-
redis 进阶
1. 管道
就是将大量的命令合并到一个请求中去,而不是每个请求一下,减少了IO
一次请求/响应服务器能实现处理新的请求即使旧的请求还未被响应。这样就可以将多个命令发送到服务器,而不用等待回复,最后在一个步骤中读取该答复。
2. pubsub 发布订阅
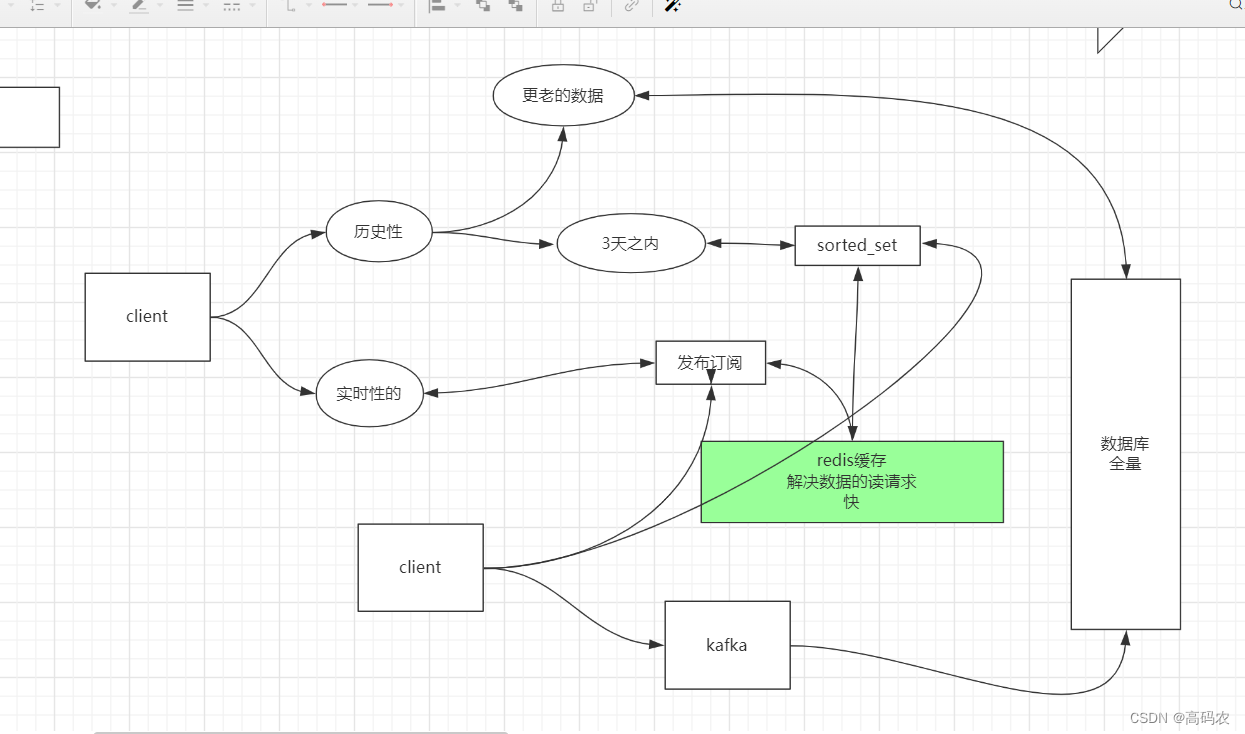
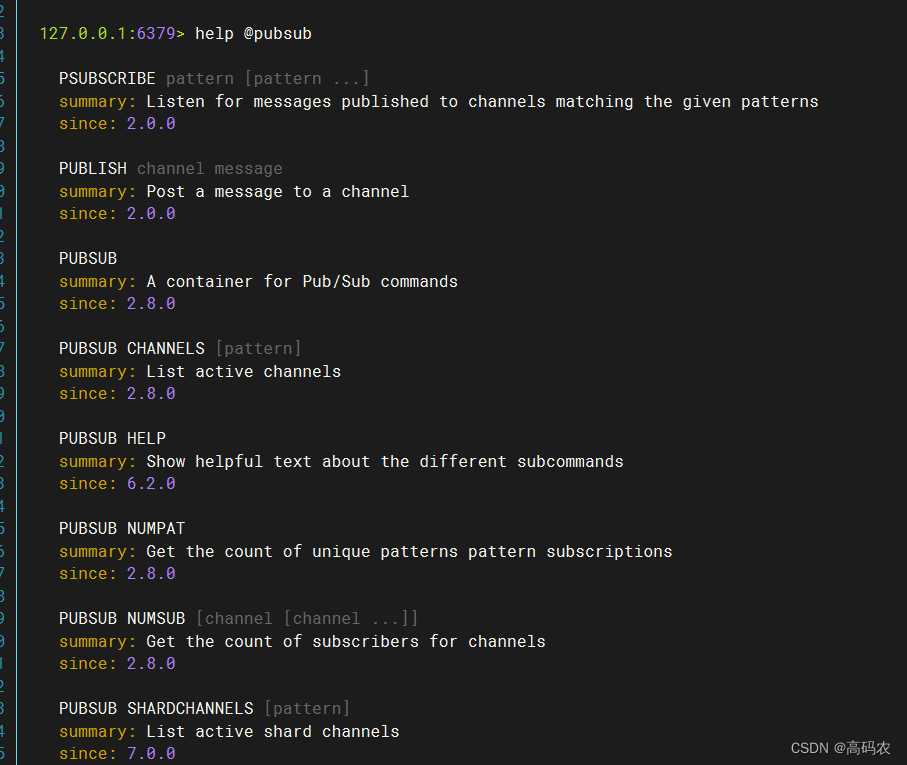
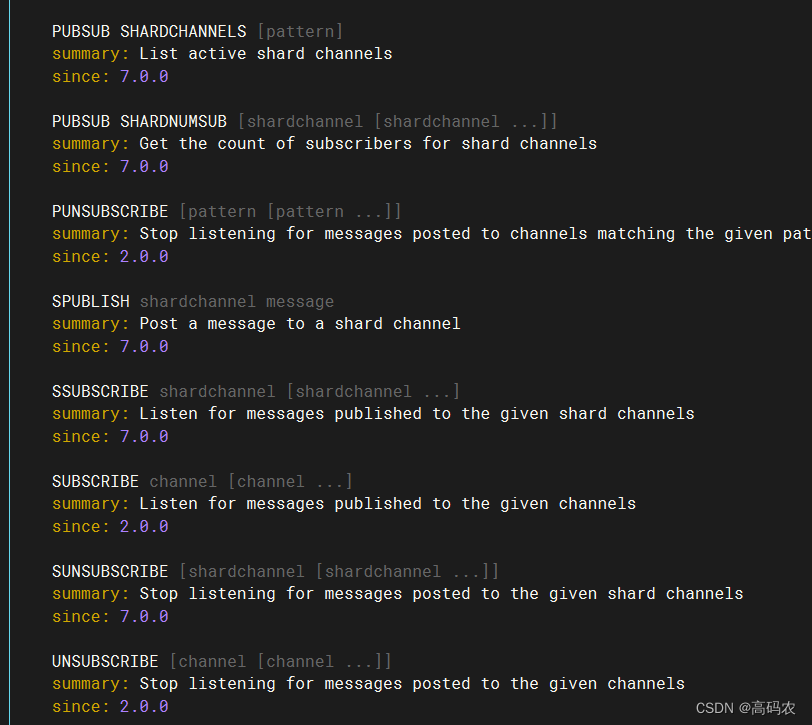
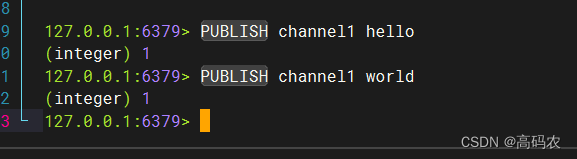
简单案例
先订阅后推送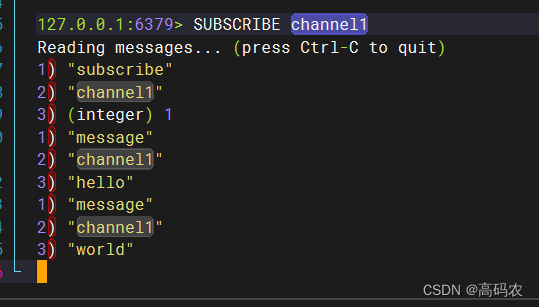
3. 事务
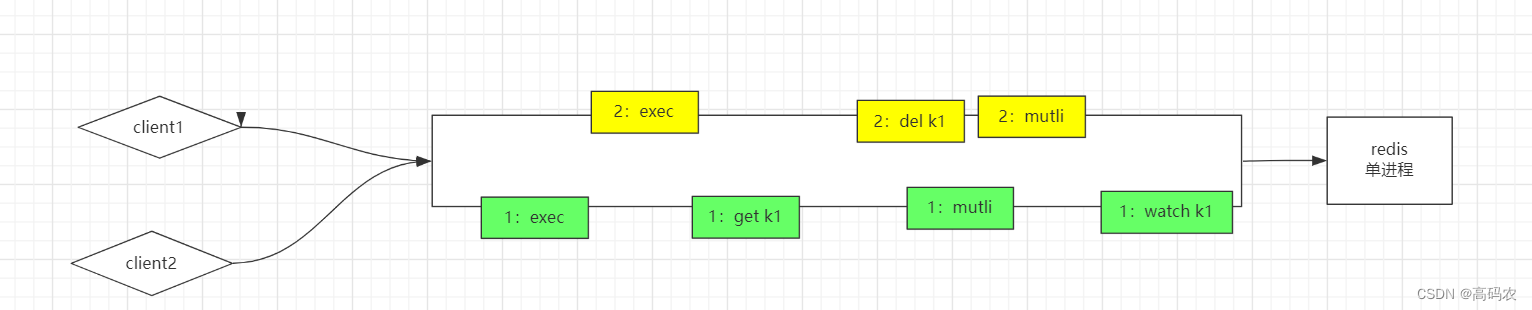
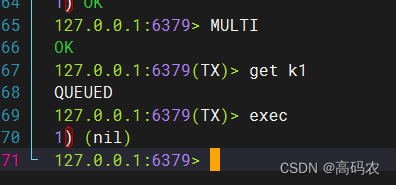
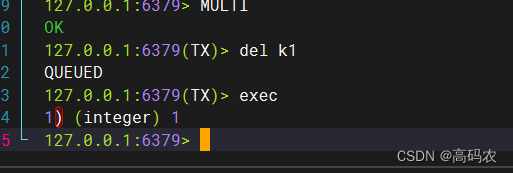
两个客户端开启事务,谁先执行事务,主要看谁先执行exec
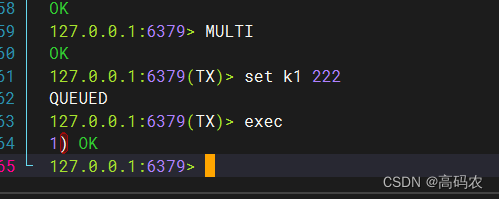
在事务中的命令,不会呗立马执行,会被放在队列中,直道执行exec才会正在的执行事务中的命令
案例:先开启了第一张图的事务,在开启了第二张图的事务,但是我先执行了第二张图 exec命令, 直接把k1删掉了,第一张图执行事务的时候就找不到这个key
3.1 watch 的用法
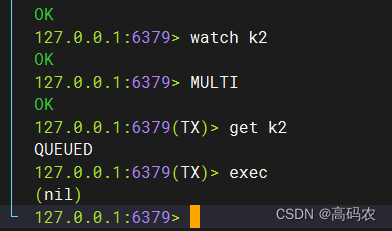
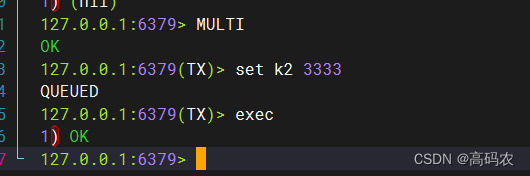
watch 主要是用于监听key,如果在监听过程中,监听的key被改变了,就不会执行该事务了
案例:
如图:监听了k2,在监听过程中,第二张图的事务先进行了执行。然后第一张图的事务操作就不会在执行
4. redis 缓存穿透
缓存穿透是指当用户在查询一条数据的时候,而此时数据库和缓存却没有关于这条数据的任何记录,而这条数据在缓存中没找到就会向数据库请求获取数据。用户拿不到数据时,就会一直发请求,查询数据库,这样会对数据库的访问造成很大的压力。
解决方法:
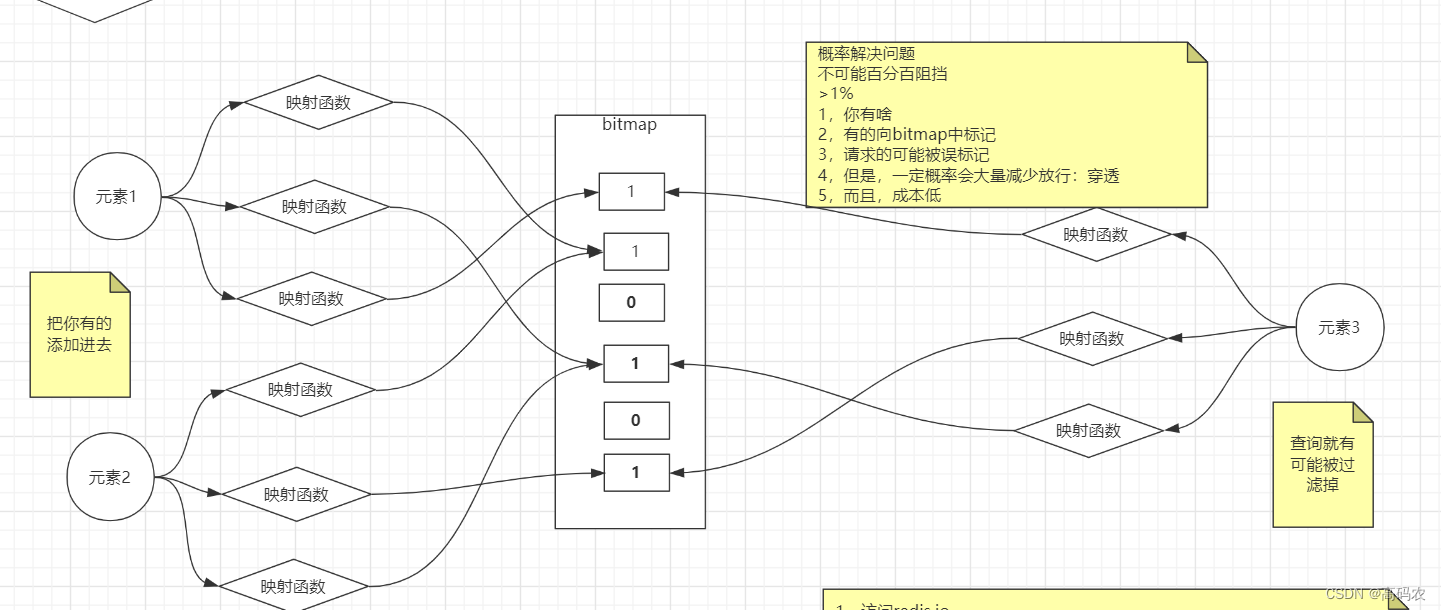
4.1 布隆过滤器
原理如图:
安装过程
4.1.1 在github上下载对应版本
地址:布隆过滤器
4.1.2 上传.zip文件到服务器并解压
yum install unzip unzip *.zip- 1
- 2
4.1.3 编译布隆过滤器
make //复制配置文件到自己想要的目录 cp redisbloom.so /etc/redis/- 1
- 2
- 3
4.1.4 带布隆过滤器模块启动
redis-server --loadmodule /etc/redis/redisboom.so- 1
4.1.5 安装遇到的问题
编译的时候遇到如下图的问题
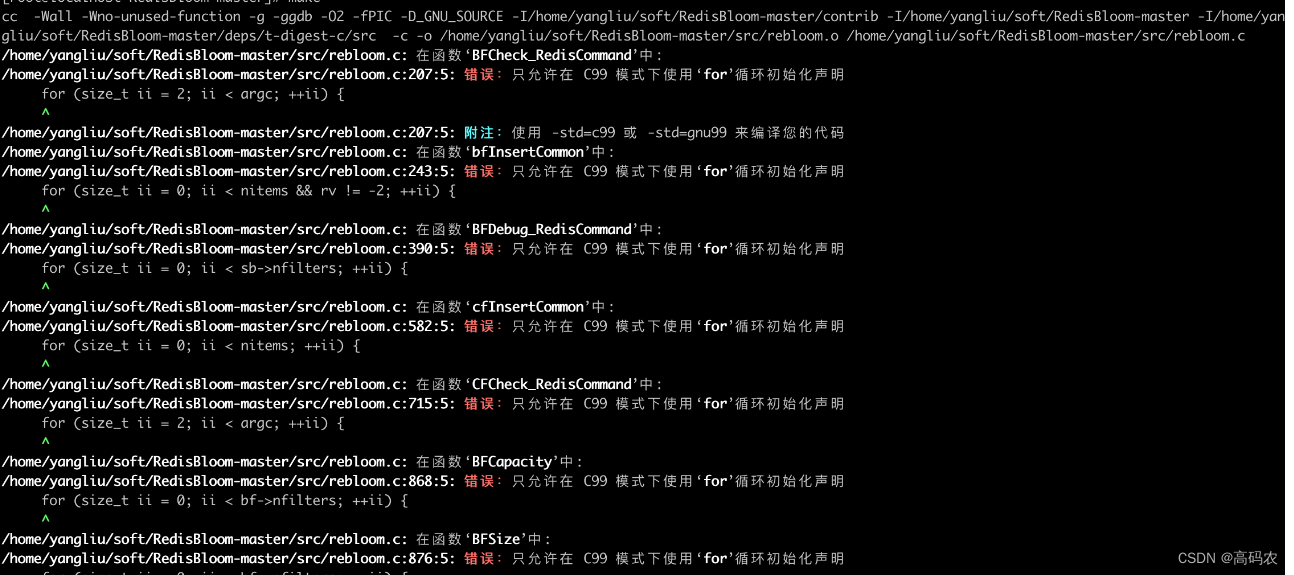
网上找了很多相关的解决办法,最好的解决办法就是换个版本安装本文安装了 2.2.17版本 make编译的时候就不会报错了
5. redis 作为缓存
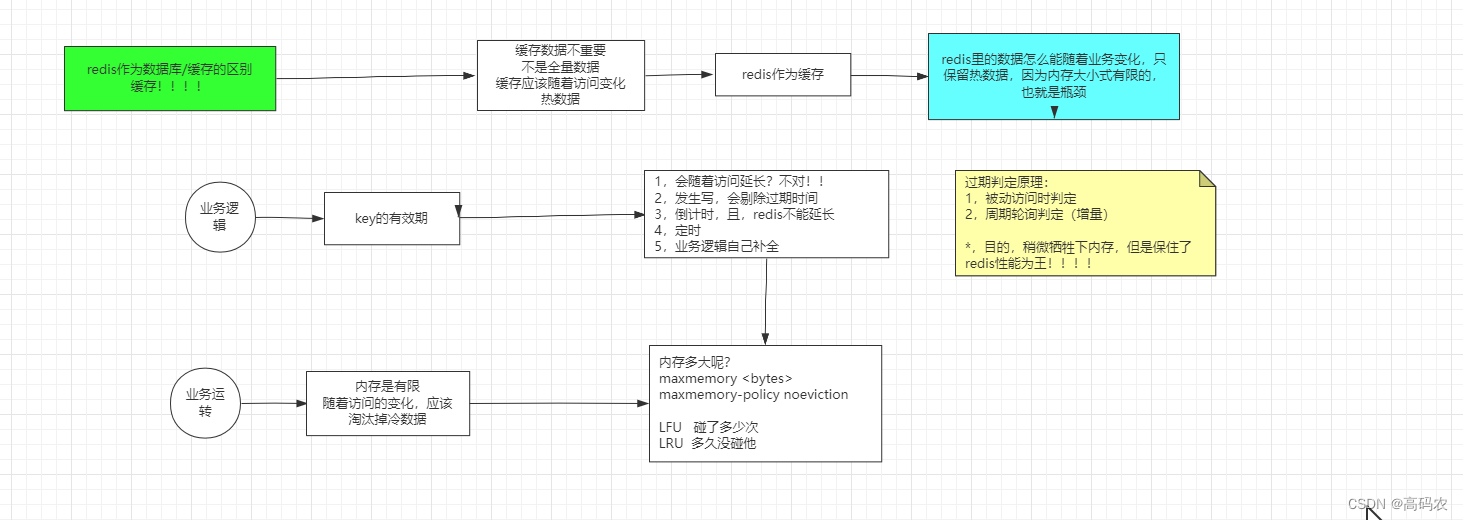
5.1 key的有效期
- 发生读请求,redis的有效期不会随着访问延长
- 发生写请求,redis的有效期会剔除过期时间
5.2 内存淘汰冷数据机制
在redis.conf 中有两个熟悉
- maxmemory //表示最大的内存
- maxmemory-policy noeviction //表示当达到最大的内存的时候,淘汰冷数据的策略
5.2.1 策略分类
noeviction表示的是达到最大内存,就报错,来保证数据不会丢失,一般是用redis 作为数据库采用这个策略
allkeys-lru 表示的是从所有key中回收一部分key
volatile-lru 从快要过期的key中回收一部分key
allkeys-random 随机从所有key中回收一部分key
volatile-random 随机从快过期的key中回收一部分key
volatile-ttl: 直接回收快过期的key- noeviction:返回错误当内存限制达到并且客户端尝试执行会让更多内存被使用的命令(大部分的写入指令,但DEL和几个例外)
- allkeys-lru: 尝试回收最少使用的键(LRU),使得新添加的数据有空间存放。
- volatile-lru: 尝试回收最少使用的键(LRU),但仅限于在过期集合的键,使得新添加的数据有空间存放。
- allkeys-random: 回收随机的键使得新添加的数据有空间存放。
- volatile-random: 回收随机的键使得新添加的数据有空间存放,但仅限于在过期集合的键。
- volatile-ttl: 回收在过期集合的键,并且优先回收存活时间(TTL)较短的键,使得新添加的数据有空间存放。
5.3 过期判断原理
- 被动访问判定
就是访问该key的同时判定key是否过期 - 周期轮询判定
就是保证抽样的样本key中 只有少于25%的key过期
定时随机测试设置keys的过期时间。所有这些过期的keys将会从密钥空间删除。
具体就是Redis每秒10次做的事情:
1.测试随机的20个keys进行相关过期检测。
2. 删除所有已经过期的keys。
3. 如果有多于25%的keys过期,重复步奏1.6 redis 持久化
参考博客:redis持久化
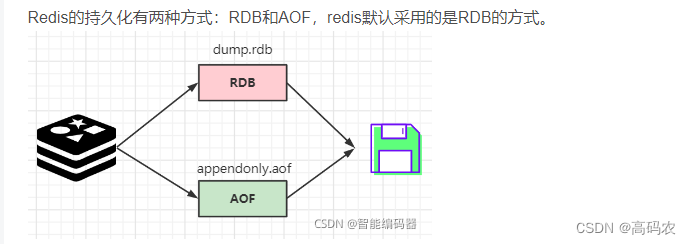
6.1 RDB 持久化
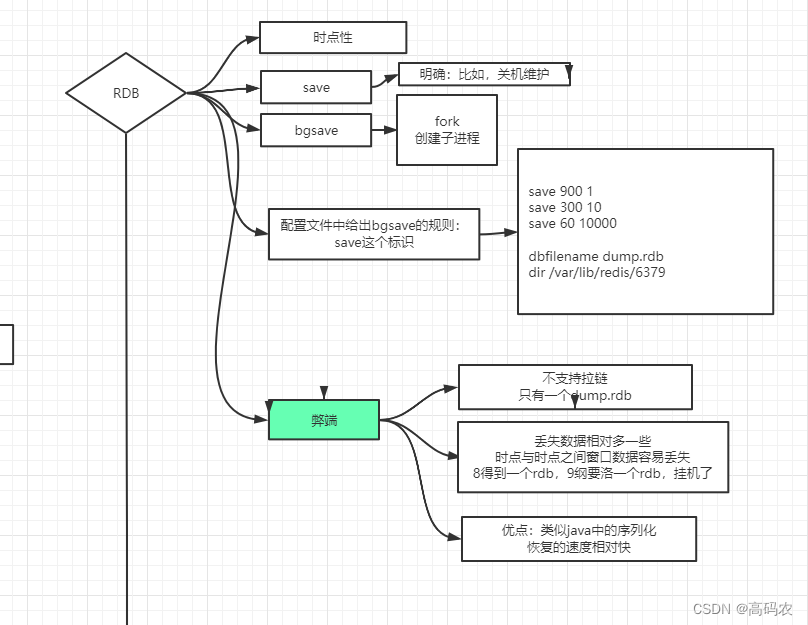
RDB 具有时点性,默认redis采用RDB模式,将内存数据库保存在dump.rdb文件中去
6.1.1 RDB 配置持久化策略
- save N M //表示的是redis 在N秒内至少有M个改动就会触发rdb持久化操作
save 900 1 //900 秒内至少有一个改动 save 300 10 // 300秒内至少有10个改动 save 60 10000 //60秒内至少有10000个改动- 1
- 2
- 3
- 在配置文件中配置bgsave
配置自动生成rdb文件后台使用的是bgsave方式。
6.1.2 bgsave写时复制的(COW)机制
Redis借助了linux系统的写时复制(Copy-On-Write)技术,在生成快照的同时,仍然可以接收命令处理数据。简单来说,bgsave线程是由主线程fork生成的子线程,可以共享主线程所有的内存数据。bgsave线程运行后,开始读取主线程的内存数据,也就是redis的内存数据,将内存数据写入到dump.rdb文件中。此时,如果主线程处理的命令都是读操作,则bgsave线程不受影响。如果主线程处理了写操作,则会对该命令操作的数据复制一份,生成副本,bgsave线程会把这个副本写入到dump.rdb文件中,而在这个过程中,主线程仍可执行命令。
就是利用linux的写时复制,利用fork创建子进程bgsave,bgsave复制一份主进程,指向到主进程的数据,当主进程发生读请求时,对bgsave不会产生影响,当主进程产生增删改请求时,bgsave 会把这些命令存入到dump.rdb文件中
比较项 save bgsave IO类型 同步 异步 是否阻塞命令 是 否(fork 是会短暂阻塞) 复杂度 O(n) O(n) 优点 不会消耗额外内存 不阻塞操作 缺点 阻塞操作 会消耗额外内存 6.1.3 RDB 的优缺点
缺点:
- RDB每次持久化需要将所有内存数据写入文件,然后替换原有文件,当内存数据量很大的时候,频繁的生成快照会很耗性能。
- 如果将生成快照的策略设置的时间间隔很大,会导致redis宕机的时候丢失过的的数据。
优点:
因为 dump.rdb是二进制文件,所以可以很快的将数据恢复到 内存到中去
6.2 AOF 持久化
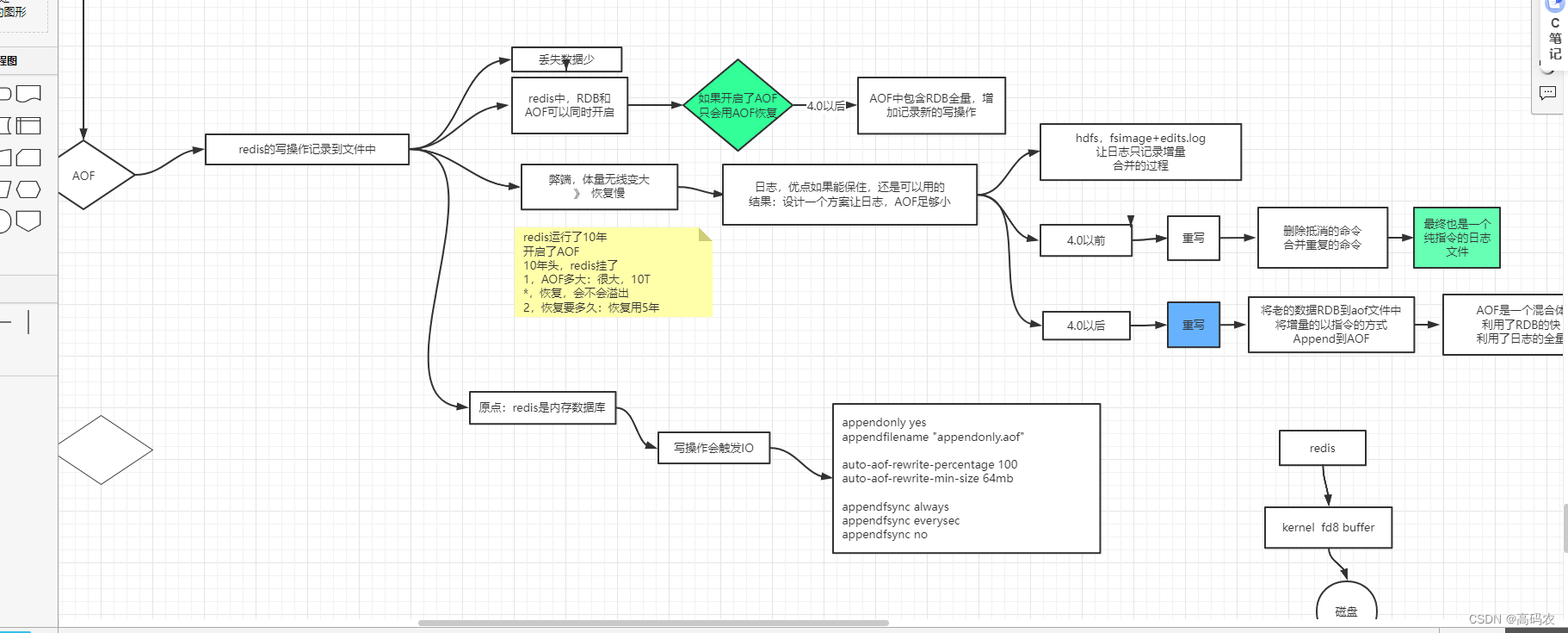
将redis 的操作的指令以追加的形式存到appendonly.aof
6.2.1 开启aof持久化
appendonly yes- 1
6.2.2 AOF可以配置三种刷盘策略:
appendfsync always:每次执行写命令都会刷盘,非常慢,也非常安全。 appendfsync everysec:每秒刷盘一次,兼顾性能和安全。 appendfsync no:将刷盘操作交给系统,很快,不安全。- 1
- 2
- 3
推荐使用everysec,该策略下,最多会丢1秒的数据。
6.2.3 AOF重写:
应为appendonly.aof文件中存储的是执行命令,所以会产生很多没用的命令,因此,redis会定期根据最新的内存数据生成新的aof文件。
如下两个配置可以控制aop文件重写的频率:# auto‐aof‐rewrite‐min‐size 64mb: -- aof文件至少达到了64m才会触发重写 # auto‐aof‐rewrite‐percentage 100: -- 距离上次重写增长了100%才会再次触发重写- 1
- 2
AOF也可以手动触发重写:bgrewriteof
6.3 Redis 4.0之后混合持久化
重启 Redis 时,我们很少使用 RDB来恢复内存状态,因为会丢失大量数据。我们通常使用 AOF 日志重
放,但是重放 AOF 日志性能相对 RDB来说要慢很多,这样在 Redis 实例很大的情况下,启动需要花费很
长的时间。 Redis 4.0 为了解决这个问题,带来了一个新的持久化选项——混合持久化。开启混合持久化
aof‐use‐rdb‐preamble yes- 1
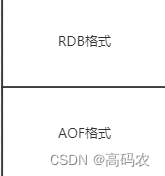
如果开启了混合持久化,AOF在重写时,不再是单纯将内存数据转换为RESP命令写入AOF文件,而是将重写这一刻之前的内存做RDB快照处理,并且将RDB快照内容和增量的AOF修改内存数据的命令存在一起,都写入新的AOF文件,新的文件一开始不叫appendonly.aof,等到重写完新的AOF文件才会进行改名,覆盖原有的AOF文件,完成新旧两个AOF文件的替换。
于是在 Redis 重启的时候,可以先加载 RDB 的内容,然后再重放增量 AOF 日志就可以完全替代之前的AOF 全量文件重放,因此重启效率大幅得到提升。
混合持久化AOF文件结构如下:
-
相关阅读:
Docker概述及CentOS安装Docker
万宾科技智能井盖,实现对井盖的监测
谷粒学苑_第六天
JAVA实现QQ登录、注册、修改密码等功能(美化版)
【头歌实验】一、Python初体验——Hello World
[ITIL]-ITIL4的服务管理关键概念
HTML5期末考核大作业:基于Html+Css+javascript的网页制作(化妆品公司网站制作)
内涵语录
【瑞吉外卖】day10:缓存验证码、菜品、套餐信息以及推送到gitee
debug模式启动不了项目,报:Method breakpoints may dramatically slow down debugging
- 原文地址:https://blog.csdn.net/yaoxie1534/article/details/126399834