-
【python】爬虫系列之requests库介绍
目录
活动地址:CSDN21天学习挑战赛
**
学习日记 Day 14
**
前面讲解了关于爬虫的入门内容,本文学习与爬虫相关的requests模块的内容。
requests主要用于发送请求获取响应,该模块有很多的替代模块,比如urlib模块。但相对来说requests模块代码简洁 易懂,相对于urlib模块,使用requests编写的代码会更少,实现某个功能更简单。
一、 安装requests模块
点击 【win+r】,输入cmd,输入如下对应的pip命令,等待安装成功。
pip install requests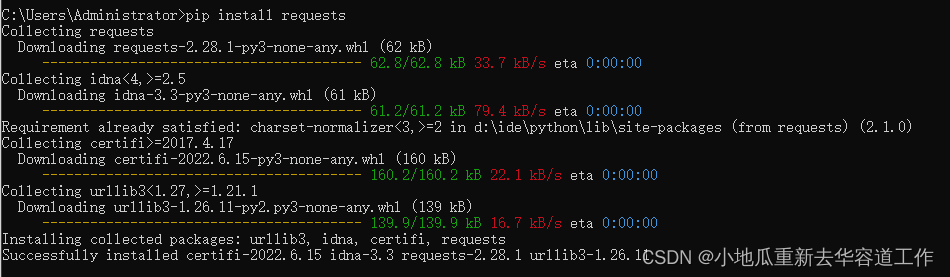
二、 requests模块常用的方法和属性
- requests模块的常用方法和属性如下:
方法名/属性名 说明 response = requests.get(url) 发送请求获取的响应对象(比较常用) response = requests.post(url) 发送请求获取的响应对象 response.json() 自动将json字符串类型的响应内容转换为python对象(dict 或 list) response.url 响应的url,有时候响应的url与请求的url并不一致 response.status_code 响应状态码,如200,404等 response.request.headers 响应对应的请求头 response.headers 响应头 response.request.cookies 响应对应请求的cookie;返回cookieJar类型 response.cookies 响应的cookie(经过了set-cookie动作;返回cookieJar类型) response.text 返回响应的内容,str类型 response.content 返回响应内容,bytes类型 使用示例:
- # 想百度首页发送请求,获取该页面的源码
- import requests
- # 百度的网址
- url = "https://www.baidu.com/"
- # 发送请求
- response = requests.get(url)
- print("响应对象的类型:",type(response))
- print("响应对象的状态码:",response.status_code) # 200表示请求正常,服务器正常的返回数据
- print("响应内容的类型:",type(response.text))
- print("Cookies:",response.cookies)
- print("响应对应的请求头:",response.request.headers)
- print("响应头:",response.headers)
- print("响应对用请求的cookie:",response.request.prepare_cookies)
- print("响应内容:",response.text)
- print("响应的内容,bytes类型的:",response.content)
显示结果:
- 响应对象的类型: <class 'requests.models.Response'>
- 响应对象的状态码: 200
- 响应内容的类型: <class 'str'>
- Cookies: <RequestsCookieJar[<Cookie BDORZ=27315 for .baidu.com/>]>
- 响应对应的请求头: {'User-Agent': 'python-requests/2.28.1', 'Accept-Encoding': 'gzip, deflate', 'Accept': '*/*', 'Connection': 'keep-alive'}
- 响应头: {'Cache-Control': 'private, no-cache, no-store, proxy-revalidate, no-transform', 'Connection': 'keep-alive', 'Content-Encoding': 'gzip', 'Content-Type': 'text/html', 'Date': 'Wed, 17 Aug 2022 02:05:07 GMT', 'Last-Modified': 'Mon, 23 Jan 2017 13:24:18 GMT', 'Pragma': 'no-cache', 'Server': 'bfe/1.0.8.18', 'Set-Cookie': 'BDORZ=27315; max-age=86400; domain=.baidu.com; path=/', 'Transfer-Encoding': 'chunked'}
- 响应对用请求的cookie:
PreparedRequest.prepare_cookies of <PreparedRequest [GET]>> - 响应内容: DOCTYPE html>
ç¾åº¦ä¸ä¸ï¼ä½ å°±çé wrapper> 响应的内容,bytes类型的: b'\r\n
响应的内容,bytes类型的: b'\r\n\xe7\x99\xbe\xe5\xba\xa6\xe4\xb8\x80\xe4\xb8\x8b\xef\xbc\x8c\xe4\xbd\xa0\xe5\xb0\xb1\xe7\x9f\xa5\xe9\x81\x93 \r\n' name=wd class=s_ipt value maxlength=255 autocomplete=off autofocus=autofocus>\xe5\x85\xb3\xe4\xba\x8e\xe7\x99\xbe\xe5\xba\xa6 About Baidu
©2017 Baidu \xe4\xbd\xbf\xe7\x94\xa8\xe7\x99\xbe\xe5\xba\xa6\xe5\x89\x8d\xe5\xbf\x85\xe8\xaf\xbb \xe6\x84\x8f\xe8\xa7\x81\xe5\x8f\x8d\xe9\xa6\x88 \xe4\xba\xacICP\xe8\xaf\x81030173\xe5\x8f\xb7

从结果中发现response.text和response.content是有区别的:
- response.text——是str类型,request模块自动根据HTTP头部响应的编码作出有根据的推测
- response.content——是bytes类型
通过对response.content进行decode可以解决中文乱码的问题:
- response.conten.decode()
- response.conten.decode("GBK")
常见的编码字符集有:
- utf-8
- gbk
- gb2312
- asci
- iso-8859-1
使用示例:
- import requests
- # 目标网址
- url = "http://www.baidu.com/"
- # 发送请求获取响应
- response = requests.get(url)
- # 手动设置编码格式
- response.encoding = 'utf8'
- # 打印源码的str类型数据
- print(response.text)
- # response.content是存储的bytes类型的响应数据,进行decode操作
- print(response.content.decode('utf-8'))
显示结果:
- html>
- <html> <head><meta http-equiv=content-type content=text/html;charset=utf-8><meta http-equiv=X-UA-Compatible content=IE=Edge><meta content=always name=referrer><link rel=stylesheet type=text/css href=http://s1.bdstatic.com/r/www/cache/bdorz/baidu.min.css><title>百
- 度一下,你就知道title>head> <body link=#0000cc> <div id=wrapper> <div id=head> <div class=head_wrapper> <div class=s_form> <div class=s_form_wrapper> <div id=lg> <img hidefocus=true
- src=//www.baidu.com/img/bd_logo1.png width=270 height=129> div> <form id=form name=f action=//www.baidu.com/s class=fm> <input type=hidden name=bdorz_come value=1> <input type=hidden name=ie value=utf-8> <input type=hidden name=f value=8> <input type=hidden name=rsv_bp value=1> <input type=hidden name=rsv_idx value=1> <input type=hidden name=tn value=baidu><span class="bg s_ipt_wr"><input id=kw name=wd class=s_ipt value maxlength=255 autocomplete=off autofocus>span><span class="bg s_btn_wr"><input type=submit id=su value=百度一下 class="bg s_btn">span> form> div> div> <div id=u1> <a href=http://news.baidu.com name=tj_trnews class=mnav>新闻a> <a href=http://www.hao123.com name=tj_trhao123 class=mnav>hao123a> <a href=http://map.baidu.com name=tj_trmap class=mnav>地图a> <a href=http://v.baidu.com name=tj_trvideo class=mnav>视频a> <a href=http://tieba.baidu.com name=tj_trtieba class=mnav>贴吧a> <noscript> <a href=http://www.baidu.com/bdorz/login.gif?login&tpl=mn&u=http%3A%2F%2Fwww.baidu.com%2f%3fbdorz_come%3d1 name=tj_login class=lb>登录a> noscript> <script>document.write('encodeURIComponent(window.location.href+ (window.location.search === "" ? "?" : "&")+ "bdorz_come=1")+ '" name="tj_login" class="lb">登录');script> <a href=//www.baidu.com/more/ name=tj_briicon class=bri style="display: block;">更多产品a> div> div> div> <div id=ftCon> <div id=ftConw> <p id=lh> <a href=http://home.baidu.com>关于百度a> <a href=http://ir.baidu.com>About Baidua> p> <p id=cp>©2017 Baidu <a href=http://www.baidu.com/duty/>使用百度前必读a> <a href=http://jianyi.baidu.com/ class=cp-feedback>意见反馈a> 京ICP证030173号 <img src=//www.baidu.com/img/gs.gif> p> div> div> div> body> html>
- html>
- <html> <head><meta http-equiv=content-type content=text/html;charset=utf-8><meta http-equiv=X-UA-Compatible content=IE=Edge><meta content=always name=referrer><link rel=stylesheet type=text/css href=http://s1.bdstatic.com/r/www/cache/bdorz/baidu.min.css><title>百
- 度一下,你就知道title>head> <body link=#0000cc> <div id=wrapper> <div id=head> <div class=head_wrapper> <div class=s_form> <div class=s_form_wrapper> <div id=lg> <img hidefocus=true
- src=//www.baidu.com/img/bd_logo1.png width=270 height=129> div> <form id=form name=f action=//www.baidu.com/s class=fm> <input type=hidden name=bdorz_come value=1> <input type=hidden name=ie value=utf-8> <input type=hidden name=f value=8> <input type=hidden name=rsv_bp value=1> <input type=hidden name=rsv_idx value=1> <input type=hidden name=tn value=baidu><span class="bg s_ipt_wr"><input id=kw name=wd class=s_ipt value maxlength=255 autocomplete=off autofocus>span><span class="bg s_btn_wr"><input type=submit id=su value=百度一下 class="bg s_btn">span> form> div> div> <div id=u1> <a href=http://news.baidu.com name=tj_trnews class=mnav>新闻a> <a href=http://www.hao123.com name=tj_trhao123 class=mnav>hao123a> <a href=http://map.baidu.com name=tj_trmap class=mnav>地图a> <a href=http://v.baidu.com name=tj_trvideo class=mnav>视频a> <a href=http://tieba.baidu.com name=tj_trtieba class=mnav>贴吧a> <noscript> <a href=http://www.baidu.com/bdorz/login.gif?login&tpl=mn&u=http%3A%2F%2Fwww.baidu.com%2f%3fbdorz_come%3d1 name=tj_login class=lb>登录a> noscript> <script>document.write('encodeURIComponent(window.location.href+ (window.location.search === "" ? "?" : "&")+ "bdorz_come=1")+ '" name="tj_login" class="lb">登录');script> <a href=//www.baidu.com/more/ name=tj_briicon class=bri style="display: block;">更多产品a> div> div> div> <div id=ftCon> <div id=ftConw> <p id=lh> <a href=http://home.baidu.com>关于百度a> <a href=http://ir.baidu.com>About Baidua> p> <p id=cp>©2017 Baidu <a href=http://www.baidu.com/duty/>使用百度前必读a> <a href=http://jianyi.baidu.com/ class=cp-feedback>意见反馈a> 京ICP证030173号 <img src=//www.baidu.com/img/gs.gif> p> div> div> div> body> html>
三、 发送带有headers参数的请求
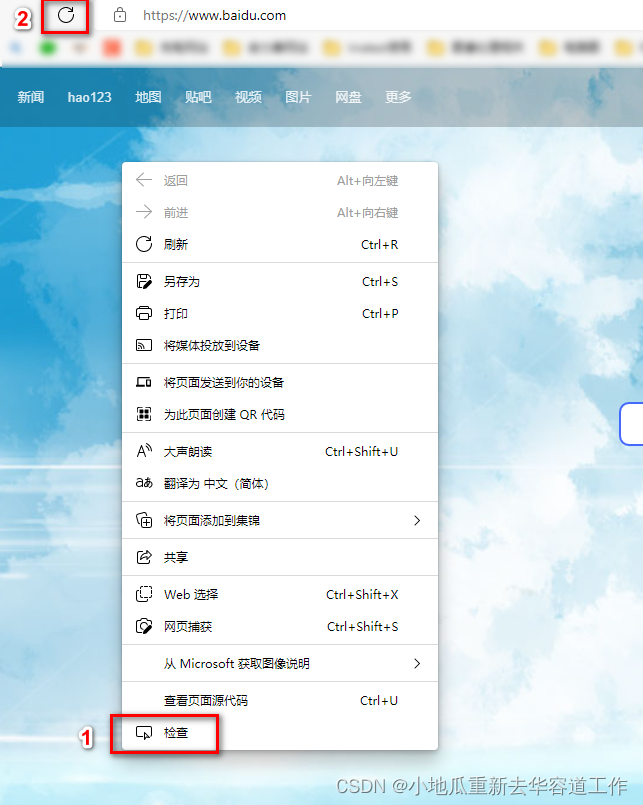
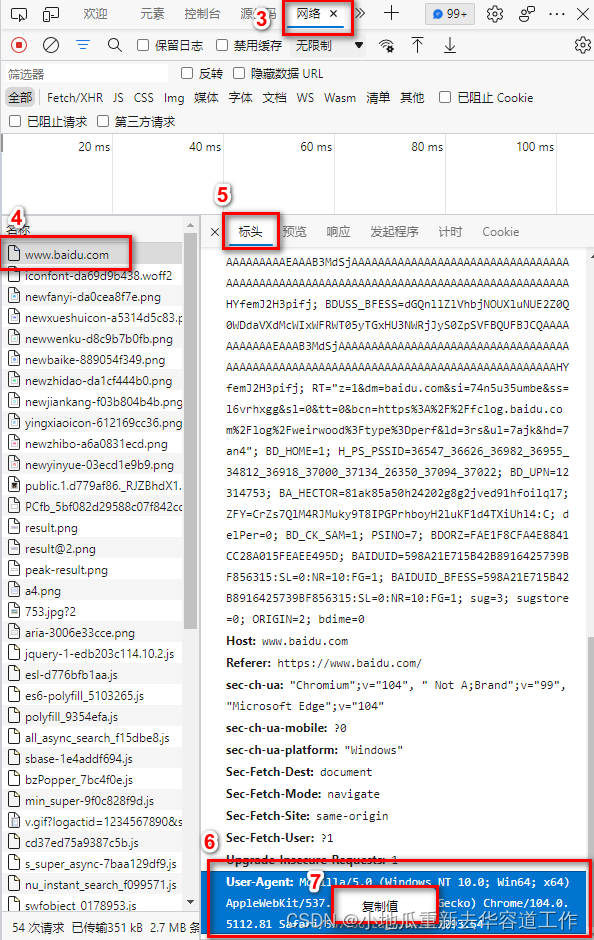
1. 获取浏览器的请求头
- 打开浏览器,然后在页面上单击右键——> 检查,然后左上角刷新网页;
- 点击Network——>找到对应的网址,在右侧的Headers中找到User-Agent并复制;
如下:
2. 代码实现
request.get(url,headers=headers)参数 headers 接收字典形式的请求头,请求头字段名作为key,字段对应的值作为value。
- import requests
- url = "https://www.baidu.com/"
- headers={"User-Agent" : "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/104.0.5112.81 Safari/537.36 Edg/104.0.1293.54"}
- response = requests.get(url,headers=headers)
- print(response.text)
返回结果是整个网页的源码。
四、 发送带参数的请求
发送带参数的请求有两种方式:
- 网址中带参数;如下例子中的wd=python
- import requests
- # 目标网址
- url = "https://www.baidu.com/s?wd=python"
- headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/103.0.0.0 Safari/537.36'}
- # 发送请求获取响应
- response = requests.get(url,headers=headers)
- print(response.text)
- 通过params构造参数字典
- import requests
- # 目标网址
- url = "https://www.baidu.com/s?"
- headers = {
- 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/103.0.0.0 Safari/537.36'}
- # 请求参数是一个字典
- kw = {'wd': 'python'}
- # 发送请求的时候设置参数字典,获取响应
- response = requests.get(url, headers=headers, params=kw)
- print(response.text)
五、 在header参数中携带cookie
请求头中的cookie字段可以保持用户访问的状态,可以在headers参数中添加Cookie,模拟普通用户的请求。Cookie具有时效性,过一段时间需要更换。
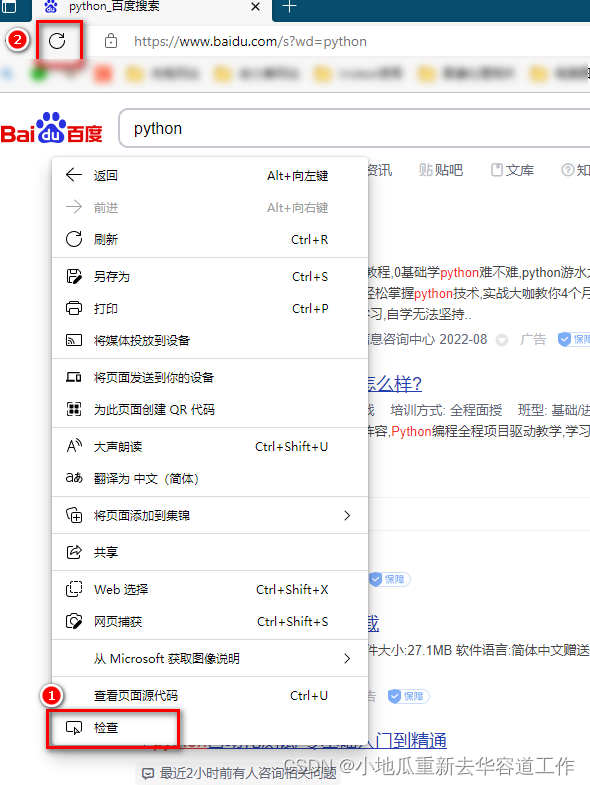
- 查找cookie
打开浏览器,右键→检查→点击刷新网页,找到Network →找到对用的网址→在Headers中往下翻找到Cookie并复制。具体步骤如下:
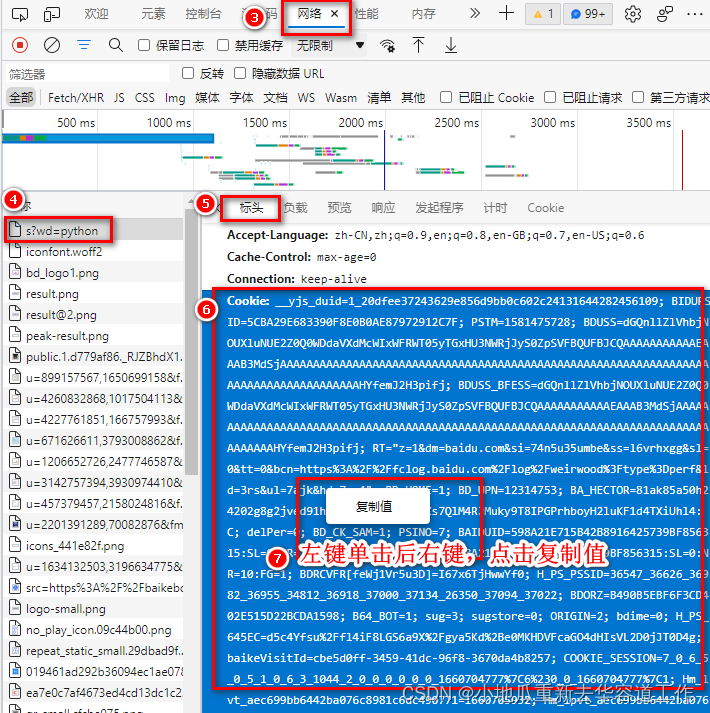
- 代码实现
在headers参数中添加cookie参数即可:
- headers = {
- 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/103.0.0.0 Safari/537.36',
- 'Cookie' : '__yjs_duid=1_20dfee37243629e856d9bb0c602c24131644282456109; BIDUPSID=5CBA29E683390F8E0B0AE87972912C7F; PSTM=1581475728; BDUSS=dGQnllZlVhbjNOUXluNUE2Z0Q0WDdaVXdMcWIxWFRWT05yTGxHU3NWRjJyS0ZpSVFBQUFBJCQAAAAAAAAAAAEAAAB3MdSjAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAHYfemJ2H3pifj; BDUSS_BFESS=dGQnllZlVhbjNOUXluNUE2Z0Q0WDdaVXdMcWIxWFRWT05yTGxHU3NWRjJyS0ZpSVFBQUFBJCQAAAAAAAAAAAEAAAB3MdSjAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAHYfemJ2H3pifj; RT="z=1&dm=baidu.com&si=74n5u35umbe&ss=l6vrhxgg&sl=0&tt=0&bcn=https://fclog.baidu.com/log/weirwood?type=perf&ld=3rs&ul=7ajk&hd=7an4"; BD_HOME=1; BD_UPN=12314753; BA_HECTOR=81ak85a50h24202g8g2jved91hfoilq17; ZFY=CrZs7QlM4RJMuky9T8IPGPrhboyH2luKF1d4TXiUhl4:C; delPer=0; BD_CK_SAM=1; PSINO=7; BAIDUID=598A21E715B42B8916425739BF856315:SL=0:NR=10:FG=1; BAIDUID_BFESS=598A21E715B42B8916425739BF856315:SL=0:NR=10:FG=1; BDRCVFR[feWj1Vr5u3D]=I67x6TjHwwYf0; H_PS_PSSID=36547_36626_36982_36955_34812_36918_37000_37134_26350_37094_37022; BDORZ=B490B5EBF6F3CD402E515D22BCDA1598; B64_BOT=1; sug=3; sugstore=0; ORIGIN=2; bdime=0; H_PS_645EC=d5c4Yfsu/fl4iF8LGS6a9X/gya5Kd+e0MKHDVFcaGO4dHIsVL2D0jJT0D4g; baikeVisitId=cbe5d0ff-3459-41dc-96f8-3670da4b8257; COOKIE_SESSION=7_0_6_5_0_5_1_0_6_3_1044_2_0_0_0_0_0_0_1660704777|6#0_0_1660704777|1; Hm_lvt_aec699bb6442ba076c8981c6dc490771=1660705932; Hm_lpvt_aec699bb6442ba076c8981c6dc490771=1660705932'
- }
六、使用超时参数timeout
超时参数让请求在规定的时间内返回结果,否则就报错。超时参数可以在一定程度上提高项目的效率。
使用时只需设置requests.get()函数的timeout参数即可,单位是秒。如下示例:
- # -*- coding:utf-8 -*-
- import requests
- url = "https://www.baidu.com/"
- header = {
- 'User-Agent' : 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/104.0.5112.81 Safari/537.36 Edg/104.0.1293.54'
- }
- try:
- response = requests.get(url,headers=header,timeout=0.05)
- print("超时10s")
- except:
- for i in range(4):
- response = requests.get(url=url,headers=header,timeout=20)
- if response.status_code == 200:
- break
- print("超时20s")
- html_str = response.text
七、 proxies代理参数的使用
为了让服务器以为不是同一个客户端在请求,为了防止频繁项一个域名发送请求被封ip,所以需要使用代理ip。
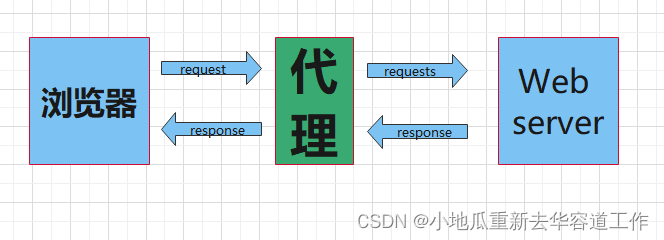
proxies的形式是字典类型
如下:
- proxies = {
- "http": "http://12.34.5679:9527",
- "https": "https://12.34.5679:9527",
- }
使用时在requests.get()函数里设置参数proxies=proxies即可。
如果proxies字典中包含有多个键值对,发送请求时将按照url地址的协议来选择使用相应的代理ip。
八、 发送post请求
requests模块发送post请求和发送get请求的参数完全一致。
语法格式:
response = requests.post(url,data)- 查找data表单,如下以百度翻译网页版为例,
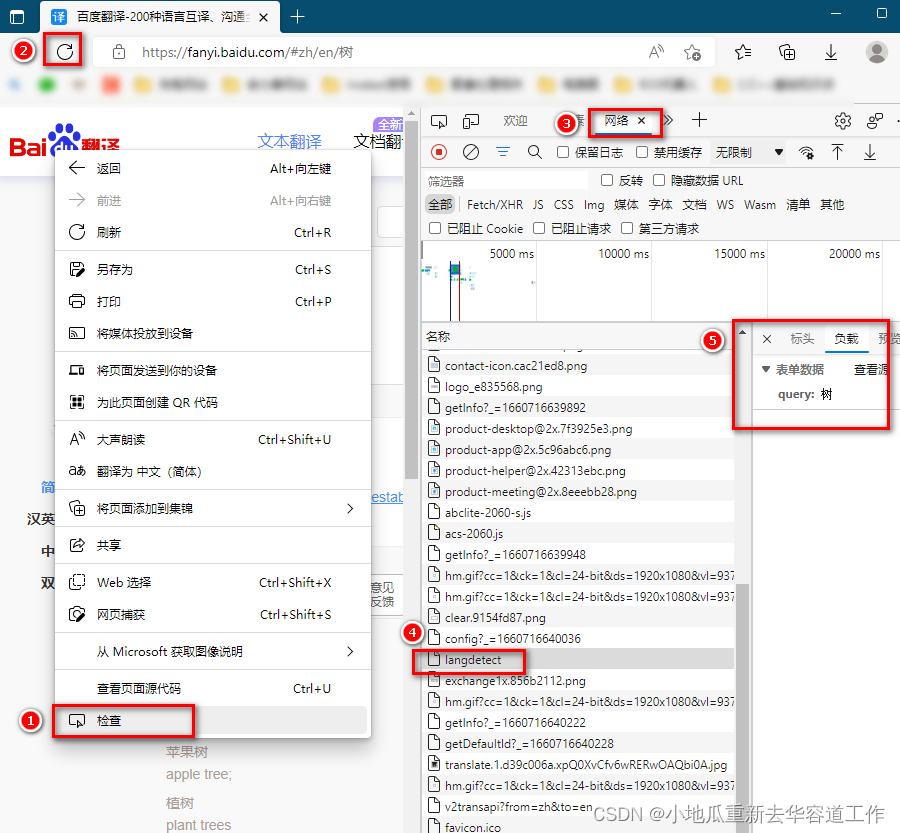
在代码中构造data字典
- import requests
- url = 'https://fanyi.baidu.com/'
- data={
- 'query': '树'
- }
- reponse = requests.post(url,data)
- print(reponse.text)
返回完整的网页源码。
- 相关阅读:
计算机网络 -- HTTP 协议详解
『Material Design』CollapsingToolbarLayout可折叠标题栏
《向量数据库》——向量数据库Milvus Cloud 和Dify比较
Android开发之百度地图定位打卡
16.2 ARP 主机探测技术
第一百四十五回 如何给组件添加阴影
详解uniapp的生命周期 ~ 解惑 实用 ~
从零开始写 Docker(十五)---实现 mydocker run -e 支持环境变量传递
doc与docx文档转html,格式样式不变(包含图片转换)
Java基础
- 原文地址:https://blog.csdn.net/sinat_41752325/article/details/126385248


 https://blog.csdn.net/yuan2019035055/article/details/125469852
https://blog.csdn.net/yuan2019035055/article/details/125469852{kind=link}