-
2022 全球 AI 模型周报
本周介绍了 5 个多模态的深度学习模型: CLIP 连接文本与图像、 BLIP 统一图文理解与生成、 LightningDot 加速图文跨模态检索、 Data2Vec 兼容文本与音频、 Perceiver 进一步模拟人类处理不同模态数据。
如果你觉得我们分享的内容还不错,请不要吝啬给我们一些免费的鼓励:点赞、喜欢、或者分享给你的小伙伴。
多模态顶流模型 CLIP 连接语言与视觉
出品人:Towhee 技术团队 顾梦佳
OpenAI 从互联网收集了 4 亿对(图像、文本)的数据集,在预训练之后,用自然语言描述所学的视觉概念,从而使模型能够在 zero-shot 状态下转移到下游任务。这种设计类似于 GPT-2 和 GPT-3 的“zero-shot”,因此 CLIP¹ 可以不直接针对基准进行优化,同时表现出了优越的性能。实验表明,CLIP 模型的稳健性差距(robustness gap)缩小了 75%,性能和 ResNet50 相当。无需使用其训练的128万个训练样本中的任何一个,即可匹敌原始 ResNet50 在 ImageNet 上 Zero-shot 的精确度。

Summary of CLIP
CLIP 能够将图像映射到文本描述的类别中。它可以通过自然语言监督有效地学习视觉概念,从而解决目前深度学习主流方法存在的一些问题。如同大部分跨模态框架,CLIP 模型包括图像编码器和文本编码器,通过计算与比较图像表征与文本表征之间的相似性,对数据集中的图像与文本进行配对。当进行 zero-shot 迁移任务时,CLIP 将数据集原本的类别标签拓展成更丰富的文本表达,从而利用预训练模型找到与其最匹配的图像。
相关资料:
-
更多资料:【多模态】CLIP模型 - 知乎
统一图文理解与生成,BLIP 为多模态预训练模型带来新思路
出品人:Towhee 技术团队 王翔宇、顾梦佳
BLIP 在模型结构与数据处理上分别进行了创新与改进,使得多模态模型不再局限于任务类型,从而统一了视觉与语言的跨模态理解与生成。它在诸多下游任务中都取得了 SOTA 的效果,比如图文检索、图像描述(文本生成)、视觉问答。
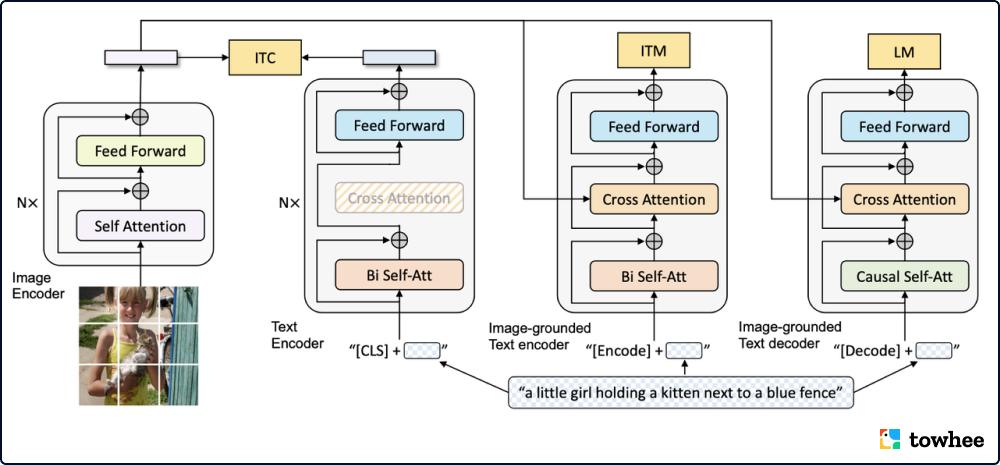
BLIP: Architecture of Pretrained Model
如今大部分文本-图像多模态模型的结构基础大体分为两种,且各自有限制:基于编码器的模型不适用于生成任务,而基于编码器和解码器结构的模型则胜任检索任务。此外,大部分模型所用的数据都来自于网络上的图像文本对,尽管性能收益可以通过扩大数据集的规模得到,但该方法依然存在诸多缺陷。面对这些问题,BLIP 提出一种新的图像文本预训练框架,有效地将自举的方式利用到有噪声的网络数据上。模型使用一个描述器生成文本描述,并且通过一个过滤器清洗数据噪声。
相关资料:
图文跨模态检索的黑马模型 LightningDot, 千倍提速,不影响准确率!
出品人:Towhee 技术团队 张晨、顾梦佳
多模态预训练已经推动了视觉和语言研究的巨大进步。这些大规模的预训练模型虽然成功,但却有一个致命缺点:由于巨大的计算成本(主要来自 Transformer 架构中的跨模态注意力),其推理速度缓慢。当模型被应用到现实生活中时,这样的延迟和大量的计算需求严重阻碍了预训练模型的落地生产。LightningDot² 针对视觉&文本应用中最成熟的场景——图像-文本检索(ITR),提出了一种简单而高效的方法。它能在不影响准确性的情况下,将推理速度加快数千倍!
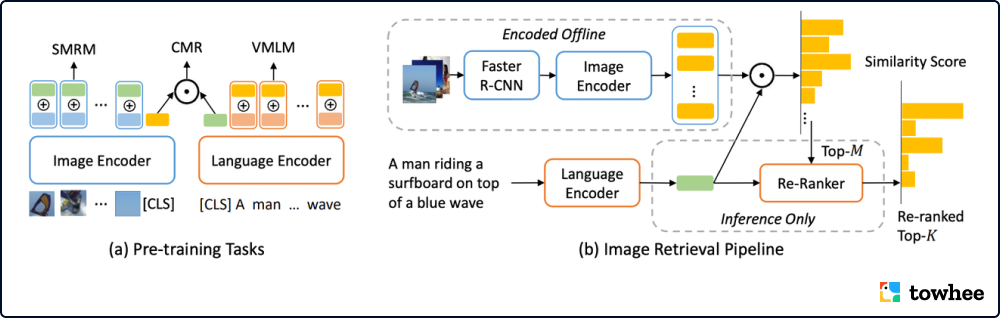
Overall Architecture of LightningDot
LightningDOT 通过对三个新的学习目标进行预训练,实现离线提取特征索引。它另外采用了即时点积匹配与进一步的重新排序,大幅加快了检索过程,从而消除了耗时的跨模式注意力。实验结果表明,LightningDOT 在 Flickr30k、COCO 和 Multi30K 等多个图文检索数据集的基准中达到了新的技术水平,超过了当时已有的预训练模型,甚至比它们节省了1000倍数量级的时间。
相关资料:
自监督学习框架 data2vec,文本、图像、音频都能行
出品人:Towhee 技术团队 王翔宇、顾梦佳
实际生活中的场景鲜少只有单一模态的数据,而不同数据通常需要单独的算法模型。相信大家都想过,有没有一个通用的模型能够处理不同类型的数据?Facebook 人工智能研究院就提出了一种能够处理视觉、文本、语音数据的通用自监督框架 data2vec。实验结果表明,data2vec³ 不仅拓宽了业务领域,在各种任务上(比如图像分类、自然语言理解、语音识别)也都展示出了具有竞争力的表现,甚至在视觉领域超越了一些曾经的热门算法。
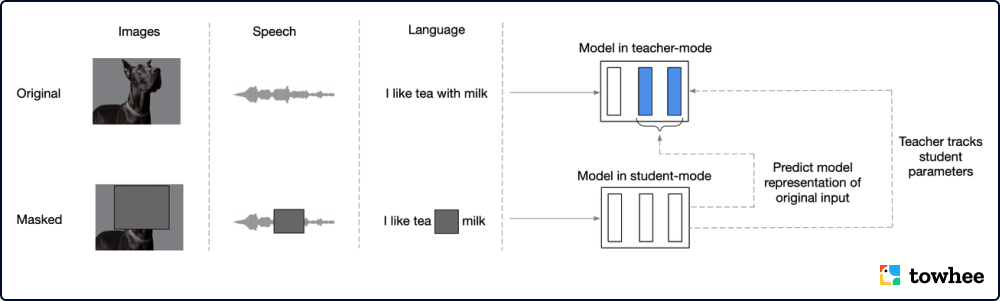
data2vec for different modalities
data2vec 将不同模态的输入都转换成了同一种形式的数据序列,基于 transformer 设计了一个教师-学生形式的网络结构。训练时,其核心思路是将数据上进行部分遮盖,用模型生成潜在表示并预测被遮盖的部分。为了避免不同模态之间的差异性,data2vec 并没有使用和模态绑定的重建目标(文本,视觉记号,语音单元),而是选择预测带有上下文的潜在表示。
相关资料:
谷歌提出硬核高效的多模态架构 Perceiver
出品人:Towhee 技术团队 徐锦玲、顾梦佳
Perceiver 不需要改变模型结构就能处理多种模态的数据,这更加接近人类感知行为。与以往的视觉 Transformer 不同,Perceiver 直接在图像的像素层面进行注意力计算,这使得其能够处理不同尺寸的输入数据。实验对图像、音频、视频、点云数据都进行了测试,结果表明 Perceiver 在不同模态数据的分类任务上均能达到或超越 SoTA 效果。

Perceiver Structure
Perceiver⁴ 模型大体由两种基础结构组成:交叉注意力机制(cross-attention)和 Transformer 编码器(latent transformer)。模型将输入的数据按像素层面展开成一维向量,然后将该向量通过 MLP 得到注意力机制需要的 K、V 。另外,模型通过随机初始化得到较小维度的隐向量(latent array),在保证模型复杂度的情况下,可以直接处理任意长的输入,即获得处理不同尺寸图像的能力。最后,通过堆叠多个交叉注意力机制和 Transformer 编码器模块,模型能够充分挖掘输入向量的信息。
相关资料:
-
模型用例:https://github.com/towhee-io/towhee/tree/main/towhee/models/perceiver
-
更多资料:DeepMind 提出 Perceiver:使用RNN的方式进行注意力,通过交叉注意力节省计算量,附使用方法 - 知乎
如果你觉得我们分享的内容还不错,请不要吝啬给我们一些鼓励:点赞、喜欢或者分享给你的小伙伴!
活动信息、技术分享和招聘速递请关注:你好👋,数据探索者
 https://zilliz.gitee.io/welcome/
https://zilliz.gitee.io/welcome/如果你对我们的项目感兴趣请关注:
-
相关阅读:
嵌入式养成计划-47----QT--基于QT的OpenCV库实现人脸识别功能
萨特——治愈了迷茫的你吗
Linux命令(107)之basename
基于PHP的医药博客管理系统
测试工程师面试之设计测试用例
SQLite 3.39.0 发布,支持右外连接和全外连接
delete-by-query和复合查询
Spring - BeanDefinitionRegistryPostProcessor 扩展接口 动态注册bean
Android OpenCV 身份证识别实战
k8s dashboard安装部署实战详细手册
- 原文地址:https://blog.csdn.net/weixin_44839084/article/details/126426427
 https://github.com/towhee-io/towhee/tree/main/towhee/models
https://github.com/towhee-io/towhee/tree/main/towhee/models