-
Arxiv 2206 | Global Context Vision Transformers
GCViT:局部和全局区域自注意力


本文的目的主要在于改进自注意力计算的高昂计算成本。所以基于局部自注意力的形式进行了扩展,实现了一种更加高效的全局注意力形式,而免去了Swin那样的划窗操作(划窗操作需要进行padding和mask,以及划窗仅仅会覆盖不同局部区域的部分内容)或者其他更为复杂的例如token unfolding和rolling操作,甚至是对于key和value的额外计算。
针对Self-Attention的改进
仍然基于windows-based attention的形式,从而保证了相对于图像大小线性的放缩关系。
在类似于Swin中的local attention的基础上,作者们构建了一种新的global attention形式,来实现横跨不同local window之间的图像patch上的信息交流。

global attention的核心是对原本local attention的query的改进。其直接使用从原始图像特征上利用CNN结构(即文中的Global Query Generator)提取缩小到窗口区域对应尺寸嵌入,使其与image token窗口中的local key和local value进行计算,从而允许捕获跨区域交互的长距离信息。

因此local attention与global attention的唯一差异在于query的来源,前者来自模块输入,而后者则来自于stage初生成,内部各个module共享的global token。

整个stage的流程如下:
- 特征送如一个stage中,即
GCViTLayer - 首先根据送入的特征计算global query。这里的计算中,会将输入特征下采样到和后续计算的window-based attention的window有着相同的尺寸。
- 特征和global query送入多个交替安置的local attention(global query不起作用)和global attention模块中。
- 在attention模块中,使用pre-norm形式。attention的计算需要先对输入特征划分窗口,对各个窗口执行local attention。计算输出结果后再将形状恢复,送入后续的基于FC的MLP中。其中:
- local attention的q来自于输入特征,计算过程是正常的;
- global attention的q来自global query,在执行qk计算之前,会先对q执行repeat操作,使其形状与k和v保持一致,之后执行local attention。
- stage结尾后按需求进行下采样。下采样是借助于跨步卷积实现。
对应的代码段如下:
# https://github.com/NVlabs/GCVit/blob/caa62fc4d55cf822cf3bef5eb8b69cc11b90e885/models/gc_vit.py#L525-L589 def forward(self, x): q_global = self.q_global_gen(_to_channel_first(x)) for blk in self.blocks: x = blk(x, q_global) if self.downsample is None: return x return self.downsample(x)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
架构的其他细节

- 使用overlapping patches,基于3x3的步长为2的跨步卷积。
- 每个stage之后下采样2倍,通道数增加2倍。下采样使用下面几个操作的级联:
- Modified Fused-MBConv Block:DWConv3x3+GELU+SEBlock+Conv1x1。这个卷积模块为模型提供了归纳偏置和模拟通道间依赖的理想属性;
- Max Pooling(kernel size=3,stride=2):论文中文本里提到的是最大池化,而图3中绘制的是卷积层,代码中提供的也是卷积层;
- Layer Norm。
- Self-Attention仍使用相对位置偏置,加到放缩后的qk上。相对位置偏置对于密集预测任务很有用。

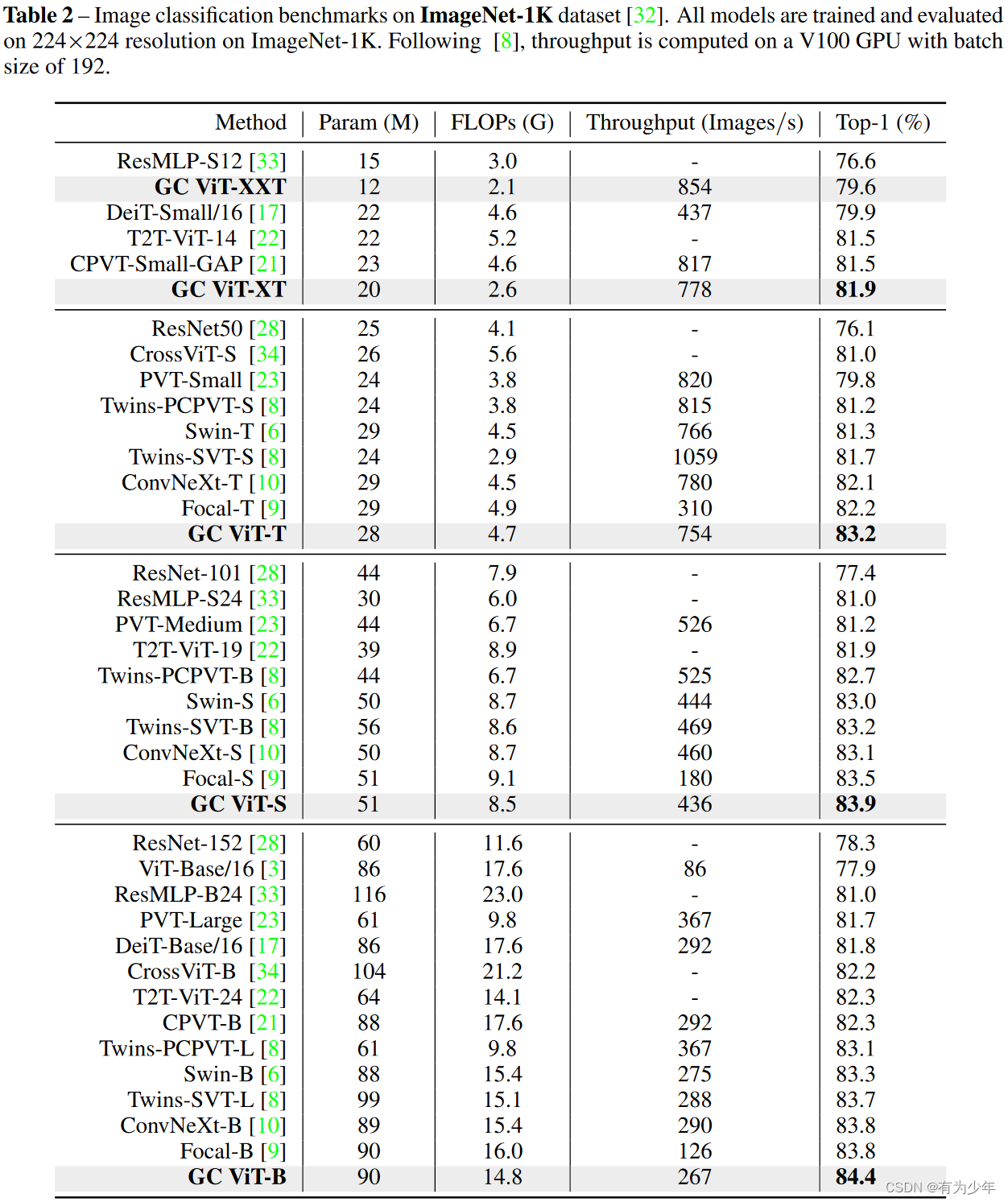
实验结果

- 特征送如一个stage中,即
-
相关阅读:
中间相遇法(分治类问题非等大分治的平衡做法)
LP光纤模式计算器
【嵌入式设计】Main Memory:SPM 便签存储器 | 缓存锁定 | 读取 DRAM 内存 | DREM 猝发(Brust)
【英语:基础进阶_原著扩展阅读】J2.手把手教你阅读如何查词
Spring WebFlux—Reactive 核心
掌握语义内核(Semantic Kernel):如何精进你的提示词工程
2311d游戏引擎适配ios
聊下自己转型测试开发的历程
基于原子变量的内存模型优化
Docker从认识到实践再到底层原理(七)|Docker存储卷
- 原文地址:https://blog.csdn.net/P_LarT/article/details/126409460