-
OGG|使用 OGG12.3 同步 Oracle 部分表到 Kafka

作者 | JiekeXu
来源 |公众号 JiekeXu DBA之路(ID: JiekeXu_IT)
如需转载请联系授权 | (个人微信 ID:JiekeXu_DBA)
大家好,我是 JiekeXu,很高兴又和大家见面了,今天和大家一起来学习使用 OGG12.3 同步 Oracle 部分表到 Kafka,欢迎点击上方蓝字关注我,标星或置顶,更多干货第一时间到达!
说 明:源端 Oracle 数据库版本 19c, ogg 19.1 源端也可以是 11.2.0.4 db,ogg 版本 12.3.0.1.2
目标端:Kafka 版本 kafka_2.11-2.0.0(本次不涉及) ogg for bigdata 12.3.2.1.1- --源端 version
- Oracle GoldenGate Command Interpreter for Oracle
- Version 19.1.0.0.4 OGGCORE_19.1.0.0.0_PLATFORMS_191017.1054_FBO
- Linux, x64, 64bit (optimized), Oracle 19c on Oct 17 2019 21:16:29
- Operating system character set identified as US-ASCII.
- Copyright (C) 1995, 2019, Oracle and/or its affiliates. All rights reserved.
- --目标端 version
- Oracle GoldenGate for Big Data Version 12.3.2.1.1 (Build 005) 依赖 jdk 1.8 及以上版本,故需安装 JDK
- Oracle GoldenGate for Big Data
- Version 12.3.2.1.1 (Build 005)
支持的 Kafka 版本

OGG 12.3.2.1 已停止支持 Kafka 版本 0.8.2.2、0.8.2.1 和 0.8.2.0。这允许在 Kafka 生产者上执行刷新调用,从而为流控制和检查点提供更好的支持。
一、安装 ogg
源端 ogg 安装和普通 ogg 安装一样,这里不在介绍,如果有需要请点击链接查看前面文章说明。目标端 ogg 有所区别,一定要下载安装 Oracle GoldenGate for Big Data 相关版本,官网已经看不到 12.3.2.1 的版本了,不过也可以下载 19.1 或者 21.3 版本的 OGG for bigdata,当然也可以到 http://edelivery.oracle.com 网站去下载历史版本。


安装 JDK1.8
Oracle GoldenGate for Big Data 已通过 Java 1.8 认证。在安装和运行 Oracle GoldenGate for Big Data 之前,您必须安装 Java(JDK 或 JRE)1.8 或更高版本。可以使用 Java 运行时环境 (JRE) 或完整的 Java 开发工具包(包括 JRE)。- export JAVA_HOME=/opt/jdk1.8
- export PATH=$JAVA_HOME/bin:$PATH
- export LD_LIBRARY_PATH=$JAVA_HOME/jre/lib/i386/server:$LD_LIBRARY_PATH
在上面的示例中,目录 $JAVA_HOME/jre/lib/i386/server 应该包含 libjvm.so 和 libjsig.so 文件。包含 JVM 库的实际目录取决于操作系统以及是否使用 64 位 JVM。
上传软件包
OGG_BigData_Linux_x64_12.3.2.1.1.zip,java.tar.gz,文章中所涉及到的 12.3 的 OGG 相关软件,如有需要可在公众号后台回复【OGG12.3】获取。
- unzip OGG_BigData_Linux_x64_12.3.2.1.1.zip
- tar -xvf OGG_BigData_Linux_x64_12.3.2.1.1.tar
- ./ggsci
- ./ggsci: error while loading shared libraries: libjvm.so: cannot open shared object file: No such file or directory
- --ggsci 命令报错,提示找不到 libjvm.so 文件,需要安装配置 java 路径,前期的 OGG 版本暂时还未集成 java 需要单独安装。
安装 java 配置环境变量- cd /home/oracle/java1.8
- tar -xvf java.tar.gz
- tree -L 2 java
- java
- `-- jdk1.8.0_181
- |-- bin
- |-- COPYRIGHT
- |-- include
- |-- javafx-src.zip
- |-- jre
- |-- lib
- |-- LICENSE
- |-- man
- |-- README.html
- |-- release
- |-- src.zip
- |-- THIRDPARTYLICENSEREADME-JAVAFX.txt
- `-- THIRDPARTYLICENSEREADME.txt
- --配置环境变量
- vi .bash_profile
- export JAVA_HOME=/home/oracle/java1.8/java/jdk1.8.0_181/
- export PATH=$JAVA_HOME/bin:$PATH
- export LD_LIBRARY_PATH=$JAVA_HOME/jre/lib/amd64/server:$LD_LIBRARY_PATH
- source .bash_profile
启动目标端 ogg
mgr 进程- Oracle GoldenGate for Big Data
- Version 12.3.2.1.1 (Build 005)
- Oracle GoldenGate Command Interpreter
- Version 12.3.0.1.2 OGGCORE_OGGADP.12.3.0.1.2_PLATFORMS_180712.2305
- Linux, x64, 64bit (optimized), Generic on Jul 13 2018 00:46:09
- Operating system character set identified as US-ASCII.
- Copyright (C) 1995, 2018, Oracle and/or its affiliates. All rights reserved.
- Shell> ./ggsci
- GGSCI> CREATE SUBDIRS
- -- 编辑 MGR 配置文件
- GGSCI> EDIT PARAM MGR
- PORT 7809
- DYNAMICPORTLIST 7810-7829
- AUTORESTART EXTRACT *,RETRIES 5,WAITMINUTES 3
- PURGEOLDEXTRACTS ./dirdat/*,usecheckpoints, minkeepdays 30
- GGSCI>START MGR
- GGSCI>INFO MGR
二、配置 ogg
源端配置 ogg
- --MGR 参数如下
- GGSCI> view params mgr
- PORT 7809
- DYNAMICPORTLIST 7710-7729
- AUTOSTART EXTRACT *
- PURGEOLDEXTRACTS /ogg19c/dirdat/*,usecheckpoints, minkeepdays 15
- Lagcriticalminutes 60
- ACCESSRULE, PROG *, IPADDR 192.*.*.*, ALLOW
- GGSCI> start mgr
配置捕获投递进程
- GGSCI> add extract ext1, TRANLOG, BEGIN NOW, THREADS 2
- GGSCI> add exttrail /ogg19c/dirdat/dw, extract ext1, megabytes 100
- GGSCI> edit params ext1
- extract ext1
- setenv (NLS_LANG="AMERICAN_AMERICA.AL32UTF8")
- userid ogg@DW, password ogg
- TRANLOGOPTIONS DBLOGREADER
- exttrail /ogg19c/dirdat/dw ,FORMAT RELEASE 12.2
- discardfile /ogg19c/dirrpt/ext1.dsc, append, MEGABYTES 1024
- --DDL EXCLUDE ALL
- statoptions reportfetch
- reportrollover at 08:30
- GETUPDATEBEFORES
- NOCOMPRESSDELETES
- NOCOMPRESSUPDATES
- TABLE ODSOR.T_MON_DOCDATUM;
- GGSCI> start ext1
注意的两点:1.“FORMAT RELEASE 12.2” 指定 trail 文件格式的版本,可选的版本有
values (10.4|11.1|11.2|12.1|12.2|12.3|18.1|19.1) for [release]
但是,当数据库为 19c OGG 为 19.1 时只能选择最低版本为 12.2,不能选择 11.2,在 11g 数据库和 OGG 12.3 中可以选择 11.2。
2.从 Oracle 同步数据到 Kafka 时不支持 DDL,故源端 DDL 变更不会同步到目标端,也不需要配置 DDL 相关捕获,DDL 相关参数也不需要配置。Only the TRUNCATE TABLE DDL statement is supported. All other DDL statements are ignored.
You can use the TRUNCATE statements one of these ways:
In a DDL statement, TRUNCATE TABLE, ALTER TABLE TRUNCATE PARTITION, and other DDL TRUNCATE statements. This uses the DDL parameter.
Standalone TRUNCATE support, which just has TRUNCATE TABLE. This uses the GETTRUNCATES parameter.
注意:只支持 TRUNCATE TABLE DDL 语句。所有其他 DDL 语句将被忽略。
使用 TRUNCATE 语句的方式如下:
在 DDL 语句中,TRUNCATE TABLE, ALTER TABLE TRUNCATE PARTITION,以及其他 DDL TRUNCATE 语句。
独立的 TRUNCATE 支持,它只有 TRUNCATE TABLE。它使用 GETTRUNCATES 参数。添加投递进程
- GGSCI> add extract dpe1, exttrailsource /ogg19c/dirdat/dw
- GGSCI> add rmttrail /soft/dirdat/dw, EXTRACT dpe1, MEGABYTES 1024
- GGSCI> edit params dpe1
- extract dpe1
- setenv (NLS_LANG="AMERICAN_AMERICA.AL32UTF8")
- rmthost 192.168.27.15,mgrport 7809,compress
- rmttrail /soft/dirdat/dw,format release 12.2
- --dynamicresolution
- passthru
- numfiles 3000
- TABLE ODSOR.T_MON_DOCDATUM;
- GGSCI> start dpe1
然后需要对同步的表添加补充日志,一般通过登录 OGG 添加即可,不过,业务对于 Kafka 端的要求开启全部列的补充日志。
- add trandata ODSOR.T_MON_DOCDATUM
- info trandata ODSOR.T_MON_DOCDATUM
- --使用 SQL 命令手动添加主键补全日志
- alter table ODSOR.T_MON_DOCDATUM add supplemental log data (primary key) columns;
- --使用 SQL 命令手动添加所有列补全日志,在日志中补全所有字段(排除 LOB 和 LONG 类型)
- alter table ODSOR.T_MON_DOCDATUM add supplemental log data (all) columns;
- --使用 SQL 命令手动删除补全日志
- alter table ODSOR.T_MON_DOCDATUM drop supplemental log data (all) columns;
- ---关闭补全日志
- alter database drop supplemental log data (primary key,unique index) columns;
- ---重新开启补全日志
- alter database add supplemental log data (primary key,unique index) columns;
goldengate.def 表结构定义文件
在 ogg for bigdata 以前的老版本中,需要表结构定义文件,利用 DEFGEN 工具可以为源端和目标端表生成数据定义文件,当源库和目标库类型不一致时,或源端的表和目标端的表结构不一致时,数据定义文件时必须要有的。
一般生成数据定义文件的步骤如下:
Step1. 编辑 defgen 文件
- GGSCI> edit param test_ogg
- defsfile /goldengate/dirdef/goldengate.def,FORMAT RELEASE 11.2, PURGE
- userid ogg,password ogg
- TABLE ODSOR.T_MON_DOCDATUM;
Step2. 利用 defgen 工具生成 defgen.prm 文件
- /ogg19c/defgen paramfile /ogg19c/dirprm/test_ogg.prm
- 或者
- ./defgen paramfile ./dirprm/test_ogg.prm
Step3. 将生成好的数据定义文件 scp 二进制模式传输到目标端对应的目录 dirdef
scp /ogg19c/dirdef/goldengate.def oracle@192.168.17.25:/soft/dirdef/goldengate_rep03.def目标端配置 ogg
编辑 rep 复制进程参数文件
以下官方文档示例参数模板:
- REPLICAT hdfs
- TARGETDB LIBFILE libggjava.so SET property=dirprm/hdfs.properties
- --SOURCEDEFS ./dirdef/dbo.def
- DDL INCLUDE ALL
- GROUPTRANSOPS 1000
- MAPEXCLUDE dbo.excludetable
- MAP dbo.*, TARGET dbo.*;
以下是对这些 Replicat 配置条目的解释:
REPLICAT hdfs --Replicat 进程的名称。
TARGETDB LIBFILE libggjava.so SET property=dirprm/hdfs.properties --在您退出时设置目标数据库libggjava.so并将 Java 适配器属性文件设置为dirprm/hdfs.properties.
–SOURCEDEFS ./dirdef/dbo.def --设置源数据库定义文件。它被注释掉是因为 Oracle GoldenGate 跟踪文件在跟踪中提供元数据。
GROUPTRANSOPS 1000 --将源跟踪文件中的 1000 个事务分组为单个目标事务。这是默认设置,可提高大数据集成的性能。
MAPEXCLUDE dbo.excludetable --设置要排除的表。
MAP dbo., TARGET dbo.; --设置输入到输出表的映射。以下是我测试环境参数配置:
- REPLICAT rep03
- sourcedefs /soft/dirdef/goldengate_rep03.def
- TARGETDB LIBFILE libggjava.so SET property=dirprm/kafka_dw.props
- REPORTCOUNT EVERY 1 MINUTES, RATE
- GROUPTRANSOPS 10000
- GETUPDATEBEFORES
- HANDLECOLLISIONS
- REPLACEBADCHAR SUBSTITUTE ? FORCECHECK
- MAP ODSOR.T_MON_DOCDATUM,target ODSOR.T_MON_DOCDATUM;
- MAP OPS.T_LABEL_RULE,target OPS.T_LABEL_RULE;
- MAP prod.*,target prod.*;
- MAPEXCLUDE PROD.T_FILE_NAME;
kafka_dw.props 配置文件如下,下游 Kafka 集群安装配置这里就先不介绍了。
- vim /soft/dirprm/kafka_dw.props
- gg.handlerlist=kafkahandler
- gg.handler.kafkahandler.type=kafka
- gg.handler.kafkahandler.KafkaProducerConfigFile=custom_kafka_producer.properties
- gg.handler.kafkahandler.format=json
- gg.handler.kafkahandler.mode=op
- gg.handler.kafkahandler.format.includePrimaryKeys=true
- gg.classpath=dirprm/:/home/oracle/kafka/libs/*:/soft/:/soft/lib/*
- gg.handler.kafkahandler.BlockingSend=true
- #gg.handler.kafkahandler.topicMappingTemplate=ORACLE_JIEKEDB_${schemaName}_${tableName}_${primaryKeys}
- #gg.handler.kafkahandler.keyMappingTemplate=ORACLE_JIEKEDB_${schemaName}_${tableName}_${primaryKeys}
- gg.handler.kafkahandler.topicMappingTemplate=ORACLE_DW_75.${schemaName}.${tableName}
- gg.handler.kafkahandler.keyMappingTemplate=${primaryKeys}
添加 rep 复制进程
添加和启动 Replicat 进程的命令如下:
- GGSCI> add replicat rep03,exttrail /soft/dirdat/dw nodbcheckpoint
- GGSCI> START rep03
- cat ODSOR.T_MON_DOCDATUM.schema.json
- {
- "$schema":"http://json-schema.org/draft-04/schema#",
- "title":"ODSOR.T_MON_DOCDATUM",
- "description":"JSON schema for table ODSOR.T_MON_DOCDATUM",
- "definitions":{
- "row":{
- "type":"object",
- "properties":{
- "ID":{
- "type":[
- "string",
- "null"
- ]
- },
- "FKCORP":{
- "type":[
- "string",
- "null"
- ]
- },
- ......
正常同步之后,Kafka 则会读取 ./dirdef/ 目录下生成的 json 文件进行消费,消费完之后如有必要还会落库写入数据库,如果落库有时候也会需要同步历史数据,可选择 DataX 等 ETL 工具从源库抽取历史数据,这里不在介绍,如有需要请自行查找相关文档。
三、新增表配置
有时候随着业务的快速发展及新功能需求,需要进一步同步一些表到 Kafka,下面一起看看操作步骤。
这里以某一用户下 T_FILE_RENDER 表为例进行介绍,步骤完全一样,不需要同步历史数据,仅使用 OGG 同步变化数据即可。
- --源端
- su - oracle
- cd /ogg19c
- ./ggsci
- GGSCI> stop EXT1
- GGSCI> edit param ext1
- #添加 TABLE CC.T_FILE_RENDER;到参数文件里,wq!保存退出
- TABLE CC.T_FILE_RENDER;
- GGSCI> view param ext1
- #获取 goldengate 数据库用户连接串
- GGSCI> dblogin userid ogg@jiekedb, password ogg
- #添加表字段补充日志
- GGSCI> add trandata CC.T_FILE_RENDER
- GGSCI> info trandata CC.T_FILE_RENDER
- #看见is enabled 等字样就代表补充日志已经添加成功
- #编辑 dpe1 投递进程添加新增表
- GGSCI> edit parmas dpe1
- TABLE CC.T_FILE_RENDER;
添加表到表结构定义文件
添加 TABLE CC.T_FILE_RENDER; 到表结构变更配置文件- vi /ogg19c/dirprm/test_ogg.prm
- TABLE CC.T_FILE_RENDER;
生成表结构文件并传到目标端相关文件夹下。
- ./defgen paramfile dirprm/test_ogg.prm
- scp /ogg19c/dirdef/goldengate.def oracle@192.168.75.17:/ogg/dirdef
添加各个表的补充日志后,停掉目标端 rep1 复制进程和源端 dpe1 投递进程,重启 ext1 捕获进程。在目标端 rep1 进程参数中添加新增表的 MAP 信息,然后重启即可。
- GGSCI> stop rep01
- GGSCI> edit params rep01
- MAP CC.T_FILE_RENDER,target CC.T_FILE_RENDER;
- GGSCI> start rep01
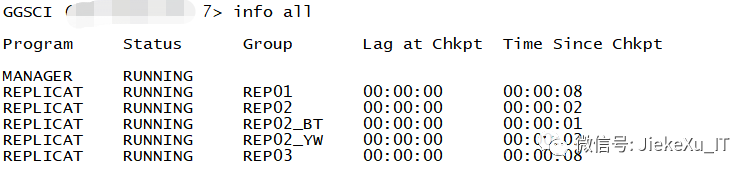
- GGSCI> info all
- GGSCI> info rep01
- #启动之后观察延迟趋近于0即为正常

参考文档
https://docs.oracle.com/en/middleware/goldengate/big-data/12.3.2.1/gbdig/installing-oracle-goldengate-big-data.html#GUID-640A1CE0-7F5C-421C-B693-A74C6223F3B2全文完,希望可以帮到正在阅读的你,如果觉得有帮助,可以分享给你身边的朋友,同事,你关心谁就分享给谁,一起学习共同进步~~~
❤️ 欢迎关注我的公众号,一起学习新知识!!!
- ————————————————————————————
- 公众号:JiekeXu DBA之路
- 墨天轮:https://www.modb.pro/u/4347
- CSDN :https://blog.csdn.net/JiekeXu
- 腾讯云:https://cloud.tencent.com/developer/user/5645107
- ————————————————————————————
- Oracle 表碎片检查及整理方案
- OGG|Oracle GoldenGate 基础2021 年公众号历史文章合集整理
- 2020 年公众号历史文章合集整理
- 我的 2021 年终总结和 2022 展望Oracle 19c RAC 遇到的几个问题
- 利用 OGG 迁移 Oracle11g 到 19COGG|Oracle GoldenGate 微服务架构Oracle 查询表空间使用率超慢问题一则国产数据库|TiDB 5.4 单机快速安装初体验Oracle ADG 备库停启维护流程及增量恢复Linux 环境搭建 MySQL8.0.28 主从同步环境
-
相关阅读:
人体神经系统分类图解,人体神经系统分类图片
第六章 支持向量机
腾讯云国际站-阿里云OSS如何迁移到腾讯云COS?腾讯云cos迁移教程
批量kill进程
Flutter 数据存储大全之使用 MongoDB Realm 构建离线 Flutter 应用(教程含源码)
Java项目:jsp在线考试系统
nacos -分布式事务-Seata** linux安装jdk ,mysql5.7启动nacos配置ideal 调用接口配合 (保姆级细节教程)
一些实用的工具网站
建筑类企业做ISO9001时需要带GB/T50430标准
技巧 | Python绘制2022年卡塔尔世界杯决赛圈预测图
- 原文地址:https://blog.csdn.net/JiekeXu/article/details/126397554
