-
GMM基础
GMM
定义
高斯混合模型就是用高斯概率密度函数(正态分布曲线)精确地量化事物,它是一个将事物分解为若干的基于高斯概率密度函数(正态分布曲线)形成的模型。
几何表示
假如我们我们现有的数据分布如红线所示,可以发现用一个高斯分布很难较好的描述这组数据的分布,所以我们能够用两个高斯分布加权平均得到一个新的分布,其中每一个数据点都有一定概率属于两个高斯分布中的一个。

GMM只是若干个高斯分布的加权平均(上图中是两个高斯分布)
P ( x ) = ∑ k = 1 K α k N ( μ k , Σ k ) ∑ k = 1 K α k = 1 P(x)=\sum_{k=1}^K\alpha_kN(\mu_k,\Sigma_k)\qquad\sum_{k=1}^K\alpha_k=1 P(x)=k=1∑KαkN(μk,Σk)k=1∑Kαk=1
每个数据点都有属于每个高斯分布的可能性,我们用概率去描述这个可能性设 x x x 表示观测数据; z z z 是我们引入的隐变量,用于表示对应的样本属于哪一个高斯分布。
在 G M M GMM GMM中, Z Z Z 是离散型的随机变量。
引入隐变量 Z Z Z 后,有:
P ( x ∣ θ ) = ∑ k = 1 K P ( x , z k = c k ∣ θ ) = ∑ k = 1 K P ( z k = c k ∣ θ ) P ( x ∣ z k = c k , θ ) = ∑ k = 1 P k ⋅ N ( x ∣ μ k , Σ k ) P(x|θ)=K∑k=1P(x,zk=ck|θ)=K∑k=1P(zk=ck|θ)P(x|zk=ck,θ)=∑k=1Pk·N(x|μk,Σk)P(x∣θ)=k=1∑KP(x,zk=ck∣θ)=k=1∑KP(zk=ck∣θ)P(x∣zk=ck,θ)=k=1∑Pk⋅N(x∣μk,Σk)P(x|θ)=∑k=1KP(x,zk=ck|θ)=∑k=1KP(zk=ck|θ)P(x|zk=ck,θ)=∑k=1Pk⋅N(x|μk,Σk) 用途
GMM,是一种业界广泛使用的聚类算法,该方法使用了高斯分布作为参数模型,并使用了期望最大(Expectation Maximization,简称EM)算法进行训练。
证明推导
极大似然估计(MLE)
极大似然估计,通俗理解来说,就是利用已知的样本结果信息,反推最具有可能(最大概率)导致这些样本结果出现的模型参数值!
模型 + 数据 → 参数 模型+数据\rightarrow 参数 模型+数据→参数
怎样的参数是最好的?使得观测数据出现的概率(即所谓likelihood,似然)最大的参数就是最好的。这个朴素的思想,就是极大似然估计(Maximum Likelihood Estimation, MLE)。对一个独立同分布(i.d.d)的样本集来说,总体的似然就是每个样本似然的乘积。假设我们已知模型是高斯分布 N ( μ , σ ) , μ 未知, σ 已知 N(\mu,\sigma),\mu未知,\sigma已知 N(μ,σ),μ未知,σ已知,和一组数据 X X X,那么它的似然就是
L ( μ ) = ∏ i N 1 2 π σ e − ( X i − μ ) 2 2 σ 2 L(\mu)=\prod_i^N\frac 1{\sqrt{2\pi}\sigma}e^{-\frac {(X_i-\mu)^2}{2\sigma^2}} L(μ)=i∏N2πσ1e−2σ2(Xi−μ)2
在实际中,因为连乘计算起来比较麻烦,并且概率都很小,难免越乘越接近0最终引发数值bug,因此多对其取log, 得到log似然( log likelihood):
L L ( μ ) = ∑ i N ( X i − μ ) 2 2 σ 2 − N 2 l o g 2 π − N l o g σ LL(\mu)=\sum_i^N\frac {(X_i-\mu)^2}{2\sigma^2}-\frac N2log2\pi-Nlog\sigma LL(μ)=i∑N2σ2(Xi−μ)2−2Nlog2π−Nlogσ
log并不改变似然函数的凸性,因此可令其对u取极值(函数取极值的方法:导数为0的点,边界点。),显然得到:
μ = ∑ i N X i N \mu=\frac {\sum_i^NX_i}{N} μ=N∑iNXi
这就完成了对高斯分布均值的极大似然估计。值得一提的是,该例的log似然实在是太简单,所以这个极值可以直接得到;在更多的情况下,我们需要通过梯度下降法等最优化算法来求解。GMM 参数求解
G M M GMM GMM模型似然函数
L ( θ ) = ∏ i = 1 n p ( x ( i ) ∣ θ ) = ∏ i = 1 n ∑ k = 1 K α k N ( x ( i ) ∣ μ k , σ k ) = ∏ i = 1 n ∑ k = 1 K p ( x ( i ) , z ( i ) = k ∣ θ ) = ∏ i = 1 n ∑ k = 1 K p ( z ( i ) = k ∣ θ ) p ( x ( i ) ∣ z ( i ) = k , θ ) (1) L(θ)=n∏i=1p(x(i)|θ)=n∏i=1K∑k=1αkN(x(i)|μk,σk)=n∏i=1K∑k=1p(x(i),z(i)=k|θ)=n∏i=1K∑k=1p(z(i)=k|θ)p(x(i)|z(i)=k,θ)\tag1 L(θ)=i=1∏np(x(i)∣θ)=i=1∏nk=1∑KαkN(x(i)∣μk,σk)=i=1∏nk=1∑Kp(x(i),z(i)=k∣θ)=i=1∏nk=1∑Kp(z(i)=k∣θ)p(x(i)∣z(i)=k,θ)(1)L(θ)=∏i=1np(x(i)|θ)=∏i=1n∑k=1KαkN(x(i)|μk,σk)=∏i=1n∑k=1Kp(x(i),z(i)=k|θ)=∏i=1n∑k=1Kp(z(i)=k|θ)p(x(i)|z(i)=k,θ) 对数似然
L L ( θ ) = l n L ( θ ) = ∑ i = 1 n l n ∑ k = 1 K α k N ( x ( i ) ∣ μ k , σ k ) = ∑ i = 1 n l n ∑ k = 1 K p ( z ( i ) = k ∣ θ ) p ( x ( i ) ∣ z ( i ) = k , θ ) LL(θ)=lnL(θ)=n∑i=1lnK∑k=1αkN(x(i)|μk,σk)=n∑i=1lnK∑k=1p(z(i)=k|θ)p(x(i)|z(i)=k,θ)LL(θ)=lnL(θ)=i=1∑nlnk=1∑KαkN(x(i)∣μk,σk)=i=1∑nlnk=1∑Kp(z(i)=k∣θ)p(x(i)∣z(i)=k,θ)LL(θ)=lnL(θ)=∑i=1nln∑k=1KαkN(x(i)|μk,σk)=∑i=1nln∑k=1Kp(z(i)=k|θ)p(x(i)|z(i)=k,θ)
G M M GMM GMM通过求不完全数据的边缘概率来得到完全数据的似然函数,因此:
θ = a r g m a x θ L L X \theta=\underset\theta{arg~max} LL_X θ=θarg maxLLXEM 算法求解参数
接下来使用EM算法来求解参数,EM算法分为E步,求期望;和M步,求期望最大化时的参数值。
E-step
直接求导来求得参数解不太现实,想办法将它转化。先给转化后的形式,再给分析:
L L ( θ ) = ∑ i = 1 n l n ∑ k = 1 K p ( z ( i ) = k ∣ θ ) p ( x ( i ) ∣ z ( i ) = k , θ ) = ∑ i = 1 n l n ∑ k = 1 K ω k ( i ) p ( z ( i ) = k ∣ θ ) p ( x ( i ) ∣ z ( i ) = k , θ ) ω k ( i ) ≥ ∑ i = 1 n ∑ k = 1 K ω k ( i ) l n p ( z ( i ) = k ∣ θ ) p ( x ( i ) ∣ z ( i ) = k , θ ) ω k ( i ) LL(θ)=n∑i=1lnK∑k=1p(z(i)=k|θ)p(x(i)|z(i)=k,θ)=n∑i=1lnK∑k=1ω(i)kp(z(i)=k|θ)p(x(i)|z(i)=k,θ)ω(i)k≥n∑i=1K∑k=1ω(i)klnp(z(i)=k|θ)p(x(i)|z(i)=k,θ)ω(i)kLL(θ)=i=1∑nlnk=1∑Kp(z(i)=k∣θ)p(x(i)∣z(i)=k,θ)=i=1∑nlnk=1∑Kωk(i)ωk(i)p(z(i)=k∣θ)p(x(i)∣z(i)=k,θ)≥i=1∑nk=1∑Kωk(i)lnωk(i)p(z(i)=k∣θ)p(x(i)∣z(i)=k,θ)LL(θ)=∑i=1nln∑k=1Kp(z(i)=k|θ)p(x(i)|z(i)=k,θ)=∑i=1nln∑k=1Kω(i)kp(z(i)=k|θ)p(x(i)|z(i)=k,θ)ω(i)k≥∑i=1n∑k=1Kω(i)klnp(z(i)=k|θ)p(x(i)|z(i)=k,θ)ω(i)k
步骤 2 2 2给每个样本 i i i引入一个分布 ω ( i ) \omega^{(i)} ω(i),满足
∑ i = 1 K ω k ( i ) = 1 \sum_{i=1}^K\omega_k^{(i)}=1 i=1∑Kωk(i)=1
步骤 3 3 3由 j e n s e n jensen jensen不等式得到j e n s e n jensen jensen不等式:对于一个凸(或凹)函数 f ( x ) f(x) f(x),其满足 E ( f ( x ) ) ≥ f ( E ( x ) ) E(f(x))\geq f(E(x)) E(f(x))≥f(E(x))(或) f ( E ( x ) ) ≥ E ( f ( x ) ) f(E(x))\geq E(f(x)) f(E(x))≥E(f(x)),当且仅当变量x为常数是等号成立,对数 l n ( ⋅ ) ln(·) ln(⋅)为凹函数,因此
l n ∑ k = 1 K ω k ( i ) p ( z ( i ) = k ∣ θ ) p ( x ( i ) ∣ z ( i ) = k , θ ) ω k ( i ) ≥ ∑ k = 1 K ω k ( i ) l n p ( z ( i ) = k ∣ θ ) p ( x ( i ) ∣ z ( i ) = k , θ ) ω k ( i ) ln\sum_{k=1}^K\omega_k^{(i)}\frac {p(z^{(i)}=k|\theta)p(x^{(i)}|z^{(i)}=k,\theta)}{\omega_k^{(i)}}\geq\sum_{k=1}^K\omega_k^{(i)}ln\frac {p(z^{(i)}=k|\theta)p(x^{(i)}|z^{(i)}=k,\theta)}{\omega_k^{(i)}} lnk=1∑Kωk(i)ωk(i)p(z(i)=k∣θ)p(x(i)∣z(i)=k,θ)≥k=1∑Kωk(i)lnωk(i)p(z(i)=k∣θ)p(x(i)∣z(i)=k,θ)
即期望的函数大于等于函数的期望。下一步是要使步骤三中的等号成立,使得对原优化问题转化为对步骤三的优化。前面说过,等号成立的条件是随机变量为常数,即
p ( z ( i ) = k ∣ θ ) p ( x ( i ) ∣ z ( i ) = k , θ ) ω k ( i ) = c ( 常数 ) \frac {p(z^{(i)}=k|\theta)p(x^{(i)}|z^{(i)}=k,\theta)}{\omega_k^{(i)}}=c(常数) ωk(i)p(z(i)=k∣θ)p(x(i)∣z(i)=k,θ)=c(常数)
所以
p ( z ( i ) = k ∣ θ ) p ( x ( i ) ∣ z ( i ) = k , θ ) = c ω k ( i ) ∑ k = 1 K p ( z ( i ) = k ∣ θ ) p ( x ( i ) ∣ z ( i ) = k , θ ) = ∑ k = 1 K c ω k ( i ) ∑ k = 1 K p ( z ( i ) = k ∣ θ ) p ( x ( i ) ∣ z ( i ) = k , θ ) = c ( 常数 ) {p(z^{(i)}=k|\theta)p(x^{(i)}|z^{(i)}=k,\theta)}=c{\omega_k^{(i)}}\\ \sum_{k=1}^K{p(z^{(i)}=k|\theta)p(x^{(i)}|z^{(i)}=k,\theta)}=\sum_{k=1}^Kc{\omega_k^{(i)}}\\ \sum_{k=1}^K{p(z^{(i)}=k|\theta)p(x^{(i)}|z^{(i)}=k,\theta)}=c(常数) p(z(i)=k∣θ)p(x(i)∣z(i)=k,θ)=cωk(i)k=1∑Kp(z(i)=k∣θ)p(x(i)∣z(i)=k,θ)=k=1∑Kcωk(i)k=1∑Kp(z(i)=k∣θ)p(x(i)∣z(i)=k,θ)=c(常数)
则
ω k ( i ) = p ( z ( i ) = k ∣ θ ) p ( x ( i ) ∣ z ( i ) = k , θ ) c = p ( z ( i ) = k ∣ θ ) p ( x ( i ) ∣ z ( i ) = k , θ ) ∑ k = 1 K p ( z ( i ) = k ∣ θ ) p ( x ( i ) ∣ z ( i ) = α k N ( x ( i ) ∣ μ k , σ k ) ∑ k = 1 K α k N ( x ( i ) ∣ μ k , σ k ) ω(i)k=p(z(i)=k|θ)p(x(i)|z(i)=k,θ)c=p(z(i)=k|θ)p(x(i)|z(i)=k,θ)∑Kk=1p(z(i)=k|θ)p(x(i)|z(i)=αkN(x(i)|μk,σk)∑Kk=1αkN(x(i)|μk,σk)ωk(i)=cp(z(i)=k∣θ)p(x(i)∣z(i)=k,θ)=∑k=1Kp(z(i)=k∣θ)p(x(i)∣z(i)p(z(i)=k∣θ)p(x(i)∣z(i)=k,θ)=∑k=1KαkN(x(i)∣μk,σk)αkN(x(i)∣μk,σk)
即在给定 θ \theta θ后,我们就能使用上式求出 ω ( i ) \omega^{(i)} ω(i), ω k ( i ) \omega_k^{(i)} ωk(i)成为样本 i i i对第 k k k个分模型的响应度。GMM中这一步其实就是在对每个样本点聚类操作。确定了 ω k ( i ) \omega_k^{(i)} ωk(i)后,问题就退化成只关于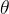 的函数。
的函数。M-step
求模型参数:固定 ω ( i ) \omega^{(i)} ω(i)后的最大化
∑ i = 1 n ∑ k = 1 K ω k ( i ) l n p ( z ( i ) = k ∣ θ ) p ( x ( i ) ∣ z ( i ) = k , θ ) ω k ( i ) = ∑ i = 1 n ∑ k = 1 K ω k ( i ) l n α k N ( x ( i ) ∣ μ k , σ k ) ω k ( i ) \sum_{i=1}^n\sum_{k=1}^K\omega_k^{(i)}ln\frac {p(z^{(i)}=k|\theta)p(x^{(i)}|z^{(i)}=k,\theta)}{\omega_k^{(i)}}=\sum_{i=1}^n\sum_{k=1}^K\omega_k^{(i)}ln\frac {\alpha_kN(x^{(i)}|\mu_k,\sigma_k)}{\omega_k^{(i)}} i=1∑nk=1∑Kωk(i)lnωk(i)p(z(i)=k∣θ)p(x(i)∣z(i)=k,θ)=i=1∑nk=1∑Kωk(i)lnωk(i)αkN(x(i)∣μk,σk)
求解模型参数,即
θ t + 1 = a r g m a x θ ∑ i = 1 n ∑ k = 1 K ω k ( i ) α k N ( x ( i ) ∣ μ k , σ k ) ω k ( i ) \theta^{t+1}=\underset\theta{arg~max}\sum_{i=1}^n\sum_{k=1}^K\omega_k^{(i)}\frac {\alpha_kN(x^{(i)}|\mu_k,\sigma_k)}{\omega_k^{(i)}} θt+1=θarg maxi=1∑nk=1∑Kωk(i)ωk(i)αkN(x(i)∣μk,σk)算法步骤
-
初始化模型的参数值。EM算法对初始值较敏感,不同的初始值可能得到不同的参数估计值。
-
E-step:依据当前模型参数,计算分模型k对观测样本数据的响应度
ω k ( i ) = α k N ( x ( i ) ∣ μ k , σ k ) ∑ k = 1 K α k N ( x ( i ) ∣ μ k , σ k ) \omega_k^{(i)}=\frac {\alpha_kN(x^{(i)}|\mu_k,\sigma_k)}{\sum_{k=1}^K\alpha_kN(x^{(i)}|\mu_k,\sigma_k)} ωk(i)=∑k=1KαkN(x(i)∣μk,σk)αkN(x(i)∣μk,σk) -
M-step:计算新一轮迭代的模型参数
-
重复步骤(2)(3),直至达到收敛。
高维高斯分布基础
一维标准正态分布
p ( x ) = 1 2 π e − ( x 2 2 ) p(x)=\frac 1{\sqrt{2\pi}}e^{-(\frac {x^2} 2)} p(x)=2π1e−(2x2)
二维标准正态分布,就是两个独立的一维标准正态分布随机变量的联合分布:
p ( x , y ) = p ( x ) p ( y ) = 1 2 π e − ( x 2 + y 2 2 ) p(x,y)=p(x)p(y)=\frac 1{2\pi}e^{-(\frac {x^2+y^2} 2)} p(x,y)=p(x)p(y)=2π1e−(2x2+y2)把两个随机变量组合成一个随机向量: v = [ x y ] T v=[x~y]^T v=[x y]T,则有
p ( v ) = 1 2 π e − 1 2 v T v p({\bf {v}})=\frac 1{2\pi}e^{-\frac 12\bf v^Tv} p(v)=2π1e−21vTv然后从标准正态分布推广到一般正态分布,办法是通过一个线性变换: v = A ( x − μ ) v=A(x−μ) v=A(x−μ)
p ( x ) = ∣ det ( A ) ∣ 2 π e [ − 1 2 ( x − μ ) T A T A ( x − μ ) ] p({\bf {x}})=\frac {|\det(A)|}{2\pi}e^{[-\frac 12\bf( x-\mu)^TA^TA(x-\mu)]} p(x)=2π∣det(A)∣e[−21(x−μ)TATA(x−μ)]
注意前面的系数多了一个 ∣ det ( A ) ∣ |\det(A)| ∣det(A)∣(A的行列式的绝对值)。可以证明这个分布的均值为μ,协方差为 ( A T A ) − 1 (A^TA)^{−1} (ATA)−1。记 Σ = ( A T A ) − 1 Σ=(A^TA)^{−1} Σ=(ATA)−1,那就有
p ( x ) = 1 2 π ∣ Σ ∣ 1 / 2 e [ − 1 2 ( x − μ ) T Σ − 1 ( x − μ ) ] p({\bf {x}})=\frac {1}{2\pi|\Sigma|^{1/2}}e^{[-\frac 12\bf( x-\mu)^T\Sigma^{-1}(x-\mu)]} p(x)=2π∣Σ∣1/21e[−21(x−μ)TΣ−1(x−μ)]
高维情形同理。 -
-
相关阅读:
【FPGA的小娱乐】在tft显示屏上画X型
ArcGIS制图:高考人数统计
Maven学习(二)
产品设计实战(上):Axure9绘制高保真原型
回归预测 | MATLAB实现基于RF随机森林的工业增加值预测(多因素、多指标)
进来“抄作业”!示例代码、操作手册,尽在华为云Codelabs!
LeetCode-2. 两数相加-Java-medium
Java笔记(工厂模式、动态代理、XML)
ubuntu 修改磁盘名称
Chatgpt人工智能对话源码系统分享 带完整搭建教程
- 原文地址:https://blog.csdn.net/weixin_45363113/article/details/126431517