-
char可以存汉字吗,底层是怎么存的?
先给出结论:
-
char变量是用来存储Unicode编码字符的,采用Unicode编码集,一个char占用两个字节,而一个中文字符也是两个字节,因此Java中的char是可以表示一个中文字符的;
-
Java内部其实是使用的UTF-16的编码,所以是支持大部分非生僻汉字的;
-
Java的char只能表示UTF-16中的BMP部分的中文字符,不能表示扩展字符集里的中文字符;
Java中char类型使用16位无符号整数来描述unicode中最早一批收录的字符,这批字符后来被叫作Basic Multilingual Plane(BMP)。
char类型是按照Unicode规范实现的一种数据类型,固定16bit大小,范围为 [U+0000,U+FFFF] (无符号16进制)。现如今,Unicode字符集已经进行了扩展,表示的范围已经超过了16bit。Unicode字符集的数值范围扩大到了[U+0000,U+10FFFF]。
一个char能够存储16bit大小的数值,即2个字节。但是,就常用的UTF-8编码来说,我们都听说过他是用3或者4个字节来表示一个汉字的。就拿3个字节来算的话,一个char也存不下是不是?
而且,绝大部分的中文字符的Unicode范围是[0x4E00, 0x9FBB],恰好是char可存储的范围内。
是不是说这里出现了破解不了的矛盾呢?UTF-8占用3到4个字节,char只能存2个字节(16bit),然而UTF-8中的几乎所有汉字都是在char可存储的范围内,是不是矛盾了?
不矛盾,这里给出解释:
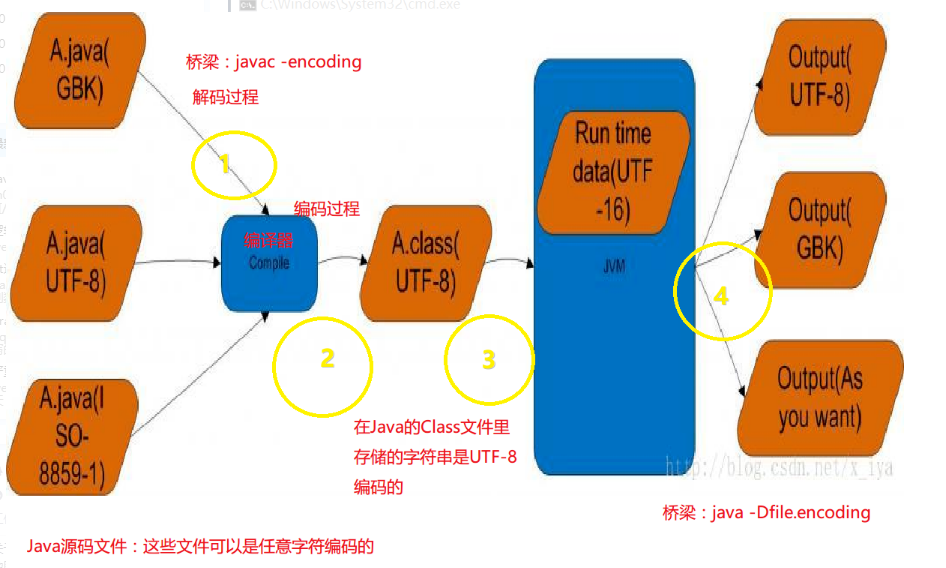
先看图,首先我们得清楚class文件编码格式是UTF-8,JVM虚拟机内存中字符编码是UTF-16,而Java代码是在虚拟机运行的.
UTF-16编码对于占用两个字节的字符是直接存储Unicode值,而UTF-8有标识位所以需要三个字节才能存储.
具体内容可参考我的这两篇文章:
-
-
相关阅读:
扩展包的安装
SkyWalking快速上手(五)——存放在内存、数据持久化
Slf4j(门面)
【OFDM系列6】MIMO-OFDM系统模型、迫零(ZF)均衡检测和最小均方误差(MMSE)均衡检测原理和公式推导
CentOS和Ubuntu中防火墙相关命令
软考高级架构师下篇-17安全架构设计理论与实践
LeetCode 541. 反转字符串 II
(干货) 差分对信号的长度和间距基于什么而界定的,一文了解。
C++中的继承
C语言数据结构 —— 复杂度
- 原文地址:https://blog.csdn.net/qq_51409098/article/details/126421767