-
Nginx-动静分离与 URLRwrite
目录
一、动静分离原理
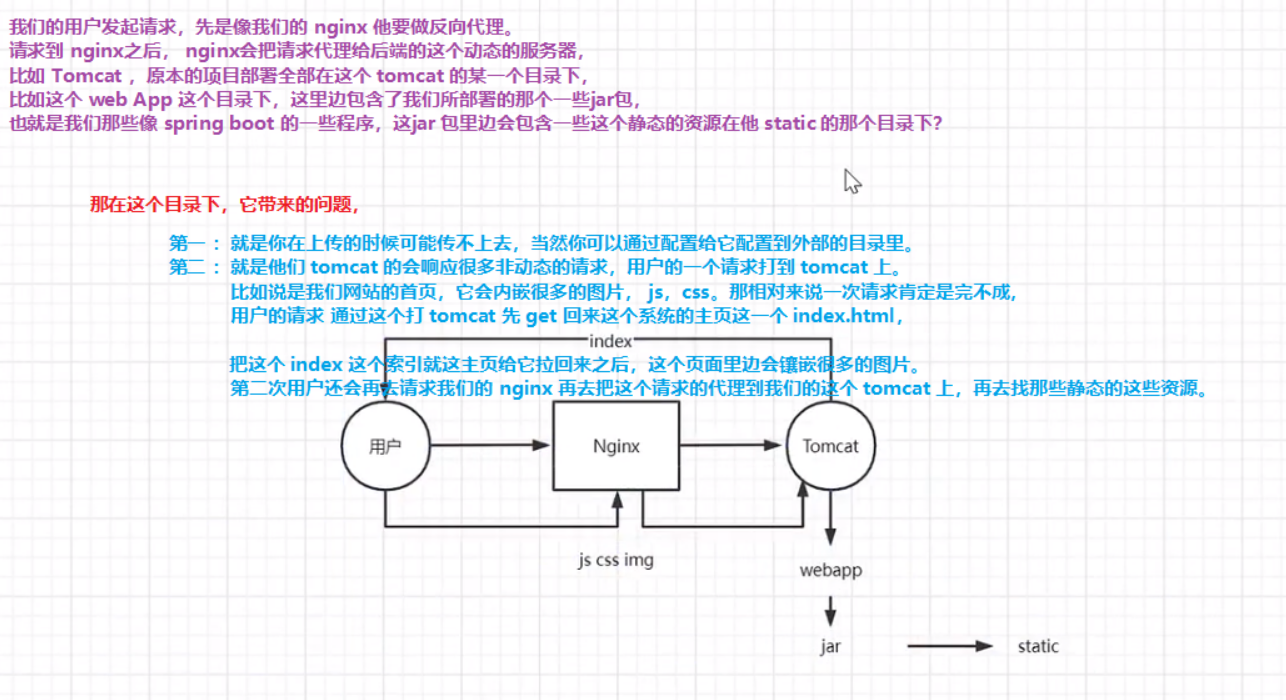
为了提高网站的响应速度,减轻程序服务器(Tomcat,Jboss等)的负载,对于静态资源,如图片、js、css等文件,可以在反向代理服务器中进行缓存,这样浏览器在请求一个静态资源时,代理服务器就可以直接处理,而不用将请求转发给后端服务器。对于用户请求的动态文件,如servlet、jsp,则转发给Tomcat,Jboss服务器处理,这就是动静分离。即动态文件与静态文件的分离。
动静分离可通过location对请求url进行匹配,将网站静态资源(HTML,JavaScript,CSS,img等文件)与后台应用分开部署,提高用户访问静态代码的速度,降低对后台应用访问。通常将静态资源放到nginx中,动态资源转发到tomcat服务器中。
二、动静分离使用场景
nginx 的动静分离是常用的一种功能,这个功能一般比较适合中小型的网站,大型网站一般来说就不适用。
它为什么只适合中小型网站呢?中小型网站的并发量并不是特别高,需要分离出来的静态资源不是特别多。那么需要把这些静态资源,挪到前置的 nginx 服务器里,如果大型系统的话,那文件就太多了。
比如说淘宝,你用户上传的文件就非常非常的多,买家秀卖家秀,商户上传这些商品详情页里边的一些介绍,这些图片,这些都属于是静态资源,这就非常多,它就不适合动静分离这种简单的技术架构。动静分离比较适合初创的企业,网站的H5的 内嵌到 App 里展示,或者是一些网站的展示,这些都是没有问题的。包括这个 ERP 系统,传统的这种项目也可以使用动静分离,动静分离能够给我们起到这个系统加速的作用。
三、动静分离配置
1.把源网站项目如 Tomcat 服务器上的静态资源文件如css、js、html等删除,然后上传到 /usr/local/nginx/html 目录下:
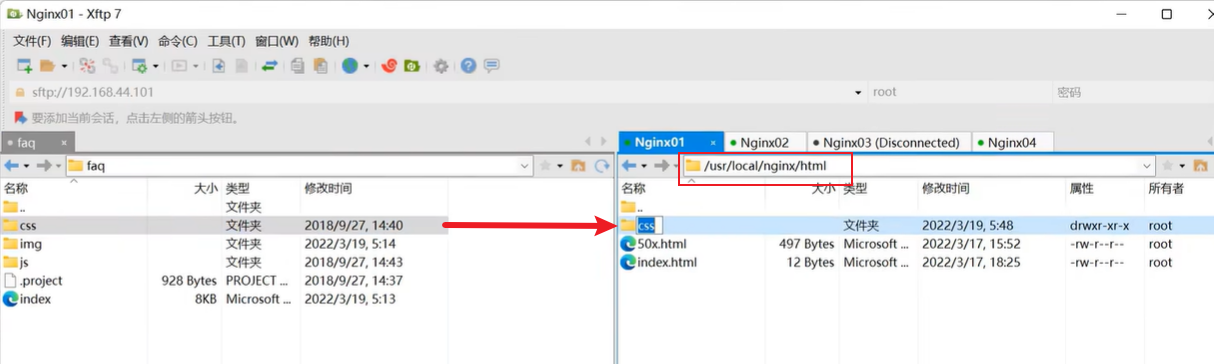
2.修改配置文件:

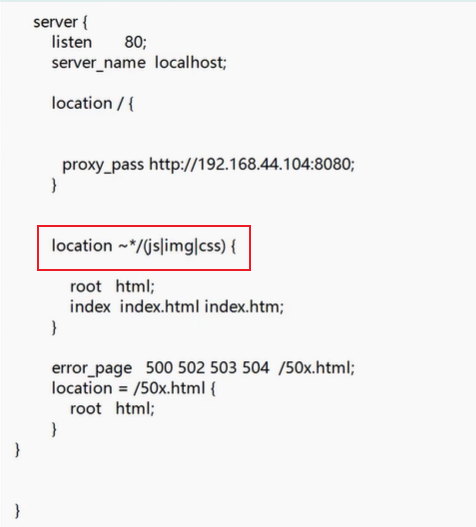
3.如需存放多个静态目录,只需添加多个 location 模块:


四、使用正则配置动静分离
1.常见的Nginx正则表达式:
- ^ :匹配输入字符串的起始位置
- $ :匹配输入字符串的结束位置
- * :匹配前面的字符零次或多次。如“ol*”能匹配“o”及“ol”、“oll”
- + :匹配前面的字符一次或多次。如“ol+”能匹配“ol”及“oll”、“olll”,但不能匹配“o”
- ? :匹配前面的字符零次或一次,例如“do(es)?”能匹配“do”或者“does”,”?”等效于”{0,1}”
- . :匹配除“\n”之外的任何单个字符,若要匹配包括“\n”在内的任意字符,请使用诸如“[.\n]”之类的模式
- \ :将后面接着的字符标记为一个特殊字符或一个原义字符或一个向后引用。如“\n”匹配一个换行符,而“\$”则匹配“$”
- \d :匹配纯数字
- {n} :重复 n 次
- {n,} :重复 n 次或更多次
- {n,m} :重复 n 到 m 次
- [] :定义匹配的字符范围
- [c] :匹配单个字符 c
- [a-z] :匹配 a-z 小写字母的任意一个
- [a-zA-Z0-9] :匹配所有大小写字母或数字
- () :表达式的开始和结束位置
- | :或运算符 //例(js|img|css)
2.location 正则:
- 1.# location大致可以分为三类
- 精准匹配:location = /{}
- 一般匹配:location /{}
- 正则匹配:location ~/{}
- 2.# location常用的匹配规则:
- = :进行普通字符精确匹配,也就是完全匹配。
- ^~ :表示前缀字符串匹配(不是正则匹配,需要使用字符串),如果匹配成功,则不再匹配其它 location。
- ~ :区分大小写的匹配(需要使用正则表达式)。
- ~* :不区分大小写的匹配(需要使用正则表达式)。
- !~ :区分大小写的匹配取非(需要使用正则表达式)。
- !~* :不区分大小写的匹配取非(需要使用正则表达式)。
- 3.# 优先级
- 首先精确匹配 =
- 其次前缀匹配 ^~
- 其次是按文件中顺序的正则匹配 ~或~*
- 然后匹配不带任何修饰的前缀匹配
- 最后是交给 / 通用匹配
注意:
- 精确匹配:
=, 后面的表达式中写的是纯字符串 - 字符串匹配:
^~和无符号匹配, 后面的表达式中写的是纯字符串 - 正则匹配:
~和~*和!~和!~*, 后面的表达式中写的是正则表达式
3.location 使用说明:
- (1)location = / {}
- =为精确匹配 / ,主机名后面不能带任何字符串,比如访问 / 和 /data,则 / 匹配,/data 不匹配
- 再比如 location = /abc,则只匹配/abc ,/abc/或 /abcd不匹配。若 location /abc,则即匹配/abc 、/abcd/ 同时也匹配 /abc/。
- (2)location / {}
- 因为所有的地址都以 / 开头,所以这条规则将匹配到所有请求 比如访问 / 和 /data, 则 / 匹配, /data 也匹配,
- 但若后面是正则表达式会和最长字符串优先匹配(最长匹配)
- (3)location /documents/ {}
- 匹配任何以 /documents/ 开头的地址,匹配符合以后,还要继续往下搜索其它 location
- 只有其它 location后面的正则表达式没有匹配到时,才会采用这一条
- (4)location /documents/abc {}
- 匹配任何以 /documents/abc 开头的地址,匹配符合以后,还要继续往下搜索其它 location
- 只有其它 location后面的正则表达式没有匹配到时,才会采用这一条
- (5)location ^~ /images/ {}
- 匹配任何以 /images/ 开头的地址,匹配符合以后,停止往下搜索正则,采用这一条
- (6)location ~* \.(gif|jpg|jpeg)$ {}
- 匹配所有以 gif、jpg或jpeg 结尾的请求
- 然而,所有请求 /images/ 下的图片会被 location ^~ /images/ 处理,因为 ^~ 的优先级更高,所以到达不了这一条正则
- (7)location /images/abc {}
- 最长字符匹配到 /images/abc,优先级最低,继续往下搜索其它 location,会发现 ^~ 和 ~ 存在
- (8)location ~ /images/abc {}
- 匹配以/images/abc 开头的,优先级次之,只有去掉 location ^~ /images/ 才会采用这一条
- (9)location /images/abc/1.html {}
- 匹配/images/abc/1.html 文件,如果和正则 ~ /images/abc/1.html 相比,正则优先级更高
- 优先级总结:
- (location =) > (location 完整路径) > (location ^~ 路径) > (location ~,~* 正则顺序) > (location 部分起始路径) > (location /)
案例:
五、URLRewrite
1.URLRewrite 使用场景
URLRewrite 也是比较实用的一个功能,它能隐藏我们真实的后端服务器的这个物理的地址。
2.rewrite语法格式及参数语法
rewrite 是实现URL重写的关键指令,根据regex (正则表达式)部分内容,重定向到replacement,结尾是flag标记。
- 1.# 语法:
- rewrite <regex> <replacement> [flag];
- 关键字 正则 替代内容 flag标记
- 关键字:其中关键字不能改变
- 正则:perl兼容正则表达式语句进行规则匹配
- 替代内容:将正则匹配的内容替换成 replacement
- flag标记:rewrite 支持的 flag 标记
- rewrite参数的标签段位置:server,location,if
- 2.# 语法模板:
- rewrite ^ 正则 $ 书写要转变的地址(真实的地址) 转发的形式 (如break ,rewrite,last,redirect ,percent )
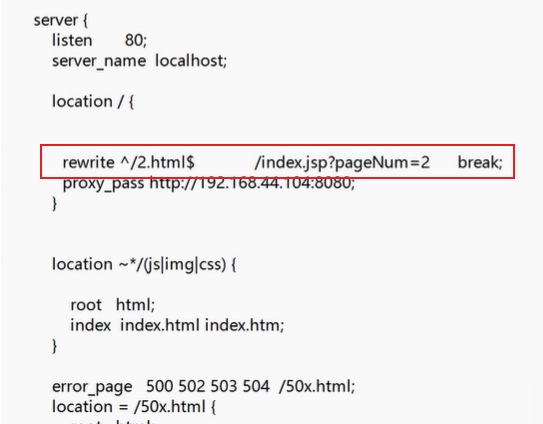
- 3.# 例子:
- rewrite ^ /2.html $ /index.jsppageNum=2 break;
- URLRewrite 的关键字 rewrite ,后面跟正则表达式,这正则表达式以 ^ 开头,然后以这个$ 结尾, 里边写正则, 后边写上这个我们想要转变的这个地址,就是原来的这个真实地址,后面可加转发的形式。
- 4.# flag标记说明:
- last #本条规则匹配完成后,继续向下匹配新的location URI规则
- break #本条规则匹配完成即终止,不再匹配后面的任何规则
- redirect #返回302临时重定向,浏览器地址会显示跳转后的URL地址
- permanent #返回301永久重定向,浏览器地址栏会显示跳转后的URL地址
- 5.# redirect 和 perement 的区别
- redirect 302 会返回的临时重定向
- perement 301 返回 永久冲定向
- 这个 301 和 302 的区别,在我们实际给到用户去适用的时候其实是没有任何区别的,它都会跳转,然后这个 URL 都会发生变化。临时重定向和永久重定向,其实是给网络爬虫给它来看的。
3.URLRewrite的优缺点
- 优点:掩藏真实的url以及url中可能暴露的参数,以及隐藏web使用的编程语言,提高安全性便于搜索引擎收录
- 缺点:降低效率,影响性能。如果项目是内网使用,比如公司内部软件,则没有必要配置。
4.案例
在浏览器输入 192.168.44.104:8080/2.html 会匹配并转发到项目文件中存在的地址 192.168.44.104:8080/index.jsp?pageNum=2 这个页面。
- rewrite ^ /2.html$ /index.jsp?pageNum=2 break;
- //也可以用正则表达式的形式:
- rewrite ^/([0-9]+).html$ /index.jsp?pageNum=$1 break; //$1表示第一个匹配的字符串
- 在浏览器可以输入任意数字访问匹配到的页面
-
相关阅读:
深度学习-矩阵计算
opencv-python cv2读写视频,灰度图像视频保存
曲线任意里程中边桩坐标正反算4800 disicixiugai
LLM基础
阿里巴巴、阿里云Java面试题、笔试题(含答案)
Nature Microbiology|益生菌的菌株特异性影响驱动早产儿肠道微生物组的发展
Java面试题:解释死锁的概念,给出避免死锁的常见策略。你能给我一个具体的例子吗?
【RabbitMQ 实战】09 客户端连接集群生产和消费消息
十、空闲任务及其钩子函数
简单工厂、工厂方法和抽象工厂模式(创建型设计模式)的 C++ 代码示例模板
- 原文地址:https://blog.csdn.net/weixin_46560589/article/details/126404197
