-
Spring Boot 引起的“堆外内存泄漏”排查及经验总结
背景
为了更好地实现对项目的管理,我们将组内一个项目迁移到MDP框架(基于Spring Boot),随后我们就发现系统会频繁报出Swap区域使用量过高的异常。笔者被叫去帮忙查看原因,发现配置了4G堆内内存,但是实际使用的物理内存竟然高达7G,确实不正常。JVM参数配置是“-XX:MetaspaceSize=256M -XX:MaxMetaspaceSize=256M -XX:+AlwaysPreTouch -XX:ReservedCodeCacheSize=128m -XX:InitialCodeCacheSize=128m, -Xss512k -Xmx4g -Xms4g,-XX:+UseG1GC -XX:G1HeapRegionSize=4M”,实际使用的物理内存如下图所示:

top命令显示的内存情况
堆外内存泄漏排查
直接内存:指的是Java应用程序通过直接方式从操作系统中申请的内存,也叫堆外内存,因为这些对象分配在Java虚拟机的堆(严格来说,应该是JVM的内存外,但是堆是这块内存中最大的)以外。
直接内存有哪些?
- 元空间。
- BIO中ByteBuffer分配的直接内存。
- 使用Java的Unsafe类做一些分配本地内存的操作。
- JNI或者JNA程序,直接操纵了本地内存,比如一些加密库、压缩解压等。
JNI(Java Native Interface):通过使用Java本地接口(C或者C++)书写程序,可以确保代码在不同的平台上方便移植。
JNA(Java Native Access):提供一组Java工具类用于在运行期间动态访问系统本地库(native library:如 Window 的 dll)而不需要编写任何Native/JNI代码。开发人员只要在一个java接口中描述目标native library的函数与结构,JNA将自动实现Java接口到native function的映射。
JNA是建立在JNI技术基础之上的一个Java类库,它使您可以方便地使用java直接访问动态链接库中的函数。原来使用JNI,你必须手工用C写一个动态链接库,在C语言中映射Java的数据类型。而在JNA中,它提供了一个动态的C语言编写的转发器,可以自动实现Java和C的数据类型映射,你不再需要编写C动态链接库。也许这也意味着,使用JNA技术比使用JNI技术调用动态链接库会有些微的性能损失。但总体影响不大,因为JNA也避免了JNI的一些平台配置的开销。
直接内存的优缺点
直接内存,其实就是不受JVM控制的内存。相比于堆内存有几个优势:
- 减少了垃圾回收的工作,因为垃圾回收会暂停其他的工作,能保持一个较小的堆内内存,以减少垃圾收集对应用的影响。
- 加快了复制的速度。因为堆内在flush到远程时,会先复制到直接内存(非堆内存),然后再发送,而堆外内存相当于省略掉了这个工作。
- 可以在进程间共享,减少JVM间的对象复制,使得JVM的分割部署更容易实现。
- 可以扩展至更大的内存空间,比如超过1TB甚至比主存还大的空间。
直接内存有很多好处,我们还是应该要了解它的缺点:
- 堆外内存难以控制,如果内存泄漏,那么很难排查。
- 堆外内存相对来说,不适合存储很复杂的对象,一般简单的对象比较适合。
排查过程
1. 使用Java层面的工具定位内存区域(堆内内存、Code区域或者使用unsafe.allocateMemory和DirectByteBuffer申请的堆外内存)
笔者在项目中添加
-XX:NativeMemoryTracking=detailJVM参数重启项目,使用命令jcmd pid VM.native_memory detail查看到的内存分布如下:
jcmd显示的内存情况
发现命令显示的committed的内存小于物理内存,因为jcmd命令显示的内存包含堆内内存、Code区域、通过unsafe.allocateMemory和DirectByteBuffer申请的内存,但是不包含其他Native Code(C代码)申请的堆外内存。所以猜测是使用Native Code申请内存所导致的问题。
为了防止误判,笔者使用了pmap查看内存分布,发现大量的64M的地址;而这些地址空间不在jcmd命令所给出的地址空间里面,基本上就断定就是这些64M的内存所导致。

pmap显示的内存情况
2. 使用系统层面的工具定位堆外内存
因为笔者已经基本上确定是Native Code所引起,而Java层面的工具不便于排查此类问题,只能使用系统层面的工具去定位问题。
首先,使用了gperftools去定位问题
gperftools的使用方法可以参考gperftools:
https://github.com/gperftools/gperftools,gperftools的监控如下:
gperftools监控
从上图可以看出:使用malloc申请的的内存最高到3G之后就释放了,之后始终维持在700M-800M。笔者第一反应是:难道Native Code中没有使用malloc申请,直接使用mmap/brk申请的?(gperftools原理就使用动态链接的方式替换了操作系统默认的内存分配器(glibc)。)
然后,使用strace去追踪系统调用
因为使用gperftools没有追踪到这些内存,于是直接使用命令“strace -f -e”brk,mmap,munmap” -p pid”追踪向OS申请内存请求,但是并没有发现有可疑内存申请。strace监控如下图所示:

strace监控
接着,使用GDB去dump可疑内存
因为使用strace没有追踪到可疑内存申请;于是想着看看内存中的情况。就是直接使用命令
gdp -pid pid进入GDB之后,然后使用命令dump memory mem.bin startAddress endAddressdump内存,其中startAddress和endAddress可以从/proc/pid/smaps中查找。然后使用strings mem.bin查看dump的内容,如下:
gperftools监控
从内容上来看,像是解压后的JAR包信息。读取JAR包信息应该是在项目启动的时候,那么在项目启动之后使用strace作用就不是很大了。所以应该在项目启动的时候使用strace,而不是启动完成之后。
再次,项目启动时使用strace去追踪系统调用
项目启动使用strace追踪系统调用,发现确实申请了很多64M的内存空间,截图如下:

strace监控
使用该mmap申请的地址空间在pmap对应如下:
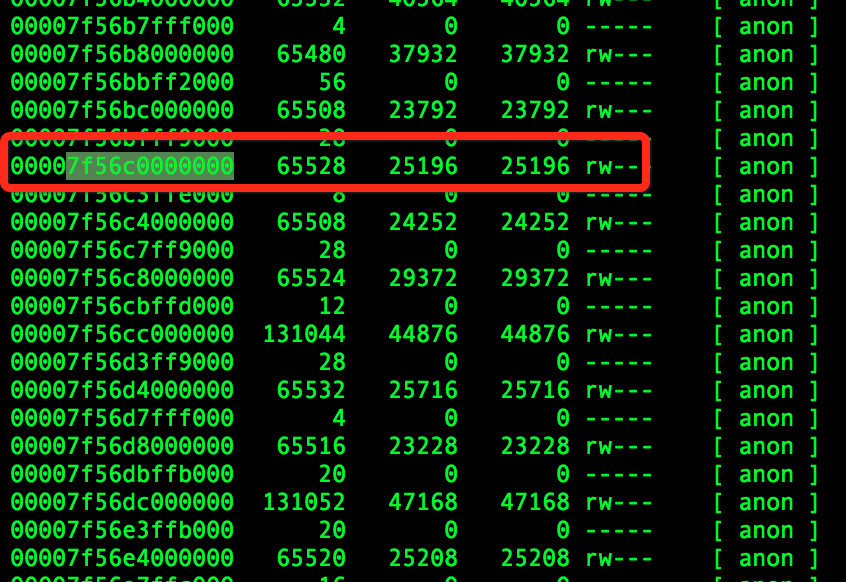
strace申请内容对应的pmap地址空间
最后,使用jstack去查看对应的线程
因为strace命令中已经显示申请内存的线程ID。直接使用命令
jstack pid去查看线程栈,找到对应的线程栈(注意10进制和16进制转换)如下: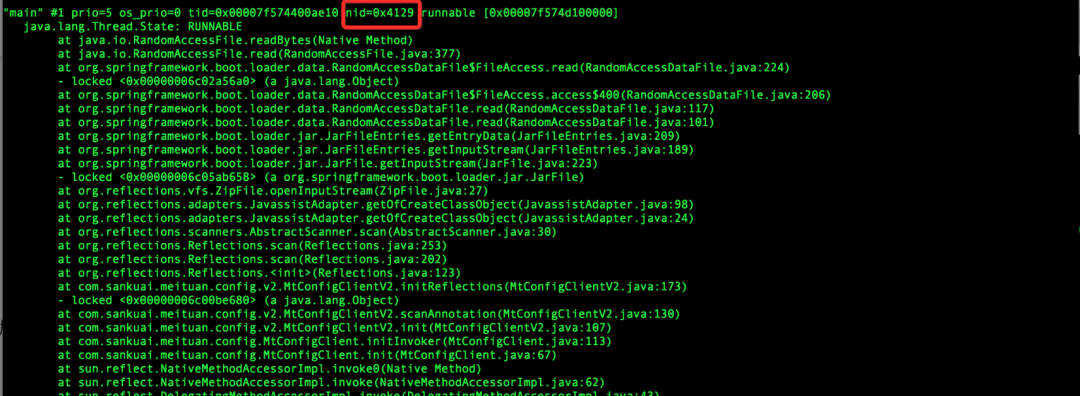
strace申请空间的线程栈
这里基本上就可以看出问题来了:MCC(美团统一配置中心)使用了Reflections进行扫包,底层使用了Spring Boot去加载JAR。因为解压JAR使用Inflater类,需要用到堆外内存,然后使用Btrace去追踪这个类,栈如下:

btrace追踪栈
然后查看使用MCC的地方,发现没有配置扫包路径,默认是扫描所有的包。于是修改代码,配置扫包路径,发布上线后内存问题解决。
3. 为什么堆外内存没有释放掉呢?
虽然问题已经解决了,但是有几个疑问:
-
为什么使用旧的框架没有问题?
-
为什么堆外内存没有释放?
-
为什么内存大小都是64M,JAR大小不可能这么大,而且都是一样大?
-
为什么gperftools最终显示使用的的内存大小是700M左右,解压包真的没有使用malloc申请内存吗?
带着疑问,笔者直接看了一下Spring Boot Loader:
https://github.com/spring-projects/spring-boot/tree/master/spring-boot-project/spring-boot-tools/spring-boot-loader/src/main/java/org/springframework/boot/loader那一块的源码。发现Spring Boot对Java JDK的InflaterInputStream进行了包装并且使用了Inflater,而Inflater本身用于解压JAR包的需要用到堆外内存。而包装之后的类ZipInflaterInputStream没有释放Inflater持有的堆外内存。于是笔者以为找到了原因,立马向Spring Boot社区反馈了这个bug:https://github.com/spring-projects/spring-boot/issues/13935。但是反馈之后,笔者就发现Inflater这个对象本身实现了finalize方法,在这个方法中有调用释放堆外内存的逻辑。也就是说Spring Boot依赖于GC释放堆外内存。笔者使用jmap查看堆内对象时,发现已经基本上没有Inflater这个对象了。于是就怀疑GC的时候,没有调用finalize。带着这样的怀疑,笔者把Inflater进行包装在Spring Boot Loader里面替换成自己包装的Inflater,在finalize进行打点监控,结果finalize方法确实被调用了。于是笔者又去看了Inflater对应的C代码,发现初始化的使用了malloc申请内存,end的时候也调用了free去释放内存。
此刻,笔者只能怀疑free的时候没有真正释放内存,便把Spring Boot包装的InflaterInputStream替换成Java JDK自带的,发现替换之后,内存问题也得以解决了。
这时,再返过来看gperftools的内存分布情况,发现使用Spring Boot时,内存使用一直在增加,突然某个点内存使用下降了好多(使用量直接由3G降为700M左右)。这个点应该就是GC引起的,内存应该释放了,但是在操作系统层面并没有看到内存变化,那是不是没有释放到操作系统,被内存分配器持有了呢?
继续探究,发现系统默认的内存分配器(glibc 2.12版本)和使用gperftools内存地址分布差别很明显,2.5G地址使用smaps发现它是属于Native Stack。内存地址分布如下:

gperftools显示的内存地址分布
到此,基本上可以确定是内存分配器在捣鬼;搜索了一下glibc 64M,发现glibc从2.11开始对每个线程引入内存池(64位机器大小就是64M内存),原文如下:

glib内存池说明
按照文中所说去修改MALLOC_ARENA_MAX环境变量,发现没什么效果。查看tcmalloc(gperftools使用的内存分配器)也使用了内存池方式。
为了验证是内存池搞的鬼,笔者就简单写个不带内存池的内存分配器。使用命令
gcc zjbmalloc.c -fPIC -shared -o zjbmalloc.so生成动态库,然后使用export LD_PRELOAD=zjbmalloc.so替换掉glibc的内存分配器。其中代码Demo如下:- #include
- #include
- #include
- #include
- //作者使用的64位机器,sizeof(size_t)也就是sizeof(long)
- void* malloc ( size_t size )
- {
- long* ptr = mmap( 0, size + sizeof(long), PROT_READ | PROT_WRITE, MAP_PRIVATE | MAP_ANONYMOUS, 0, 0 );
- if (ptr == MAP_FAILED) {
- return NULL;
- }
- *ptr = size; // First 8 bytes contain length.
- return (void*)(&ptr[1]); // Memory that is after length variable
- }
- void *calloc(size_t n, size_t size) {
- void* ptr = malloc(n * size);
- if (ptr == NULL) {
- return NULL;
- }
- memset(ptr, 0, n * size);
- return ptr;
- }
- void *realloc(void *ptr, size_t size)
- {
- if (size == 0) {
- free(ptr);
- return NULL;
- }
- if (ptr == NULL) {
- return malloc(size);
- }
- long *plen = (long*)ptr;
- plen--; // Reach top of memory
- long len = *plen;
- if (size <= len) {
- return ptr;
- }
- void* rptr = malloc(size);
- if (rptr == NULL) {
- free(ptr);
- return NULL;
- }
- rptr = memcpy(rptr, ptr, len);
- free(ptr);
- return rptr;
- }
- void free (void* ptr )
- {
- if (ptr == NULL) {
- return;
- }
- long *plen = (long*)ptr;
- plen--; // Reach top of memory
- long len = *plen; // Read length
- munmap((void*)plen, len + sizeof(long));
- }
通过在自定义分配器当中埋点可以发现其实程序启动之后应用实际申请的堆外内存始终在700M-800M之间,gperftools监控显示内存使用量也是在700M-800M左右。但是从操作系统角度来看进程占用的内存差别很大(这里只是监控堆外内存)。
笔者做了一下测试,使用不同分配器进行不同程度的扫包,占用的内存如下:
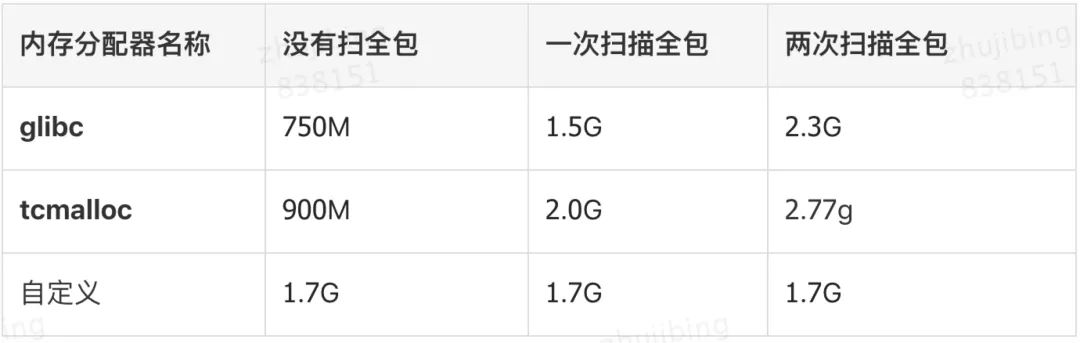
内存测试对比
为什么自定义的malloc申请800M,最终占用的物理内存在1.7G呢?
因为自定义内存分配器采用的是mmap分配内存,mmap分配内存按需向上取整到整数个页,所以存在着巨大的空间浪费。通过监控发现最终申请的页面数目在536k个左右,那实际上向系统申请的内存等于512k * 4k(pagesize) = 2G。为什么这个数据大于1.7G呢?
因为操作系统采取的是延迟分配的方式,通过mmap向系统申请内存的时候,系统仅仅返回内存地址并没有分配真实的物理内存。只有在真正使用的时候,系统产生一个缺页中断,然后再分配实际的物理Page。
总结

流程图
整个内存分配的流程如上图所示。MCC扫包的默认配置是扫描所有的JAR包。在扫描包的时候,Spring Boot不会主动去释放堆外内存,导致在扫描阶段,堆外内存占用量一直持续飙升。当发生GC的时候,Spring Boot依赖于finalize机制去释放了堆外内存;但是glibc为了性能考虑,并没有真正把内存归返到操作系统,而是留下来放入内存池了,导致应用层以为发生了“内存泄漏”。所以修改MCC的配置路径为特定的JAR包,问题解决。笔者在发表这篇文章时,发现Spring Boot的最新版本(2.0.5.RELEASE)已经做了修改,在ZipInflaterInputStream主动释放了堆外内存不再依赖GC;所以Spring Boot升级到最新版本,这个问题也可以得到解决。
-
相关阅读:
few shot目标检测survey paper笔记(迁移学习)
MySQL高级篇4
UVa129 Krypton Factor(困难的串)
26 JavaScript模块
面了三十个人,说说我的真实感受
python包合集-shutil
Dragonfly 中 P2P 传输协议优化
iPhone 15 Pro有5项重大设计升级,让iPhone 15看起来很无聊
最近带着江苏高校的学生做软件测试项目实战
数据链路层-------以太网协议
- 原文地址:https://blog.csdn.net/qq_45637260/article/details/126400103
