-
DataHub元数据采集
DataHub支持使用DataHub基于UI创建、配置、调度和执行批处理元数据采集。通过最大限度地减少操作自定义集成管道所需的开销,使元数据更容易进入DataHub。
先决条件
要查看和管理基于UI的元数据采集,必须先将 Manage Metadata Ingestion、Manage Secrets 权限分配给帐户,这些可以通过平台策略授予。
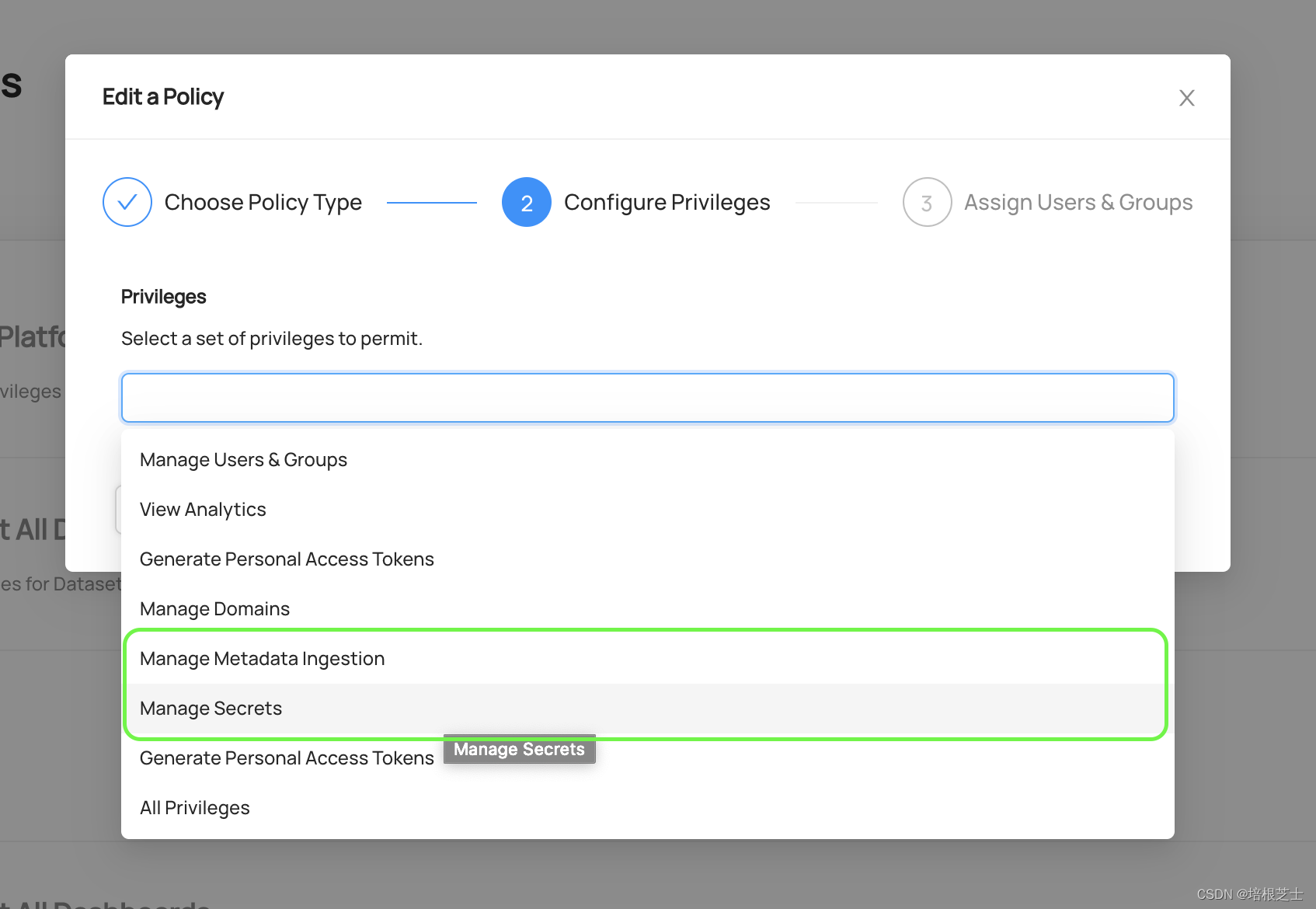
一旦拥有这些权限,就可以通过DataHub导航栏中的“Ingestion”选项卡来开始管理采集。

在此页面上,会看到采集源的列表。
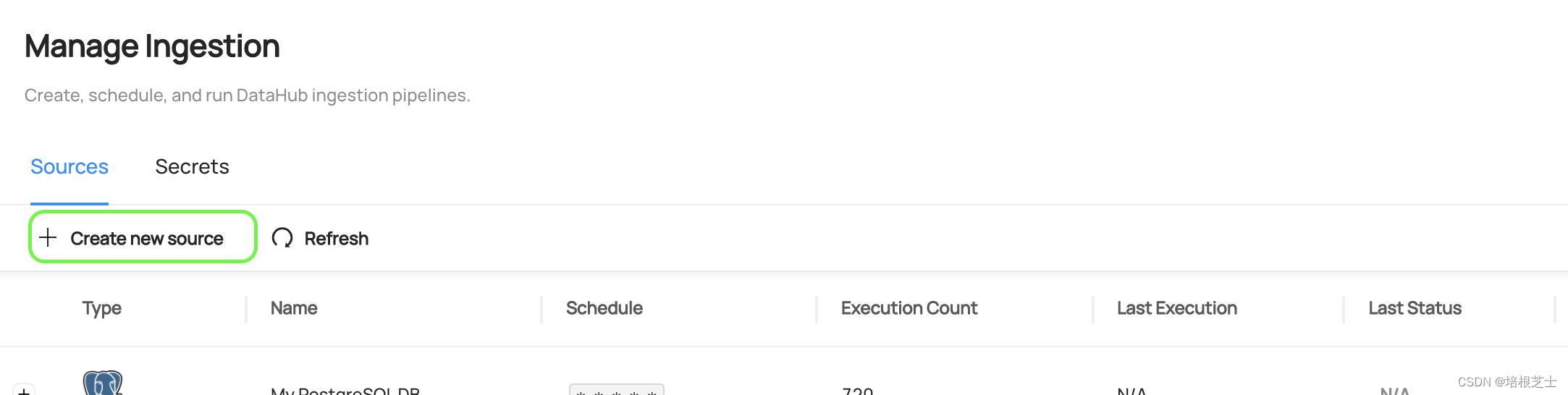
创建采集源
在采集任何元数据之前,需要创建一个新的采集源。首先点按 + Create new source。
第1步:选择平台模板
第一步,选择与要从中提取元数据的源类型相对应的配方模板。从各种原生支持的集成中进行选择,从Snowflake到Postgres再到Kafka。选择Custom以从头开始构建采集配方。

接下来,需要配置采集配方,该配方定义了如何从源系统提取和提取什么。
第2步:配置配方
接下来,将在YAML中定义采集配方。配方是DataHub用于从第三方系统提取元数据的一组配置。它通常由以下部分组成:
(1)源类型:想要从中提取元数据的系统类型(例如snowflake、mysql、postgres)。如果选择了原生模板,则该模板已为你填充。
(2)源配置:特定于源类型的一组配置。大多数来源支持以下类型的配置值:
- 坐标:要从中提取元数据的系统的位置
- 凭据:用于访问要从中提取元数据的系统的授权凭据
- 自定义:关于将提取的元数据的自定义,例如,在关系数据库中扫描哪些数据库或表
(3)接收器类型:从源类型提取的元数据的接收器类型。官方支持的DataHub接收器类型是datahub-rest和datahub-kafka。
(4)接收器配置:将元数据发送到提供的接收器类型所需的配置。例如,DataHub坐标和凭据。
从MySQL采集元数据的完整配方示例可以在下图中找到。
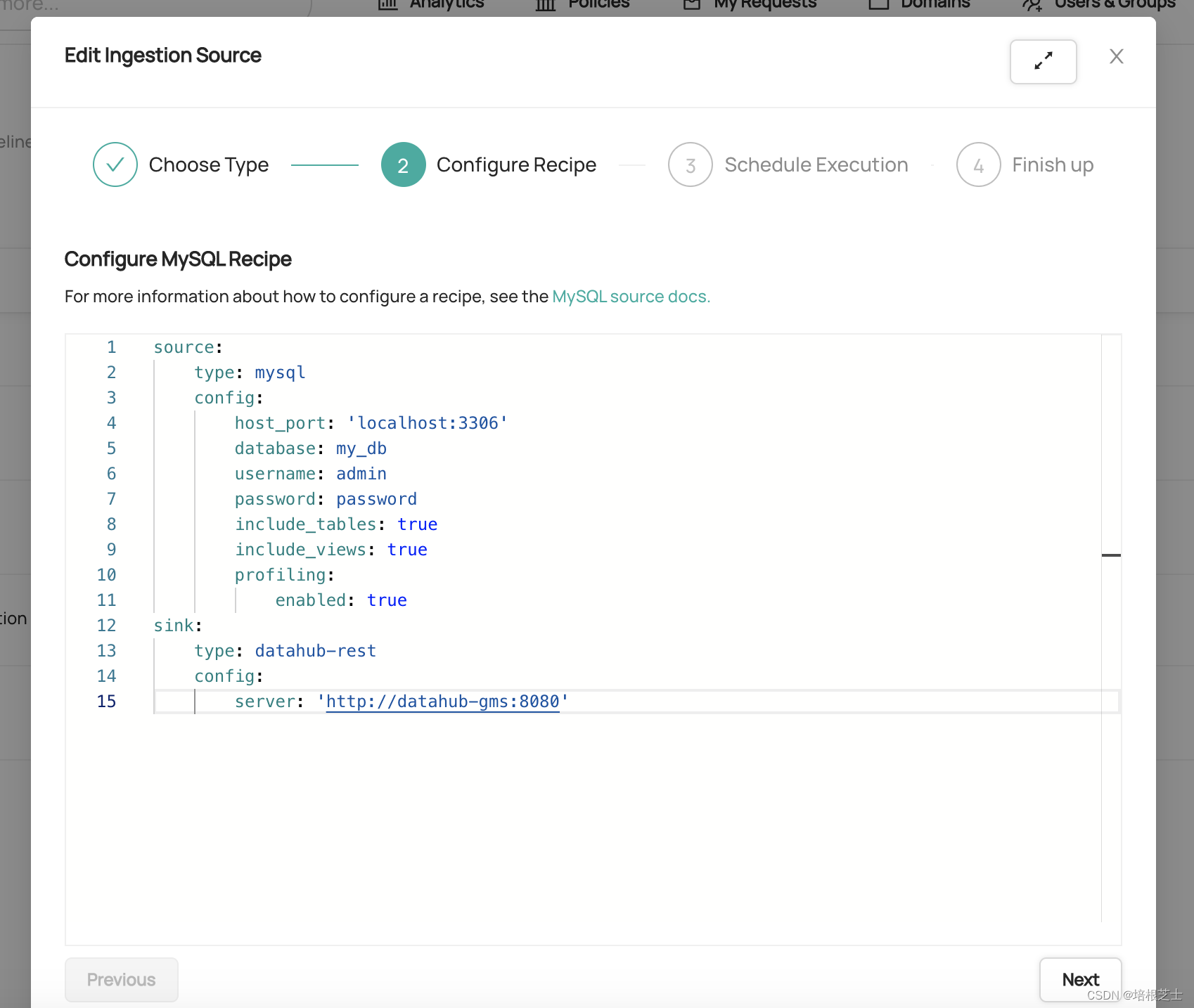
每个源类型的详细配置示例和文档可以在DataHub Docs网站上找到。
第3步:安排执行
接下来,可以选择配置执行新采集源的日程。可以根据组织的需求,按每月、每周、每天或每小时的节奏安排元数据提取。日程使用CRON格式定义。
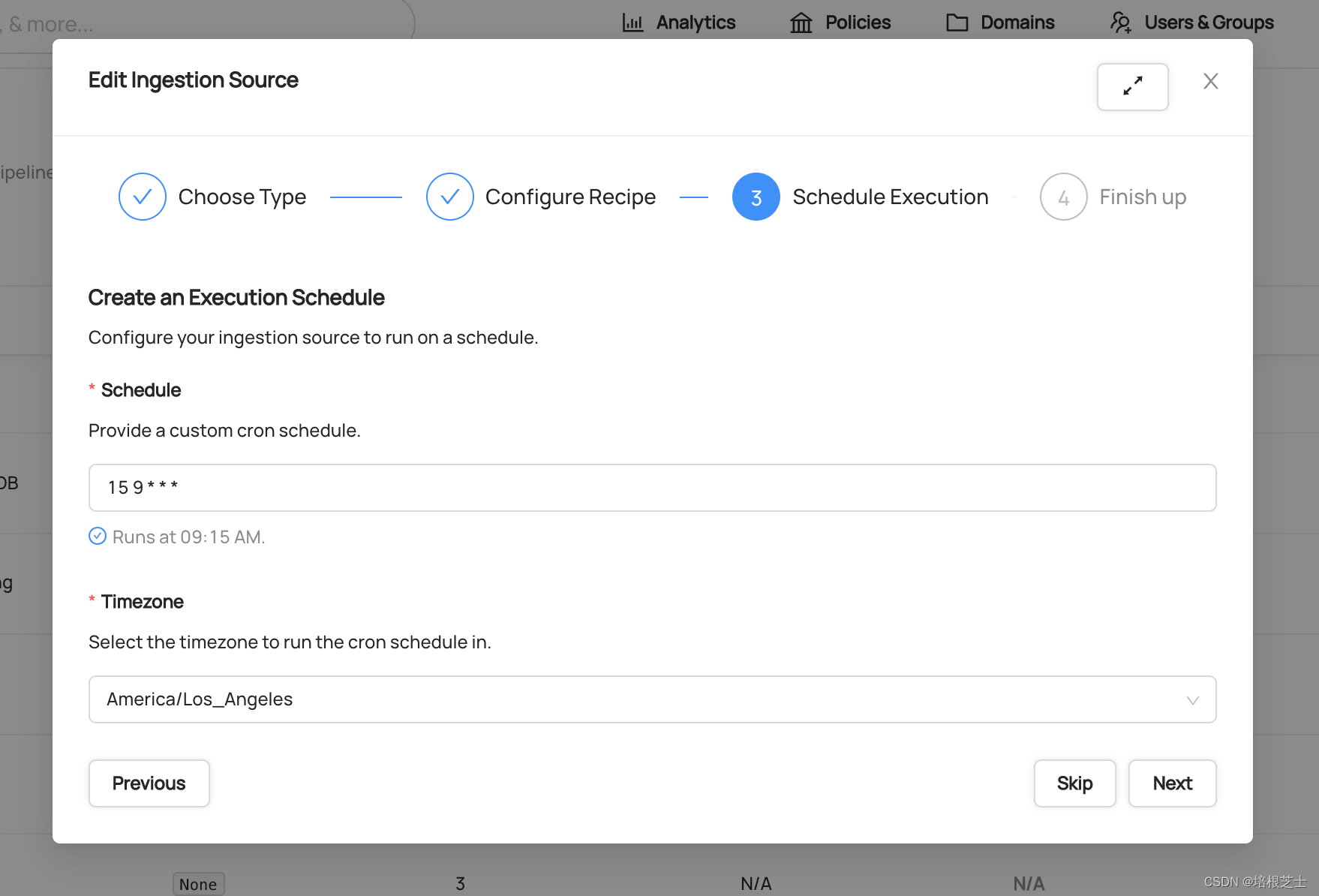
如果计划临时执行采集,可以单机“Skip”完全跳过调度步骤。
第4步:完成
最后,给你的采集源起个名字,单击“Done”以保存更改。
DataHub默认配置为使用与服务器兼容的最新版本的DataHub CLI。可以使用“Advanced”源配置覆盖默认软件包版本。
运行采集源
创建采集源后,可以通过单击“Execute”来运行。不久之后,应该会看到采集源的“Last Status”列从“
N/A”更改为“Running”。这意味着DataHub采集执行器已成功接收执行采集的请求。
如果采集成功执行,应该会看到它的状态变以绿色显示的“
Succeeded”。
-
相关阅读:
详解AVL树(二叉搜索平衡树)【C++实现】
springboot使用@Validated校验不生效
FastAPI 学习之路(二十四)子依赖项
#775 Div.1 C. Tyler and Strings 组合数学
数据库应用:kylin 部署 达梦数据库DM8
pandas基础笔记01|joyful Pandas学习
numpy和matlab的多维数组展平:ravel, flatten, reshape, (:)
C语言每日一题(10):无人生还
【MySQL中auto_increment有什么作用?】
Ubuntu18 无法加载登录界面【100%解决】
- 原文地址:https://blog.csdn.net/watson2017/article/details/126408145