-
sklearn.model_selection.learning_curve介绍(评估多大的样本量用于训练才能达到最佳效果)
前言
学习曲线函数:可以用于检验数据是否过拟合,并且可以评估多大的样本量用于训练才能达到最佳效果(了解数据如何影响模型的性能)。还可以用于测试模型的超参数。一、learning_curve介绍
learning_curve函数介绍: 用于确定不同训练集大小的交叉验证训练和测试分数,交叉验证生成器在训练和测试数据中对整个数据集进行k次拆分。将使用具有不同大小的训练集的子集来训练估计器,并将计算每个训练子集大小的分数和测试集。之后,将对每个训练子集大小的所有k次运行的分数求平均。
sklearn.model_selection.learning_curve( estimator, X, y, *, groups=None, train_sizes=array([0.1, 0.33, 0.55, 0.78, 1.]), cv=None, scoring=None, exploit_incremental_learning=False, n_jobs=None, pre_dispatch='all', verbose=0, shuffle=False, random_state=None, error_score=nan, return_times=False, fit_params=None)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
注意:
1、当训练集的准确率比其他独立数据集上的测试结果的准确率要高时,一般都是过拟合。
2、当训练集和验证集的准确率都很低,很可能是欠拟合。一些常用参数:
1、estimator:传入的模型对象。
2、X:传入的特征
3、y:传入的标签
4、train_sizes:数组,代表训练示例的相对或绝对数量,将用于生成学习曲线。如果dtype为float,则视为训练集最大尺寸的一部分(由所选的验证方法确定),即,它必须在(0,1]之内,否则将被解释为绝对大小注意,为了进行分类,样本的数量通常必须足够大,以包含每个类中的至少一个样本(默认值:np.linspace(0.1,1.0,5))
5、cv
cv的可能输入是:
1)None,要使用默认的三折交叉验证(v0.22版本中将改为五折)
2)整数,用于指定(分层)KFold中的折叠数,比如说10
3)CV splitter:分割器,例如我们这里用到的ShuffleSplit
6、n_jobs:运行的cpu个数。 -1表示使用所有处理器。
7、random_state:随机数种子。返回值:
train_sizes_abs:返回生成的训练样本数量列表。
train_scores:数组,形状(n_ticks,n_cv_folds),训练集得分列表。
test_scores:数组,形状(n_ticks,n_cv_folds)测试集得分列表。二、实战
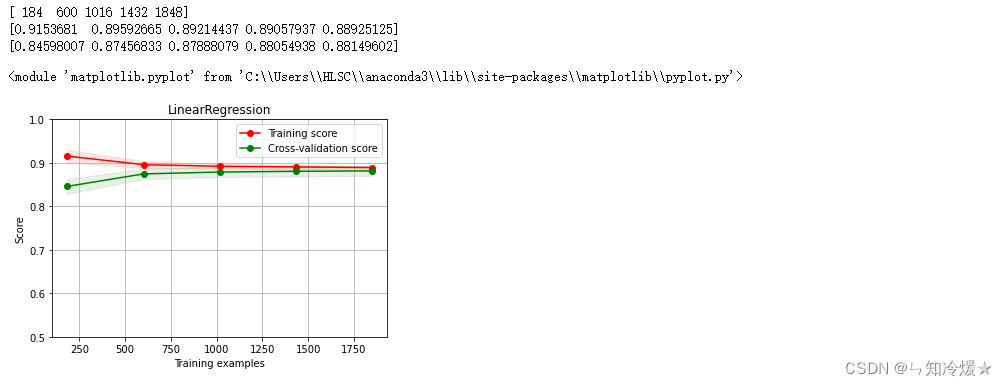
import numpy as np import pandas as pd import matplotlib.pyplot as plt import seaborn as sns from scipy import stats def plot_learning_curve(estimator, title, X, y, ylim=None, cv=None, n_jobs=1, train_sizes=np.linspace(.1, 1.0, 5)): ''' 定义画出学习曲线的方法,核心是调用learning_curve方法。 ''' plt.figure() plt.title(title) if ylim is not None: plt.ylim(*ylim) plt.xlabel("Training examples") plt.ylabel("Score") # 这里交叉验证调用的必须是ShuffleSplit。 # n_jobs: 要并行运行的作业数,这里默认为1,如果-1则表示使用所有处理器。 train_sizes, train_scores, test_scores = learning_curve( estimator, X, y, cv=cv, n_jobs=n_jobs, train_sizes=train_sizes) # 返回值: # train_sizes: 训练示例的等分比例,代表着横坐标有几个点。 # train_scores: 训练集得分: 二维数组,shape:(5, 100) # test_scores:测试集得分 # print(train_scores) # print(test_scores) # 最后求得五个平均值 train_scores_mean = np.mean(train_scores, axis=1) train_scores_std = np.std(train_scores, axis=1) test_scores_mean = np.mean(test_scores, axis=1) test_scores_std = np.std(test_scores, axis=1) print(train_sizes) print(train_scores_mean) print(test_scores_mean) plt.grid() plt.fill_between(train_sizes, train_scores_mean - train_scores_std, train_scores_mean + train_scores_std, alpha=0.1, color="r") plt.fill_between(train_sizes, test_scores_mean - test_scores_std, test_scores_mean + test_scores_std, alpha=0.1, color="g") plt.plot(train_sizes, train_scores_mean, 'o-', color="r", label="Training score") plt.plot(train_sizes, test_scores_mean, 'o-', color="g", label="Cross-validation score") plt.legend(loc="best") return plt # X是2310行,37列的数据 X = train_data.values y = train_target.values # 图一 title = r"LinearRegression" # ShuffleSplit:将样例打散,随机取出20%的数据作为测试集,这样取出100次, cv = ShuffleSplit(n_splits=100, test_size=0.2, random_state=0) estimator = LinearRegression() #建模 plot_learning_curve(estimator, title, X, y, ylim=(0.5, 1), cv=cv, n_jobs=1)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
输出:
参考文章:
Sklearn — 检视过拟合Learning curve.
官方文档.
sklearn中的学习曲线learning_curve函数.
总结
好耶好耶。
-
相关阅读:
不能显式拦截ajax请求的302响应?
含文档+PPT+源码等]精品基于Uniapp实现的鲜花商城App[包运行成功]
集合 set
ucharts最详细教程(含踩坑记录)
嵌入式Linux高级案例-移植LVGL到Linux开发板
SV--对象拷贝、参数化的类
java电子配件公司仓库管理系统计算机毕业设计MyBatis+系统+LW文档+源码+调试部署
第三次上机作业 大连理工大学
最强开源大模型面世:阿里发布Qwen2
JVM在线分析-解决问题的工具二(jcmd, jdb, jhsdb)
- 原文地址:https://blog.csdn.net/weixin_42475060/article/details/126403913