-
HBase入门至进阶以及开发等知识梳理
HBase入门至进阶以及开发等知识梳理
HBase简介
hadoop简介
Hadoop是一个由Apache基金会所开发的分布式系统基础架构。用户可以在不了解分布式底层细节的情况下,开发分布式程序。充分利用集群的威力进行高速运算和存储。Hadoop实现了一个分布式文件系统( Distributed File System),其中一个组件是HDFS(Hadoop Distributed File System)。HDFS有高容错性的特点,并且设计用来部署在低廉的(low-cost)硬件上;而且它提供高吞吐量(high throughput)来访问应用程序的数据,适合那些有着超大数据集(large data set)的应用程序。HDFS放宽了(relax)POSIX的要求,可以以流的形式访问(streaming access)文件系统中的数据。Hadoop的框架最核心的设计就是:HDFS和MapReduce。HDFS为海量的数据提供了存储,而MapReduce则为海量的数据提供了计算 。
从 1970 年开始,大多数的公司数据存储和维护使用的是关系型数据库
大数据技术出现后,很多拥有海量数据的公司开始选择像Hadoop的方式来存储海量数据hadoop局限性
- Hadoop主要是实现批量数据的处理,并且通过顺序方式访问数据
- 要查找数据必须搜索整个数据集, 如果要进行随机读取数据,效率较低
HBase与NoSQL
-
NoSQL是一个通用术语,泛指一个数据库并不是使用SQL作为主要语言的非关系型数据库
-
HBase是BigTable的开源java版本。是建立在HDFS之上,提供高可靠性、高性能、列存储、可伸缩、实时读写NoSQL的数据库系统
-
HBase仅能通过主键(row key)和主键的range来检索数据,仅支持单行事务
-
主要用来存储结构化和半结构化的松散数据
-
Hbase查询数据功能很简单,不支持join等复杂操作,不支持复杂的事务(行级的事务),从技术上来说,HBase更像是一个「数据存储」而不是「数据库」,因为HBase缺少RDBMS中的许多特性,例如带类型的列、二级索引以及高级查询语言等
-
Hbase中支持的数据类型:byte[]
-
与Hadoop一样,Hbase目标主要依靠横向扩展,通过不断增加廉价的商用服务器,来增加存储和处理能力,例如,把集群从10个节点扩展到20个节点,存储能力和处理能力都会加倍
-
HBase中的表一般有这样的特点
-
大:一个表可以有上十亿行,上百万列
-
面向列:面向列(族)的存储和权限控制,列(族)独立检索
-
稀疏:对于为空(null)的列,并不占用存储空间,因此,表可以设计的非常稀疏
-
HBase应用场景
-
对象存储
- 不少的头条类、新闻类的的新闻、网页、图片存储在HBase之中,一些病毒公司的病毒库也是存储在HBase之中
-
时序数据
- HBase之上有OpenTSDB模块,可以满足时序类场景的需求
-
推荐画像
- 用户画像,是一个比较大的稀疏矩阵,蚂蚁金服的风控就是构建在HBase之上
-
时空数据
- 主要是轨迹、气象网格之类,滴滴打车的轨迹数据主要存在HBase之中,另外在技术所有大一点的数据量的车联网企业,数据都是存在HBase之中
-
CubeDB OLAP
- Kylin一个cube分析工具,底层的数据就是存储在HBase之中,不少客户自己基于离线计算构建cube存储在hbase之中,满足在线报表查询的需求
-
消息/订单
- 在电信领域、银行领域,不少的订单查询底层的存储,另外不少通信、消息同步的应用构建在HBase之上
-
Feeds流
- 典型的应用就是xx朋友圈类似的应用,用户可以随时发布新内容,评论、点赞。
-
NewSQL
- 之上有Phoenix的插件,可以满足二级索引、SQL的需求,对接传统数据需要SQL非事务的需求
-
其他
- 存储爬虫数据
- 海量数据备份
- 短网址
- …
发展历程
年份 重大事件 2006年11月 Google发布BigTable论文. 2007年10月 发布第一个可用的HBase版本,基于Hadoop 0.15.0 2008年1月 HBase称为Hadoop的一个子项目 2010年5月 HBase称为Apache的顶级项目 HBase特点
- 强一致性读/写
- HBASE不是“最终一致的”数据存储
- 它非常适合于诸如高速计数器聚合等任务
- 自动分块
- HBase表通过Region分布在集群上,随着数据的增长,区域被自动拆分和重新分布
- 自动RegionServer故障转移
- Hadoop/HDFS集成
- HBase支持HDFS开箱即用作为其分布式文件系统
- MapReduce
- HBase通过MapReduce支持大规模并行处理,将HBase用作源和接收器
- Java Client API
- HBase支持易于使用的 Java API 进行编程访问
- Thrift/REST API
- 块缓存和布隆过滤器
- HBase支持块Cache和Bloom过滤器进行大容量查询优化
- 运行管理
- HBase为业务洞察和JMX度量提供内置网页。
RDBMS与HBase的对比
关系型数据库
关系型数据库-结构
- 数据库已表的形式存在
- 支持FAT、NTFS、EXT、文件系统
- 使用主键(pk)
- 通过外部中间件可以支持分库分表,但底层还是单机引擎
- 使用行、列、单元格
关系型数据库-功能
- 支持向上扩展(购买更好的硬件配置)
- 使用SQL查询
- 面向行,即每一行都是一个连续单元
- 数据总量依赖于服务器配置
- 具有ACID支持
- 适合结构化数据
- 传统关系型数据库一般都是中心化的
- 支持事务
- 支持join
HBase
HBase-结构
- 以表形式存在
- 支持HDFS文件系统
- 使用行键(row key)
- 原生支持分布式存储、计算引擎
- 使用行、列、列簇和单元格
HBase-功能
- 支持向外扩展
- 使用API和MapReduce、Spark、Flink来访问HBase表数据
- 面向列簇,即每一个列簇都是一个连续的单元
- 数据总量不依赖具体某台机器,而取决于机器数量
- HBase不支持ACID(Atomicity、Consistency、Isolation、Durability)
- 适合结构化数据和非结构化数据
- 一般都是分布式
- l HBase不支持事务,支持的是单行数据的事务操作
- 不支持join
HDFS与HBase
HDFS
- HDFS是一个非常适合存储大型文件的分布式文件系统
- HDFS它不是一个通用的文件系统,也无法在文件中快速查询某个数据
HBase
- HBase构建在HDFS之上,并为大型表提供快速记录查找(和更新)
- HBase内部将大量数据放在HDFS中名为「StoreFiles」的索引中,以便进行高速查找
- Hbase比较适合做快速查询等需求,而不适合做大规模的OLAP应用
Hive与HBase
Hive和Hbase是两种基于Hadoop的不同技术
Hive是一种类SQL的引擎,并且运行MapReduce任务
Hbase是一种在Hadoop之上的NoSQL 的Key/value数据库
这两种工具是可以同时使用的。就像用Google来搜索,用FaceBook进行社交一样,Hive可以用来进行统计查询,而HBase可以用来进行实时查询,数据也可以从Hive写到HBase,或者从HBase写回HiveHive
- 数据仓库分析工具
- Hive的本质其实就相当于将HDFS中已经存储的文件在Mysql中做了一个双射关系,以方便使用HQL去管理查询
- 用于数据分析、清洗
- Hive适用于离线的数据分析和清洗,延迟较高
- 基于HDFS、MapReduce
- Hive存储的数据依旧在DataNode上,编写的HQL语句终将是转换为MapReduce代码执行
HBase
- NoSQL数据库
- 是一种面向列存储的非关系型数据库
- 用于存储结构化和非结构化的数据
- 适用于单表非关系型数据的存储,不适合做关联查询,类似join等操作
- 基于HDFS
- 数据持久化存储的体现形式是Hfile,存放于DataNode中,被ResionServer以region的形式进行管理
- 延迟较低,接入在线业务使用
- 面对大量的企业数据,HBase可以直线单表大量数据的存储,同时提供了高效的数据访问速度
HBase集群搭建部署
【注意】
HBase的集群安装部署写在另外一篇文章中:https://blog.csdn.net/wt334502157/article/details/116837187
由于篇幅原因,将部署内容单独写在部署文章中。
HBase数据模型
结构简介
在HBASE中,数据存储在具有行和列的表中。这是看起来关系数据库(RDBMS)一样,但将HBASE表看成是多个维度的Map结构更容易理解
ROWKEY C1列蔟 C2列蔟 rowkey 列1 | 列2 | 列3 列4 | 列5 | 列6 rowkey 0001 C1(Map) 列1 => 值1 列2 => 值2 列3 => 值3 C2(Map) 列4 => 值4 列5 => 值5 列6 => 值6 HBase常用术语
表(Table)
- HBase中数据都是以表形式来组织的
- HBase中的表由多个行组成
列(row)
- HBase中的行由一个rowkey(行键)和一个或多个列组成,列的值与rowkey、列相关联
- 行在存储时按行键按字典顺序排序
- 行键的设计非常重要,尽量让相关的行存储在一起
- 例如:存储网站域。如行键是域,则应该将域名反转后存储(org.apache.www、org.apache.mail、org.apache.jira)。这样,所有Apache域都在表中存储在一起,而不是根据子域的第一个字母展开
列(Column)
- HBASE中的列由列蔟(Column Family)和列限定符(Column Qualifier)组成
- 例如 : [ 列蔟名:列限定符名]。C1:USER_ID、C1:NAME
列簇(Column Family)
- 出于性能原因,列簇将一组列及其值组织在一起
- 每个列簇都有一组存储属性
- 是否应该缓存在内容中
- 数据如何被压缩或行键如何编码等
- 表中的每一行都有相同的列蔟,但在列蔟中不存储任何内容
- 所有的列蔟的数据全部都存储在一块(文件系统HDFS)
- HBase官方建议所有的列蔟保持一样的列,并且将同一类的列放在一个列蔟中
列标识符(Column Qualifier)
- 列蔟中包含一个个的列限定符,这样可以为存储的数据提供索引
- 列蔟在创建表的时候是固定的,但列限定符是不作限制的
- 不同的行可能会存在不同的列标识符
单元格(Cell)
- 单元格是行、列系列和列限定符的组合
- 包含一个值和一个时间戳(表示该值的版本)
- 单元格中的内容是以二进制存储的
ROW COLUMN+CELL 1250995 column=C1:ADDRESS, timestamp=1588591604729, value=\xC9\xBD\xCE\xF7\xCA 1250995 column=C1:LATEST_DATE, timestamp=1588591604729, value=2019-03-28 1250995 column=C1:NAME, timestamp=1588591604729, value=\xB7\xBD\xBA\xC6\xD0\xF9 1250995 column=C1:NUM_CURRENT, timestamp=1588591604729, value=398.5 1250995 column=C1:NUM_PREVIOUS, timestamp=1588591604729, value=379.5 1250995 column=C1:NUM_USEAGE, timestamp=1588591604729, value=19 1250995 column=C1:PAY_DATE, timestamp=1588591604729, value=2019-02-26 1250995 column=C1:RECORD_DATE, timestamp=1588591604729, value=2019-02-11 1250995 column=C1:SEX, timestamp=1588591604729, value=\xC5\xAE 1250995 column=C1:TOTAL_MONEY, timestamp=1588591604729, value=114 概念模型
Row Key Time Stamp ColumnFamily contents ColumnFamily anchor ColumnFamily people “com.cnn.www” t9 anchor:cnnsi.com = “CNN” “com.cnn.www” t8 anchor:my.look.ca = “CNN.com” “com.cnn.www” t6 contents:html = “…” “com.cnn.www” t5 contents:html = “…” “com.cnn.www” t3 contents:html = “…” “com.example.www” t5 contents:html = “…” people:author = “John Doe” - 上述表格有两行、三个列蔟(contens、ancho、people)
- “com.cnn.www”这一行anchor列蔟两个列(anchor:cssnsi.com、anchor:my.look.ca)、contents列蔟有个1个列(html)
- “com.cnn.www”在HBase中有 t3、t5、t6、t8、t9 5个版本的数据
- HBase中如果某一行的列被更新的,那么最新的数据会排在最前面,换句话说同一个rowkey的数据是按照倒序排序的
常用shell操作
HBase操作流程
从简单的需求实现来慢慢引出一系列对hbase的操作实施
场景需求:有以下订单数据,我们想要将这样的一些数据保存到HBase中
订单ID 订单状态 支付金额 支付方式ID 用户ID 操作时间 商品分类 001 已付款 200.5 1 001 2020-5-2 18:08:53 手机; 接下来,我们将使用HBase shell来进行以下操作:
-
创建表
-
添加数据
-
更新数据
-
删除数据
-
查询数据
创建表
在HBase中,所有的数据也都是保存在表中的。要将订单数据保存到HBase中,首先需要将表创建出来
启动HBase-shell
启动HBase shell:hbase shell
wangting@ops01:/home/wangting >hbase shell SLF4J: Class path contains multiple SLF4J bindings. SLF4J: Found binding in [jar:file:/opt/module/hbase/lib/phoenix-5.0.0-HBase-2.0-client.jar!/org/slf4j/impl/StaticLoggerBinder.class] SLF4J: Found binding in [jar:file:/opt/module/hbase/lib/slf4j-log4j12-1.7.25.jar!/org/slf4j/impl/StaticLoggerBinder.class] SLF4J: Found binding in [jar:file:/opt/module/hadoop-3.1.3/share/hadoop/common/lib/slf4j-log4j12-1.7.30.jar!/org/slf4j/impl/StaticLoggerBinder.class] SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanation. HBase Shell Use "help" to get list of supported commands. Use "exit" to quit this interactive shell. For Reference, please visit: http://hbase.apache.org/2.0/book.html#shell Version 2.0.5, r76458dd074df17520ad451ded198cd832138e929, Mon Mar 18 00:41:49 UTC 2019 Took 0.0043 seconds hbase(main):001:0>- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
创建表
语法:create ‘表名’,‘列蔟名’…
创建订单表,表名为ORDER_INFO,该表有一个列蔟为C1
hbase(main):036:0> create 'ORDER_INFO','C1' Created table ORDER_INFO Took 0.7355 seconds => Hbase::Table - ORDER_INFO hbase(main):037:0>- 1
- 2
- 3
- 4
- 5
【注意】:
- create要小写
- 一个表可以包含若干个列蔟
- 命令解析:调用hbase提供的ruby脚本的create方法,传递两个字符串参数
查看表
hbase(main):045:0> list TABLE ORDER_INFO SYSTEM.CATALOG SYSTEM.FUNCTION SYSTEM.LOG SYSTEM.MUTEX SYSTEM.SEQUENCE SYSTEM.STATS 7 row(s) Took 0.0098 seconds => ["ORDER_INFO", "SYSTEM.CATALOG", "SYSTEM.FUNCTION", "SYSTEM.LOG", "SYSTEM.MUTEX", "SYSTEM.SEQUENCE", "SYSTEM.STATS"] hbase(main):046:0>- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
删除表
要删除某个表,必须要先禁用表
禁用表
语法:disable “表名”
删除表
语法:drop “表名”
删除ORDER_INFO表
hbase(main):046:0> disable "ORDER_INFO" Took 0.4547 seconds hbase(main):047:0> drop "ORDER_INFO" Took 0.4385 seconds hbase(main):048:0> list TABLE SYSTEM.CATALOG SYSTEM.FUNCTION SYSTEM.LOG SYSTEM.MUTEX SYSTEM.SEQUENCE SYSTEM.STATS 6 row(s) Took 0.0052 seconds => ["SYSTEM.CATALOG", "SYSTEM.FUNCTION", "SYSTEM.LOG", "SYSTEM.MUTEX", "SYSTEM.SEQUENCE", "SYSTEM.STATS"]- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
添加数据
接下来,我们需要往订单表中添加以下数据
订单ID 订单状态 支付金额 支付方式ID 用户ID 操作时间 商品分类 ID STATUS PAY_MONEY PAYWAY USER_ID OPERATION_DATE CATEGORY 000001 已提交 4070 1 4944191 2020-04-25 12:09:16 手机; 使用put操作
HBase中的put命令,可以用来将数据保存到表中。但put一次只能保存一个列的值。以下是put的语法结构:
put ‘表名’,‘ROWKEY’,‘列蔟名:列名’,‘值’
hbase(main):049:0> create 'ORDER_INFO','C1' Created table ORDER_INFO Took 1.2423 seconds => Hbase::Table - ORDER_INFO hbase(main):050:0> put 'ORDER_INFO','000001','C1:ID','000001' Took 0.1005 seconds hbase(main):051:0> put 'ORDER_INFO','000001','C1:STATUS','已提交' Took 0.0044 seconds hbase(main):052:0> put 'ORDER_INFO','000001','C1:PAY_MONEY',4070 Took 0.0045 seconds hbase(main):053:0> put 'ORDER_INFO','000001','C1:PAYWAY',1 Took 0.0042 seconds hbase(main):054:0> put 'ORDER_INFO','000001','C1:USER_ID',4944191 Took 0.0045 seconds hbase(main):055:0> put 'ORDER_INFO','000001','C1:OPERATION_DATE','2020-04-25 12:09:16' Took 0.0040 seconds hbase(main):056:0> put 'ORDER_INFO','000001','C1:CATEGORY','手机;' Took 0.0053 seconds hbase(main):057:0>- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
查看添加的数据
要求将rowkey为:000001对应的数据查询出来
使用get操作
在HBase中,可以使用get命令来获取单独的一行数据。语法:get ‘表名’,‘rowkey’
hbase(main):057:0> get 'ORDER_INFO','000001' COLUMN CELL C1:CATEGORY timestamp=1660558718961, value=\xE6\x89\x8B\xE6\x9C\xBA; C1:ID timestamp=1660558716878, value=000001 C1:OPERATION_DATE timestamp=1660558716999, value=2020-04-25 12:09:16 C1:PAYWAY timestamp=1660558716958, value=1 C1:PAY_MONEY timestamp=1660558716936, value=4070 C1:STATUS timestamp=1660558716907, value=\xE5\xB7\xB2\xE6\x8F\x90\xE4\xBA\xA4 C1:USER_ID timestamp=1660558716978, value=4944191 1 row(s) Took 0.0520 seconds hbase(main):058:0>- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
查看数据value显示中文
在HBase shell中,如果在数据中出现了一些中文,默认HBase shell中显示出来的是十六进制编码。要想将这些编码显示为中文,我们需要在get命令后添加一个属性:{FORMATTER => ‘toString’}
格式为:get ‘ORDER_INFO’,‘000001’, {FORMATTER => ‘toString’}
- { key => value},这个是Ruby语法,表示定义一个HASH结构
- get是一个HBase Ruby方法,’ORDER_INFO’、’000001’、{FORMATTER => ‘toString’}是put方法的三个参数
- FORMATTER要使用大写
- 在Ruby中用{}表示一个字典,类似于hashtable,FORMATTER表示key、’toString’表示值
hbase(main):058:0> get 'ORDER_INFO','000001', {FORMATTER => 'toString'} COLUMN CELL C1:CATEGORY timestamp=1660558718961, value=手机; C1:ID timestamp=1660558716878, value=000001 C1:OPERATION_DATE timestamp=1660558716999, value=2020-04-25 12:09:16 C1:PAYWAY timestamp=1660558716958, value=1 C1:PAY_MONEY timestamp=1660558716936, value=4070 C1:STATUS timestamp=1660558716907, value=已提交 C1:USER_ID timestamp=1660558716978, value=4944191 1 row(s) Took 0.0222 seconds hbase(main):059:0>- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
更新操作
将订单ID为000001的状态,更改为「已付款」
使用put操作
同样,在HBase中,也是使用put命令来进行数据的更新,语法与之前的添加数据一模一样
hbase(main):060:0> get 'ORDER_INFO','000001', {FORMATTER => 'toString'} COLUMN CELL C1:CATEGORY timestamp=1660558718961, value=手机; C1:ID timestamp=1660558716878, value=000001 C1:OPERATION_DATE timestamp=1660558716999, value=2020-04-25 12:09:16 C1:PAYWAY timestamp=1660558716958, value=1 C1:PAY_MONEY timestamp=1660558716936, value=4070 C1:STATUS timestamp=1660558716907, value=已提交 C1:USER_ID timestamp=1660558716978, value=4944191 1 row(s) Took 0.0258 seconds hbase(main):061:0> put 'ORDER_INFO','000001','C1:STATUS','已付款' Took 0.0051 seconds hbase(main):062:0> get 'ORDER_INFO','000001', {FORMATTER => 'toString'} COLUMN CELL C1:CATEGORY timestamp=1660558718961, value=手机; C1:ID timestamp=1660558716878, value=000001 C1:OPERATION_DATE timestamp=1660558716999, value=2020-04-25 12:09:16 C1:PAYWAY timestamp=1660558716958, value=1 C1:PAY_MONEY timestamp=1660558716936, value=4070 C1:STATUS timestamp=1660615875423, value=已付款 C1:USER_ID timestamp=1660558716978, value=4944191 1 row(s) Took 0.0143 seconds hbase(main):063:0>- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- HBase中会自动维护数据的版本
- 每次put操作的执行,都会重新生成新的时间戳
删除操作
删除状态列数据
将订单ID为000001的状态STSTUS列删除
使用delete操作
在HBase中,可以使用delete命令来将一个单元格的数据删除
语法格式:delete ‘表名’, ‘rowkey’, ‘列蔟:列’
注意:此处HBase默认会保存多个时间戳的版本数据,所以这里的delete删除的是最新版本的列数据
hbase(main):068:0> delete 'ORDER_INFO', '000001', 'C1:STATUS' Took 0.0136 seconds- 1
- 2
删除整行数据
将订单ID为000001的信息全部删除(删除所有的列)
使用deleteall操作
deleteall命令可以将指定rowkey对应的所有列全部删除
语法格式:deleteall ‘表名’,‘rowkey’
hbase(main):070:0> deleteall 'ORDER_INFO','000001' Took 0.0091 seconds- 1
- 2
清空表
将ORDER_INFO的数据全部删除
使用truncate操作
truncate命令用来清空某个表中的所有数据
语法格式:truncate “表名”
hbase(main):071:0> truncate 'ORDER_INFO' Truncating 'ORDER_INFO' table (it may take a while): Disabling table... Truncating table... Took 1.5176 seconds- 1
- 2
- 3
- 4
- 5
导入测试数据文件
需求:ORDER_INFO.txt 中,有一份这样的HBase数据集,我们需要将这些指令放到HBase中执行,将数据导入到HBase中
资料下载:wget http://osswangting.oss-cn-shanghai.aliyuncs.com/hbase/ORDER_INFO.txt
注意是linux命令行操作,并非进入到交互界面后
wangting@ops01:/home/wangting/hbase >ll total 52 -rw-r--r-- 1 wangting wangting 49366 Aug 5 16:34 ORDER_INFO.txt wangting@ops01:/home/wangting/hbase > wangting@ops01:/home/wangting/hbase >pwd /home/wangting/hbase wangting@ops01:/home/wangting/hbase > wangting@ops01:/home/wangting/hbase >hbase shell /home/wangting/hbase/ORDER_INFO.txt SLF4J: Class path contains multiple SLF4J bindings. SLF4J: Found binding in [jar:file:/opt/module/hbase/lib/phoenix-5.0.0-HBase-2.0-client.jar!/org/slf4j/impl/StaticLoggerBinder.class] SLF4J: Found binding in [jar:file:/opt/module/hbase/lib/slf4j-log4j12-1.7.25.jar!/org/slf4j/impl/StaticLoggerBinder.class] SLF4J: Found binding in [jar:file:/opt/module/hadoop-3.1.3/share/hadoop/common/lib/slf4j-log4j12-1.7.30.jar!/org/slf4j/impl/StaticLoggerBinder.class] SLF4J: See http://www.slf4j.org/codes.html multiple_bindings for an explanation. Took 0.5581 seconds Took 0.0072 seconds Took 0.0047 seconds Took 0.0046 seconds Took 0.0064 seconds ... ...- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
计数操作
查看HBase中的ORDER_INFO表,一共有多少条记录
使用count操作
hbase(main):074:0> count 'ORDER_INFO' 66 row(s) Took 0.0570 seconds => 66 hbase(main):075:0>- 1
- 2
- 3
- 4
注意:这个操作是比较耗时的。在数据量大的这个命令可能会运行很久,本次导入数据量非常少
大量数据的计数统计方式
当HBase中数据量大时,可以使用HBase中提供的MapReduce程序来进行计数统计
语法如下:$HBASE_HOME/bin/hbase org.apache.hadoop.hbase.mapreduce.RowCounter ‘表名’
wangting@ops01:/home/wangting/hbase >$HBASE_HOME/bin/hbase org.apache.hadoop.hbase.mapreduce.RowCounter 'ORDER_INFO' SLF4J: Class path contains multiple SLF4J bindings. SLF4J: Found binding in [jar:file:/opt/module/hbase/lib/phoenix-5.0.0-HBase-2.0-client.jar!/org/slf4j/impl/StaticLoggerBinder.class] SLF4J: Found binding in [jar:file:/opt/module/hbase/lib/slf4j-log4j12-1.7.25.jar!/org/slf4j/impl/StaticLoggerBinder.class] SLF4J: Found binding in [jar:file:/opt/module/hadoop-3.1.3/share/hadoop/common/lib/slf4j-log4j12-1.7.30.jar!/org/slf4j/impl/StaticLoggerBinder.class] SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanation. 2022-08-16 10:51:15,013 INFO [main] client.RMProxy: Connecting to ResourceManager at ops02/11.8.36.63:8032 2022-08-16 10:51:17,747 INFO [main] zookeeper.ReadOnlyZKClient: Connect 0x0e27ba81 to ... ... HBase Counters BYTES_IN_REMOTE_RESULTS=5616 BYTES_IN_RESULTS=5616 MILLIS_BETWEEN_NEXTS=591 NOT_SERVING_REGION_EXCEPTION=0 NUM_SCANNER_RESTARTS=0 NUM_SCAN_RESULTS_STALE=0 REGIONS_SCANNED=1 REMOTE_RPC_CALLS=1 REMOTE_RPC_RETRIES=0 ROWS_FILTERED=0 ROWS_SCANNED=66 RPC_CALLS=1 RPC_RETRIES=0 org.apache.hadoop.hbase.mapreduce.RowCounter$RowCounterMapper$Counters ROWS=66 File Input Format Counters Bytes Read=0 File Output Format Counters Bytes Written=0 wangting@ops01:/home/wangting/hbase >- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
最终可以看到ROWS=66的输出信息
扫描操作
查看ORDER_INFO表中所有的数据
使用scan操作
在HBase,我们可以使用scan命令来扫描HBase中的表。语法:scan ‘表名’
hbase(main):075:0> scan 'ORDER_INFO',{FORMATTER => 'toString'} ROW COLUMN+CELL 02602f66-adc7-40d4-8485-76b5632b5b53 column=C1:CATEGORY, timestamp=1660617813649, value=手机; 02602f66-adc7-40d4-8485-76b5632b5b53 column=C1:OPERATION_DATE, timestamp=1660617813327, value=2020-04-25 12:09:16 02602f66-adc7-40d4-8485-76b5632b5b53 column=C1:PAYWAY, timestamp=1660617812628, value=1 02602f66-adc7-40d4-8485-76b5632b5b53 column=C1:PAY_MONEY, timestamp=1660617812242, value=4070 02602f66-adc7-40d4-8485-76b5632b5b53 column=C1:STATUS, timestamp=1660617811677, value=已提交 02602f66-adc7-40d4-8485-76b5632b5b53 column=C1:USER_ID, timestamp=1660617812988, value=4944191 0968a418-f2bc-49b4-b9a9-2157cf214cfd column=C1:CATEGORY, timestamp=1660617813651, value=家用电器;电脑; .... ....- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
注意:尽量避免scan一张大表
查询订单数据(只显示3条)
hbase(main):076:0> scan 'ORDER_INFO', {LIMIT => 3, FORMATTER => 'toString'}- 1
只查询订单状态以及支付方式,并且只展示3条数据
hbase(main):077:0> scan 'ORDER_INFO', {LIMIT => 3, COLUMNS => ['C1:STATUS', 'C1:PAYWAY'], FORMATTER => 'toString'} ROW COLUMN+CELL 02602f66-adc7-40d4-8485-76b5632b5b53 column=C1:PAYWAY, timestamp=1660617812628, value=1 02602f66-adc7-40d4-8485-76b5632b5b53 column=C1:STATUS, timestamp=1660617811677, value=已提交 0968a418-f2bc-49b4-b9a9-2157cf214cfd column=C1:PAYWAY, timestamp=1660617812632, value=1 0968a418-f2bc-49b4-b9a9-2157cf214cfd column=C1:STATUS, timestamp=1660617811735, value=已完成 0e01edba-5e55-425e-837a-7efb91c56630 column=C1:PAYWAY, timestamp=1660617812639, value=3 0e01edba-5e55-425e-837a-7efb91c56630 column=C1:STATUS, timestamp=1660617811748, value=已付款 3 row(s) Took 0.0127 seconds- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
查询指定订单ID的数据并以中文展示
根据ROWKEY来查询对应的数据,ROWKEY为02602f66-adc7-40d4-8485-76b5632b5b53,只查询订单状态、支付方式,并以中文展示
要查询指定ROWKEY的数据,需要使用ROWPREFIXFILTER
语法格式:scan ‘表名’, {ROWPREFIXFILTER => ‘rowkey’}
hbase(main):078:0> scan 'ORDER_INFO', {ROWPREFIXFILTER => '02602f66-adc7-40d4-8485-76b5632b5b53', COLUMNS => ['C1:STATUS', 'C1:PAYWAY'], FORMATTER => 'toString'} ROW COLUMN+CELL 02602f66-adc7-40d4-8485-76b5632b5b53 column=C1:PAYWAY, timestamp=1660617812628, value=1 02602f66-adc7-40d4-8485-76b5632b5b53 column=C1:STATUS, timestamp=1660617811677, value=已提交 1 row(s) Took 0.0103 seconds hbase(main):079:0>- 1
- 2
- 3
- 4
- 5
- 6
- 7
过滤器
在HBase中,如果要对海量的数据来进行查询,此时基本的操作是比较无力的。需要借助HBase中的高级语法——Filter来进行查询。Filter可以根据列簇、列、版本等条件来对数据进行过滤查询。因为在HBase中,主键、列、版本都是有序存储的,所以借助Filter,可以高效地完成查询。当执行Filter时,HBase会将Filter分发给各个HBase服务器节点来进行查询。
HBase中的过滤器也是基于Java开发的,只不过在Shell中,我们是使用基于JRuby的语法来实现的交互式查询。
在HBase的shell中,通过show_filters指令,可以查看到HBase中内置的一些过滤器
内置过滤器
hbase(main):079:0> show_filters DependentColumnFilter # 允许用户指定一个参考列或引用列来过滤其他列的过滤器 KeyOnlyFilter # 只对单元格的键进行过滤和显示,不显示值 ColumnCountGetFilter # 限制每个逻辑行返回键值对的个数,在get方法中使用 SingleColumnValueFilter # 在指定的列蔟和列中进行比较的值过滤器 PrefixFilter # rowkey前缀过滤器 SingleColumnValueExcludeFilter # 排除匹配成功的值 FirstKeyOnlyFilter # 只扫描显示相同键的第一个单元格,其键值对会显示出来 ColumnRangeFilter # 过滤列名称的范围 ColumnValueFilter # 过滤列值的范围 TimestampsFilter # 时间戳过滤,支持等值,可以设置多个时间戳 FamilyFilter # 列簇过滤器 QualifierFilter # 列标识过滤器,只显示对应列名的数据 ColumnPrefixFilter # 对列名称的前缀进行过滤 RowFilter # 实现行键字符串的比较和过滤 MultipleColumnPrefixFilter # 可以指定多个前缀对列名称过滤 InclusiveStopFilter # 替代 ENDROW 返回终止条件行 PageFilter # 对显示结果按行进行分页显示 ValueFilter # 值过滤器,找到符合值条件的键值对 ColumnPaginationFilter # 对一行的所有列分页,只返回 [offset,offset+limit] 范围内的列 Took 0.0075 seconds- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
过滤器用法
scan ‘表名’, { Filter => "过滤器(比较运算符, ‘比较器表达式’)” }
比较器
比较器 描述 表达式语言缩写 BinaryComparator 匹配完整字节数组 binary:值 BinaryPrefixComparator 匹配字节数组前缀 binaryprefix:值 BitComparator 匹配比特位 bit:值 NullComparator 匹配空值 null RegexStringComparator 匹配正则表达式 regexstring:正则表达式 SubstringComparator 匹配子字符串 substring:值 基本语法:比较器类型:比较器的值
需求1:使用RowFilter查询指定订单ID的数据
只查询订单的ID为:02602f66-adc7-40d4-8485-76b5632b5b53、订单状态以及支付方式
分析:
- 因为要订单ID就是ORDER_INFO表的rowkey,所以,我们应该使用rowkey过滤器来过滤
- 通过HBase的JAVA API,找到RowFilter构造器
- 参数1:op——比较运算符
- 参数2:rowComparator——比较器
所以构建该Filter的时候,只需要传入两个参数即可
hbase(main):081:0> scan 'ORDER_INFO', {FILTER => "RowFilter(=,'binary:02602f66-adc7-40d4-8485-76b5632b5b53')",FORMATTER => 'toString'} ROW COLUMN+CELL 02602f66-adc7-40d4-8485-76b5632b5b53 column=C1:CATEGORY, timestamp=1660617813649, value=手机; 02602f66-adc7-40d4-8485-76b5632b5b53 column=C1:OPERATION_DATE, timestamp=1660617813327, value=2020-04-25 12:09:16 02602f66-adc7-40d4-8485-76b5632b5b53 column=C1:PAYWAY, timestamp=1660617812628, value=1 02602f66-adc7-40d4-8485-76b5632b5b53 column=C1:PAY_MONEY, timestamp=1660617812242, value=4070 02602f66-adc7-40d4-8485-76b5632b5b53 column=C1:STATUS, timestamp=1660617811677, value=已提交 02602f66-adc7-40d4-8485-76b5632b5b53 column=C1:USER_ID, timestamp=1660617812988, value=4944191 1 row(s) Took 0.0139 seconds hbase(main):082:0>- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
需求2:查询状态为「已付款」的订单
分析:
- 因为此处要指定列来进行查询,所以,我们不再使用rowkey过滤器,而是要使用列过滤器
- 我们要针对指定列和指定值进行过滤,比较适合使用SingleColumnValueFilter过滤器,查看JAVA API
- 参数1:列簇
- 参数2:列标识(列名)
- 比较运算符
- 比较器
注意:
- 列名STATUS的大小写一定要对!此处使用的是大写!
- 列名写错了查不出来数据,但HBase不会报错,因为HBase是无模式的
hbase(main):082:0> scan 'ORDER_INFO', {FILTER => "SingleColumnValueFilter('C1', 'STATUS', =, 'binary:已付款')", FORMATTER => 'toString'} ROW COLUMN+CELL 0e01edba-5e55-425e-837a-7efb91c56630 column=C1:CATEGORY, timestamp=1660617813657, value=男装;男鞋; 0e01edba-5e55-425e-837a-7efb91c56630 column=C1:OPERATION_DATE, timestamp=1660617813337, value=2020-04-25 12:09:44 0e01edba-5e55-425e-837a-7efb91c56630 column=C1:PAYWAY, timestamp=1660617812639, value=3 0e01edba-5e55-425e-837a-7efb91c56630 column=C1:PAY_MONEY, timestamp=1660617812254, value=6370 0e01edba-5e55-425e-837a-7efb91c56630 column=C1:STATUS, timestamp=1660617811748, value=已付款 ... ... ...- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
需求3:查询支付方式为1,且金额大于3000的订单
分析:
- 此处需要使用多个过滤器共同来实现查询,多个过滤器,可以使用AND或者OR来组合多个过滤器完成查询
- 使用SingleColumnValueFilter实现对应列的查询
查询支付方式为1:SingleColumnValueFilter(‘C1’, ‘PAYWAY’, = , ‘binary:1’)
查询金额大于3000的订单:SingleColumnValueFilter(‘C1’, ‘PAY_MONEY’, > , ‘binary:3000’)
hbase(main):083:0> scan 'ORDER_INFO', {FILTER => "SingleColumnValueFilter('C1', 'PAYWAY', = , 'binary:1') AND SingleColumnValueFilter('C1', 'PAY_MONEY', > , 'binary:3000')", FORMATTER => 'toString'}- 1
注意:
- HBase shell中比较默认都是字符串比较,所以如果是比较数值类型的,会出现不准确的情况
- 例如:在字符串比较中4000是比100000大的
INCR
某新闻APP应用为了统计每个新闻的每隔一段时间的访问次数,他们将这些数据保存在HBase中
该表格数据如下所示:
新闻ID 访问次数 时间段 ROWKEY 0000000001 12 00:00-01:00 0000000001_00:00-01:00 0000000002 12 01:00-02:00 0000000002_01:00-02:00 要求:原子性增加新闻的访问次数值
incr可以实现对某个单元格的值进行原子性计数。
语法:incr ‘表名’,‘rowkey’,‘列蔟:列名’,累加值(默认累加1)
- 如果某一列要实现计数功能,必须要使用incr来创建对应的列
- 使用put创建的列是不能实现累加的
导入测试数据
下载地址:wget http://osswangting.oss-cn-shanghai.aliyuncs.com/hbase/NEWS_VISIT_CNT.txt
该脚本文件创建了一个表,名为NEWS_VISIT_CNT,列蔟为C1。并使用incr创建了若干个计数器,每个rowkey为:新闻的编号_时间段。CNT为count的缩写,表示访问的次数
wangting@ops01:/home/wangting/hbase >pwd /home/wangting/hbase wangting@ops01:/home/wangting/hbase >ll total 60 -rw-r--r-- 1 wangting wangting 6595 Aug 5 16:34 NEWS_VISIT_CNT.txt -rw-r--r-- 1 wangting wangting 49366 Aug 5 16:34 ORDER_INFO.txt wangting@ops01:/home/wangting/hbase >hbase shell /home/wangting/hbase/NEWS_VISIT_CNT.txt- 1
- 2
- 3
- 4
- 5
- 6
- 7
hbase(main):084:0> scan 'NEWS_VISIT_CNT', {LIMIT => 3, FORMATTER => 'toString'} ROW COLUMN+CELL 0000000001_00:00-01:00 column=C1:CNT, timestamp=1660639040544, value= 0000000001_00:00-01:00 column=C1:TIME_RANGE, timestamp=1660639040815, value=00:00-01:00 0000000002_01:00-02:00 column=C1:CNT, timestamp=1660639040575, value= 0000000002_01:00-02:00 column=C1:TIME_RANGE, timestamp=1660639040820, value=01:00-02:00 0000000003_02:00-03:00 column=C1:CNT, timestamp=1660639040581, value={ 0000000003_02:00-03:00 column=C1:TIME_RANGE, timestamp=1660639040825, value=02:00-03:00 3 row(s) Took 0.0215 seconds hbase(main):085:0>- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
需求1:对0000000020新闻01:00 - 02:00访问计数+1
- 获取0000000020这条新闻在01:00-02:00当前的访问次数
hbase(main):085:0> get_counter 'NEWS_VISIT_CNT','0000000020_01:00-02:00','C1:CNT' COUNTER VALUE = 6 Took 0.0101 seconds- 1
- 2
- 3
- 使用incr进行累加
hbase(main):087:0> incr 'NEWS_VISIT_CNT','0000000020_01:00-02:00','C1:CNT' COUNTER VALUE = 7 Took 0.0099 seconds hbase(main):088:0>- 1
- 2
- 3
- 4
- 再次查案新闻当前的访问次数
hbase(main):088:0> get_counter 'NEWS_VISIT_CNT','0000000020_01:00-02:00','C1:CNT' COUNTER VALUE = 7 Took 0.0041 seconds hbase(main):089:0>- 1
- 2
- 3
- 4
shell管理操作
status
显示服务器状态信息
hbase(main):090:0> status 1 active master, 0 backup masters, 3 servers, 0 dead, 13.6667 average load Took 0.1194 seconds- 1
- 2
- 3
whoami
显示HBase当前用户
hbase(main):091:0> whoami wangting (auth:SIMPLE) groups: wangting Took 0.0093 seconds- 1
- 2
- 3
- 4
list
显示当前所有的表
hbase(main):092:0> list TABLE NEWS_VISIT_CNT ORDER_INFO SYSTEM.CATALOG SYSTEM.FUNCTION SYSTEM.LOG SYSTEM.MUTEX SYSTEM.SEQUENCE SYSTEM.STATS 8 row(s) Took 0.0065 seconds => ["NEWS_VISIT_CNT", "ORDER_INFO", "SYSTEM.CATALOG", "SYSTEM.FUNCTION", "SYSTEM.LOG", "SYSTEM.MUTEX", "SYSTEM.SEQUENCE", "SYSTEM.STATS"]- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
count
统计指定表的记录数
hbase(main):093:0> count 'ORDER_INFO' 66 row(s) Took 0.0241 seconds => 66- 1
- 2
- 3
- 4
describe
展示表结构信息
hbase(main):094:0> describe 'ORDER_INFO' Table ORDER_INFO is ENABLED ORDER_INFO COLUMN FAMILIES DESCRIPTION {NAME => 'C1', VERSIONS => '1', EVICT_BLOCKS_ON_CLOSE => 'false', NEW_VERSION_BEHAVIOR => 'false', KEEP_DELETED_CELLS => 'FALSE', CACHE_DATA_ON_WRITE => 'false', DATA_BLOCK_ENCODING => 'NONE', TTL => 'FOREVER', MIN_VERSIONS => '0', REPLICATION_SCOPE => '0', BLOOMFILTER => 'ROW', CACHE_INDEX_ON_WRITE => 'false', IN_MEMORY => 'false', CACHE_BLOOMS_ON_WRITE => 'false', PREFETCH_BLOCKS_ON_OPEN => 'false', COMPRESSION => 'NONE', BLOCKCACHE => 'true', BLOCKSIZE => '65536'} 1 row(s) Took 0.0260 seconds hbase(main):095:0>- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
exists
检查表是否存在,适用于表量特别多的情况
hbase(main):095:0> exists 'ORDER_INFO' Table ORDER_INFO does exist Took 0.0084 seconds => true- 1
- 2
- 3
- 4
is_endbled、is_disabled
检查表是否启用或禁用
hbase(main):096:0> is_enabled 'ORDER_INFO' true Took 0.0080 seconds => true hbase(main):097:0> is_disabled 'ORDER_INFO' false Took 0.0040 seconds => 1- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
alter
该命令可以改变表和列蔟的模式
# 创建测试USER_INFO表,列簇C1,C2 hbase(main):098:0> create 'USER_INFO', 'C1', 'C2' Created table USER_INFO Took 0.7598 seconds => Hbase::Table - USER_INFO # 新增列簇C3 hbase(main):099:0> alter 'USER_INFO', 'C3' Updating all regions with the new schema... 1/1 regions updated. Done. Took 2.2088 seconds # 删除列簇C3 hbase(main):100:0> alter 'USER_INFO', 'delete' => 'C3' Updating all regions with the new schema... 1/1 regions updated. Done. Took 2.1770 seconds- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
disable、enable
禁用一张表/启用一张表
hbase(main):101:0> disable 'USER_INFO' Took 0.7453 seconds hbase(main):102:0> enable 'USER_INFO' Took 0.7531 seconds- 1
- 2
- 3
- 4
drop
删除一张表,记得在删除表之前必须先禁用
truncate
清空表的数据,相当于禁用表-删除表-创建表
HBase_java_api编程
需求与数据集
某某自来水公司,需要存储大量的缴费明细数据。以下截取了缴费明细的一部分内容
用户id 姓名 用户地址 性别 缴费时间 表示数(本次) 表示数(上次) 用量(立方) 合计金额 查表日期 最迟缴费日期 4944191 登卫红 贵州省铜仁市德江县7单元267室 男 2020-05-10 308.1 283.1 25 150 2020-04-25 2020-06-09 因为缴费明细的数据记录非常庞大,该公司的信息部门决定使用HBase来存储这些数据。并且,他们希望能够通过Java程序来访问这些数据
实验环境准备
创建maven工程
通过idea工具创建maven项目(idea开发工具自行准备)
groupId cn.wangt artifactId hbase_op 导入pom依赖
pom文件
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd"> <modelVersion>4.0.0modelVersion> <groupId>cn.wangtgroupId> <artifactId>hbase_opartifactId> <version>1.0-SNAPSHOTversion> <repositories> <repository> <id>aliyunid> <url>http://maven.aliyun.com/nexus/content/groups/public/url> <releases> <enabled>trueenabled> releases> <snapshots> <enabled>falseenabled> <updatePolicy>neverupdatePolicy> snapshots> repository> repositories> <dependencies> <dependency> <groupId>org.apache.hbasegroupId> <artifactId>hbase-clientartifactId> <version>2.1.0version> dependency> <dependency> <groupId>commons-iogroupId> <artifactId>commons-ioartifactId> <version>2.6version> dependency> <dependency> <groupId>junitgroupId> <artifactId>junitartifactId> <version>4.12version> <scope>testscope> dependency> <dependency> <groupId>org.testnggroupId> <artifactId>testngartifactId> <version>6.14.3version> <scope>testscope> dependency> dependencies> <build> <plugins> <plugin> <groupId>org.apache.maven.pluginsgroupId> <artifactId>maven-compiler-pluginartifactId> <version>3.1version> <configuration> <target>1.8target> <source>1.8source> configuration> plugin> plugins> build> project>- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
右边打开maven工具栏,对项目进行test测试,会去拉取依赖包
复制HBase和Hadoop配置文件
将以下三个配置文件复制到创建的maven项目中resource目录中
- hbase-site.xml (hbase/conf)
- core-site.xml (hadoop-3.1.3/etc/hadoop)
- log4j.properties (hbase/conf)
项目创建包结构和类
-
在项目test你也可以创建cn.wangt.hbase.admin.api_test 包结构
-
创建TableAmdinTest类
创建Hbase连接以及admin管理对象
要操作Hbase也需要建立Hbase的连接。此处我们仍然使用TestNG来编写测试。使用@BeforeTest初始化HBase连接,创建admin对象、@AfterTest关闭连接
实现步骤:
- 使用HbaseConfiguration.create()创建Hbase配置
- 使用ConnectionFactory.createConnection()创建Hbase连接
- 要创建表,需要基于Hbase连接获取admin管理对象
- 使用admin.close、connection.close关闭连接
package cn.wangt.hbase.admin.api_test; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.hbase.HBaseConfiguration; import org.apache.hadoop.hbase.client.*; import org.testng.annotations.AfterTest; import org.testng.annotations.BeforeTest; import java.io.IOException; public class TableAmdinTest { private Connection connection; private Admin admin; @BeforeTest public void beforeTest() throws IOException { // 1.使用HbaseConfiguration.create()创建Hbase配置 Configuration configuration = HBaseConfiguration.create(); // 2. 使用ConnectionFactory.createConnection()创建Hbase连接 connection = ConnectionFactory.createConnection(configuration); // 3. 要创建表,需要基于Hbase连接获取admin管理对象 // 要创建表、删除表需要和HMaster连接,所以需要有一个admin对象 admin = connection.getAdmin(); } @AfterTest public void afterTest() throws IOException { // 4. 使用admin.close、connection.close关闭连接 admin.close(); connection.close(); } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
需求1:使用java代码创建表
创建一个名为WATER_BILL的表,包含一个列蔟C1
实现步骤:
- 判断表是否存在
a) 存在,则退出 - 使用TableDescriptorBuilder.newBuilder构建表描述构建器
- 使用ColumnFamilyDescriptorBuilder.newBuilder构建列蔟描述构建器
- 构建列蔟描述,构建表描述
- 创建表
当前的hbase表list信息:
hbase(main):103:0> list TABLE NEWS_VISIT_CNT ORDER_INFO SYSTEM.CATALOG SYSTEM.FUNCTION SYSTEM.LOG SYSTEM.MUTEX SYSTEM.SEQUENCE SYSTEM.STATS USER_INFO 9 row(s) Took 0.0079 seconds => ["NEWS_VISIT_CNT", "ORDER_INFO", "SYSTEM.CATALOG", "SYSTEM.FUNCTION", "SYSTEM.LOG", "SYSTEM.MUTEX", "SYSTEM.SEQUENCE", "SYSTEM.STATS", "USER_INFO"]- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
建表代码
package cn.wangt.hbase.admin.api_test; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.hbase.HBaseConfiguration; import org.apache.hadoop.hbase.TableName; import org.apache.hadoop.hbase.client.*; import org.apache.hadoop.hbase.util.Bytes; import org.testng.annotations.AfterTest; import org.testng.annotations.BeforeTest; import org.testng.annotations.Test; import java.io.IOException; public class TableAmdinTest { private Connection connection; private Admin admin; @BeforeTest public void beforeTest() throws IOException { // 1.使用HbaseConfiguration.create()创建Hbase配置 Configuration configuration = HBaseConfiguration.create(); // 2. 使用ConnectionFactory.createConnection()创建Hbase连接 connection = ConnectionFactory.createConnection(configuration); // 3. 要创建表,需要基于Hbase连接获取admin管理对象 // 要创建表、删除表需要和HMaster连接,所以需要有一个admin对象 admin = connection.getAdmin(); } @Test public void createTableTest() throws IOException { // 表名 String TABLE_NAME = "WATER_BILL"; // 列簇名 String COLUMN_FAMILY = "C1"; // 1.判断表是否存在 if(admin.tableExists(TableName.valueOf(TABLE_NAME))){ return; } // 2.构建表描述构建器 TableDescriptorBuilder tableDescriptorBuilder = TableDescriptorBuilder.newBuilder(TableName.valueOf(TABLE_NAME)); // 3.构建列簇描述构建器 ColumnFamilyDescriptorBuilder columnFamilyDescriptorBuilder = ColumnFamilyDescriptorBuilder.newBuilder(Bytes.toBytes(COLUMN_FAMILY)); // 4.构建列簇描述 ColumnFamilyDescriptor columnFamilyDescriptor = columnFamilyDescriptorBuilder.build(); // 5.构建表描述 添加列簇 tableDescriptorBuilder.setColumnFamily(columnFamilyDescriptor); TableDescriptor tableDescriptor = tableDescriptorBuilder.build(); // 6.创建表 admin.createTable(tableDescriptor); } @AfterTest public void afterTest() throws IOException { // 4. 使用admin.close、connection.close关闭连接 admin.close(); connection.close(); } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
再次查看hbase表list信息:
hbase(main):105:0> list TABLE NEWS_VISIT_CNT ORDER_INFO SYSTEM.CATALOG SYSTEM.FUNCTION SYSTEM.LOG SYSTEM.MUTEX SYSTEM.SEQUENCE SYSTEM.STATS USER_INFO WATER_BILL 10 row(s) Took 0.0038 seconds => ["NEWS_VISIT_CNT", "ORDER_INFO", "SYSTEM.CATALOG", "SYSTEM.FUNCTION", "SYSTEM.LOG", "SYSTEM.MUTEX", "SYSTEM.SEQUENCE", "SYSTEM.STATS", "USER_INFO", "WATER_BILL"]- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
可以看到WATER_BILL表创建成功
需求2:向表中插入数据
-
在 test 目录中创建 cn.wangt.hbase.data.api_test 包
-
创建DataOpTest类
在表中插入一个行,该行只包含一个列
ROWKEY 姓名(列名:NAME) 4944191 登卫红 实现步骤:
1.使用Hbase连接获取Htable
2.构建ROWKEY、列蔟名、列名
3.构建Put对象(对应put命令)
4.添加姓名列
5.使用Htable表对象执行put操作
6.关闭Htable表对象代码:
package cn.wangt.hbase.data.api_test; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.hbase.HBaseConfiguration; import org.apache.hadoop.hbase.TableName; import org.apache.hadoop.hbase.client.*; import org.apache.hadoop.hbase.util.Bytes; import org.testng.annotations.AfterTest; import org.testng.annotations.BeforeTest; import org.testng.annotations.Test; import java.io.IOException; public class DataOpTest { private Configuration configuration; private Connection connection; @BeforeTest public void beforeTest() throws IOException { configuration = HBaseConfiguration.create(); connection = ConnectionFactory.createConnection(configuration); } @Test public void addTest() throws IOException { // 1.使用Hbase连接获取Htable TableName waterBillTableName = TableName.valueOf("WATER_BILL"); Table waterBillTable = connection.getTable(waterBillTableName); // 2.构建ROWKEY、列蔟名、列名 String rowkey = "4944191"; String cfName = "C1"; String colName = "NAME"; // 3.构建Put对象(对应put命令) Put put = new Put(Bytes.toBytes(rowkey)); // 4.添加姓名列 put.addColumn(Bytes.toBytes(cfName) , Bytes.toBytes(colName) , Bytes.toBytes("登卫红")); // 5.使用Htable表对象执行put操作 waterBillTable.put(put); // 6. 关闭表 waterBillTable.close(); } @AfterTest public void afterTest() throws IOException { connection.close(); } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
查询验证:
hbase(main):106:0> get 'WATER_BILL','4944191',{FORMATTER => 'toString'} COLUMN CELL C1:NAME timestamp=1660704584510, value=登卫红 1 row(s) Took 0.0118 seconds hbase(main):107:0>- 1
- 2
- 3
- 4
- 5
- 6
继续尝试插入其他列数据
列名 说明 值 ADDRESS 用户地址 贵州省铜仁市德江县7单元267室 SEX 性别 男 PAY_DATE 缴费时间 2020-05-10 NUM_CURRENT 表示数(本次) 308.1 NUM_PREVIOUS 表示数(上次) 283.1 NUM_USAGE 用量(立方) 25 TOTAL_MONEY 合计金额 150 RECORD_DATE 查表日期 2020-04-25 LATEST_DATE 最迟缴费日期 2020-06-09 代码:
package cn.wangt.hbase.data.api_test; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.hbase.HBaseConfiguration; import org.apache.hadoop.hbase.TableName; import org.apache.hadoop.hbase.client.*; import org.apache.hadoop.hbase.util.Bytes; import org.testng.annotations.AfterTest; import org.testng.annotations.BeforeTest; import org.testng.annotations.Test; import java.io.IOException; public class DataOpTest { private Configuration configuration; private Connection connection; @BeforeTest public void beforeTest() throws IOException { configuration = HBaseConfiguration.create(); connection = ConnectionFactory.createConnection(configuration); } @Test public void addTest() throws IOException { // 1.使用Hbase连接获取Htable TableName waterBillTableName = TableName.valueOf("WATER_BILL"); Table waterBillTable = connection.getTable(waterBillTableName); // 2.构建ROWKEY、列蔟名、列名 String rowkey = "4944191"; String cfName = "C1"; String colName = "NAME"; String colADDRESS = "ADDRESS"; String colSEX = "SEX"; String colPAY_DATE = "PAY_DATE"; String colNUM_CURRENT = "NUM_CURRENT"; String colNUM_PREVIOUS = "NUM_PREVIOUS"; String colNUM_USAGE = "NUM_USAGE"; String colTOTAL_MONEY = "TOTAL_MONEY"; String colRECORD_DATE = "RECORD_DATE"; String colLATEST_DATE = "LATEST_DATE"; // 3.构建Put对象(对应put命令) Put put = new Put(Bytes.toBytes(rowkey)); // 4.添加姓名列 put.addColumn(Bytes.toBytes(cfName) , Bytes.toBytes(colName) , Bytes.toBytes("登卫红")); put.addColumn(Bytes.toBytes(cfName) , Bytes.toBytes(colADDRESS) , Bytes.toBytes("贵州省铜仁市德江县7单元267室")); put.addColumn(Bytes.toBytes(cfName) , Bytes.toBytes(colSEX) , Bytes.toBytes("男")); put.addColumn(Bytes.toBytes(cfName) , Bytes.toBytes(colPAY_DATE) , Bytes.toBytes("2020-05-10")); put.addColumn(Bytes.toBytes(cfName) , Bytes.toBytes(colNUM_CURRENT) , Bytes.toBytes("308.1")); put.addColumn(Bytes.toBytes(cfName) , Bytes.toBytes(colNUM_PREVIOUS) , Bytes.toBytes("283.1")); put.addColumn(Bytes.toBytes(cfName) , Bytes.toBytes(colNUM_USAGE) , Bytes.toBytes("25")); put.addColumn(Bytes.toBytes(cfName) , Bytes.toBytes(colTOTAL_MONEY) , Bytes.toBytes("150")); put.addColumn(Bytes.toBytes(cfName) , Bytes.toBytes(colRECORD_DATE) , Bytes.toBytes("2020-04-25")); put.addColumn(Bytes.toBytes(cfName) , Bytes.toBytes(colLATEST_DATE) , Bytes.toBytes("2020-06-09")); // 5.使用Htable表对象执行put操作 waterBillTable.put(put); // 6. 关闭表 waterBillTable.close(); } @AfterTest public void afterTest() throws IOException { connection.close(); } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
查询验证:
hbase(main):108:0> get 'WATER_BILL','4944191',{FORMATTER => 'toString'} COLUMN CELL C1:ADDRESS timestamp=1660705352480, value=贵州省铜仁市德江县7单元267室 C1:LATEST_DATE timestamp=1660705352480, value=2020-06-09 C1:NAME timestamp=1660705352480, value=登卫红 C1:NUM_CURRENT timestamp=1660705352480, value=308.1 C1:NUM_PREVIOUS timestamp=1660705352480, value=283.1 C1:NUM_USAGE timestamp=1660705352480, value=25 C1:PAY_DATE timestamp=1660705352480, value=2020-05-10 C1:RECORD_DATE timestamp=1660705352480, value=2020-04-25 C1:SEX timestamp=1660705352480, value=男 C1:TOTAL_MONEY timestamp=1660705352480, value=150 1 row(s) Took 0.0122 seconds- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
需求3:表中查看1条数据
查询rowkey为4944191的所有列的数据,并打印出来
实现步骤:
- 获取HTable
- 使用rowkey构建Get对象
- 执行get请求
- 获取所有单元格
- 打印rowkey
- 迭代单元格列表
- 关闭表
代码:
注意:截至目前代码均是类的完整代码,实际只是在原有代码中增加了get方法,运行时只需要单独运行get即可
后续代码至附上相关代码段
package cn.wangt.hbase.data.api_test; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.hbase.Cell; import org.apache.hadoop.hbase.HBaseConfiguration; import org.apache.hadoop.hbase.TableName; import org.apache.hadoop.hbase.client.*; import org.apache.hadoop.hbase.util.Bytes; import org.testng.annotations.AfterTest; import org.testng.annotations.BeforeTest; import org.testng.annotations.Test; import java.io.IOException; import java.util.List; public class DataOpTest { private Configuration configuration; private Connection connection; @BeforeTest public void beforeTest() throws IOException { configuration = HBaseConfiguration.create(); connection = ConnectionFactory.createConnection(configuration); } @Test public void addTest() throws IOException { // 1.使用Hbase连接获取Htable TableName waterBillTableName = TableName.valueOf("WATER_BILL"); Table waterBillTable = connection.getTable(waterBillTableName); // 2.构建ROWKEY、列蔟名、列名 String rowkey = "4944191"; String cfName = "C1"; String colName = "NAME"; String colADDRESS = "ADDRESS"; String colSEX = "SEX"; String colPAY_DATE = "PAY_DATE"; String colNUM_CURRENT = "NUM_CURRENT"; String colNUM_PREVIOUS = "NUM_PREVIOUS"; String colNUM_USAGE = "NUM_USAGE"; String colTOTAL_MONEY = "TOTAL_MONEY"; String colRECORD_DATE = "RECORD_DATE"; String colLATEST_DATE = "LATEST_DATE"; // 3.构建Put对象(对应put命令) Put put = new Put(Bytes.toBytes(rowkey)); // 4.添加姓名列 put.addColumn(Bytes.toBytes(cfName) , Bytes.toBytes(colName) , Bytes.toBytes("登卫红")); put.addColumn(Bytes.toBytes(cfName) , Bytes.toBytes(colADDRESS) , Bytes.toBytes("贵州省铜仁市德江县7单元267室")); put.addColumn(Bytes.toBytes(cfName) , Bytes.toBytes(colSEX) , Bytes.toBytes("男")); put.addColumn(Bytes.toBytes(cfName) , Bytes.toBytes(colPAY_DATE) , Bytes.toBytes("2020-05-10")); put.addColumn(Bytes.toBytes(cfName) , Bytes.toBytes(colNUM_CURRENT) , Bytes.toBytes("308.1")); put.addColumn(Bytes.toBytes(cfName) , Bytes.toBytes(colNUM_PREVIOUS) , Bytes.toBytes("283.1")); put.addColumn(Bytes.toBytes(cfName) , Bytes.toBytes(colNUM_USAGE) , Bytes.toBytes("25")); put.addColumn(Bytes.toBytes(cfName) , Bytes.toBytes(colTOTAL_MONEY) , Bytes.toBytes("150")); put.addColumn(Bytes.toBytes(cfName) , Bytes.toBytes(colRECORD_DATE) , Bytes.toBytes("2020-04-25")); put.addColumn(Bytes.toBytes(cfName) , Bytes.toBytes(colLATEST_DATE) , Bytes.toBytes("2020-06-09")); // 5.使用Htable表对象执行put操作 waterBillTable.put(put); // 6. 关闭表 waterBillTable.close(); } @Test public void getOneTest() throws IOException { // 1. 获取HTable TableName waterBillTableName = TableName.valueOf("WATER_BILL"); Table waterBilltable = connection.getTable(waterBillTableName); // 2. 使用rowkey构建Get对象 Get get = new Get(Bytes.toBytes("4944191")); // 3. 执行get请求 Result result = waterBilltable.get(get); // 4. 获取所有单元格 List<Cell> cellList = result.listCells(); // 打印rowkey System.out.println("rowkey => " + Bytes.toString(result.getRow())); // 5. 迭代单元格列表 for (Cell cell : cellList) { // 打印列蔟名 System.out.print(Bytes.toString(cell.getQualifierArray(), cell.getQualifierOffset(), cell.getQualifierLength())); System.out.println(" => " + Bytes.toString(cell.getValueArray(), cell.getValueOffset(), cell.getValueLength())); } // 6.关闭表 waterBillTable.close(); } @AfterTest public void afterTest() throws IOException { connection.close(); } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
- 110
- 111
- 112
- 113
- 114
- 115
- 116
- 117
- 118
- 119
- 120
- 121
- 122
- 123
- 124
- 125
- 126
- 127
- 128
run运行getOneTest查看 idea控制台输出:
2022-08-17 11:13:15,559 INFO [ReadOnlyZKClient-ops01:2181,ops02:2181,ops03:2181@0x15eb5ee5-SendThread(ops03:2181)] zookeeper.ClientCnxn: Socket connection established to ops03/11.8.36.76:2181, initiating session 2022-08-17 11:13:15,590 INFO [ReadOnlyZKClient-ops01:2181,ops02:2181,ops03:2181@0x15eb5ee5-SendThread(ops03:2181)] zookeeper.ClientCnxn: Session establishment complete on server ops03/11.8.36.76:2181, sessionid = 0x30a8f7122b00027, negotiated timeout = 40000 rowkey => 4944191 ADDRESS => 贵州省铜仁市德江县7单元267室 LATEST_DATE => 2020-06-09 NAME => 登卫红 NUM_CURRENT => 308.1 NUM_PREVIOUS => 283.1 NUM_USAGE => 25 PAY_DATE => 2020-05-10 RECORD_DATE => 2020-04-25 SEX => 男 TOTAL_MONEY => 150 2022-08-17 11:13:17,012 INFO [main] zookeeper.ReadOnlyZKClient: Close zookeeper connection 0x15eb5ee5 to ops01:2181,ops02:2181,ops03:2181 =============================================== Default Suite Total tests run: 1, Failures: 0, Skips: 0 =============================================== 2022-08-17 11:13:17,028 INFO [ReadOnlyZKClient-ops01:2181,ops02:2181,ops03:2181@0x15eb5ee5] zookeeper.ZooKeeper: Session: 0x30a8f7122b00027 closed Process finished with exit code 0- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
需求4:删除一条数据
删除rowkey为4944191的整条数据
实现步骤:
1.获取HTable对象
2.根据rowkey构建delete对象
3.执行delete请求
4.关闭表相关代码块:
@Test public void deleteOneTest() throws IOException { // 1. 获取HTable对象 Table waterBillTable = connection.getTable(TableName.valueOf("WATER_BILL")); // 2. 根据rowkey构建delete对象 Delete delete = new Delete(Bytes.toBytes("4944191")); // 3. 执行delete请求 waterBillTable.delete(delete); // 4. 关闭表 waterBillTable.close(); }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
复核验证
hbase(main):110:0> get 'WATER_BILL','4944191',{FORMATTER => 'toString'} COLUMN CELL 0 row(s) Took 0.0053 seconds hbase(main):111:0>- 1
- 2
- 3
- 4
- 5
需求5:导入数据&导出数据
数据导入
需求将一份数据文件导入HBase中
实验数据文件:http://osswangting.oss-cn-shanghai.aliyuncs.com/hbase/part-m-00000_10w
在HBase中,有一个Import的MapReduce作业,可以专门用来将数据文件导入到HBase中
使用方式:hbase org.apache.hadoop.hbase.mapreduce.Import 表名 HDFS数据文件路径
- 将资料中数据文件上传到Linux中或wget下载
- 将文件上传到hdfs中
# 下载数据文件 wangting@ops01:/home/wangting/hbase >wget http://osswangting.oss-cn-shanghai.aliyuncs.com/hbase/part-m-00000_10w # 查看 wangting@ops01:/home/wangting/hbase >ll total 50340 -rw-r--r-- 1 wangting wangting 6595 Aug 5 16:34 NEWS_VISIT_CNT.txt -rw-r--r-- 1 wangting wangting 49366 Aug 5 16:34 ORDER_INFO.txt -rw-r--r-- 1 wangting wangting 51483241 Aug 5 16:32 part-m-00000_10w # 创建hdfs目录 wangting@ops01:/home/wangting/hbase >hadoop fs -mkdir -p /water_bill/output_ept_10W 2022-08-17 11:39:05,123 INFO [main] Configuration.deprecation (Configuration.java:logDeprecation(1395)) - No unit for dfs.client.datanode-restart.timeout(30) assuming SECONDS # 文件上传至hdfs wangting@ops01:/home/wangting/hbase >hadoop fs -put part-m-00000_10w /water_bill/output_ept_10W 2022-08-17 11:39:17,432 INFO [main] Configuration.deprecation (Configuration.java:logDeprecation(1395)) - No unit for dfs.client.datanode-restart.timeout(30) assuming SECONDS 2022-08-17 11:39:18,194 INFO [Thread-7] sasl.SaslDataTransferClient (SaslDataTransferClient.java:checkTrustAndSend(239)) - SASL encryption trust check: localHostTrusted = false, remoteHostTrusted = false # 查看上传结果 wangting@ops01:/home/wangting/hbase >hadoop dfs -ls /water_bill/output_ept_10W WARNING: Use of this script to execute dfs is deprecated. WARNING: Attempting to execute replacement "hdfs dfs" instead. 2022-08-17 11:39:44,182 INFO [main] Configuration.deprecation (Configuration.java:logDeprecation(1395)) - No unit for dfs.client.datanode-restart.timeout(30) assuming SECONDS Found 1 items -rw-r--r-- 3 wangting supergroup 51483241 2022-08-17 11:39 /water_bill/output_ept_10W/part-m-00000_10w wangting@ops01:/home/wangting/hbase >- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
当前相当于HBase有一张表water_bill,但暂时未和hdfs上数据关联,还需要导入hbase
wangting@ops01:/home/wangting/hbase >hbase org.apache.hadoop.hbase.mapreduce.Import WATER_BILL /water_bill/output_ept_10W SLF4J: Class path contains multiple SLF4J bindings. SLF4J: Found binding in [jar:file:/opt/module/hbase/lib/phoenix-5.0.0-HBase-2.0-client.jar!/org/slf4j/impl/StaticLoggerBinder.class] SLF4J: Found binding in [jar:file:/opt/module/hbase/lib/slf4j-log4j12-1.7.25.jar!/org/slf4j/impl/StaticLoggerBinder.class] SLF4J: Found binding in [jar:file:/opt/module/hadoop-3.1.3/share/hadoop/common/lib/slf4j-log4j12-1.7.30.jar!/org/slf4j/impl/StaticLoggerBinder.class] SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanation. 2022-08-17 11:44:48,894 INFO [main] mapreduce.Import: writing directly to table from Mapper. 2022-08-17 11:44:49,100 INFO [main] client.RMProxy: Connecting to ResourceManager at ops02/11.8.36.63:8032 ... ... 2022-08-17 11:45:00,711 INFO [main] mapreduce.Job: map 0% reduce 0% 2022-08-17 11:45:13,801 INFO [main] mapreduce.Job: map 100% reduce 0% 2022-08-17 11:45:14,814 INFO [main] mapreduce.Job: Job job_1615531413182_9573 completed successfully 2022-08-17 11:45:14,901 WARN [main] counters.FrameworkCounterGroup: MAP_PHYSICAL_MEMORY_BYTES_MAX is not a recognized counter. 2022-08-17 11:45:14,902 WARN [main] counters.FrameworkCounterGroup: MAP_VIRTUAL_MEMORY_BYTES_MAX is not a recognized counter. 2022-08-17 11:45:14,911 INFO [main] mapreduce.Job: operations=0 HDFS: Number of bytes read=51483366 HDFS: Number of bytes written=0 HDFS: Number of read operations=3 HDFS: Number of large read operations=0 HDFS: Number of write operations=0 Job Counters Launched map tasks=1 Data-local map tasks=1 Total time spent by all maps in occupied slots (ms)=11095 Total time spent by all reduces in occupied slots (ms)=0 Total time spent by all map tasks (ms)=11095 Total vcore-milliseconds taken by all map tasks=11095 Total megabyte-milliseconds taken by all map tasks=11361280 Map-Reduce Framework Map input records=99505 Map output records=99505 Input split bytes=125 Spilled Records=0 Failed Shuffles=0 Merged Map outputs=0 GC time elapsed (ms)=172 CPU time spent (ms)=12840 Physical memory (bytes) snapshot=272273408 Virtual memory (bytes) snapshot=2012495872 Total committed heap usage (bytes)=170393600 File Input Format Counters Bytes Read=51483241 File Output Format Counters Bytes Written=0 2022-08-17 11:45:14,917 WARN [main] counters.FrameworkCounterGroup: MAP_PHYSICAL_MEMORY_BYTES_MAX is not a recognized counter. 2022-08-17 11:45:14,917 WARN [main] counters.FrameworkCounterGroup: MAP_VIRTUAL_MEMORY_BYTES_MAX is not a recognized counter. 2022-08-17 11:45:14,921 WARN [main] counters.FrameworkCounterGroup: MAP_PHYSICAL_MEMORY_BYTES_MAX is not a recognized counter. 2022-08-17 11:45:14,921 WARN [main] counters.FrameworkCounterGroup: MAP_VIRTUAL_MEMORY_BYTES_MAX is not a recognized counter. wangting@ops01:/home/wangting/hbase >- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
数据导出
# 查看hdfs的/water_bill/目录 wangting@ops01:/home/wangting/hbase >hadoop dfs -ls /water_bill/ WARNING: Use of this script to execute dfs is deprecated. WARNING: Attempting to execute replacement "hdfs dfs" instead. 2022-08-17 11:54:49,211 INFO [main] Configuration.deprecation (Configuration.java:logDeprecation(1395)) - No unit for dfs.client.datanode-restart.timeout(30) assuming SECONDS Found 1 items drwxr-xr-x - wangting supergroup 0 2022-08-17 11:39 /water_bill/output_ept_10W wangting@ops01:/home/wangting/hbase > # 数据导出 wangting@ops01:/home/wangting/hbase >hbase org.apache.hadoop.hbase.mapreduce.Export WATER_BILL /water_bill/output_ept_10W_export_0817 SLF4J: Class path contains multiple SLF4J bindings. SLF4J: Found binding in [jar:file:/opt/module/hbase/lib/phoenix-5.0.0-HBase-2.0-client.jar!/org/slf4j/impl/StaticLoggerBinder.class] SLF4J: Found binding in [jar:file:/opt/module/hbase/lib/slf4j-log4j12-1.7.25.jar!/org/slf4j/impl/StaticLoggerBinder.class] SLF4J: Found binding in [jar:file:/opt/module/hadoop-3.1.3/share/hadoop/common/lib/slf4j-log4j12-1.7.30.jar!/org/slf4j/impl/StaticLoggerBinder.class] SLF4J: See http://www.slf4j.org/codes.htmlmultiple_bindings for an explanation. ... ... 2022-08-17 11:55:09,033 INFO [main] mapreduce.Job: map 0% reduce 0% 2022-08-17 11:55:19,115 INFO [main] mapreduce.Job: map 100% reduce 0% 2022-08-17 11:55:20,128 INFO [main] mapreduce.Job: Job job_1615531413182_9574 completed successfully 2022-08-17 11:55:20,214 WARN [main] counters.FrameworkCounterGroup: MAP_PHYSICAL_MEMORY_BYTES_MAX is not a recognized counter. 2022-08-17 11:55:20,214 WARN [main] counters.FrameworkCounterGroup: MAP_VIRTUAL_MEMORY_BYTES_MAX is not a recognized counter. 2022-08-17 11:55:20,224 INFO [main] mapreduce.Job: Total time spent by all reduces in occupied slots (ms)=0 Total time spent by all map tasks (ms)=8586 Total vcore-milliseconds taken by all map tasks=8586 Total megabyte-milliseconds taken by all map tasks=8792064 Map-Reduce Framework Map input records=99505 Map output records=99505 Input split bytes=136 Spilled Records=0 Failed Shuffles=0 Merged Map outputs=0 GC time elapsed (ms)=149 CPU time spent (ms)=10410 Physical memory (bytes) snapshot=287027200 Virtual memory (bytes) snapshot=2046070784 Total committed heap usage (bytes)=186122240 HBase Counters BYTES_IN_REMOTE_RESULTS=53960732 BYTES_IN_RESULTS=53960732 MILLIS_BETWEEN_NEXTS=3697 NOT_SERVING_REGION_EXCEPTION=0 NUM_SCANNER_RESTARTS=0 NUM_SCAN_RESULTS_STALE=0 REGIONS_SCANNED=1 REMOTE_RPC_CALLS=996 REMOTE_RPC_RETRIES=0 ROWS_FILTERED=1 ROWS_SCANNED=99506 RPC_CALLS=996 RPC_RETRIES=0 File Input Format Counters Bytes Read=0 File Output Format Counters Bytes Written=51483241 # 查看验证hdfs已经成功导出一份output_ept_10W_export_0817数据 wangting@ops01:/home/wangting/hbase >hadoop dfs -ls /water_bill/ WARNING: Use of this script to execute dfs is deprecated. WARNING: Attempting to execute replacement "hdfs dfs" instead. 2022-08-17 11:56:30,957 INFO [main] Configuration.deprecation (Configuration.java:logDeprecation(1395)) - No unit for dfs.client.datanode-restart.timeout(30) assuming SECONDS Found 2 items drwxr-xr-x - wangting supergroup 0 2022-08-17 11:39 /water_bill/output_ept_10W drwxr-xr-x - wangting supergroup 0 2022-08-17 11:55 /water_bill/output_ept_10W_export_0817 wangting@ops01:/home/wangting/hbase >- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
需求6:代码实现条件查询
查询2020年6月份所有用户的用水量
在Java API中,我们也是使用scan + filter来实现过滤查询。2020年6月份其实就是从2020年6月1日到2020年6月30日的所有抄表数据
-
在cn.wangt.hbase.data.api_test包下创建ScanFilterTest类
-
使用@BeforeTest、@AfterTest构建HBase连接、以及关闭HBase连接
实现步骤:
- 获取表
- 构建scan请求对象
- 构建两个过滤器
a) 构建两个日期范围过滤器(注意此处请使用RECORD_DATE——抄表日期比较
b) 构建过滤器列表 - 执行scan扫描请求
- 迭代打印result
- 迭代单元格列表
- 关闭ResultScanner(这玩意把转换成一个个的类似get的操作,注意要关闭释放资源)
- 关闭表
代码实现
package cn.wangt.hbase.data.api_test; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.hbase.Cell; import org.apache.hadoop.hbase.CompareOperator; import org.apache.hadoop.hbase.HBaseConfiguration; import org.apache.hadoop.hbase.TableName; import org.apache.hadoop.hbase.client.*; import org.apache.hadoop.hbase.filter.BinaryComparator; import org.apache.hadoop.hbase.filter.FilterList; import org.apache.hadoop.hbase.filter.SingleColumnValueFilter; import org.apache.hadoop.hbase.util.Bytes; import org.testng.annotations.AfterTest; import org.testng.annotations.BeforeTest; import org.testng.annotations.Test; import java.io.IOException; import java.util.Iterator; import java.util.List; public class ScanFilterTest { private Connection connection; private TableName TABLE_NAME = TableName.valueOf("WATER_BILL"); @BeforeTest public void beforeTest() throws IOException { Configuration configuration = HBaseConfiguration.create(); connection = ConnectionFactory.createConnection(configuration); } // 查询2020年6月份所有用户的用水量数据 @Test public void scanFilterTest() throws IOException { // 1. 获取表 Table table = connection.getTable(TABLE_NAME); // 2. 构建scan请求对象 Scan scan = new Scan(); // 3. 构建两个过滤器 // a) 构建两个日期范围过滤器(注意此处请使用RECORD_DATE——抄表日期比较 SingleColumnValueFilter startFilter = new SingleColumnValueFilter(Bytes.toBytes("C1") , Bytes.toBytes("RECORD_DATE") , CompareOperator.GREATER_OR_EQUAL , new BinaryComparator(Bytes.toBytes("2020-06-01"))); SingleColumnValueFilter endFilter = new SingleColumnValueFilter(Bytes.toBytes("C1") , Bytes.toBytes("RECORD_DATE") , CompareOperator.LESS_OR_EQUAL , new BinaryComparator(Bytes.toBytes("2020-06-30"))); // b) 构建过滤器列表 FilterList filterList = new FilterList(FilterList.Operator.MUST_PASS_ALL, startFilter, endFilter); // 4. 执行scan扫描请求 scan.setFilter(filterList); ResultScanner resultScanner = table.getScanner(scan); Iterator<Result> iterator = resultScanner.iterator(); // 5. 迭代打印result while (iterator.hasNext()) { Result result = iterator.next(); // 列出所有的单元格 List<Cell> cellList = result.listCells(); // 5. 打印rowkey byte[] rowkey = result.getRow(); System.out.println(Bytes.toString(rowkey)); // 6. 迭代单元格列表 for (Cell cell : cellList) { // 将字节数组转换为字符串 // 获取列蔟的名称 String cf = Bytes.toString(cell.getFamilyArray(), cell.getFamilyOffset(), cell.getFamilyLength()); // 获取列的名称 String columnName = Bytes.toString(cell.getQualifierArray(), cell.getQualifierOffset(), cell.getQualifierLength()); String value = ""; // 解决乱码问题: // 思路: // 如果某个列是以下列中的其中一个,调用toDouble将它认为是一个数值来转换 //1. NUM_CURRENT //2. NUM_PREVIOUS //3. NUM_USAGE //4. TOTAL_MONEY if (columnName.equals("NUM_CURRENT") || columnName.equals("NUM_PREVIOUS") || columnName.equals("NUM_USAGE") || columnName.equals("TOTAL_MONEY")) { value = Bytes.toDouble(cell.getValueArray()) + ""; } else { // 获取值 value = Bytes.toString(cell.getValueArray(), cell.getValueOffset(), cell.getValueLength()); } System.out.println(cf + ":" + columnName + " -> " + value); } } // 7. 关闭ResultScanner(这玩意把转换成一个个的类似get的操作,注意要关闭释放资源) resultScanner.close(); // 8. 关闭表 table.close(); } @AfterTest public void afterTest() throws IOException { connection.close(); } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
- 110
- 111
- 112
- 113
- 114
需求7:使用Java代码删除表
创建一个测试表
hbase(main):114:0> create 'TEST_FOR_DROP','C1' Created table TEST_FOR_DROP Took 0.7583 seconds => Hbase::Table - TEST_FOR_DROP hbase(main):115:0> list TABLE NEWS_VISIT_CNT ORDER_INFO SYSTEM.CATALOG SYSTEM.FUNCTION SYSTEM.LOG SYSTEM.MUTEX SYSTEM.SEQUENCE SYSTEM.STATS TEST_FOR_DROP USER_INFO WATER_BILL 11 row(s) Took 0.0078 seconds => ["NEWS_VISIT_CNT", "ORDER_INFO", "SYSTEM.CATALOG", "SYSTEM.FUNCTION", "SYSTEM.LOG", "SYSTEM.MUTEX", "SYSTEM.SEQUENCE", "SYSTEM.STATS", "TEST_FOR_DROP", "USER_INFO", "WATER_BILL"] hbase(main):116:0>- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
实现步骤:
- 判断表是否存在
- 如果存在,则禁用表
- 再删除表
在admin.api_test包下的,TableAmdinTest类中增加一个dropTable方法
相关代码块
@Test public void dropTable() throws IOException { // 表名 TableName tableName = TableName.valueOf("TEST_FOR_DROP"); // 1. 判断表是否存在 if(admin.tableExists(tableName)) { // 2. 禁用表 admin.disableTable(tableName); // 3. 删除表 admin.deleteTable(tableName); } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
命令行查看验证发现TEST_FOR_DROP表已经不存在
hbase(main):117:0> list TABLE NEWS_VISIT_CNT ORDER_INFO SYSTEM.CATALOG SYSTEM.FUNCTION SYSTEM.LOG SYSTEM.MUTEX SYSTEM.SEQUENCE SYSTEM.STATS USER_INFO WATER_BILL 10 row(s) Took 0.0070 seconds => ["NEWS_VISIT_CNT", "ORDER_INFO", "SYSTEM.CATALOG", "SYSTEM.FUNCTION", "SYSTEM.LOG", "SYSTEM.MUTEX", "SYSTEM.SEQUENCE", "SYSTEM.STATS", "USER_INFO", "WATER_BILL"] hbase(main):118:0>- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
HBase高可用
考虑关于HBase集群的一个问题,在当前的HBase集群中,只有一个Master,一旦Master出现故障,将会导致HBase不再可用。所以,在实际的生产环境中,是非常有必要搭建一个高可用的HBase集群的
HBase高可用介绍
HBase的高可用配置其实就是HMaster的高可用。要搭建HBase的高可用,只需要再选择一个节点作为HMaster,在HBase的conf目录下创建文件backup-masters,然后再backup-masters添加备份Master的记录。一条记录代表一个backup master,可以在文件配置多个记录
当前环境查看
wangting@ops01:/home/wangting >for i in ops01 ops02 ops03;do echo "=== $i ===" && ssh $i jps -l | grep hbase;done === ops01 === 16029 org.apache.hadoop.hbase.regionserver.HRegionServer 15806 org.apache.hadoop.hbase.master.HMaster === ops02 === 60896 org.apache.hadoop.hbase.regionserver.HRegionServer === ops03 === 80496 org.apache.hadoop.hbase.regionserver.HRegionServer wangting@ops01:/home/wangting >- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
11.8.37.50 ops01 # HMaster
11.8.36.63 ops02
11.8.36.76 ops03hbase(main):118:0> status 1 active master, 0 backup masters, 3 servers, 0 dead, 14.3333 average load Took 0.0117 seconds hbase(main):119:0>- 1
- 2
- 3
- 4
搭建部署HBase高可用落地
# 在hbase的conf文件夹中创建 backup-masters 文件 wangting@ops01:/home/wangting >cd /opt/module/hbase/conf/ # 将另2台服务器hosts添加至文件 wangting@ops01:/opt/module/hbase/conf >vim backup-masters ops02 ops03 #分发同步文件 wangting@ops01:/opt/module/hbase/conf >scp backup-masters ops02:$PWD wangting@ops01:/opt/module/hbase/conf >scp backup-masters ops03:$PWD # 重启服务 wangting@ops01:/opt/module/hbase/bin >stop-hbase.sh wangting@ops01:/opt/module/hbase/bin >start-hbase.sh # 再次查看应用相关信息 wangting@ops01:/opt/module/hbase/bin >for i in ops01 ops02 ops03;do echo "=== $i ===" && ssh $i jps -l | grep hbase;done === ops01 === 112651 org.apache.hadoop.hbase.master.HMaster 112874 org.apache.hadoop.hbase.regionserver.HRegionServer === ops02 === 117251 org.apache.hadoop.hbase.regionserver.HRegionServer 117339 org.apache.hadoop.hbase.master.HMaster === ops03 === 64828 org.apache.hadoop.hbase.master.HMaster 64733 org.apache.hadoop.hbase.regionserver.HRegionServer- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
状态查看
hbase(main):119:0> status 1 active master, 2 backup masters, 3 servers, 0 dead, 14.3333 average load Took 0.0641 seconds hbase(main):120:0>- 1
- 2
- 3
- 4
通过zk去查看hbase集群信息
wangting@ops01:/home/wangting >zkCli.sh Connecting to localhost:2181 2022-08-17 16:44:34,063 [myid:] - INFO [main:Environment@109] - Client environment:zookeeper.version=3.5.7-f0fdd52973d373ffd9c86b81d99842dc2c7f660e, built on 02/10/2020 11:30 GMT 2022-08-17 16:44:34,067 [myid:] - INFO [main:Environment@109] - Client environment:host.name=ops01 [zk: localhost:2181(CONNECTED) 0] [zk: localhost:2181(CONNECTED) 1] # 通过get /hbase/master看到hbase的master是ops01 [zk: localhost:2181(CONNECTED) 2] get /hbase/master �master:16000D��PBUF ops01�}���ת0�} # 通过ls /hbase/backup-masters看到backup-masters为ops02和ops03 [zk: localhost:2181(CONNECTED) 3] ls /hbase/backup-masters [ops02,16000,1660725472902, ops03,16000,1660725472775] [zk: localhost:2181(CONNECTED) 4]- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
验证HBase高可用
# 查看当前ops01上hbase进程 wangting@ops01:/home/wangting >jps -l | grep hbase 112651 org.apache.hadoop.hbase.master.HMaster 112874 org.apache.hadoop.hbase.regionserver.HRegionServer # 杀掉master的进程 wangting@ops01:/home/wangting >kill -9 112651 wangting@ops01:/home/wangting > # 查看hbase集群服务信息 wangting@ops01:/home/wangting >for i in ops01 ops02 ops03;do echo "=== $i ===" && ssh $i jps -l | grep hbase;done === ops01 === 112874 org.apache.hadoop.hbase.regionserver.HRegionServer === ops02 === 117251 org.apache.hadoop.hbase.regionserver.HRegionServer 117339 org.apache.hadoop.hbase.master.HMaster === ops03 === 64828 org.apache.hadoop.hbase.master.HMaster 64733 org.apache.hadoop.hbase.regionserver.HRegionServer wangting@ops01:/home/wangting > # 通过zookeeper查看集群角色信息 wangting@ops01:/home/wangting >zkCli.sh Connecting to localhost:2181 2022-08-17 16:58:25,940 [myid:] - INFO [main:Environment@109] - Client environment:zookeeper.version=3.5.7-f0fdd52973d373ffd9c86b81d99842dc2c7f660e, built on 02/10/2020 11:30 GMT 2022-08-17 16:58:25,944 [myid:] - INFO [main:Environment@109] - Client environment:host.name=ops01 WatchedEvent state:SyncConnected type:None path:null # 可以看到杀掉ops01的master进程后,ops03成为master [zk: localhost:2181(CONNECTED) 0] get /hbase/master �master:16000��� L\�BPBUF ops03�}���ת0�} # backup-masters为ops02 [zk: localhost:2181(CONNECTED) 1] ls /hbase/backup-masters [ops02,16000,1660725472902] [zk: localhost:2181(CONNECTED) 2]- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
至此,hbase自动实现了master的角色切换
HBase架构
系统架构图
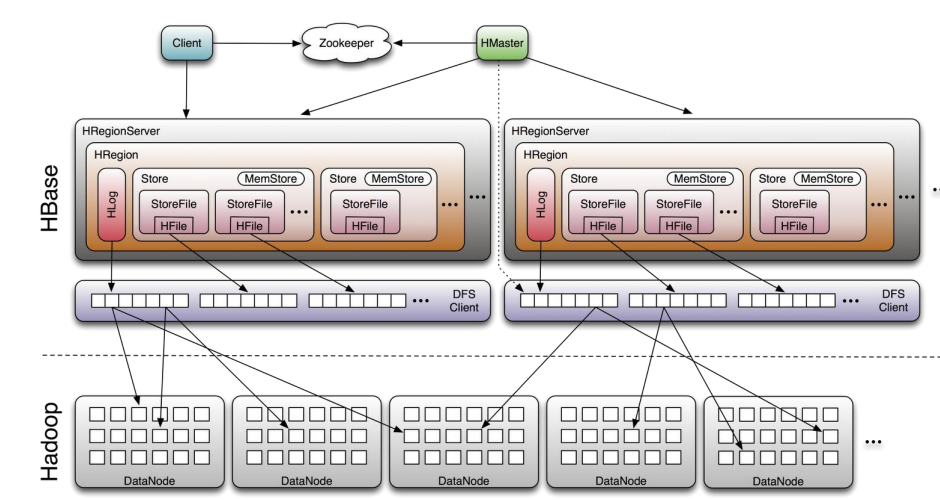
角色-Client
客户端,指发出HBase操作的请求方。例如:之前编写的Java API代码发起求情、以及HBase shell交互命令行,都是CLient
角色-Master Server
- 监控RegionServer
- 处理RegionServer故障转移
- 处理元数据的变更
- 处理region的分配或移除
- 在空闲时间进行数据的负载均衡
- 通过Zookeeper发布自己的位置给客户端
角色-Region Server
- 处理分配给它的Region
- 负责存储HBase的实际数据
- 刷新缓存到HDFS
- 维护HLog
- 执行压缩
- 负责处理Region分片
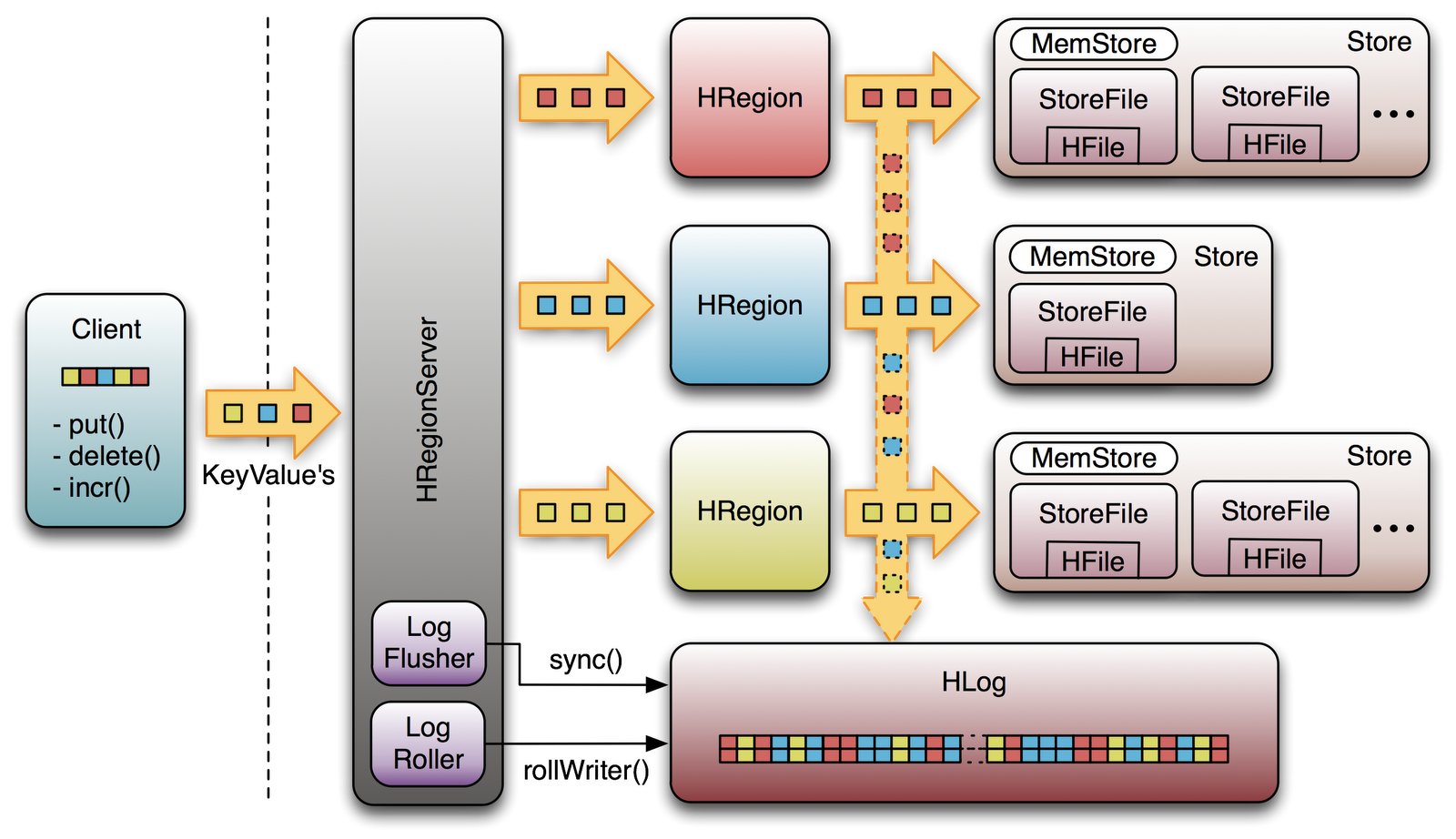
其中RegionServer中包含了大量丰富的组件
Write-Ahead logs
HFile(StoreFile)
Store
MemStore
Region逻辑结构模型
Region
- 在HBASE中,表被划分为很多「Region」,并由Region Server提供服务
Store
- Region按列蔟垂直划分为「Store」,存储在HDFS在文件中
MemStore
- MemStore与缓存内存类似
- 当往HBase中写入数据时,首先是写入到MemStore
- 每个列蔟将有一个MemStore
- 当MemStore存储快满的时候,整个数据将写入到HDFS中的HFile中
StoreFile
- 每当任何数据被写入HBASE时,首先要写入MemStore
- 当MemStore快满时,整个排序的key-value数据将被写入HDFS中的一个新的HFile中
- 写入HFile的操作是连续的,速度非常快
- 物理上存储的是HFile
WAL
- WAL全称为Write Ahead Log,它最大的作用就是故障恢复
- WAL是HBase中提供的一种高并发、持久化的日志保存与回放机制
- 每个业务数据的写入操作(PUT/DELETE/INCR),都会保存在WAL中
- 一旦服务器崩溃,通过回放WAL,就可以实现恢复崩溃之前的数据
- 物理上存储是Hadoop的Sequence File
Apache Phoenix
phoenix简介
Apache Phoenix让Hadoop中支持低延迟OLTP和业务操作分析。
-
提供标准的SQL以及完备的ACID事务支持
-
通过利用HBase作为存储,让NoSQL数据库具备通过有模式的方式读取数据,我们可以使用SQL语句来操作HBase,例如:创建表、以及插入数据、修改数据、删除数据等。
-
Phoenix通过协处理器在服务器端执行操作,最小化客户机/服务器数据传输
Apache Phoenix可以很好地与其他的Hadoop组件整合在一起,例如:Spark、Hive、Flume以及MapReduce。
hoenix特点
- Phoenix不会影响HBase性能,反而会提升HBase性能
- Phoenix将SQL查询编译为本机HBase扫描
- 确定scan的key的最佳startKey和endKey
- 编排scan的并行执行
- 将WHERE子句中的谓词推送到服务器端
- 通过协处理器执行聚合查询
- 用于提高非行键列查询性能的二级索引
- 统计数据收集,以改进并行化,并指导优化之间的选择
- 跳过扫描筛选器以优化IN、LIKE和OR查询
- 行键加盐保证分配均匀,负载均衡
Phoenix只是在HBase之上构建了SQL查询引擎,并不是像MapReduce、Spark这种大规模数据计算引擎。HBase的定位是在高性能随机读写,Phoenix可以使用SQL快查询HBase中的数据,但数据操作底层是必须符合HBase的存储结构,例如:必须要有ROWKEY、必须要有列蔟。因为有这样的一些限制,绝大多数公司不会选择HBase+Phoenix来作为数据仓库的开发。而是用来快速进行海量数据的随机读写。这方面HBase +Phoenix有很大的优势。
安装部署phoenix
官网下载地址:http://archive.apache.org/dist/phoenix/
# 安装包 wangting@ops01:/home/wangting >cd /opt/software/ wangting@ops01:/opt/software >ll | grep phoenix -rw-r--r-- 1 wangting wangting 436868323 May 9 17:11 apache-phoenix-5.0.0-HBase-2.0-bin.tar.gz # 解压 wangting@ops01:/opt/software >tar -zxvf apache-phoenix-5.0.0-HBase-2.0-bin.tar.gz -C /opt/module/ # 改名 wangting@ops01:/opt/module >mv apache-phoenix-5.0.0-HBase-2.0-bin phoenix wangting@ops01:/opt/module >cd phoenix/ wangting@ops01:/opt/module/phoenix > # 复制server包和client包到hbase集群各节点的lib目录下 wangting@ops01:/opt/module/phoenix >cp phoenix-*.jar /opt/module/hbase/lib/ wangting@ops01:/opt/module/phoenix >scp phoenix-*.jar ops02:/opt/module/hbase/lib/ wangting@ops01:/opt/module/phoenix >scp phoenix-*.jar ops03:/opt/module/hbase/lib/ # 添加环境变量 wangting@ops01:/opt/module/phoenix >sudo vim /etc/profile #phoenix export PHOENIX_HOME=/opt/module/phoenix export PATH=$PATH:$PHOENIX_HOME/bin wangting@ops01:/opt/module/phoenix >source /etc/profile wangting@ops01:/opt/module/phoenix >for i in ops01 ops02 ops03 ;do ssh $i sudo netstat -tnlpu|grep 2181;done tcp6 0 0 :::2181 :::* LISTEN 56644/java tcp6 0 0 :::2181 :::* LISTEN 105183/java tcp6 0 0 :::2181 :::* LISTEN 53772/java wangting@ops01:/opt/module/phoenix >cd /opt/module/hbase/conf/ # hbase配置文件增加命名空间映射和索引相关配置 wangting@ops01:/opt/module/hbase/conf >vim hbase-site.xml <!-- 支持HBase命名空间映射 --> <property> <name>phoenix.schema.isNamespaceMappingEnabled</name> <value>true</value> </property> <!-- 支持索引预写日志编码 --> <property> <name>hbase.regionserver.wal.codec</name> <value>org.apache.hadoop.hbase.regionserver.wal.IndexedWALEditCodec</value> </property> wangting@ops01:/opt/module/hbase/conf >scp hbase-site.xml ops02:$PWD wangting@ops01:/opt/module/hbase/conf >scp hbase-site.xml ops03:$PWD # 4. 将配置后的hbase-site.xml拷贝到phoenix的bin目录 wangting@ops01:/opt/module/hbase/conf >cp hbase-site.xml /opt/module/phoenix/bin/ # 重启hbase集群 wangting@ops01:/opt/module/phoenix >stop-hbase.sh wangting@ops01:/opt/module/phoenix >start-hbase.sh # 启动Phoenix 指定zookeeper集群 wangting@ops01:/home/wangting >sqlline.py ops01,ops02,ops03:2181 Setting property: [incremental, false] Setting property: [isolation, TRANSACTION_READ_COMMITTED] issuing: !connect jdbc:phoenix:ops01,ops02,ops03:2181 none none org.apache.phoenix.jdbc.PhoenixDriver Connecting to jdbc:phoenix:ops01,ops02,ops03:2181 SLF4J: Class path contains multiple SLF4J bindings. SLF4J: Found binding in [jar:file:/opt/module/phoenix/phoenix-5.0.0-HBase-2.0-client.jar!/org/slf4j/impl/StaticLoggerBinder.class] SLF4J: Found binding in [jar:file:/opt/module/hadoop-3.1.3/share/hadoop/common/lib/slf4j-log4j12-1.7.30.jar!/org/slf4j/impl/StaticLoggerBinder.class] SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanation. 22/08/17 18:01:30 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable 22/08/17 18:01:34 WARN query.ConnectionQueryServicesImpl: Expected 5 system tables but found 6:[SYSTEM.CATALOG, SYSTEM.FUNCTION, SYSTEM.LOG, SYSTEM.MUTEX, SYSTEM.SEQUENCE, SYSTEM.STATS] Connected to: Phoenix (version 5.0) Driver: PhoenixEmbeddedDriver (version 5.0) Autocommit status: true Transaction isolation: TRANSACTION_READ_COMMITTED Building list of tables and columns for tab-completion (set fastconnect to true to skip)... 133/133 (100%) Done Done sqlline version 1.2.0 0: jdbc:phoenix:ops01,ops02,ops03:2181> 0: jdbc:phoenix:ops01,ops02,ops03:2181> !tables +------------+--------------+-------------+---------------+----------+------------+----------------------------+-----------------+--------------+-----------------+---------------+---------------+-----------------+------------+-------------+----------------+----------+ | TABLE_CAT | TABLE_SCHEM | TABLE_NAME | TABLE_TYPE | REMARKS | TYPE_NAME | SELF_REFERENCING_COL_NAME | REF_GENERATION | INDEX_STATE | IMMUTABLE_ROWS | SALT_BUCKETS | MULTI_TENANT | VIEW_STATEMENT | VIEW_TYPE | INDEX_TYPE | TRANSACTIONAL | IS_NAMES | +------------+--------------+-------------+---------------+----------+------------+----------------------------+-----------------+--------------+-----------------+---------------+---------------+-----------------+------------+-------------+----------------+----------+ | | SYSTEM | CATALOG | SYSTEM TABLE | | | | | | false | null | false | | | | false | true | | | SYSTEM | FUNCTION | SYSTEM TABLE | | | | | | false | null | false | | | | false | true | | | SYSTEM | LOG | SYSTEM TABLE | | | | | | true | 32 | false | | | | false | true | | | SYSTEM | SEQUENCE | SYSTEM TABLE | | | | | | false | null | false | | | | false | true | | | SYSTEM | STATS | SYSTEM TABLE | | | | | | false | null | false | | | | false | true | +------------+--------------+-------------+---------------+----------+------------+----------------------------+-----------------+--------------+-----------------+---------------+---------------+-----------------+------------+-------------+----------------+----------+ 0: jdbc:phoenix:ops01,ops02,ops03:2181>- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
phoenix使用
phoenix创建表
在Phoenix中,我们可以使用类似于MySQL DDL的方式快速创建表
建表语法:
CREATE TABLE IF NOT EXISTS 表名 (
ROWKEY名称 数据类型 PRIMARY KEY
列蔟名.列名1 数据类型 NOT NULL,
列蔟名.列名2 数据类型 NOT NULL,
列蔟名.列名3 数据类型);
create table if not exists ORDER_DTL( ID varchar primary key, C1.STATUS varchar, C1.MONEY float, C1.PAY_WAY integer, C1.USER_ID varchar, C1.OPERATION_TIME varchar, C1.CATEGORY varchar );- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
查看表结构信息
0: jdbc:phoenix:ops01,ops02,ops03:2181> !desc ORDER_DTL +------------+--------------+-------------+-----------------+------------+------------+--------------+----------------+-----------------+-----------------+-----------+----------+-------------+----------------+-------------------+--------------------+-----------------+ | TABLE_CAT | TABLE_SCHEM | TABLE_NAME | COLUMN_NAME | DATA_TYPE | TYPE_NAME | COLUMN_SIZE | BUFFER_LENGTH | DECIMAL_DIGITS | NUM_PREC_RADIX | NULLABLE | REMARKS | COLUMN_DEF | SQL_DATA_TYPE | SQL_DATETIME_SUB | CHAR_OCTET_LENGTH | ORDINAL_POSITIO | +------------+--------------+-------------+-----------------+------------+------------+--------------+----------------+-----------------+-----------------+-----------+----------+-------------+----------------+-------------------+--------------------+-----------------+ | | | ORDER_DTL | ID | 12 | VARCHAR | null | null | null | null | 0 | | | null | null | null | 1 | | | | ORDER_DTL | STATUS | 12 | VARCHAR | null | null | null | null | 1 | | | null | null | null | 2 | | | | ORDER_DTL | MONEY | 6 | FLOAT | null | null | null | null | 1 | | | null | null | null | 3 | | | | ORDER_DTL | PAY_WAY | 4 | INTEGER | null | null | null | null | 1 | | | null | null | null | 4 | | | | ORDER_DTL | USER_ID | 12 | VARCHAR | null | null | null | null | 1 | | | null | null | null | 5 | | | | ORDER_DTL | OPERATION_TIME | 12 | VARCHAR | null | null | null | null | 1 | | | null | null | null | 6 | | | | ORDER_DTL | CATEGORY | 12 | VARCHAR | null | null | null | null | 1 | | | null | null | null | 7 | +------------+--------------+-------------+-----------------+------------+------------+--------------+----------------+-----------------+-----------------+-----------+----------+-------------+----------------+-------------------+--------------------+-----------------+ 0: jdbc:phoenix:ops01,ops02,ops03:2181>- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
删除表
0: jdbc:phoenix:ops01,ops02,ops03:2181> drop table if exists ORDER_DTL; No rows affected (1.601 seconds)- 1
- 2
phoenix大小写
在HBase中,如果在列蔟、列名没有添加双引号。Phoenix会自动转换为大写
create table if not exists ORDER_DTL( id varchar primary key, C1.status varchar, C1.money double, C1.pay_way integer, C1.user_id varchar, C1.operation_time varchar, C1.category varchar ); 0: jdbc:phoenix:ops01,ops02,ops03:2181> !desc ORDER_DTL |COLUMN_NAME |ID |STATUS |MONEY |PAY_WAY |USER_ID |OPERATION_TIME |CATEGORY- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
插入数据
在Phoenix中,插入并不是使用insert来实现的。而是 「upsert 」命令。它的功能为insert + update,与HBase中的put相对应。如果不存在则插入,否则更新。列表是可选的,如果不存在,值将按模式中声明的顺序映射到列。这些值必须计算为常量
语法:upsert into 表名(列蔟列名, xxxx, ) VALUES(XXX, XXX, XXX)
0: jdbc:phoenix:ops01,ops02,ops03:2181> UPSERT INTO ORDER_DTL VALUES('000001', '已提交', 4070, 1, '4944191', '2020-04-25 12:09:16', '手机'); 1 row affected (0.249 seconds)- 1
- 2
数据查询
与标准SQL一样,Phoenix也是使用select语句来实现数据的查询
0: jdbc:phoenix:ops01,ops02,ops03:2181> select * from ORDER_DTL; +---------+---------+---------+----------+----------+----------------------+-----------+ | ID | STATUS | MONEY | PAY_WAY | USER_ID | OPERATION_TIME | CATEGORY | +---------+---------+---------+----------+----------+----------------------+-----------+ | 000001 | 已提交 | 4070.0 | 1 | 4944191 | 2020-04-25 12:09:16 | 手机 | +---------+---------+---------+----------+----------+----------------------+-----------+ 1 row selected (0.162 seconds)- 1
- 2
- 3
- 4
- 5
- 6
- 7
数据更新
在Phoenix中,更新数据也是使用UPSERT。语法格式如下:
UPSERT INTO 表名(列名, …) VALUES(对应的值, …);
将ORDER_DTL表ID为’000001’的订单状态修改为已付款
0: jdbc:phoenix:ops01,ops02,ops03:2181> UPSERT INTO ORDER_DTL(ID, STATUS) VALUES ('000001', '已付款'); 1 row affected (0.014 seconds) 0: jdbc:phoenix:ops01,ops02,ops03:2181> select * from ORDER_DTL; +---------+---------+---------+----------+----------+----------------------+-----------+ | ID | STATUS | MONEY | PAY_WAY | USER_ID | OPERATION_TIME | CATEGORY | +---------+---------+---------+----------+----------+----------------------+-----------+ | 000001 | 已付款 | 4070.0 | 1 | 4944191 | 2020-04-25 12:09:16 | 手机 | +---------+---------+---------+----------+----------+----------------------+-----------+ 1 row selected (0.083 seconds) 0: jdbc:phoenix:ops01,ops02,ops03:2181>- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
条件查询
0: jdbc:phoenix:ops01,ops02,ops03:2181> UPSERT INTO ORDER_DTL VALUES('000002', '已提交', 8888, 1, '9988776', '2222-02-22 12:09:16', '激光枪'); 1 row affected (0.015 seconds) 0: jdbc:phoenix:ops01,ops02,ops03:2181> select * from ORDER_DTL; +---------+---------+---------+----------+----------+----------------------+-----------+ | ID | STATUS | MONEY | PAY_WAY | USER_ID | OPERATION_TIME | CATEGORY | +---------+---------+---------+----------+----------+----------------------+-----------+ | 000001 | 已付款 | 4070.0 | 1 | 4944191 | 2020-04-25 12:09:16 | 手机 | | 000002 | 已提交 | 8888.0 | 1 | 9988776 | 2222-02-22 12:09:16 | 激光枪 | +---------+---------+---------+----------+----------+----------------------+-----------+ 2 rows selected (0.08 seconds) 0: jdbc:phoenix:ops01,ops02,ops03:2181> SELECT * FROM ORDER_DTL WHERE "ID" = '000002'; +---------+---------+---------+----------+----------+----------------------+-----------+ | ID | STATUS | MONEY | PAY_WAY | USER_ID | OPERATION_TIME | CATEGORY | +---------+---------+---------+----------+----------+----------------------+-----------+ | 000002 | 已提交 | 8888.0 | 1 | 9988776 | 2222-02-22 12:09:16 | 激光枪 | +---------+---------+---------+----------+----------+----------------------+-----------+ 1 row selected (0.054 seconds) 0: jdbc:phoenix:ops01,ops02,ops03:2181> SELECT * FROM ORDER_DTL WHERE "OPERATION_TIME" > '2022-08-18 00:00:00'; +---------+---------+---------+----------+----------+----------------------+-----------+ | ID | STATUS | MONEY | PAY_WAY | USER_ID | OPERATION_TIME | CATEGORY | +---------+---------+---------+----------+----------+----------------------+-----------+ | 000002 | 已提交 | 8888.0 | 1 | 9988776 | 2222-02-22 12:09:16 | 激光枪 | +---------+---------+---------+----------+----------+----------------------+-----------+ 1 row selected (0.069 seconds)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
条件删除
0: jdbc:phoenix:ops01,ops02,ops03:2181> DELETE FROM ORDER_DTL WHERE "ID" = '000002'; 1 row affected (0.01 seconds) 0: jdbc:phoenix:ops01,ops02,ops03:2181> select * from ORDER_DTL; +---------+---------+---------+----------+----------+----------------------+-----------+ | ID | STATUS | MONEY | PAY_WAY | USER_ID | OPERATION_TIME | CATEGORY | +---------+---------+---------+----------+----------+----------------------+-----------+ | 000001 | 已付款 | 4070.0 | 1 | 4944191 | 2020-04-25 12:09:16 | 手机 | +---------+---------+---------+----------+----------+----------------------+-----------+ 1 row selected (0.057 seconds)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
导入测试数据(执行sql脚本)
使用phoenix自带的psql.py工具
# 编写sql测试数据 wangting@ops01:/home/wangting >cd /home/wangting/hbase/ wangting@ops01:/home/wangting/hbase >vim load_phoenix.sql UPSERT INTO "ORDER_DTL" VALUES('000002','已提交',4070,1,'4944191','2020-04-25 12:09:16','手机;'); UPSERT INTO "ORDER_DTL" VALUES('000003','已完成',4350,1,'1625615','2020-04-25 12:09:37','家用电器;;电脑;'); UPSERT INTO "ORDER_DTL" VALUES('000004','已提交',6370,3,'3919700','2020-04-25 12:09:39','男装;男鞋;'); UPSERT INTO "ORDER_DTL" VALUES('000005','已付款',6370,3,'3919700','2020-04-25 12:09:44','男装;男鞋;'); UPSERT INTO "ORDER_DTL" VALUES('000006','已提交',9380,1,'2993700','2020-04-25 12:09:41','维修;手机;'); UPSERT INTO "ORDER_DTL" VALUES('000007','已付款',9380,1,'2993700','2020-04-25 12:09:46','维修;手机;'); UPSERT INTO "ORDER_DTL" VALUES('000008','已完成',6400,2,'5037058','2020-04-25 12:10:13','数码;女装;'); UPSERT INTO "ORDER_DTL" VALUES('000009','已付款',280,1,'3018827','2020-04-25 12:09:53','男鞋;汽车;'); UPSERT INTO "ORDER_DTL" VALUES('000010','已完成',5600,1,'6489579','2020-04-25 12:08:55','食品;家用电器;'); UPSERT INTO "ORDER_DTL" VALUES('000011','已付款',5600,1,'6489579','2020-04-25 12:09:00','食品;家用电器;'); UPSERT INTO "ORDER_DTL" VALUES('000012','已提交',8340,2,'2948003','2020-04-25 12:09:26','男装;男鞋;'); UPSERT INTO "ORDER_DTL" VALUES('000013','已付款',8340,2,'2948003','2020-04-25 12:09:30','男装;男鞋;'); UPSERT INTO "ORDER_DTL" VALUES('000014','已提交',7060,2,'2092774','2020-04-25 12:09:38','酒店;旅游;'); UPSERT INTO "ORDER_DTL" VALUES('000015','已提交',640,3,'7152356','2020-04-25 12:09:49','维修;手机;'); UPSERT INTO "ORDER_DTL" VALUES('000016','已付款',9410,3,'7152356','2020-04-25 12:10:01','维修;手机;'); UPSERT INTO "ORDER_DTL" VALUES('000017','已提交',9390,3,'8237476','2020-04-25 12:10:08','男鞋;汽车;'); UPSERT INTO "ORDER_DTL" VALUES('000018','已提交',7490,2,'7813118','2020-04-25 12:09:05','机票;文娱;'); UPSERT INTO "ORDER_DTL" VALUES('000019','已付款',7490,2,'7813118','2020-04-25 12:09:06','机票;文娱;'); UPSERT INTO "ORDER_DTL" VALUES('000020','已付款',5360,2,'5301038','2020-04-25 12:08:50','维修;手机;'); UPSERT INTO "ORDER_DTL" VALUES('000021','已提交',5360,2,'5301038','2020-04-25 12:08:53','维修;手机;'); UPSERT INTO "ORDER_DTL" VALUES('000022','已取消',5360,2,'5301038','2020-04-25 12:08:58','维修;手机;'); UPSERT INTO "ORDER_DTL" VALUES('000023','已付款',6490,0,'3141181','2020-04-25 12:09:22','食品;家用电器;'); UPSERT INTO "ORDER_DTL" VALUES('000024','已付款',3820,1,'9054826','2020-04-25 12:10:04','家用电器;;电脑;'); UPSERT INTO "ORDER_DTL" VALUES('000025','已提交',4650,2,'5837271','2020-04-25 12:08:52','机票;文娱;'); UPSERT INTO "ORDER_DTL" VALUES('000026','已付款',4650,2,'5837271','2020-04-25 12:08:57','机票;文娱;'); wangting@ops01:/home/wangting/hbase >pwd /home/wangting/hbase wangting@ops01:/home/wangting/hbase >ls -l /home/wangting/hbase/load_phoenix.sql -rw-rw-r-- 1 wangting wangting 2773 Aug 18 09:19 /home/wangting/hbase/load_phoenix.sql # 如果配置了环境变量,执行时也可以不带全路径 wangting@ops01:/home/wangting >ls -l /opt/module/phoenix/bin/psql.py -rwxr-xr-x 1 wangting wangting 2739 Jun 27 2018 /opt/module/phoenix/bin/psql.py wangting@ops01:/home/wangting >/opt/module/phoenix/bin/psql.py /home/wangting/hbase/load_phoenix.sql SLF4J: Class path contains multiple SLF4J bindings. SLF4J: Found binding in [jar:file:/opt/module/phoenix/phoenix-5.0.0-HBase-2.0-client.jar!/org/slf4j/impl/StaticLoggerBinder.class] SLF4J: Found binding in [jar:file:/opt/module/hadoop-3.1.3/share/hadoop/common/lib/slf4j-log4j12-1.7.30.jar!/org/slf4j/impl/StaticLoggerBinder.class] SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanation. 22/08/18 09:24:01 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable 1 row upserted Time: 0.061 sec(s) 1 row upserted Time: 0.009 sec(s) ... ... ... 1 row upserted Time: 0.005 sec(s) # 进入phoenix命令行验证 wangting@ops01:/home/wangting > 0: jdbc:phoenix:ops01,ops02,ops03:2181> select * from ORDER_DTL; +---------+---------+---------+----------+----------+----------------------+------------+ | ID | STATUS | MONEY | PAY_WAY | USER_ID | OPERATION_TIME | CATEGORY | +---------+---------+---------+----------+----------+----------------------+------------+ | 000001 | 已付款 | 4070.0 | 1 | 4944191 | 2020-04-25 12:09:16 | 手机 | | 000002 | 已提交 | 4070.0 | 1 | 4944191 | 2020-04-25 12:09:16 | 手机; | | 000003 | 已完成 | 4350.0 | 1 | 1625615 | 2020-04-25 12:09:37 | 家用电器;;电脑; | | 000004 | 已提交 | 6370.0 | 3 | 3919700 | 2020-04-25 12:09:39 | 男装;男鞋; | | 000005 | 已付款 | 6370.0 | 3 | 3919700 | 2020-04-25 12:09:44 | 男装;男鞋; | | 000006 | 已提交 | 9380.0 | 1 | 2993700 | 2020-04-25 12:09:41 | 维修;手机; | | 000007 | 已付款 | 9380.0 | 1 | 2993700 | 2020-04-25 12:09:46 | 维修;手机; | | 000008 | 已完成 | 6400.0 | 2 | 5037058 | 2020-04-25 12:10:13 | 数码;女装; | | 000009 | 已付款 | 280.0 | 1 | 3018827 | 2020-04-25 12:09:53 | 男鞋;汽车; | | 000010 | 已完成 | 5600.0 | 1 | 6489579 | 2020-04-25 12:08:55 | 食品;家用电器; | | 000011 | 已付款 | 5600.0 | 1 | 6489579 | 2020-04-25 12:09:00 | 食品;家用电器; | | 000012 | 已提交 | 8340.0 | 2 | 2948003 | 2020-04-25 12:09:26 | 男装;男鞋; | | 000013 | 已付款 | 8340.0 | 2 | 2948003 | 2020-04-25 12:09:30 | 男装;男鞋; | | 000014 | 已提交 | 7060.0 | 2 | 2092774 | 2020-04-25 12:09:38 | 酒店;旅游; | | 000015 | 已提交 | 640.0 | 3 | 7152356 | 2020-04-25 12:09:49 | 维修;手机; | | 000016 | 已付款 | 9410.0 | 3 | 7152356 | 2020-04-25 12:10:01 | 维修;手机; | | 000017 | 已提交 | 9390.0 | 3 | 8237476 | 2020-04-25 12:10:08 | 男鞋;汽车; | | 000018 | 已提交 | 7490.0 | 2 | 7813118 | 2020-04-25 12:09:05 | 机票;文娱; | | 000019 | 已付款 | 7490.0 | 2 | 7813118 | 2020-04-25 12:09:06 | 机票;文娱; | | 000020 | 已付款 | 5360.0 | 2 | 5301038 | 2020-04-25 12:08:50 | 维修;手机; | | 000021 | 已提交 | 5360.0 | 2 | 5301038 | 2020-04-25 12:08:53 | 维修;手机; | | 000022 | 已取消 | 5360.0 | 2 | 5301038 | 2020-04-25 12:08:58 | 维修;手机; | | 000023 | 已付款 | 6490.0 | 0 | 3141181 | 2020-04-25 12:09:22 | 食品;家用电器; | | 000024 | 已付款 | 3820.0 | 1 | 9054826 | 2020-04-25 12:10:04 | 家用电器;;电脑; | | 000025 | 已提交 | 4650.0 | 2 | 5837271 | 2020-04-25 12:08:52 | 机票;文娱; | | 000026 | 已付款 | 4650.0 | 2 | 5837271 | 2020-04-25 12:08:57 | 机票;文娱; | +---------+---------+---------+----------+----------+----------------------+------------+ 26 rows selected (0.17 seconds)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
分页数据查询
使用limit和offset可以快速进行分页
limit表示每页多少条记录,offset表示从第几条记录开始查起
-- 第一页 select * from ORDER_DTL limit 10 offset 0; -- 第二页 -- offset从10开始 select * from ORDER_DTL limit 10 offset 10; -- 第三页 select * from ORDER_DTL limit 10 offset 20; # select * from ORDER_DTL limit 10 offset 0;当offset为不定义,默认为0开始 # 第一页数据 0: jdbc:phoenix:ops01,ops02,ops03:2181> select * from ORDER_DTL limit 10 offset 0; +---------+---------+---------+----------+----------+----------------------+------------+ | ID | STATUS | MONEY | PAY_WAY | USER_ID | OPERATION_TIME | CATEGORY | +---------+---------+---------+----------+----------+----------------------+------------+ | 000001 | 已付款 | 4070.0 | 1 | 4944191 | 2020-04-25 12:09:16 | 手机 | | 000002 | 已提交 | 4070.0 | 1 | 4944191 | 2020-04-25 12:09:16 | 手机; | | 000003 | 已完成 | 4350.0 | 1 | 1625615 | 2020-04-25 12:09:37 | 家用电器;;电脑; | | 000004 | 已提交 | 6370.0 | 3 | 3919700 | 2020-04-25 12:09:39 | 男装;男鞋; | | 000005 | 已付款 | 6370.0 | 3 | 3919700 | 2020-04-25 12:09:44 | 男装;男鞋; | | 000006 | 已提交 | 9380.0 | 1 | 2993700 | 2020-04-25 12:09:41 | 维修;手机; | | 000007 | 已付款 | 9380.0 | 1 | 2993700 | 2020-04-25 12:09:46 | 维修;手机; | | 000008 | 已完成 | 6400.0 | 2 | 5037058 | 2020-04-25 12:10:13 | 数码;女装; | | 000009 | 已付款 | 280.0 | 1 | 3018827 | 2020-04-25 12:09:53 | 男鞋;汽车; | | 000010 | 已完成 | 5600.0 | 1 | 6489579 | 2020-04-25 12:08:55 | 食品;家用电器; | +---------+---------+---------+----------+----------+----------------------+------------+ 10 rows selected (0.079 seconds) # 第二页数据 0: jdbc:phoenix:ops01,ops02,ops03:2181> select * from ORDER_DTL limit 10 offset 10; +---------+---------+---------+----------+----------+----------------------+-----------+ | ID | STATUS | MONEY | PAY_WAY | USER_ID | OPERATION_TIME | CATEGORY | +---------+---------+---------+----------+----------+----------------------+-----------+ | 000011 | 已付款 | 5600.0 | 1 | 6489579 | 2020-04-25 12:09:00 | 食品;家用电器; | | 000012 | 已提交 | 8340.0 | 2 | 2948003 | 2020-04-25 12:09:26 | 男装;男鞋; | | 000013 | 已付款 | 8340.0 | 2 | 2948003 | 2020-04-25 12:09:30 | 男装;男鞋; | | 000014 | 已提交 | 7060.0 | 2 | 2092774 | 2020-04-25 12:09:38 | 酒店;旅游; | | 000015 | 已提交 | 640.0 | 3 | 7152356 | 2020-04-25 12:09:49 | 维修;手机; | | 000016 | 已付款 | 9410.0 | 3 | 7152356 | 2020-04-25 12:10:01 | 维修;手机; | | 000017 | 已提交 | 9390.0 | 3 | 8237476 | 2020-04-25 12:10:08 | 男鞋;汽车; | | 000018 | 已提交 | 7490.0 | 2 | 7813118 | 2020-04-25 12:09:05 | 机票;文娱; | | 000019 | 已付款 | 7490.0 | 2 | 7813118 | 2020-04-25 12:09:06 | 机票;文娱; | | 000020 | 已付款 | 5360.0 | 2 | 5301038 | 2020-04-25 12:08:50 | 维修;手机; | +---------+---------+---------+----------+----------+----------------------+-----------+ 10 rows selected (0.063 seconds) # 第三页数据 0: jdbc:phoenix:ops01,ops02,ops03:2181> select * from ORDER_DTL limit 10 offset 20; +---------+---------+---------+----------+----------+----------------------+------------+ | ID | STATUS | MONEY | PAY_WAY | USER_ID | OPERATION_TIME | CATEGORY | +---------+---------+---------+----------+----------+----------------------+------------+ | 000021 | 已提交 | 5360.0 | 2 | 5301038 | 2020-04-25 12:08:53 | 维修;手机; | | 000022 | 已取消 | 5360.0 | 2 | 5301038 | 2020-04-25 12:08:58 | 维修;手机; | | 000023 | 已付款 | 6490.0 | 0 | 3141181 | 2020-04-25 12:09:22 | 食品;家用电器; | | 000024 | 已付款 | 3820.0 | 1 | 9054826 | 2020-04-25 12:10:04 | 家用电器;;电脑; | | 000025 | 已提交 | 4650.0 | 2 | 5837271 | 2020-04-25 12:08:52 | 机票;文娱; | | 000026 | 已付款 | 4650.0 | 2 | 5837271 | 2020-04-25 12:08:57 | 机票;文娱; | +---------+---------+---------+----------+----------+----------------------+------------+ 6 rows selected (0.061 seconds) 0: jdbc:phoenix:ops01,ops02,ops03:2181>- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
创建视图
0: jdbc:phoenix:ops01,ops02,ops03:2181> CREATE VIEW VIEW_ORDER_DTL AS SELECT * FROM ORDER_DTL; No rows affected (0.063 seconds) 0: jdbc:phoenix:ops01,ops02,ops03:2181> select count(*) from VIEW_ORDER_DTL; +-----------+ | COUNT(1) | +-----------+ | 26 | +-----------+ 1 row selected (0.047 seconds) 0: jdbc:phoenix:ops01,ops02,ops03:2181> select count(*) from ORDER_DTL; +-----------+ | COUNT(1) | +-----------+ | 26 | +-----------+ 1 row selected (0.015 seconds)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
指定分区压缩格式建表
# ===按条件建表=== # 按照用户ID来分区,一共4个分区。并指定数据的压缩格式为GZ create table if not exists ORDER_DTL_NEW( "id" varchar primary key, C1."status" varchar, C1."money" float, C1."pay_way" integer, C1."user_id" varchar, C1."operation_time" varchar, C1."category" varchar ) CONPRESSION='GZ' SPLIT ON ('3','5','7'); # 加盐指定数量分区并指定数据的压缩格式 create table if not exists ORDER_DTL_NEWWW( "id" varchar primary key, C1."status" varchar, C1."money" float, C1."pay_way" integer, C1."user_id" varchar, C1."operation_time" varchar, C1."category" varchar ) CONPRESSION='GZ', SALT_BUCKETS=10;- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
phoenix索引介绍
索引-全局索引
- 全局索引适用于读多写少业务
- 全局索引绝大多数负载都发生在写入时,当构建了全局索引时,Phoenix会拦截写入(DELETE、UPSERT值和UPSERT SELECT)上的数据表更新,构建索引更新,同时更新所有相关的索引表,开销较大
- 读取时,Phoenix将选择最快能够查询出数据的索引表。默认情况下,除非使用Hint,如果SELECT查询中引用了其他非索引列,该索引是不会生效的
- 全局索引一般和覆盖索引搭配使用,读的效率很高,但写入效率会受影响
创建语法:
CREATE INDEX 索引名称 ON 表名 (列名1, 列名2, 列名3...)- 1
索引-本地索引
- 本地索引适合写操作频繁,读相对少的业务
- 当使用SQL查询数据时,Phoenix会自动选择是否使用本地索引查询数据
- 在本地索引中,索引数据和业务表数据存储在同一个服务器上,避免写入期间的其他网络开销
- 在Phoenix 4.8.0之前,本地索引保存在一个单独的表中,在Phoenix 4.8.1中,本地索引的数据是保存在一个影子列蔟中
- 本地索引查询即使SELECT引用了非索引中的字段,也会自动应用索引的
- [注意]-创建表的时候指定了SALT_BUCKETS,是不支持本地索引的
创建语法:
CREATE local INDEX 索引名称 ON 表名 (列名1, 列名2, 列名3...)- 1
索引-覆盖索引
Phoenix提供了覆盖的索引,可以不需要在找到索引条目后返回到主表。Phoenix可以将关心的数据捆绑在索引行中,从而节省了读取时间的开销
例如,以下语法将在v1和v2列上创建索引,并在索引中包括v3列,也就是通过v1、v2就可以直接把数据查询出来。
创建语法:
CREATE INDEX my_index ON my_table (v1,v2) INCLUDE(v3)- 1
索引-函数索引
函数索引(4.3和更高版本)可以支持在列上创建索引,还可以基于任意表达式上创建索引。然后,当查询使用该表达式时,可以使用索引来检索结果,而不是数据表。例如,可以在UPPER(FIRST_NAME||‘ ’||LAST_NAME)上创建一个索引,这样将来搜索两个名字拼接在一起时,索引依然可以生效
创建语法:
-- 创建索引 CREATE INDEX UPPER_NAME_IDX ON EMP (UPPER(FIRST_NAME||' '||LAST_NAME)) -- 以下查询会走索引 SELECT EMP_ID FROM EMP WHERE UPPER(FIRST_NAME||' '||LAST_NAME)='JOHN DOE'- 1
- 2
- 3
- 4
HBase工作机制
hbase读取数据流程
- 客户端拿到一个rowkey(首先得要知道这个rowkey存在哪个region中)
- 根据zk获取hbase:meta表,这个表中存放了region的信息,根据namespace、表名,就可以根据rowkey查看是否匹配某个region的startkey、endkey,返回region的信息
- 还需要查询region是在哪个HRegionServer(因为我们是不知道region会在存在什么地方的)
- 读取Store
- 优先读取写缓存(MemStore)
- 读取BlockCache(LRUBlockCache、BucketBlockCache)
- 再读取HFile
hbase数据存储流程
HBase的数据存储过程是分为几个阶段的。写入的过程与HBase的LSM结构对应。
-
为了提高HBase的写入速度,数据都是先写入到MemStore(内存)结构中,V2.0 MemStore也会进行Compaction
-
MemStore写到一定程度(默认128M),由后台程序将MemStore的内容flush刷写到HDFS中的StoreFile
-
数据量较大时,会产生很多的StoreFile。这样对高效读取不利,HBase会将这些小的StoreFile合并,一般3-10个文件合并成一个更大的StoreFile
写入MemStore
- Client访问zookeeper,从ZK中找到meta表的region位置
- 读取meta表中的数据,根据namespace、表名、rowkey获取对应的Region信息
- 通过刚刚获取的地址访问对应的RegionServer,拿到对应的表存储的RegionServer
- 去表所在的RegionServer进行数据的添加
- 查找对应的region,在region中寻找列族,先向MemStore中写入数据
MemStore溢写合并
- 当MemStore写入的值变多,触发溢写操作(flush),进行文件的溢写,成为一个StoreFile
- 当溢写的文件过多时,会触发文件的合并(Compact)操作,合并有两种方式(major,minor)
- 一旦MemStore达到128M时,则触发Flush溢出(Region级别)
- MemStore的存活时间超过1小时(默认),触发Flush溢写(RegionServer级别)
In-memory合并
In-memory合并是HBase 2.0之后添加的。它与默认的MemStore的区别:实现了在内存中进行compaction(合并)。
在CompactingMemStore中,数据是以段(Segment)为单位存储数据的。MemStore包含了多个segment- 当数据写入时,首先写入到的是Active segment中(也就是当前可以写入的segment段)
- 在2.0之前,如果MemStore中的数据量达到指定的阈值时,就会将数据flush到磁盘中的一个StoreFile
- 2.0的In-memory compaction,active segment满了后,将数据移动到pipeline中。这个过程跟以前不一样,以前是flush到磁盘,而这次是将Active segment的数据,移到称为pipeline的内存当中。一个pipeline中可以有多个segment。而In-memory compaction会将pipeline的多个segment合并为更大的、更紧凑的segment,这就是compaction
- HBase会尽量延长CompactingMemStore的生命周期,以达到减少总的IO开销。当需要把CompactingMemStore flush到磁盘时,pipeline中所有的segment会被移动到一个snapshot中,然后进行合并后写入到HFile
StoreFile合并
- 当MemStore超过阀值的时候,就要flush到HDFS上生成一个StoreFile。因此随着不断写入,HFile的数量将会越来越多,根据前面所述,StoreFile数量过多会降低读性能
- 为了避免对读性能的影响,需要对这些StoreFile进行compact操作,把多个HFile合并成一个HFile
- compact操作需要对HBase的数据进行多次的重新读写,因此这个过程会产生大量的IO。可以看到compact操作的本质就是以IO操作换取后续的读性能的提高
Region管理
region分配
- 任何时刻,一个region只能分配给一个region server
- Master记录了当前有哪些可用的region server,以及当前哪些region分配给了哪些region server,哪些region还没有分配。当需要分配的新的region,并且有一个region server上有可用空间时,master就给这个region server发送一个装载请求,把region分配给这个region server。region server得到请求后,就开始对此region提供服务。
region server上线
- Master使用ZooKeeper来跟踪region server状态
- 当某个region server启动时
- 首先在zookeeper上的server目录下建立代表自己的znode
- 由于Master订阅了server目录上的变更消息,当server目录下的文件出现新增或删除操作时,master可以得到来自zookeeper的实时通知
- 一旦region server上线,master能马上得到消息
region server下线
- 当region server下线时,它和zookeeper的会话断开,ZooKeeper而自动释放代表这台server的文件上的独占锁
- Master即可以确定
- region server和zookeeper之间的网络断开
- region server挂掉
- 无论哪种情况,region server都无法继续为它的region提供服务了,此时master会删除server目录下代表这台region server的znode数据,并将这台region server的region分配给其它还活着的节点
region分裂
- 当region中的数据逐渐变大之后,达到某一个阈值,会进行裂变
- 一个region等分为两个region,并分配到不同的RegionServer
- 原本的Region会下线,新Split出来的两个Region会被HMaster分配到相应的HRegionServer上,使得原先1个Region的压力得以分流到2个Region上
- HBase只是增加数据,所有的更新和删除操作,都是在Compact阶段做的
- 用户写操作只需要进入到内存即可立即返回,从而保证I/O高性能读写
自动分区
- 如果初始时R=1,那么Min(128MB,10GB)=128MB,也就是说在第一个flush的时候就会触发分裂操作
- 当R=2的时候Min(22128MB,10GB)=512MB ,当某个store file大小达到512MB的时候,就会触发分裂
- 如此类推,当R=9的时候,store file 达到10GB的时候就会分裂,也就是说当R>=9的时候,store file 达到10GB的时候就会分裂
- split 点都位于region中row key的中间点
手动分区
在创建表的时候,就可以指定表分为多少个Region。默认一开始的时候系统会只向一个RegionServer写数据,系统不指定startRow和endRow,可以在运行的时候提前Split,提高并发写入
Master工作机器
master上线
Master启动进行以下步骤:
- 从zookeeper上获取唯一一个代表active master的锁,用来阻止其它master成为master
- 一般hbase集群中总是有一个master在提供服务,还有一个以上的‘master’在等待时机抢占它的位置。
- 扫描zookeeper上的server父节点,获得当前可用的region server列表
- 和每个region server通信,获得当前已分配的region和region server的对应关系
- 扫描.META.region的集合,计算得到当前还未分配的region,将他们放入待分配region列表
master下线
- 由于master只维护表和region的元数据,而不参与表数据IO的过程,master下线仅导致所有元数据的修改被冻结
- 无法创建删除表
- 无法修改表的schema
- 无法进行region的负载均衡
- 无法处理region 上下线
- 无法进行region的合并
- 唯一例外的是region的split可以正常进行,因为只有region server参与
- 表的数据读写还可以正常进行
- 因此master下线短时间内对整个hbase集群没有影响
- 从上线过程可以看到,master保存的信息全是可以冗余信息(都可以从系统其它地方收集到或者计算出来)
HBase常规优化
每个集群会有系统配置,社区一定会把一些通用的、适应性强的作为默认配置,有很多都是折中的配置。很多时候,出现问题的时候,我们要考虑优化。
- 通用优化
- 跟硬件有一定的关系,SSD、RAID(给NameNode使用RAID1架构,可以有一定容错能力)
- 操作系统优化
- 最大的开启文件数量(集群规模大之后,写入的速度很快,经常要Flush,会在操作系统上同时打开很多的文件读取)
- 最大允许开启的进程
- HDFS优化
- 副本数
- RPC的最大数量
- 开启的线程数
- HBase优化
- 配置StoreFile大小
- 预分区
- 数据压缩
- 设计ROWKEY
- 开启BLOOMFILER
- 2.X开启In-memory Compaction
- …
- JVM
- 调整堆内存大小
- 调整GC,并行GC,缩短GC的时间
-
相关阅读:
Android_一如何获取linux中的可执行文件指令之Termux使用介绍
基于5G边缘网关的储能在线监测方案
Matlab实现遗传算法仿真(附上20个仿真源码)
软件测试基本概念
基于JavaSwing开发文件传输与聊天系统 课程设计 大作业 毕业设计
SwiftUI SQLite教程之了解如何在 SwiftUI 中使用 SQLite 数据库并执行 CRUD 操作(教程含源码)
辽宁2022农民丰收节 国稻种芯:4个主会场31个分会场同步
做一个能对标阿里云的前端APM工具(上)
uniapp表单验证
多模态 —— Learnable pooling with Context Gating for video classification
- 原文地址:https://blog.csdn.net/wt334502157/article/details/126404162
