-
5.java集合与线程全面总结
集合和线程学习思维导图
思维导图是重点,下面的文字内容就是简单的记录一些比较重要的知识点(凑凑字),正常的知识点都在思维导图里,没详细的说明的一查也是一堆说明(能详细说明的都详细说明了,没详细说明的可能是疏忽或者不重要)

java集合是对数组的封装和扩展,增强了对数组的操作性,目前集合有如下3类12种:
- List类型下有四种:
ArrayListLinkedListVector->Stack
- Set类型下有三种
HashSet->LinkedHashSetTreeSet
- Map类型的有如下五种:
HashMap -> LinkedHashMapTreeMapHashTableWeakHashMap
对基本集合需要掌握内容(全部内容已在思维导图里说明了,下面内容只记录了一些重点知识):
每种集合底层的数据结构每种集合的扩容方式每种集合的数据存储顺序,和数据结构相关集合和线程安全性(这里只有vector,hashtable是线程安全的,其他的都不是,java中线程安全的集合都在JUC里,所以这里线程安全不是重点)集合的一些操作,添加删除遍历
集合
Arraylist 与 LinkedList区别
是否保证线程安全: ArrayList 和 LinkedList 都是不同步的,也就是不保证线程安全;底层数据结构: Arraylist 底层使⽤的是 Object 数组; LinkedList 底层使⽤的是 双
向链表 数据结构(JDK1.6 之前为循环链表,JDK1.7 取消了循环。注意双向链表和双向循环链
表的区别,下⾯有介绍到!)插⼊和删除是否受元素位置的影响: ① ArrayList 采⽤数组存储,所以插⼊和删除元素的
时间复杂度受元素位置的影响。 ⽐如:执⾏ add(E e) ⽅法的时候, ArrayList 会默认在
将指定的元素追加到此列表的末尾,这种情况时间复杂度就是 O(1)。但是如果要在指定位置 i
插⼊和删除元素的话( add(int index, E element) )时间复杂度就为 O(n-i)。因为在进
⾏上述操作的时候集合中第 i 和第 i 个元素之后的(n-i)个元素都要执⾏向后位/向前移⼀位的
操作。 ② LinkedList 采⽤链表存储,所以对于 add(E e) ⽅法的插⼊,删除元素时间复杂
度不受元素位置的影响,近似 O(1),如果是要在指定位置 i 插⼊和删除元素的话( (add(int
index, E element) ) 时间复杂度近似为 o(n)) 因为需要先移动到指定位置再插⼊。是否⽀持快速随机访问: LinkedList 不⽀持⾼效的随机元素访问,⽽ ArrayList ⽀持。
快速随机访问就是通过元素的序号快速获取元素对象(对应于 get(int index) ⽅法)。内存空间占⽤: ArrayList 的空 间浪费主要体现在在 list 列表的结尾会预留⼀定的容量空
间,⽽ LinkedList 的空间花费则体现在它的每⼀个元素都需要消耗⽐ ArrayList 更多的空间
(因为要存放直接后继和直接前驱以及数据)ArrayList 实现了 RandomAccess 接⼝, ⽽ LinkedList 没有实现。(RandomAccess 接⼝不过是⼀个标识罢了。标识什么? 标识实现这个接⼝的类具有随机访问功能, binarySearch() ⽅法中,它要判断传⼊的 list 是否 RamdomAccess 的实例,如果是,调
⽤ indexedBinarySearch() ⽅法,如果不是,那么调⽤ iteratorBinarySearch() ⽅法)
HashMap
HashMap是使用了哈希表的数据结构中的拉链法构建的一种集合,这个集合可以保证存入数的key是唯一的。并且以此集合为基础构建了HashSet
此外根据HashMap的底层原理:使用自定义的类型作为hash的key,需要重写hashCode()和equal()方法,hashcode用来获得这个对象的hash值java里的hash值是一个整数奥int类型,equal是用来比较对象hash值是否相同的。HashMap底层实现的数据结构是Entry
Node,Node实现了Entry接口,记录了hash,key,value,next四个值
所以一个数据进入到hashmap的时候通过hash值计算出在数组的位置后,找到这个位置会再依次比较hash值是否相同,相同覆盖value,不同给next增加节点。static class Node<K,V> implements Map.Entry<K,V> { final int hash; final K key; V value; Node<K,V> next; Node(int hash, K key, V value, Node<K,V> next) { this.hash = hash; this.key = key; this.value = value; this.next = next; } public final K getKey() { return key; } public final V getValue() { return value; } public final String toString() { return key + "=" + value; } public final int hashCode() { return Objects.hashCode(key) ^ Objects.hashCode(value); } public final V setValue(V newValue) { V oldValue = value; value = newValue; return oldValue; } public final boolean equals(Object o) { if (o == this) return true; if (o instanceof Map.Entry) { Map.Entry<?,?> e = (Map.Entry<?,?>)o; if (Objects.equals(key, e.getKey()) && Objects.equals(value, e.getValue())) return true; } return false; } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
关于hashMap通过hash值计算数组中的位置
获得每个对象的hash值,这个hash值根据对象的一些属性长度或一些别的数字信息输入一个hash函数计算而来,也就是说每个对象本身能获得一个表示他自身的唯一数字(需要设计),然后对这个数字进行hash函数计算获得加密后的结果。- hashmap里再次使用一个hash函数进行
hash扰动 - 扰动后的结果再次通过hash函数,计算获得他在数组上的位置。(
再次计算hash的目的是为了获得hash值在当前长度的数组上的位置,第一次hash扰动的hash结果是在-2147483648 到 2147483647之间的,这个结果不能直接用来找数组位置,因此要再次hash,这说明可以使用多次hash来获得新的范围的hash值)
-再次hash如何把数据映射到指定长度的数组内呢:答案是对数组长度值取余hash%length,这个操作对应的二进制操作是hash&(length-1)前提是 length 是 2的 n 次⽅;)
这里有个问题是什么要采用2的次幂作为数组长度:这里的因果关系是底层实现采用了位运算来计算余数,所以要满足长度为2的幂次,如果底层只是采用了取余操作,那就可以任意长度了。
hashMap的扩容机制
扩容结构变化:JDK1.8 以后的 HashMap 在解决哈希冲突时有了较⼤的变化,当链表⻓度⼤于阈值(默认为 8)(将链表转换成红⿊树前会判断,如果当前数组的⻓度⼩于 64,那么会选择先进⾏数组扩容,⽽不是转换为红⿊树)时,将链表转化为红⿊树,以减少搜索时间。Hashtable 没有这样的机制。
扩容因子:扩容因子是0.75,举个例子:当前的容器容量是16,负载因子是0.75;16*0.75=12,也就是说,当容量达到了12的时就会执行扩容操作。
二、原因解释
在考虑HashMap时,首先要想到的是HashMap只是一个数据结构,既然是数据结构最主要的就是节省时间和空间。负载因子的作用肯定也是节省时间和空间。为什么节省呢?我们考虑两种极端情况。
1、负载因子是1.0
数据一开始是保存在数组里,当发生了Hash碰撞的时候,就是在这个数据节点上,生出一个链表,当链表长度达到一定长度的时候,就会把链表转化为红黑树。
当负载因子是1.0时,也就意味着,只有当数组的8个值(这个图表示了8个)全部填充了,才会发生扩容。这就带来了很大的问题,因为Hash冲突时避免不了的。
后果:当负载因子是1.0的时候,意味着会出现大量的Hash的冲突,底层的红黑树变得异常复杂。对于查询效率极其不利。这种情况就是牺牲了时间来保证空间的利用率。
因此一句话总结就是负载因子过大,虽然空间利用率上去了,但是时间效率降低了。
2、负载因子是0.5
后果:负载因子是0.5的时候,这也就意味着,当数组中的元素达到了一半就开始扩容,既然填充的元素少了,Hash冲突也会减少,那么底层的链表长度或者是红黑树的高度就会降低。查询效率就会增加。
但是,此时空间利用率就会大大的降低,原本存储1M的数据,现在就意味着需要2M的空间。
总之,就是负载因子太小,虽然时间效率提升了,但是空间利用率降低了。
3、负载因子0.75
时间和空间的权衡,负载因子是0.75的时,空间利用率比较高,而且避免了相当多的Hash冲突,使得底层的链表或者是红黑树的高度比较低,提升了空间效率。

HashMap 有哪⼏种常⻅的遍历⽅式
hashmap的常见遍历方式
不用看也知道是stream方式了,感兴趣的可以详细看看
使用迭代器(Iterator)EntrySet 的方式进行遍历;
使用迭代器(Iterator)KeySet 的方式进行遍历;
使用 For Each EntrySet 的方式进行遍历;
使用 For Each KeySet 的方式进行遍历;
使用 Lambda 表达式的方式进行遍历;
使用 Streams API 单线程的方式进行遍历;
使用 Streams API 多线程的方式进行遍历。public class HashMapTest { public static void main(String[] args) { // 创建并赋值 HashMap Map<Integer, String> map = new HashMap(); map.put(1, "Java"); map.put(2, "JDK"); map.put(3, "Spring Framework"); map.put(4, "MyBatis framework"); map.put(5, "Java中文社群"); // 遍历 Iterator<Map.Entry<Integer, String>> iterator = map.entrySet().iterator(); while (iterator.hasNext()) { Map.Entry<Integer, String> entry = iterator.next(); System.out.print(entry.getKey()); System.out.print(entry.getValue()); } } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
LinkedHashMap
LinkedHashMap是在HashMap的基础上,使用了双向链表结构,按照存入数据的顺序把数据进行了管理绑定,保证了存的数据顺序为输入的顺序。

与集合相关类和一些知识
集合与迭代器
迭代器是一种设计模式,把数组或者集合传入迭代器中,迭代器内部只对外提供操作集合的几个方法,使得用户无法看到全部的集合,但是可以通过调用next方法依次获得集合中的一个元素。保护了内部的集合,可以自定义元素的访问逻辑和删除逻辑,统一了集合的访问范式,使得通过遍历访问集合的方式更加优雅。
java中迭代器继承·terator接口,必须实现hashNext和next方法,实现这两个方法的中心思想就是根据迭代器内部的集合形式,自定义next()方法和hasNext()方法,需要设置全局变量记录当前访问集合的序号,next()方法只要返回集合中的对象就行,并且将索引加1,hasNext就是判断当前索引是否超出集合长度。
java的所有集合内部都实现了一个迭代器,可以获得这个迭代器用来遍历数据定义迭代器private class Itr implements Iterator<E> { int cursor; // index of next element to return int lastRet = -1; // index of last element returned; -1 if no such int expectedModCount = modCount; Itr() {} public boolean hasNext() { return cursor != size; } @SuppressWarnings("unchecked") public E next() { checkForComodification(); int i = cursor; if (i >= size) throw new NoSuchElementException(); Object[] elementData = ArrayList.this.elementData; if (i >= elementData.length) throw new ConcurrentModificationException(); cursor = i + 1; return (E) elementData[lastRet = i]; } public void remove() { if (lastRet < 0) throw new IllegalStateException(); checkForComodification(); try { ArrayList.this.remove(lastRet); cursor = lastRet; lastRet = -1; expectedModCount = modCount; } catch (IndexOutOfBoundsException ex) { throw new ConcurrentModificationException(); } } @Override @SuppressWarnings("unchecked") public void forEachRemaining(Consumer<? super E> consumer) { Objects.requireNonNull(consumer); final int size = ArrayList.this.size; int i = cursor; if (i >= size) { return; } final Object[] elementData = ArrayList.this.elementData; if (i >= elementData.length) { throw new ConcurrentModificationException(); } while (i != size && modCount == expectedModCount) { consumer.accept((E) elementData[i++]); } // update once at end of iteration to reduce heap write traffic cursor = i; lastRet = i - 1; checkForComodification(); } final void checkForComodification() { if (modCount != expectedModCount) throw new ConcurrentModificationException(); } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
使用迭代器Map<Integer, String> map = new HashMap(); map.put(1, "Java"); map.put(2, "C++"); map.put(3, "PHP"); Iterator<Map.Entry<Integer, Stringef iterator = map.entrySet().iterator(); while (iterator.hasNext()) { Map.Entry<Integer, String> entry = iterator.next(); System.out.println(entry.getKey() + entry.getValue()); }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
集合与比较器
比较器就是比较两个对象的大小的,具体方式就是两个对象相减是大于0小于0还是等于0,以此判断两个对象的大小的。
比较器分为两类,一类是内部比较器,一种是外部比较器- 内部比较器和类的定义耦合在一起,通过继承comparable接口重写接口的compareTo方法实现,该方法传入一个对象参数,这个参数会和该类的实例进行比较
- 外部比较器是一种和类解耦的独立的比较器,通过继承comparator接口重写了compare方法实现的,该方法传入两个待比较的对象
实现comparable接口的比较器public class Person implements Comparable<Person> { private String name; private int age; public Person(String name, int age) { super(); this.name = name; this.age = age; } public String getName() { return name; } public void setName(String name) { this.name = name; } public int getAge() { return age; } public void setAge(int age) { this.age = age; } /** * T重写compareTo⽅法实现按年龄来排序 */ @Override public int compareTo(Person o) { if (this.age > o.getAge()) { return 1; } if (this.age < o.getAge()) { return -1; } return 0; } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
实现comparator接口的比较器class Person{ public int age; } public class Tcomparator implements Comparator<Person> { @Override public int compare(Person o1, Person o2) { return o1.age-o2.age; } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
// 定制排序的⽤法 Collections.sort(arrayList, new Comparator<Integer>() { @Override public int compare(Integer o1, Integer o2) { return o2.compareTo(o1); } });- 1
- 2
- 3
- 4
- 5
- 6
- 7
集合与流stream
stream流式操作,用来对集合进行快速操作的一个类,和c#的linq类似,实现了类似sql查询数据统计数据的功能
具体功能使用参考:stream的基本操作
原理参考这里:stream原理现在不准备深究原理,后续再说
特点:使用lambda表达式处理数据声明式函数编程(一种链式调用的方式完成数据处理过程,传统的处理方式是一行一行代码完成数据处理,处理过程在书写上是独立分开的,而声明式的是依次点出来的)使用流编程,效率高(流不是数据结构,流的数据来自集合、数组或I/O通道)
集合与线程
集合和线程交互的目的是为了保证数据的安全,所以会进行加锁操作,重要的是队列的AQS锁
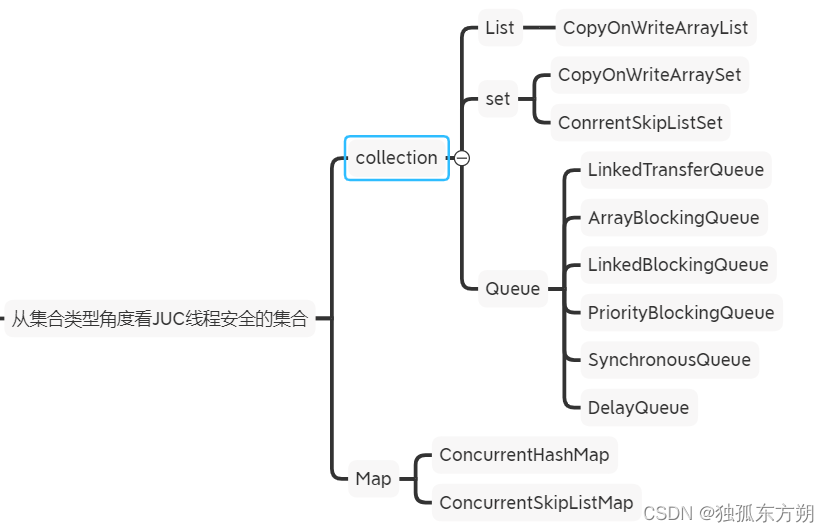
集合工具类
Collections类
Arrays类
Arrays.asList()避免坑
Arrays.asList()用来把数组转为集合,但是需要注意它接收的参数必须是对象数组,而不是基本数据类型数组
使用基本数据数组,无法调用对应集合的方法int[] myArray = { 1, 2, 3 }; List myList = Arrays.asList(myArray); System.out.println(myList.size());//1 System.out.println(myList.get(0));//数组地址值 System.out.println(myList.get(1));//报错:ArrayIndexOutOfBoundsException int [] array=(int[]) myList.get(0); System.out.println(array[0]);//1- 1
- 2
- 3
- 4
- 5
- 6
- 7
改为对象类型数组,可以进行调用了Integer[] myArray = { 1, 2, 3 } List myList = Arrays.asList(myArray); System.out.println(myList.size());//1 System.out.println(myList.get(0));//数组地址值 System.out.println(myList.get(1));//报错:ArrayIndexOutOfBoundsException int [] array=(int[]) myList.get(0); System.out.println(array[0]);//1- 1
- 2
- 3
- 4
- 5
- 6
- 7
因此从数组抓为集合,
要使用对象类型的数组,或者直接在Arrays.asLis里写值,他会自动转为对象
List jdks = new ArrayList<>(Arrays.asList(“JDK6”, “JDK8”, “JDK10”));线程
线程主要掌握如下知识点:
线程的生命周期线程的生命周期内的操作线程锁线程间的通信线程缓存线程的底层操作系统和JVM知识
JMM内存模型
JMM内存模型的定位介绍,主要有两个定位:- JMM模型是为了屏蔽操作系统底层的内存分配操作,直接提供统一的操作接口供JVM使用,其实是一种规范,和JDBC一样
- 为不同线程之间的数据相互做了统一的规定,按照规则操作数据可以保证线程数据的安全性。
总结:就是告诉你Java的内存是怎么设计的,怎么用才会线程安全,线程不安全了或者怎么设计线程安全应该考虑的内存模型底层的问题有哪些。
定位一:屏蔽底层,提供统一的数据操作(给JVM使用的)
这个定位特性体现在如下两方法:
方面一:
将内存空间划分两个区域:主存公共区域各个线程共享,工作内存,线程独享,主存公共区域就相当堆空间,工作内存就是虚拟机栈里占用的内存。当然内存是JMM定义的逻辑区域,底层内存可能是在CPU上,内存条上,但是有了JMM这些就不用我们管了,只要知道JMM中的内存区域只有两部分,具体内存的交互逻辑如下:
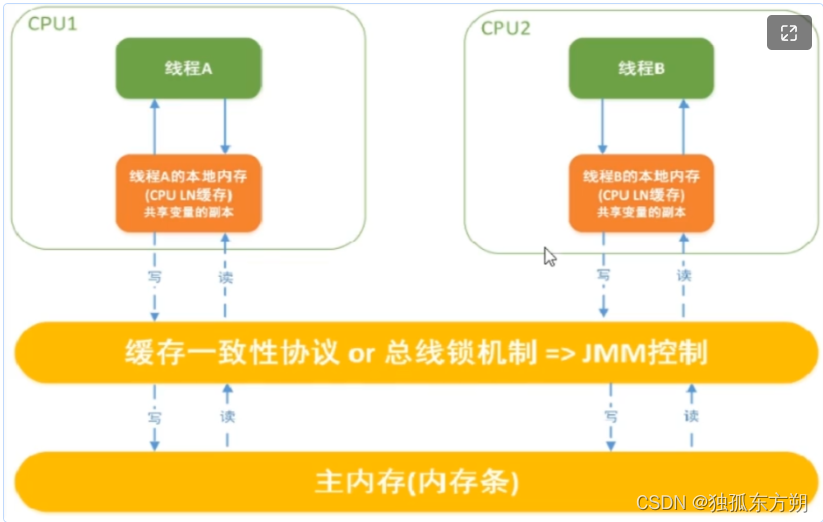
方面二:
除了定义内存的区域划分外,JMM也定义了数据在内存区域之间的交互过程,共有八大操作:加锁,解锁读取,加载保存,写入使用,赋值,分为四组,成对使用,不可以单独用,熟悉字节码指令的可以看出来这些操作在字节码文件里都有对应的指令,也不是一模一样完全对应,就是有一定关系,让知识产生 一个联系,具体的操作图示和一些具体规范就如下说明:


操作规定- 不允许read和load、store和write操作之一单独出现。即使用了read必须load,使用了store必须write
- 不允许线程丢弃他最近的assign操作,即工作变量的数据改变了之后,必须告知主存
- 不允许一个线程将没有assign的数据从工作内存同步回主内存
- 一个新的全局变量必须在主内存中诞生,不允许工作内存直接使用一个未被初始化的变量(
工作区诞生的数据局部变量,可以不守这个规则,但是必须赋值)。就是怼变量实施use、store操作之前,必须经过assign和load操作 - 一个变量同一时间只有一个线程能对其进行lock。多次lock后,必须执行相同次数的unlock才能解锁
如果对一个变量进行lock操作,会清空所有工作内存中此变量的值,在执行引擎使用这个变量前,必须重新load或assign操作初始化变量的值- 如果一个变量没有被lock,就不能对其进行unlock操作。也不能unlock一个被其他线程锁住的变量
- 对一个变量进行unlock操作之前,必须把此变量同步回主内存
总结:
公共数据存在主存,工作内存使用的时候要规范的加锁,然后赋值到工作空间,使用完成后,立马刷回到主存。这种线程安全的规范给到JVM实现的时候就是volatile关键字,锁等内容。定位二:提供一种规范,遵循规范可以多线程操作下保证数据的安全
提供了保证数据安全的三种特性:
可见性,原子性,有序性,三种特性不一定要必须全部满足才会线程安全,只是告诉你考虑线程安全的时候要从这三个方面出发考虑
可见性:一个数据对公共内存的数据操作完成后,立马让其他线程可以看到,这个特性需要使得内存数据被使用的时候所有未使用该数据的线程都清空对这个数据的使用,然后等更新使用完后,其他线程再次加锁获得这个数据,比如volitale,锁
原子性:执行的一个由多个子操作构成的操作的时候,必须是完整的不可被中途插入其他操作,就和数据库的事务一样,不可以被插入其他的操作。常见的使用原子性的操作过程就是锁,锁住资源和执行过程,其他线程无法打扰。最失败的无法保证原子性的就是volitale关键字,它对数据进行一次带有多个子操作的操作时,会被其他线程插入,抢夺到资源,进行数据更新,当抢夺线程更新数据的时候发现数据不是最新的时候,操作会被撤销,这样就会浪费一次操作,这也说明了volitale关键字不是锁,或者说是一种不能重试的乐观锁
有序性:字节码指令在执行的时候会优化重排,也就是改变了数据的执行顺序,对于存在数据依赖的操作来说,指令重排就无法获得先获得值在进行操作了,因此需要禁止指令重排,禁止指令重排的关键就是voliatle字段happens-before规则是针对可见性做的进一步的规范。
happens-before规则:- 程序次序规则:一个线程内,按照代码顺序,书写在前面的操作先行发生于书写在后面的操作;
- 锁定规则:一个unLock操作先行发生于后面对同一个锁额lock操作;
- volatile变量规则:对一个volatile域的写,happens-before于任意后续对这个volatile域的读
- 传递规则:如果A happens-before B,且B happens-before C,那么A happens-before C
- 线程启动规则:如果线程A执行操作ThreadB.start()(启动线程B),那么A线程的ThreadB.start()操作- happens-before于线程B中的任意操作
- 线程中断规则:对线程interrupt()方法的调用先行发生于被中断线程的代码检测到中断事件的发生;
- 线程终结规则:线程中所有的操作都先行发生于线程的终止检测,我们可以通过Thread.join()方法结束、Thread.isAlive()的返回值手段检测到线程已经终止执行;
- 对象终结规则:一个对象的初始化完成先行发生于他的finalize()方法的开始;
JMM模型的下的java线程安全功能的一些实现
volatile关键字
volatile关键字的特点可以保证数据的可见性和有序性,但是
无法保证原子性- 使用volatile关键字一方面是使用它的可见性,保证数据在不同线程之间可以共享,做线程标识
- 另一个方面是利用它的有序性,防止指令重排,来解决存在数据依赖的问题,保证结果运行顺序
内存屏障
内存屏障保证了数据的有序性。
内存屏障在voliatle关键字的读的时候,在其后面加锁,之后的写和读取都不可以重排
内存屏障在voliatle关键字写下的时候,在其前后加锁,之前之后的读写都不可以重排内存屏障具体分为
读屏障,写屏障和读写屏障
读屏障一般用来做条件判断,写屏障一般是用来赋值的- 读屏障,在读屏障之后插入loadload屏障,不允许之后的读操作重排到屏障之前
- 读屏障,在读屏障之后插入loadStore屏障,不允许之后的写操作重排到屏障之前
- 写屏障,在写屏障之前插入StoreStore屏障,不允许之前的写作重排到屏障之后
- 写屏障,在写屏障之后插入Storeload屏障,不允许之后的读操作重排到屏障之前
CAS
CAS是一种自旋锁,底层通过硬件实现,属于偏向锁,不存在内核状态切换,效率高,属于乐观锁,适合读多,写少的情况。写的多了很容易出现长期等待的情况。
ABA问题
ABA问题是因为一个CAS锁执行操作过程中把对象变量A变为B后又变为A,其他线程来拿到A操作之后回来发现还是A就可以更新数据了,这样存在一个问题就是A->B->A这个过程被隐藏了,没有别的线程可以发现,数据就存在安全隐患了。
解决办法:使用版本戳,记录每一步的操作。AQS
AQS就是一个双端队列+状态值的队列同步器,使用队列来完成线程同步调度。是JUC编程中锁的基础.
ReetentLock锁的代码结构- 这里使用了模板设计模式
- reetenlocke默认非公平锁
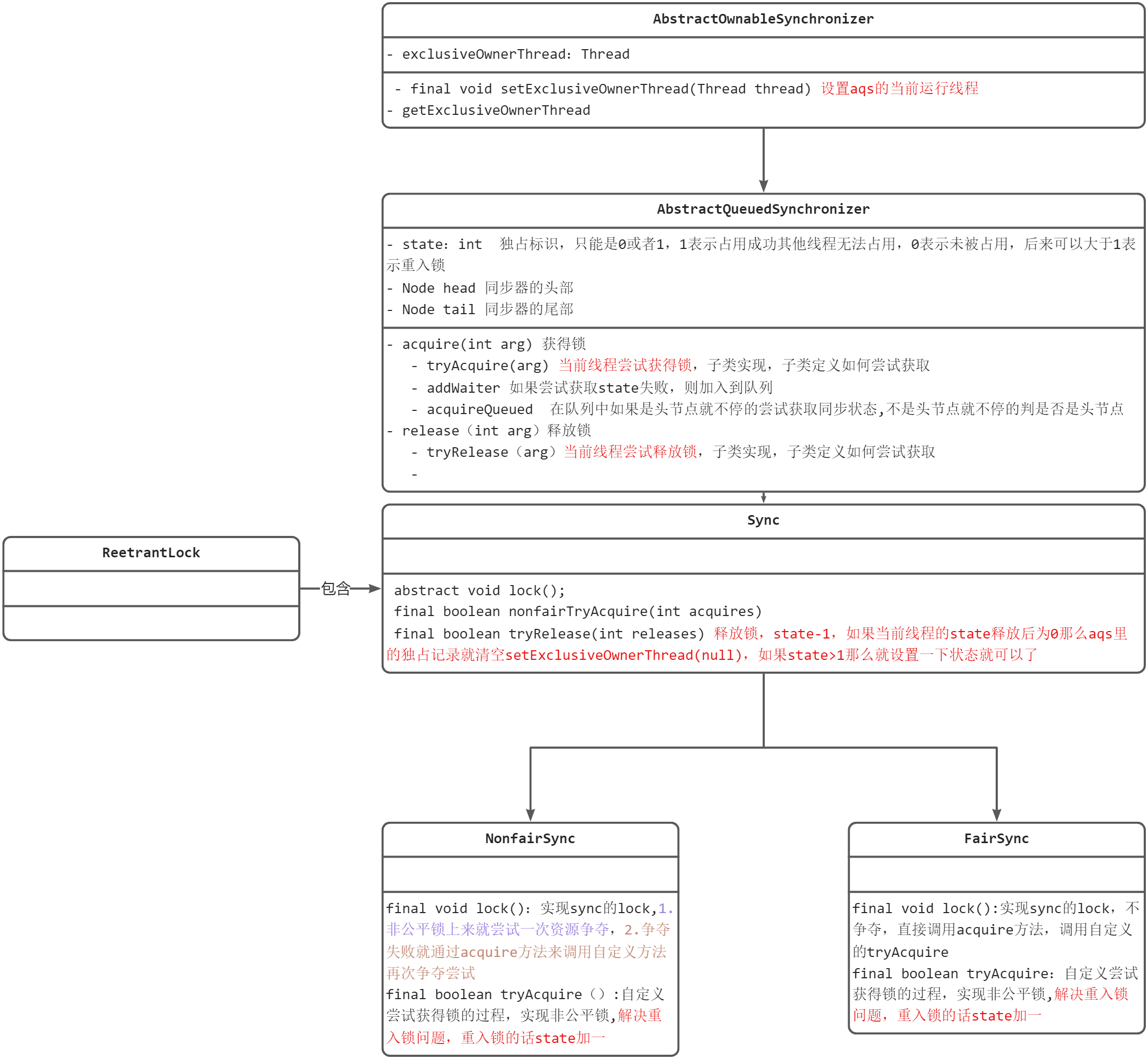
加锁解锁的流程:
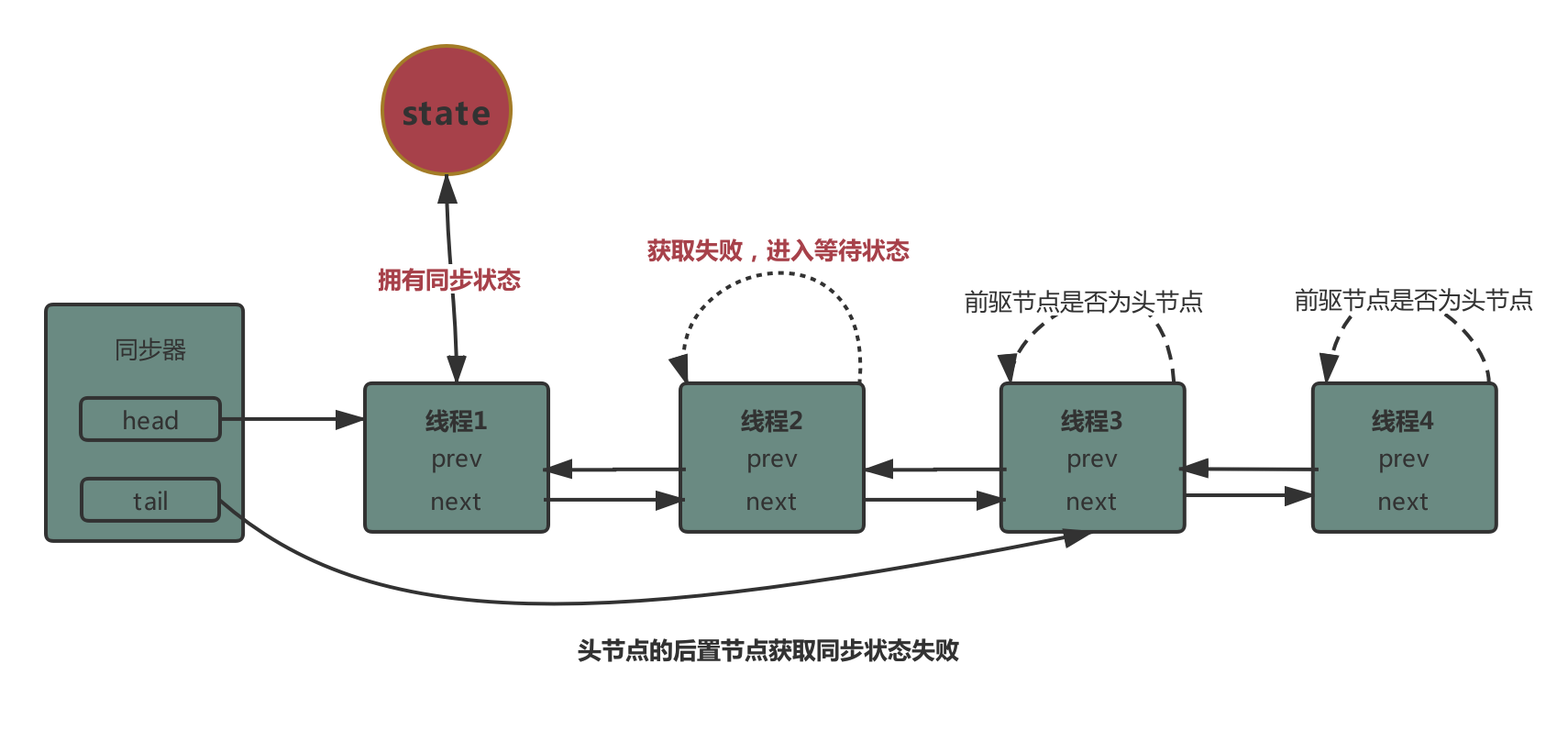

锁升级
锁升级就是针对sychronized锁进行的优化,不上来就加重量级锁,要根据实际情况慢慢升级,升级过程为:无锁,偏向锁,轻量级锁,重量级锁。锁一旦升级就不能降级,具体升级过程如下:

线程等待和阻塞的区别
线程可以通过
waitjoinLockSupport.park等方式进入等待状态,进入wating状态的线程等待唤醒(notify或notifyAll)才有机会获取cpu的时间片段来继续执行
唤醒后的线程进入同步阻塞队列等待被调用,阻塞队列里的状态就是blocked状态。
所以:与wating状态相关联的是等待队列,与blocked状态相关的是同步队列,,一个线程由等待队列迁移到同步队列时,线程状态将会由wating转化为blocked。源码分析;这两种队列在sychronizied锁的monitor监视器器里有字段记录:
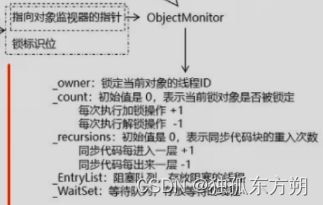
此外JUC的lock锁实现的AQS队列里也会使用线程state标记当前线程的状态等待还是阻塞 -
相关阅读:
榜样访谈——曾钰倬:从讲座中收获经验
【搜索】—— DFS之剪枝与优化
亲测解决np.fromiter转换list的时候出现cannot create object arrays from iterator
sqoop的安装和使用
MATLAB中detrend函数使用
Linux各目录的作用
bootloader介绍
【微服务】微服务之Feign 与 Ribbon
新型智慧公厕建设:引领公厕行业的未来!
AI写作助力:如何用AI降重工具快速提升论文原创性?
- 原文地址:https://blog.csdn.net/qq_37771209/article/details/126395388