-
Linux Command——ls
title: Notes of System Design No.05 — Design a WhatsApp
description: ‘Design a Uber’
date: 2022-05-14 13:45:37
tags: 系统设计
categories:- 系统设计
00. What is WhatsApp

Whatsapp messenger or Facebook messenger uses the internet to send messages, images, audio, or video. WhatsApp will never store any messages or other data related to users except for the User’s name and number for accessibility.
Only there is one point of contact with the WhatsApp server when the message is being delivered and once delivered, the data from the server is deleted. However, their servers do store your messages for 30 days if they are undelivered. Beyond this time undelivered messages will be deleted.
If the recipient is online, the message will go to them via WhatsApp servers but not stored in any WhatsApp database servers. All the messages are stored in the phone’s memory, but they are also stored in Google Drive with the user’s permission for backup.
WhatsApp ensures end-to-end encryption hence only the recipient and the sender have access to the messages.
01.Functional Requirement
- Interviewee: What would be the scale of the WhatsApp messaging system? How many daily active users are supposed to be supported?
- Interviewer: Let’s design it for WhatsApp daily user count as of 2020 i.e 500M daily active users. Assume each person sends 30 messages per day.
- Interviewee: Do we support both 1:1 conversations and group conversions?
- Interviewer: Yes, let’s design for both 1:1 conversations and group conversations.
- Interviewee: Do we support images and videos in the texts?
- Interviewer: Yes.
- Interviewee: What would be the average size of messages?
- Interviewer: Make your own assumptions.
- Interviewee: Whatsapp does not support the permanent storage of message data. Should we consider the same feature?
- Interviewer: Yes. Currently, let’s not support permanent storage. If the message is delivered it must not be stored in our database. If time permits we shall discuss the same.
- Interviewer: Whatsapp supports end-to-end encryption of messages. Should we also include encryption of messages?
- Interviewer: Yes.
- Interviewee: Should we support features like last seen, the message delivered tick, and read blue ticks?
- Interviewer: Yes.
From the above conversation we note down the required features as follows:
- Daily active users: 500 M.
- Messages per day each person: 30 msgs per day.
- Text messages don’t have much data size, so the size of messages can be in kb. But if sharing HD photos is available, then its size may be more than 1 MB. On average let’s assume 50kb of message size.
- The system must support both one-to-one conversations and group conversations.
- Media content like images and videos should also be supported.
- Permanent storage of messages is not supported.
- End to end encryption of messages.
- Support sent, delivered and read ticks features.
02. Non-Functional Requirement
- We will be handling a large amount of data, hence partition tolerance is necessary. Partition tolerance means that the cluster must continue to work despite any number of communication breakdowns between system components/ nodes in the system. Users must not face any performance failure.
- Between consistency and availability, consistency is important as sending and receiving messages in real time is necessary. We cannot afford miscommunication. The messages must be sent and received at real time and in the order in which the messages were sent.
- There should be no loss in data, due to failure of database servers. I.e system must be reliable .
- The system must also be resilient i.e the system must be capable of recovering quickly from difficulties like server failure.
03. Define API && data model
-
Send_Message(sender_userID, reciever_userID,text):
-
- sender_userID : unique user_id of sender
- reciever_userID : unique user_id of receiver
- text : content of the message
-
Get_Messages(user_Id, screen_size, before_timestamp)
-
- userID : unique user_id of the user who is fetching the messages
- screen_size : Different number of messages will have to be fetched based on the screen size of the user. I.e mobile or desktop or tablet screen size etc
- before_timestamp : Let’s say the last 20 messages are shown on the user screen. Now the user scrolls up. i.e user wants to fetch previous messages. Hence the next get_messages API call will fetch messages before_timestamp attribute
04. High-Level Design
We have discussed the API queries which we are going to need. Let’s discuss a scenario and see how the message flows in the system.

- Let’s say client A wants to send a message to client B. Client A has the message. Initially, yet client A is not connected to the system as of now. This message will be saved in the local database of the application. In android, it may be SQLite or in iPhone, it may be another lightweight database. The message will stay in the mobile database.
- As soon as the client connects to the messaging server the connection is established and the message is pushed to the messaging server.
- Once the server receives the message, it looks for whom the message has to be sent. This message now will be sent to client B by the server.
- For some reason, if client B is not connected to the internet or to the messaging server, this message will be saved into the DB and then a soon as the messaging server learns that the client B has connected back to the messaging server it retrieves the message from the DB and then sends the message to client B using the connection which is established.
Single Message server won’t be able to handle all the requests i.e 18k requests per sec. Hence we need multiple Message servers. Distributing these requests across up and running servers is also necessary. Hence we introduce load balancing to allocate requests across servers.
Consistent hashing can be used to distribute requests across message servers. UserId can be used to hash so that a user will be allocated the same server most of the time. Using consistent hashing there won’t be much problem even if any server goes down.
Usually, a much better approach is to use what is known as an API Gateway. An API Gateway is a server that is the single entry point into the system. Since clients don’t call the services directly, API Gateway acts as an entry point for the clients to forward requests to appropriate microservices.
The API Gateway encapsulates the internal system architecture and provides an API that is tailored to each client. It might have other responsibilities such as authentication, monitoring, load balancing, caching, request shaping and management, and static response handling.
The advantages of using an API gateway include:
- All the services can be updated without the clients knowing.
- Services can also use messaging protocols that are not web-friendly.
- The API Gateway can perform cross-cutting functions such as providing security, load balancing, etc.
Can we use the HTTP protocol to send and receive messages?
A big NO .
HTTP follows a client/server model, where the Web client is always the initiator of transactions, requesting data from the server. HTTP is a client to server protocol. The client sends requests and server responses.
So let’s say A wants to send a message to B. If we use the HTTP protocol, A sends a send_message() HTTP request to the messaging server. Now A has sent a message. And the TCP connection is closed. How is the message going to be sent to B? If B is offline the message will remain in the database server and the server won’t be able to send the message to B.
In the HTTP protocol, a connection cannot be originated by the server.
So what can we use?
We need a mechanism for the server to independently send, or push, data to the client without the client first making a request. We do need clients to open connections, but instead of the server sending an empty response if no response is available, we want the server to hold the TCP connection open. And once the response is available, the awaiting message can be sent to the client.
This can be done either by using WebSocket or HTTP long polling. The difference between HTTP long polling and WebSocket can be understood here .
In HTTP long polling, the client polls the server requesting new information. The server holds the request open until new data is available. Once available, the server responds and sends the new information. When the client receives the new information, it immediately sends another request, and the operation is repeated. This effectively emulates a server push feature.
But HTTP long polling cannot be used for real-time messages as can be found at Scalability Basics article.
We need another protocol over TCP. And the best fit here is WebSockets. Websockets are super nice when it comes to chatting applications. They allow peer to peer communication. So A can send to B where B can be a server. B can send to A. There is no client-server semantics over here. Now the server can send a message to client B.
Hence, we will be using Websockets.
ER Diagram:

Index:

We need consistency and partition tolerance as our priority. Hence, HBase/ Bigtable is preferable.
Read SQL vs NoSQL for more information.
05 . Low Level design
-
Database layer:
-
We need to know first which relations we want in the form of a schema. Let’s go through the flow. Now we need to build a schema such that the query can be responded to with minimum latency
-
We have discussed the API queries which we are going to need. Let’s discuss a scenario and see how the message flows in the system.
-
Let’s say person A wants to send a message to person B personally. So person A connects to the messaging server and now the messaging server needs to send it to person B somehow. And we are using web sockets.
-
Hence we do have a pool of open connections and users are connected to specific servers out of all the servers we have. So we need to have a mapping which lets us know to which server a user is connected.
-
We need a user to server mapping. Now we can keep a different microservice which stores this mapping. It needs to store the information as to a given user id is connected to messaging server 1. It will look like-
-

-
We can integrate this service with the load balancer itself but it will be an expensive thing. Because maintaining a TCP connection itself takes some memory. If we want to increase the number of connections which we want to store in the box and we don’t want that memory to be wasted by keeping information for who is connected to which box.
-
Secondly this information is being duplicated. There is some caching mechanism or there is going to be a database which is handling this information. But this is transient information so there’s going to be a lot of updates going on here because the connection mapping will be changing. Hence we will have a different microservice to store this mapping. Let’s call it a session microservice. Which says who’s connected to which box.
-
Hence we have decoupled this service from load balancers. And we have redundancy in the mapping so that there will be no single point of failure.
-
So now when user A wants to send a message to user B it calls the send_message() API and then the load balancers ask the session microservice as to where this user B exists. That is which messaging server this user B is connected to and then routes this message to the messaging server to which user B is connected and this way the message is sent to user B from the messaging server where user B had a connection.
-
Now our system design will look like
-

-
Working of Messaging server:
-
Every time when a connection is established from a client to the server, there will be a process/thread created. This thread is responsible for handling messages for this particular connection.
-
For e.g.: Let’s say A wants to send a message to B. So when A sends a message to the messaging server a thread for A will be created. This thread will be responsible for any messaging service for A. There will be a thread id. There will be a queue for every process. The queue is a buffer for messages sent by any other processes.
-
Let’s say another client B who also made a connection to the server. Thus a thread and a queue will also be formed for B.
-
We will also have a mapping of userid-thread_id
-
It will look like-
-

-
Consider A has sent a message, this message will be received by the process for id 1. It will take this message and query DB for process id for B. It will receive p_id 2 as value. This process pid1 sends this message to the queue responsible for handling client B.
-
Now it will look like-
-

-
The process for p_id-2 will keep on checking on the queue. Once it finds that there is a message in the queue, pid2 sends the message to B.
-
This way messages are sent between users.
-
Let’s say if B is not connected to the messaging server. There will be no thread and queue for client B. Also there will be no entry in the mapping. Now if A wants to send the message to client B. The message is sent to p_id 1. p_id 1 looks for p_id for client B. And it will not find any p_id. Thus it saves this message in another DB with u_id-message data for unsent messages.
-
Now we also have a DB for unsent messages. Now when B connects to the messaging server, an entry will be created in the userid-thread_id mapping. This process for client B looks for unsent messages for message B in the database with unsent messages. Now it sends these messages to client B.
-
Implementing Single tick, double tick, blue tick:
-
These features can be accomplished by Acknowledgement service.
-
-
Single Tick:
-
Once the message from UserA reaches the server, the server will send an acknowledgement saying that the message has been received. Then User_A will get a single tick.
-
Double Tick:
-
Once the message from the server sends that message to UserB by appropriate connection, UserB will send an acknowledgement to the server saying that it has received the message.
-
Then the server will send another acknowledgement to UserA, hence it will display a double tick.
-
Blue Tick:
-
Once the UserB opens WhatsApp and checks the message, UserB will send another acknowledgement to the server saying that the user has read the message. Then the server will send another acknowledgement message to UserA. Then UserA will display a blue tick.
-
-
To identify all the acknowledgements, there will be a unique ID attached to all the messages.
-
Working of Last Seen service:
-
We need a table u_id-timestamp table. We will keep another microservice to keep updating the last seen service. This service will be sending a heartbeat for every 5 seconds when the user is online or using the application.
-
When the server receives a heartbeat, it will store the timestamp in a table with User_name and last seen time.
-
Then retrieve this information, when UserB is online.
-
Working of Media Service:
-
For sending media, we cannot use previously created threads. As threads are lightweight, sending media in the same connection will not be efficient.
-
Let’s use HTTP to support media transfer. We will add another microservice to handle media content.
-
Let’s add HTTP server. This server also has CDN or object storage to the media may it be images, gifs, videos.
-
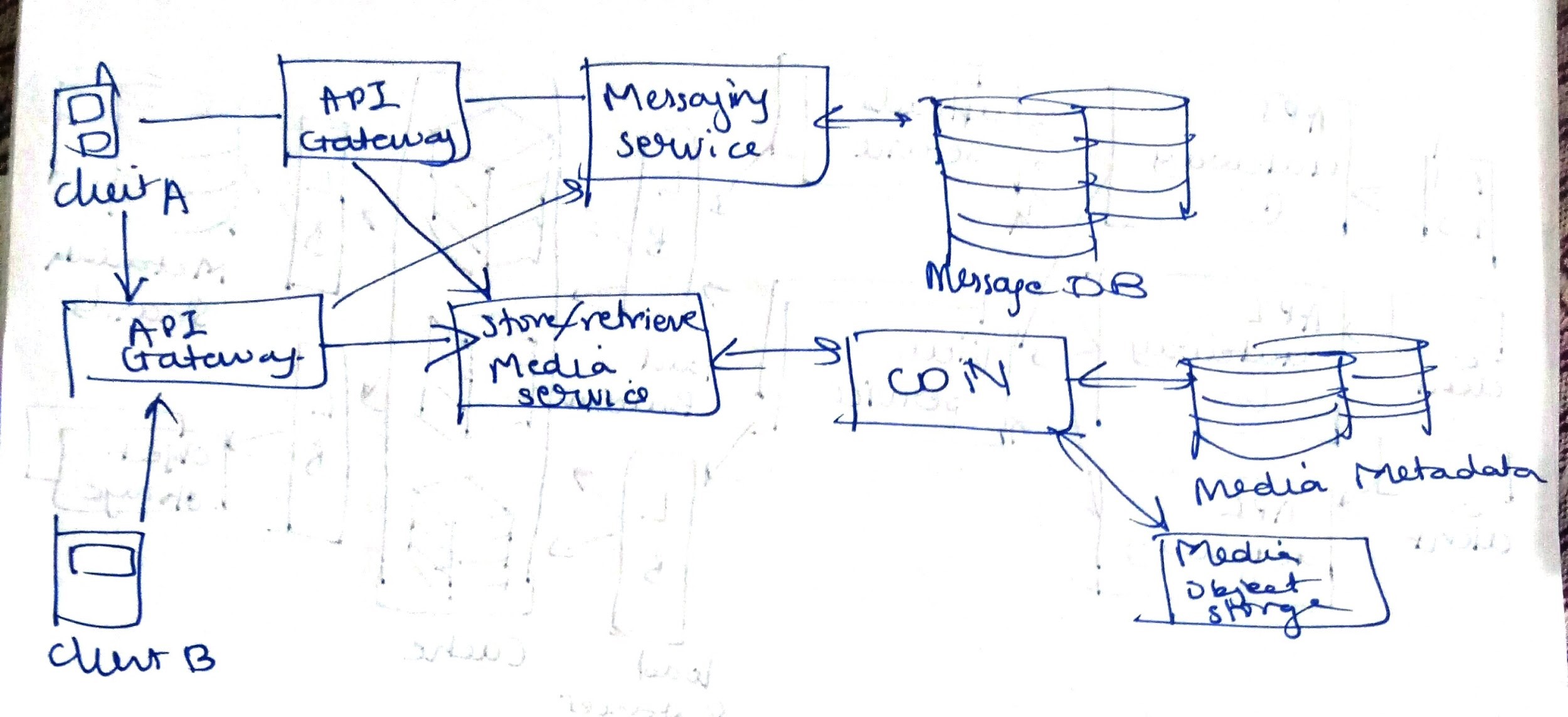
-
Let’s say A wants to send an image to B.
-
- A will not use the existing connection with the messaging server. It uploads images to the HTTP server.
- The HTTP server returns a hash/unique id for the particular media. Thus the message will now contain the hash, and media type may be audio, video or image.
- This message will now be sent by the flow discussed before by the messaging server. When this message is received by client B.
- Client B obtains the media content for the received hash from the HTTP-server microservice.
-
Working of the Group Conversation Service:
-
Let’s have another service which keeps the information about the group and its group members. Hence, there will be a mapping of group id to user id. This will be a one to many mapping as a group will have many members.
-
So when a member of let’s say, group_id 1 sends a message, it will go to the session service. The session service will send it to the appropriate message service. The messaging service will obtain all the members in group id 1. Then this message will be sent to all group members via the messaging service mechanism discussed above. So the above database with group_id-to user_id can be sharded on group id.
-
Why does WhatsApp have a constraint on the number of members allowed in a group?
Social networking websites like Instagram, Facebook use a pull and push model for spreading a post from one user to its all followers. For users with a large number of followers, the pull mechanism is used. But then consistency is not given much importance in this scenario. While in messaging service consistency is important. Hence in the number of members to whom the messages need to be sent in a group has a constraint. As such a pull model cannot be used to ensure consistency.
-

-
Encryption of messages
-
Encryption can be of two kinds -
-
- One key shared between two parties and both parties use the same key to encrypt the message. When the message is received, it uses the same key and decrypted.
- Private-key public key: One user will have a private key and share the public key to other users. This is called asymmetric encryption.
-
What if we want to store all messages?
-
Let’s say we want to build a messaging service like Facebook Messenger where messages are to be stored in the database. Here, HBase/ Bigtable can be used to store all messages. The storage estimations will change as in this case we will need to store all messages.
06. Dive Deep
Add redundancy:
What if this shard fails or catches fire? Can we afford to lose data of these users whose data was stored in this shard? No.
As we are using Cassandra, the data will be replicated across more than one shard. Hence, problems will be caused if all the shards with the same replica fail! which is almost impossible. Also, these shards can be placed in different geographical regions. Hence if a warehouse in the US catches fire, data can be obtained from the warehouse in Asia.
Instead of one load balancer, we show more load balancers, more cache, and more than 1 object storage instances. We can use Active-passive or active-active relationships to keep make our system Resilient. Basically, in order to make our system reliable, we cannot rely on only one device to do any task. We must have an additional same device may it be a load balancer, caches, etc. So if one fails, the other one can start to work instead of the failed device.
How do we know if a device is working? We can use heartbeat mechanism to know if a device is up and running all the time. a heartbeat is a periodic signal generated by hardware or software to indicate normal operation or to synchronize other parts of a computer system . Usually, a heartbeat is sent between machines at a regular interval in the order of seconds; a heartbeat message.
More information on this can be found here.
-
相关阅读:
前端HTML事件
还是 “月饼” 后续,玩转炫彩 “月饼” 之 问题说明(送开发板)
雷达测速原理、分辨率、精度、速度模糊、盲速以及速度扩展算法知识汇总
kylin使用心得
Docker学习(六):Docker Compose和Docker Stack区别
猿创征文|收到谷歌开发者大会正式邀请(Java学生的自学之路)
Python Day2 爬虫基础操作【初级】
Java设计模式之观察者模式
【正点原子STM32连载】第十四章 蜂鸣器实验 摘自【正点原子】MiniPro STM32H750 开发指南_V1.1
【Office】超简单,Excel快速完成不规则合并单元格排序
- 原文地址:https://blog.csdn.net/vjhghjghj/article/details/126393024