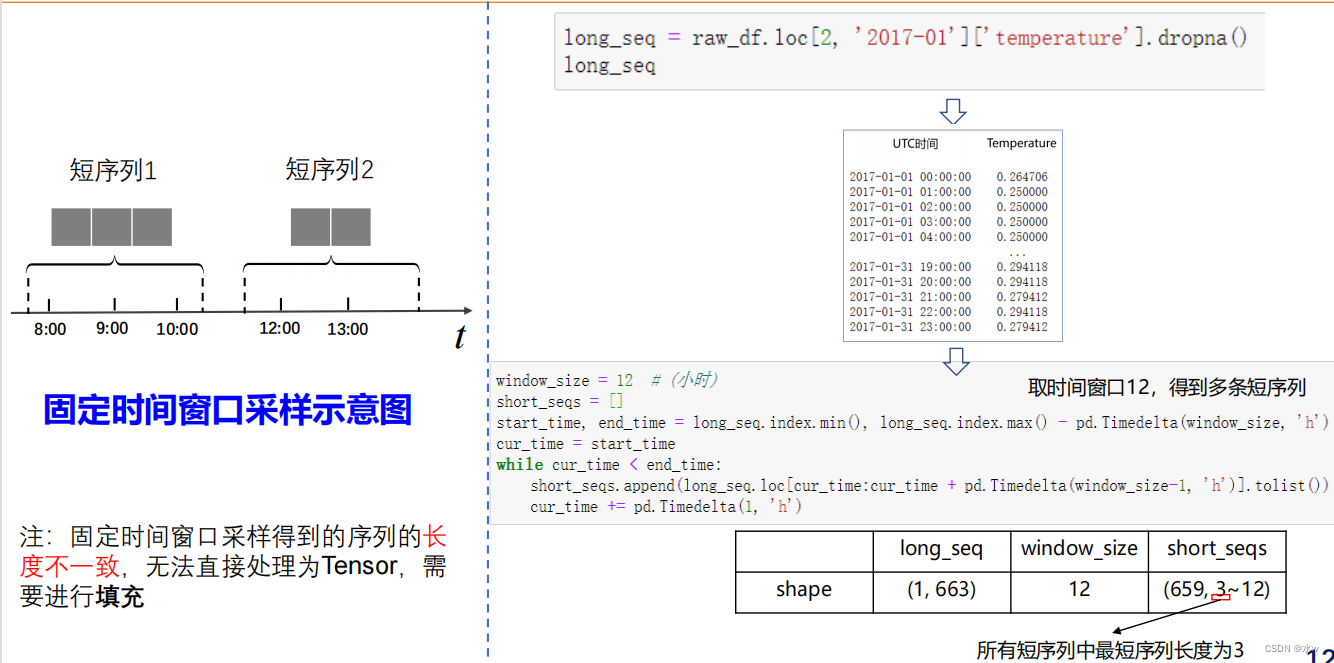 注:固定时间窗口采样得到的序列的长度不一致,无法直接处理为Tensor,需要进行填充。这个长序列,我对它进行这个固定时间窗口滑动之后,它得到的短序列,其实长度是不一样的。因为在那个时间维度上,它的分布是不均匀的。所以我固定时间窗口去对它进行滑动,得到短序列,也是完全有可能不等长的。那么由此,其实我们可以引出下一个问题就是,我们刚才得到这种不等长序列,我们如何去把它送到模型当中去学习?
注:固定时间窗口采样得到的序列的长度不一致,无法直接处理为Tensor,需要进行填充。这个长序列,我对它进行这个固定时间窗口滑动之后,它得到的短序列,其实长度是不一样的。因为在那个时间维度上,它的分布是不均匀的。所以我固定时间窗口去对它进行滑动,得到短序列,也是完全有可能不等长的。那么由此,其实我们可以引出下一个问题就是,我们刚才得到这种不等长序列,我们如何去把它送到模型当中去学习?◼ 不等长序列填充&打包
我们知道不管是porch还是tensor它处理的数据必须是一个向量,或者是方阵。除了说像刚才我们提到说固定时间窗口滑动可能产生这种不等长序列,其实大家在这个真正今后的科研过程当中很大概率会遇到这种各个样本之间,它长度就是不一样。那这个时候我们怎么办?我们首先要做的第一步呢,是将它填充这个填充的本质就是一个padding操作补零。 但是它是不知道你哪些数字是你自己补上去的,哪些是真实有效的数字的?如果你要是直接把它往里放的话,它会认为比如说这个第三条序列。它会认为后四个0也是要学习的东西,那这个就可能很大程度上会影响模型的学习,那这个时候我们怎么办呢?我们需要把这种padded后的数据,进行一个打包,吧padded_seq序列传入函数,同时还得 需要统计并输入每条序列的长度 ,告诉函数真实长度。
但是它是不知道你哪些数字是你自己补上去的,哪些是真实有效的数字的?如果你要是直接把它往里放的话,它会认为比如说这个第三条序列。它会认为后四个0也是要学习的东西,那这个就可能很大程度上会影响模型的学习,那这个时候我们怎么办呢?我们需要把这种padded后的数据,进行一个打包,吧padded_seq序列传入函数,同时还得 需要统计并输入每条序列的长度 ,告诉函数真实长度。3 面向对象的数据集构造
◼ 数据读取与标准化
通过使用面向对象的方法可以将读取、标准化、重采样、差分等一系列对数据的处理封装起来, 提高代码可用性。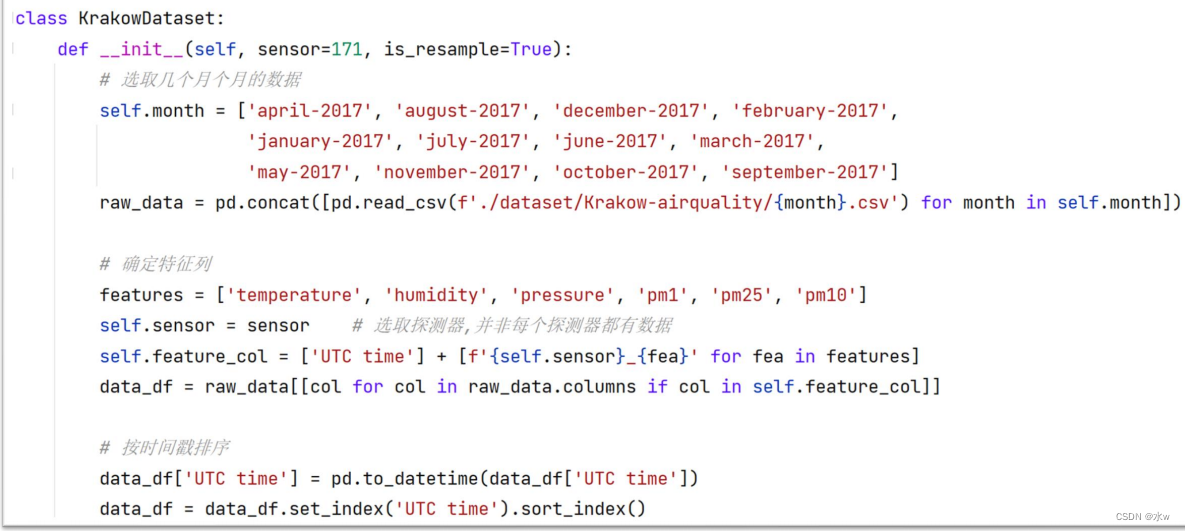

最后我们在这里做了一个数据标准化。那么这个数据标准化其实就是我们此次要使用面向对象最关键的一个点。因为我们使用了面向对象,我们就可以通过这种类内的这个变量去存储我当前数据集的最大和最小值情况,这样我们对它进行标准化之后,我们在后边是可以对它进行一个逆标准化的。

◼ 逆标准化函数
逆标准化:将数据幅度从0-1之间,放大回原有尺度
◼ 数据集的构建
• 分割训练集、验证集、测试集;• 使用滑窗技巧将数据集分割;• 构造样本,指定特征作为待预测特征,前n步预测n+1步;• 将分割后数据集封装到nn.dataset中; • torch.utils.data.Dataset:一种torch自带的用于 封装数据集 的数据类型;• torch.utils.data.DataLoader:一种torch自带的用于 加载数据 的数据类型;官方介绍文档:https://pytorch.org/docs/stable/data.html
• torch.utils.data.Dataset:一种torch自带的用于 封装数据集 的数据类型;• torch.utils.data.DataLoader:一种torch自带的用于 加载数据 的数据类型;官方介绍文档:https://pytorch.org/docs/stable/data.html得到datasets之后,放入dataloader 进行数据的迭代输出就可以了。

循环神经网络
1 基本原理
• 循环神经网络能够处理 任意长度的时序数据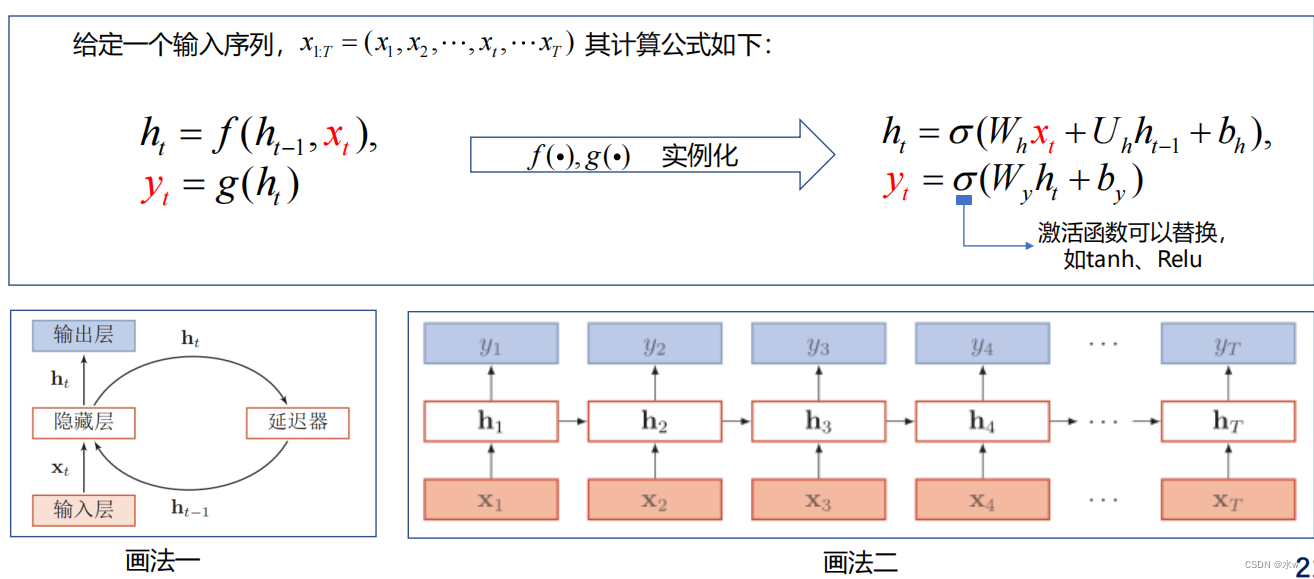
2 动手实现
◼ 模型实现 – 定义和初始化参数
• 参数维度定义• 激活函数选取• 参数初始化定义一个继承字model类的类。在里边定义好我所有要使用的参数以及隐藏层的激活函数,以及输出层的激活函数,drab函数是否要定义大家可以自行决定。

◼ 隐状态更新
• 隐藏状态初始化• 循环迭代更新• 注意返回值forward函数这里注意,跟之前的网络有一点不一样。定义了一个for循环,长度是整个序列的长度。对于序列中的每一个位置进行x和h的计算。
对整个序列来说,RNN的每一个单元处理序列,每一个位置的每一个单元,它的W和B实际上是共享的。就Wh, Uh, Bh。在整个序列上其实是共享的。
那这个时候大家要引起重视,这个RNN它并不是说我去初始化一个和序列一样长的模型,不是的。我是初始化了一个单元,这个单元在整个序列上滑动。相当于是我定义了一个前馈神经网络,沿着数据沿着我这个数据的序列。去做这样一步一步的输出的。这个本质它底层是有一个参数共享的机制。

返回的是最后一步的隐藏层和所有Y的输出。
注意:训练函数,不可能说给每个模型都重写一个,尽量保证做实验的每个模型,这个H和Y。它的顺序就谁在前,谁在后,尽量保持一致。要不然不断去调代码,会比较痛苦。
◼ 数据读取
得到3个数据集,

◼模型训练
初始化模型、loss 函数、优化器 :- 设备,输入维度,隐藏层输出的大小,序列长度,学习率;
- 定义损失函数;
- 初始化模型;
- 优化器;

调用训练函数,

train()函数:
- 首先定义预存储的loss列表,
- 然后两层for循环:外层是每一轮,内层是取dataloader中的每一个batch的数据。

注意:调用nn接口里的RNN,是没有输出层的,需要单独传输出层的。所以这里定义如果有输出层的model传进来,那么就会把我们刚刚得到的结果再去过一遍;如果没有输出层,那么就直接squeeze了。

- loss计算:需要逆归一化之后再计算指标。
也就是说预测出来的值是基于归一化之后的特征,计算出来的Y值。如果不对它进行归一化,那计算出来的真实指标会很离谱。

- 对验证集的运行,早停机制

◼ eval()函数
在utils.py脚本中实现了对三种测试指标的封装
• 定义和实现指标函数;• 对于回归任务一般选取 RMSE, MAE, MAPE;• Scikit-learn中提供了MAE和MSE;• RMSE由MSE求根得到;• MAPE需要自己实现;
◼ 测试函数:把模型切成测试模式,
在测试过程中,不使用droupout。如果还测试过程中继续使用droupout可能会影响模型的表现。在训练过程中使用droupout,相当于进行正则化提升模型的泛化能力。

◼ 可视化函数:使用PIL
两个函数:一个可以用来画loss,一个可以用来画各个指标。

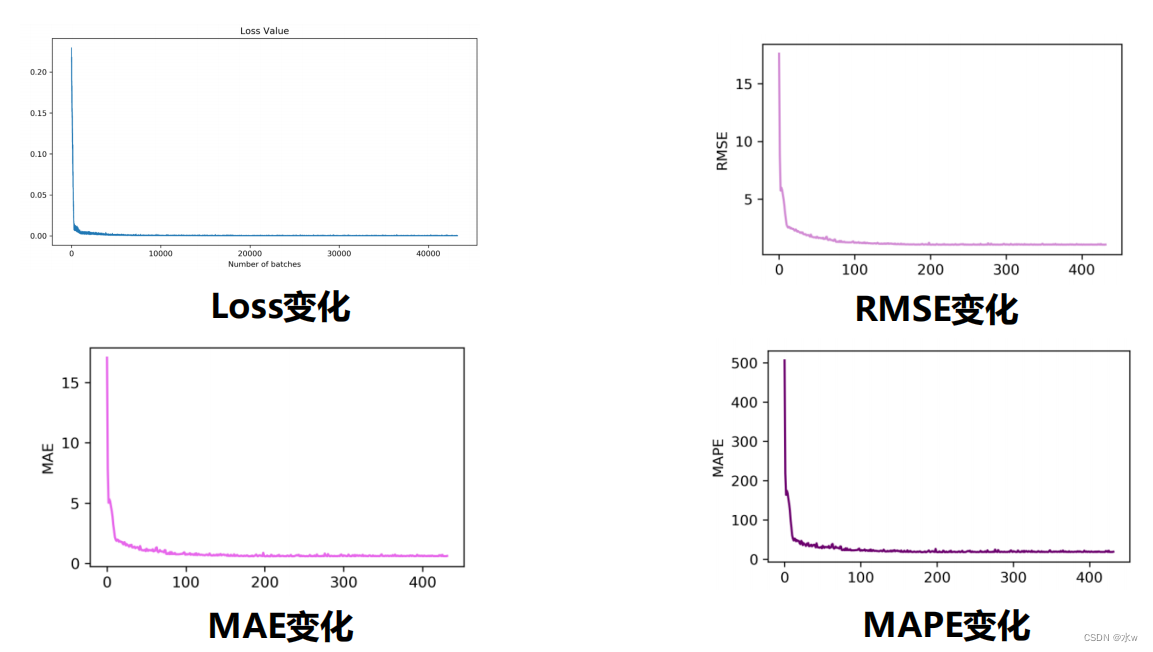
◼ 训练结果可视化

3 torch.nn.RNN
注意:输入参数中没有output参数。output本质上是每一个单元的隐藏状态。如果要做序列到序列的任务时,需要再加一个输出层。但是最后一步的隐藏状态已经包含了整个序列的信息,相当于是得到了序列的嵌入表示,直接用它也可以。

把batch_first置为true。
单独定义输出层之后,得保证它和RNN的承诺书是一起学习的,此时我们就把它们各自的参数用list相加的形式,放到adam优化器中去。这样我们在做梯度下降和优化的时候就可以一起优化了。


长短期记忆网络
1 基本原理
LSTM :Long Short Term Memory networks• 一种特殊形式的RNN;• 解决 长程依赖问题;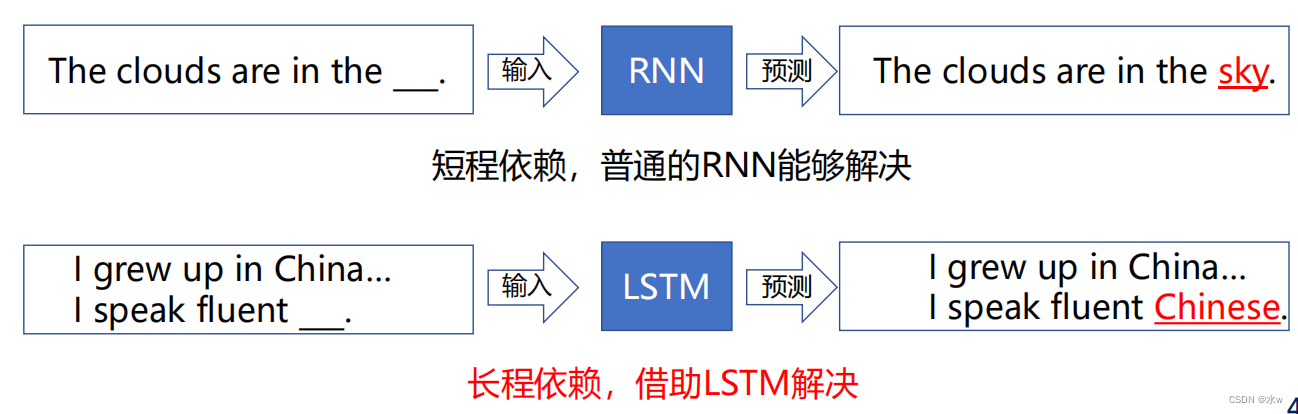
 • LSTM的核心是 细胞状态 ,用贯穿细胞的 水平线 表示所有的cell,来表示长期的这样一种信息的传递。
• LSTM的核心是 细胞状态 ,用贯穿细胞的 水平线 表示所有的cell,来表示长期的这样一种信息的传递。
• 1)计算遗忘门,决定细胞状态需要舍弃哪部分无用信息

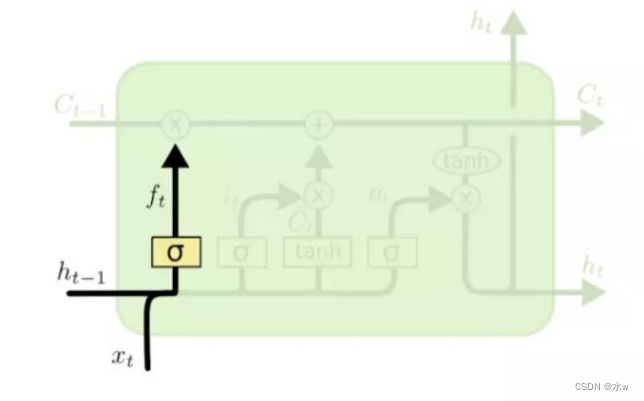 • 2)计算 输入门, 决定细胞状态需要添加哪些有用信息
• 2)计算 输入门, 决定细胞状态需要添加哪些有用信息

• 3)计算候选细胞状态


• 4)更新细胞状态

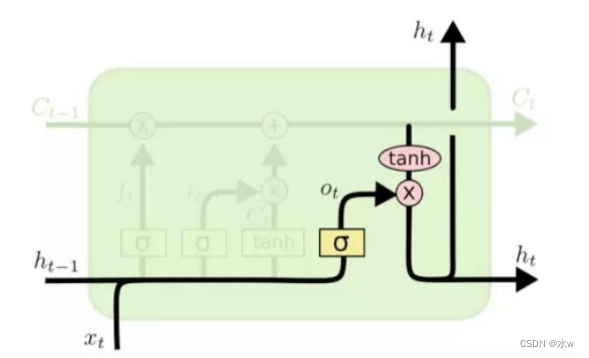 • 5)计算 输出门 ,控制细胞状态中哪些信息被输出:
• 5)计算 输出门 ,控制细胞状态中哪些信息被输出: • 6)计算输出隐状态
• 6)计算输出隐状态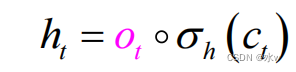
2 动手实现
◼ 模型实现 – 初始化参数
- forget遗忘门
- input输入门。output输出门
- 细胞状态
对当前状态,对当前输入和上一时刻隐藏层的计算做了4次线性操作加激活函数。最终得到的是一个输出门权重,遗忘门权重,以及候选细胞状态。
◼ 模型实现
• 初始化隐藏状态hidden_state 为全0向量;• 按照公式循环迭代更新hidden_state,计算输出;• 返回每一步的输出和最后一步的隐藏状态、细胞状态;• 注意不同地方的 激活函数 的选取;
如果没有GPU,那么模型跑起来非常慢。
◼ 优化模型实现思路
核心思想:合并矩阵运算,提高并行性1)各门控计算优化,以遗忘门为例:

2)所有门控一起合并计算:

◼ 优化模型实现
- gates:横向拼接,纵向同时计算4个门,
- 激活函数,参数初始化;
- forward函数:
- cat函数把第i个和最后一个h拼接在一起,然后过gates()这个线性层。
- 把它们切成等长的4份,得到了3个门和一个细胞候选状态。相当于我只做了一次矩阵运算,这种并行的效率比之前的串行效率提高了很多。
- 紧接着对3个门过sigmoid激活函数,然后细胞候选状态和最后的输出过tanh激活函数。
- 最终得到了输出和hiddlen以及细胞状态。

◼ 训练结果可视化

3 torch.nn.LSTM


门控循环单元
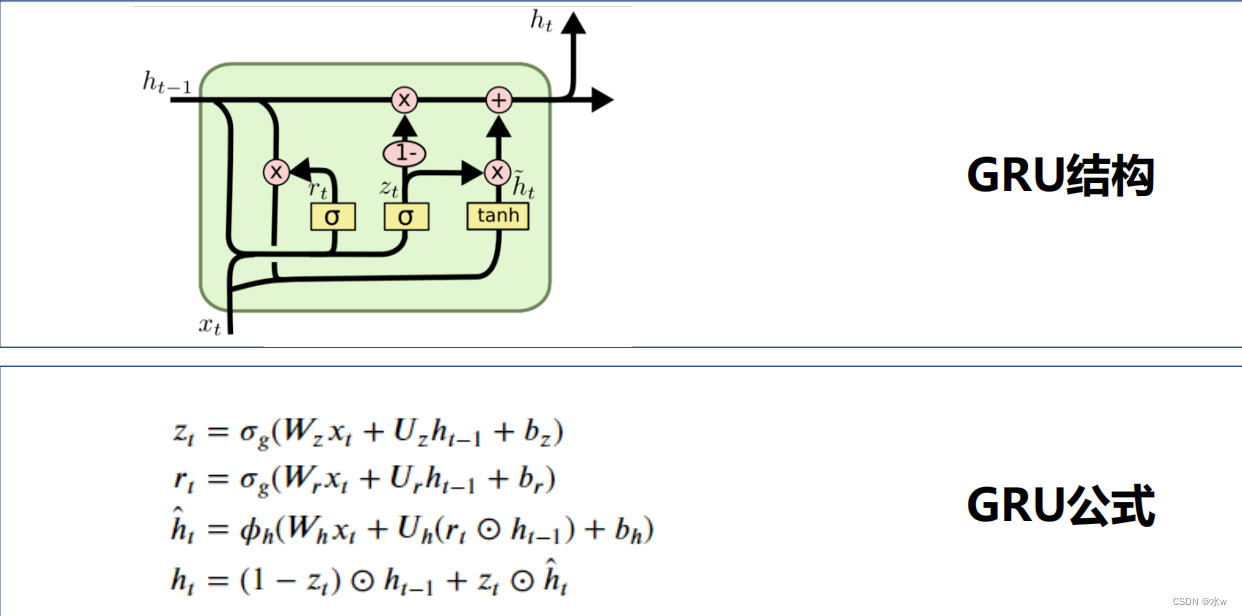
1 基本原理
GRU :Gate Recurrent Unit• 一种特殊形式的RNN;• 相比LSTM,简化门控机制,提高计算效率;• 门控:• 重置门 :控制遗忘多少之前时刻的信息;• 更新门 zt :控制保留多少当前时刻的信息;


◼ 训练结果可视化

4 RNN的一些应用
◼ 序列到类别

◼ 序列到序列

◼ 写字、作诗

◼ 看图说话

-
相关阅读:
Real-Time Rendering——16.1 Sources of Three-Dimensional Data三维数据的来源
贤鱼的刷题日常(数据结构栈学习)--P1175 表达式的转换--题目详解
springboot项目使用拦截器和注解方式验证token
[附源码]Python计算机毕业设计Django微信点餐系统
【无标题】
ADAS可视化系统,让自动驾驶更简单 -- 入门篇
基于matlab实现的卡尔曼滤波匀加速直线运动仿真
UE5.1编辑器拓展【一、脚本化资产行为,通知,弹窗,高效复制多个同样的资产】
【毕业季·进击的技术er】机械专业在校生的学习规划
spring AOP注解@Aspect的使用
- 原文地址:https://blog.csdn.net/qq_45956730/article/details/126415617