-
DN-DETR源码讲解
一:创新点
DN-DETR中的DN指的是denoising,即“去噪”,是一种训练时加快收敛速度的trick。作者将网络拆分为了Denoising Part和Matching Part,只有在训练的时才有Denoising Part,inference时去除。
DN-DETR的主框架和Conditional DETR、DAB DETR完全类似,对它们还不熟悉的小伙伴可以看Conditional DETR和DAB DETR这两篇文章。下面展示一下整体网络图:

二:源码分析
DAB-DETR主模块
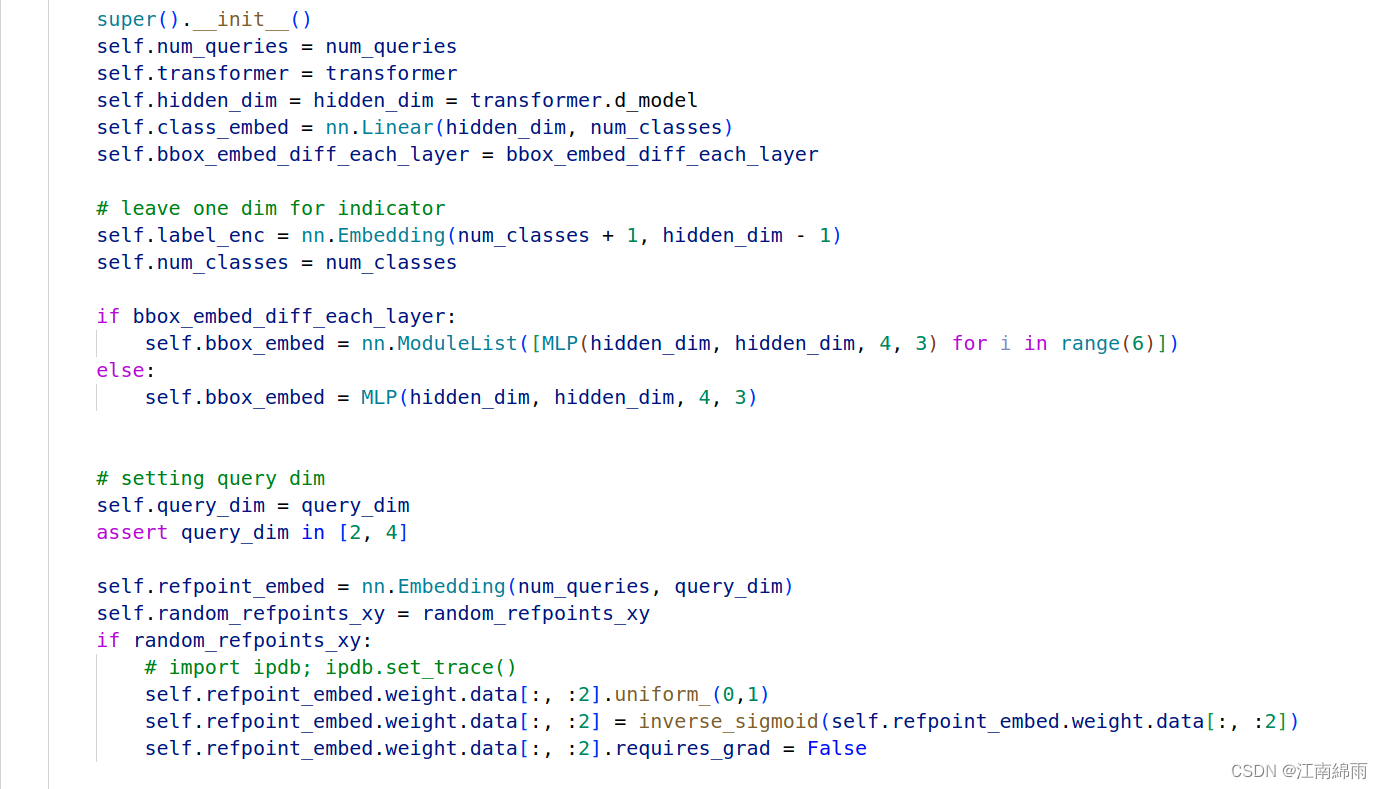
- def init()

- def forward()


init初始化时生成了
[91 + 1, 256]的self.label_enc和[10, 4]的self.refpoint_embed,分别是label词缀表(最后一维其实是初始化tgt)和refpoint的初始化。forward老生常谈,唯一的不同就是多了
prepare_for_dn处理target数据,和dn post process对输出结果作拆分(将[3 2 30 91] 和 [3 2 30 4]分别拆为 [3 2 10 91]、[3 2 10 4]和[3 2 20 91]、[3 2 20 4],前两个作为真正的output和refpoints,后两个作为去噪后的labels和boxes结果扔进mask_dict中,用来计算去噪损失)。最后返回的是[3 2 10 91]、[3 2 10 4]和mask_dict。让我们看一下
prepare_for_dn函数源码:




该函数的功能是由target中真实label和boxes,生成几组group的噪声target,然后拼接在一起。对于label是随机flip,而boxes则是改变center和w、h。得到[2, 20, 256]的input_label_embed和[2, 20, 4]的boxes。注意!最后还添加了[2 10 256]的tgt和[2 10 4]的refpoint_embed。
还有一个重点,就是attn_mask。作者在论文中提出如下见解:
Therefore, our attention mask is to make sure the matching part cannot see the denoising part and the denoising groups cannot see each other as shown in Fig. 4.- 1
- 2
翻译一下就是在decoder时防止泄题,denoising part中各个group之间不能互相看到,且matching part中的query不能看到denoising part中的groups。而denoising part中的groups看到matching part也没事,因为它们需要学习,里面不包含“答案”,
最后输出[2 30 256]的input_query_label,[2 30 4]的input_query_bbox,[30 30]的attn_mask,和包含了大量原始target和索引的字典(其中内容请看源码中的注释,用来最后计算Loss用的)。将它们和src等输入到transformer中,下面看transformer模块:
Transformer
 中规中矩,encoder和decoder中的细节就不讲了,和DAB-DETR一字不差。最后输出[3 2 30 256]的hs和[3 2 30 4]的references。最后我们再看一下Loss的计算细节:
中规中矩,encoder和decoder中的细节就不讲了,和DAB-DETR一字不差。最后输出[3 2 30 256]的hs和[3 2 30 4]的references。最后我们再看一下Loss的计算细节:Loss计算细节
- engine.py

- criterion中的 forward(output, target)


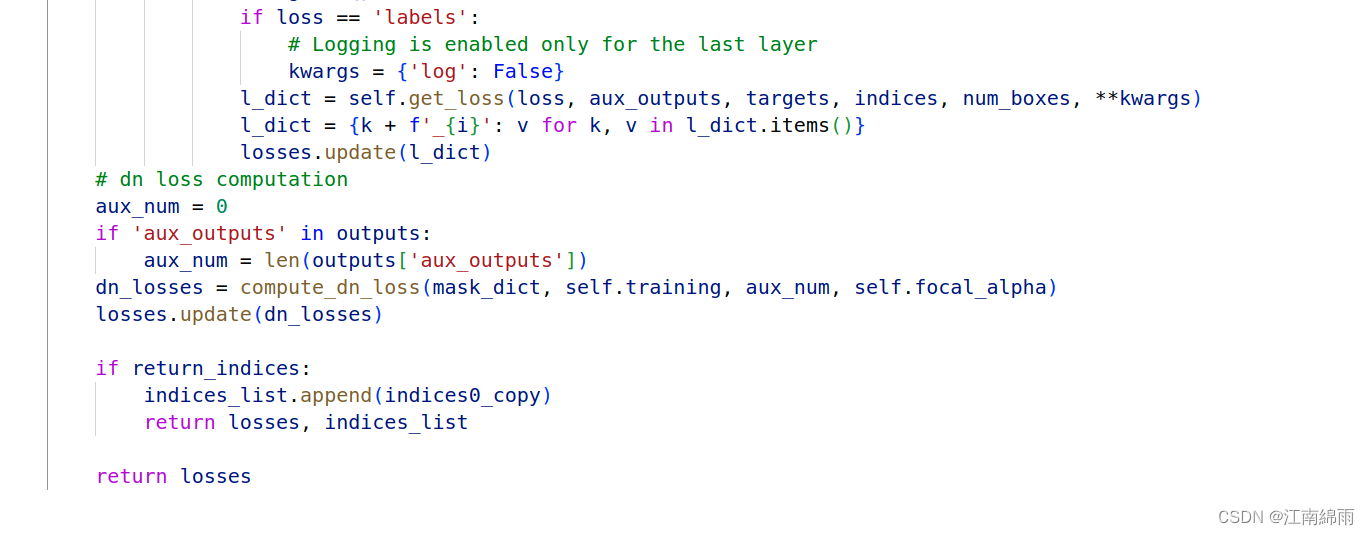
Loss计算和DETR常规计算一样,只多了
dn loss computation,计算去噪损失,下面是dn_losses = compute_dn_loss(mask_dict, self.training, aux_num, self.focal_alpha)实现源码:- compute_dn_loss
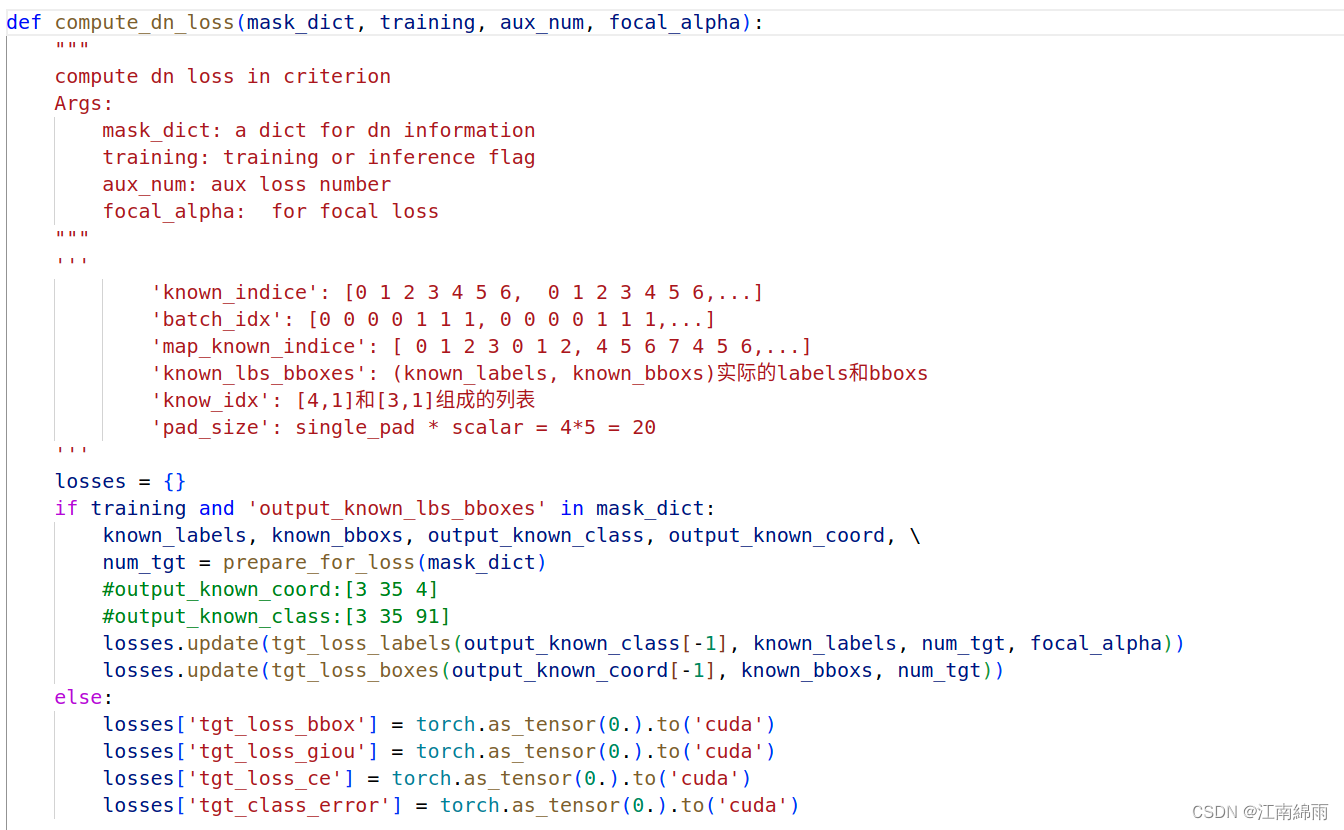

通过
prepare_for_loss对mask_dict进行处理,将[3 2 20 256]的output_known_coord和[3 2 20 4]的output_known_class中多余的zero行去除,提取出group_num✖label_num个真正的去噪target,文中是35(5✖7=35)个,该函数输出是[3 35 4]和[3 35 91]。最后只对最后一维的结果计算去噪Loss,敲重点,这里计算[35 91]的label损失用的是focal函数,实现细节略。
最后展现一下
prepare_for_loss、tgt_loss_labels、tgt_loss_boxes:- prepare_for_loss

- tgt_loss_labels

- tgt_loss_boxes

至此我对DN-DETR源码中全部的流程与细节,进行了深度讲解,希望对大家有所帮助,有不懂的地方或者建议,欢迎大家在下方留言评论。
我是努力在CV泥潭中摸爬滚打的江南咸鱼,我们一起努力,不留遗憾!
-
相关阅读:
战神引擎传奇假设教程
想知道怎么给图片加贴纸?手把手教你给图片加贴纸
接口自动化测试-断言机制哪家强 首推RestAssured 断言
从0到1:CTFer成长之路——死亡 Ping 命令
网络安全(黑客)自学
IPKISS Tutorials ------merge elements(合并对象)
STM32cubeMX配置FreeRTOS-51、USB-U盘读写
【MATLAB教程案例19】优化类算法的应用,如何针对不同问题选择不同的优化类算法
Python的电机控制模拟程序
科赫曲线
- 原文地址:https://blog.csdn.net/weixin_43702653/article/details/126378645