-
python Kmeans聚类 - CPU or GPU?
引言
k均值聚类算法1,一种经典的聚类算法,被广泛应用于机器学习领域。
本文主要对比了python库中CPU和GPU的Kmeans效率:
cpu: from sklearn.cluster import KMeans
gpu: from kmeans_pytorch import kmeans(pip install kmeans-pytorch2)
GPU版本源码:PyTorch implementation of kmeans for utilizing GPU一、时间对比
结论: 直接使用CPU版本sklearn中的KMeans or 使用以下推荐方法的GPU加速方法
推荐方法:CUDA编程方法3:从配置环境到实现KMeans算法的CUDA优化设备:4GB GEFORECE GTX GPU and an 8-core 8GB CPU
表1:不同条目数 (特征维度:32) 在不同设备聚16类所需时间 - 单位秒方法\数量 512 1024 2048 16384 100000 1000000 CPU (sklearn) 0.39 0.16 0.25 3.12 28.91 278.90 GPU (kmeans-pytorch) 0.09 0.14 0.26 3.22 52.20 489.06 每次运行结果不一样,有一定的随机性,随便取了一次结果如上表
这个结果上下两行数据换一下还好理解,很奇怪GPU一开始速度还可以越到后面越慢了 … 和其源码cpu_vs_gpu.ipynb相反
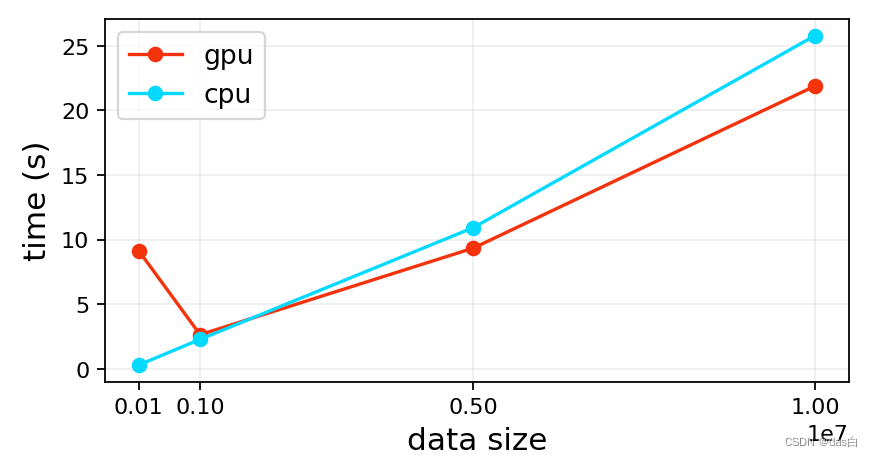
需要注明:我使用sklearn的KMeans和它的算法进行对比,而它的图使用自己的算法在CPU和GPU设备上进行对比
最后猜测:python实现的GPU加速,相比c++慢了些可能由于本身CPU内存略小,数量大的时候CPU和GPU交互时间也越长,所以在GPU上跑也很慢参数设置差异
其它可能的原因4:GPU vs CPU
二、代码
import numpy as np import random import torch import time from sklearn.cluster import KMeans from kmeans_pytorch import kmeans # 1.固定随机数 seed = 0 random.seed(seed) np.random.seed(seed) torch.manual_seed(seed) torch.cuda.manual_seed(seed) torch.cuda.manual_seed_all(seed) # 2.对比实验 类别:16 特征维度:32 cpu_t = [] gpu_t = [] for i in [512, 1024, 2048, 16384, 100000, 1000000]: print(i) feature = np.random.random([i, 32]) # 随机数 # cpu t_s = time.time() _ = KMeans(n_clusters=16, random_state=0).fit(feature) cpu_t.append(time.time() - t_s) # gpu t_s = time.time() _, _ = kmeans(torch.from_numpy(feature), num_clusters=16, device=torch.device('cuda:0')) gpu_t.append(time.time() - t_s) print(cpu_t) print(gpu_t)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
三、推荐博文
GPU优化K-Means算法方案5:基于GPU的K-Means聚类算法
k-medoids算法6:聚类算法——k-medoids算法
-
相关阅读:
瑞芯微RK1126平台 通过http接口设置 ISP 饱和度 亮度 对比度
聚观早报 | 小米汽车SU7将发布;一加Ace 3V渲染图曝光
更换双cut的via
责任链模式(Chain of Responsibility)
【Vue】二:Vue核心处理---模板语法
一些资源收集
Ubuntu不显示共享文件夹解决方案
English语法_介词搭配
深入学习Linux中的“文件系统与日志分析”
肖sir__linux讲解vim命令(3.1)
- 原文地址:https://blog.csdn.net/qq_38204686/article/details/126386265
