-
深度学习:感知机
感知机常用于二分类问题,找一个超平面将线性可分的数据集进行分类。本文将从单层感知机的原理开始探讨,再到多层感知机原理以及多层感知机的实现。
1、感知机
1.1、感知机定义
感知机(Perceptron)由Frank Roseblatt于1957年提出,是一种广泛使用的线性分类器。感知器可谓是最简单的人工神经网络,只有一个神经元。感知机是对生物神经元的简单数学模拟,有与生物神经元对应的部件,如权重(突触)、偏置(阈值)及激活函数(细胞体),输出为+1或-1。如图(1)所示。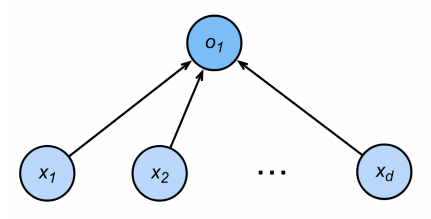
图1:感知机
感知器是一种简单的两类线性分类模型,其分类准则为:
y ^ = s g n ( w T x + b ) . (1) \hat{y}=sgn(w^Tx+b).\tag{1} y^=sgn(wTx+b).(1)
其中sgn函数的定义为:
s g n ( x ) = { 1 i f x > 0 − 1 o t h e r w i s e . (2) sgn(x)=.\tag{2} sgn(x)={1ifx>0−1otherwise.(2){ 1 i f x > 0 − 1 o t h e r w i s e 1.2、损失函数
感知机模型属于二分类线性分类模型,属于判别模型和非概率模型。简单来说,就是找到一个超平面,把线性可分数据集分到超平面两侧。
那么如何定义感知机的损失函数?首先,我们需要明白损失函数就是用来衡量预测值与真实值之间的误差,引入到本文中,那么就是衡量分类错误的数据点与超平面的距离,因为对于分类错误的数据集我们才需要调整
w和b参数,改变超平面的方向来重新分类数据点。因此根据点到直线的距离公式,我们可知:对于点 ( x i , y i ) (x_i,y_i) (xi,yi)到超平面 w x + b = 0 wx+b=0 wx+b=0的距离如下所示。
d = ∣ w x i + b ∣ ∣ ∣ w ∣ ∣ . (3) d=\frac{|wx_i+b|}{||w||}.\tag{3} d=∣∣w∣∣∣wxi+b∣.(3)
(3)中的 ∣ ∣ w ∣ ∣ ||w|| ∣∣w∣∣是 w w w的L2范数。为了方便求导,我们需要把(3)中的绝对值去掉。由于上述距离是表达错误分类数据点到超平面的距离,因此可得:
{ w x i + b < 0 i f y i = 1 w x i + b > 0 i f y i = − 1 . (4).\tag{4} {wxi+b<0ifyi=1wxi+b>0ifyi=−1.(4){ w x i + b < 0 i f y i = 1 w x i + b > 0 i f y i = − 1
因此 ∣ w x i + b ∣ = − y i ( w x i + b ) |wx_i+b|=-y_i(wx_i+b) ∣wxi+b∣=−yi(wxi+b),又因为 1 ∣ ∣ w ∣ ∣ \frac{1}{||w||} ∣∣w∣∣1是一个常数,不影响最终的导数,因此式子(3)可化为:
d = − y i ( w x i + b ) . (5) d=-y_i(wx_i+b).\tag{5} d=−yi(wxi+b).(5)
由(5)可知,可用如下表达式来描述错误分类数据点的损失函数:
l ( w , b ; x , y ) = ∑ x i ∈ M − y i ( w x i + b ) . (6) l(w,b;x,y)=\sum_{x_i\in\,M}-y_i(wx_i+b).\tag{6} l(w,b;x,y)=xi∈M∑−yi(wxi+b).(6)
其中 M M M是包含所有错误分类数据点的集合。1.3、参数更新
由(6)可知,损失函数对于 w w w和 b b b的导数分别为:
∂ l ∂ w = ∑ x i ∈ M − y i x i ∂ l ∂ b = ∑ x i ∈ M − y i . (7) \frac{\partial\,l}{\partial\,w}=\sum_{x_i\in\,M}-y_ix_i \qquad \frac{\partial\,l}{\partial\,b}=\sum_{x_i\in\,M}-y_i.\tag{7} ∂w∂l=xi∈M∑−yixi∂b∂l=xi∈M∑−yi.(7)
因此参数 w w w和 b b b的更新可以用如下式子表达:
w ← w + η y i x i b ← b + η y i . (8) w←w+ηy_ix_i\qquad\,b←b+ηy_i.\tag{8} w←w+ηyixib←b+ηyi.(8)
对于 N N N个数据点,我们可以用下式来作为分类错误的判断条件。
y i ( w x i + b ) ≤ 0 ∀ i ∈ { 1 , ⋯ , 𝑁 } (9) y_i(wx_i+b)≤0\tag{9}\qquad\, ∀i∈\lbrace\,1, ⋯ , 𝑁\rbrace yi(wxi+b)≤0∀i∈{1,⋯,N}(9)
则感知机中参数更新的整个过程可以描述为:
简单描述感知机训练过程:
1、对 w , b w,b w,b初始化
2、按顺序选取数据点 ( x i , y i ) (x_i,y_i) (xi,yi)进行分类
3、如果分类错误则更新 w , b w,b w,b,分类正确则跳过当前数据点
4、参数更新完成之后再转到第2步,直到没有分类错误的数据点或到达最大迭代次数 T T T为止。
(图2)给出了感知器参数学习的更新过程,其中红色实心点为正例,蓝色空心点为负例。黑色箭头表示当前的权重向量,红色虚线箭头表示权重的更新方向。
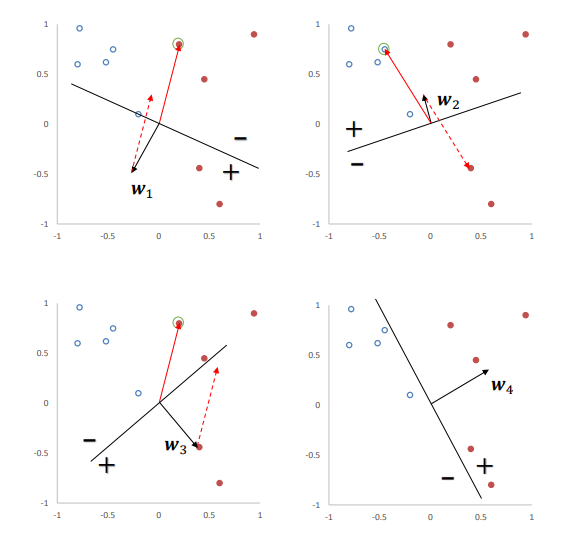
图2:感知机参数更新的过程
1.4、单层感知机的不足
尽管单层感知机可以实现两个类别的分类,但是由于感知机是线性的,因此也只能对线性可分的数据集进行分类。实际情况中,我们需要处理的数据集常常是非线性,例如:如果我们试图预测⼀个⼈是否会偿还贷款。 我们可以认为,在其他条件不变的情况下,收⼊较⾼的申请⼈⽐收⼊较低的申请⼈更有可能偿还贷款。但是, 虽然收入与还款概率存在单调性,但它们不是线性相关的。收⼊从0增加到5万,可能⽐从100万增加到105万带来更⼤的还款可能性。
因为单层感知机只能产生线性分割面,因此无法拟合XOR函数。
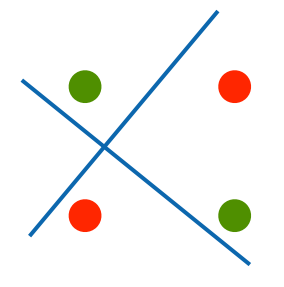
图3:XOR函数
由(图3)可以看出,无法我们如何画分割面,始终无法把两种数据集分开。
2、多层感知机
在1.4节所知:单层感知机无法拟合非线性的函数,那么是否可以多加几层感知机来拟合非线性函数?
答案是肯定的。如下图所示,我们先使用蓝色和黄色标识的感知机分别对数据集分类,然后再将两个感知机计算的结果作为下一层感知机的输入,最后由感知机处理后输出结果。
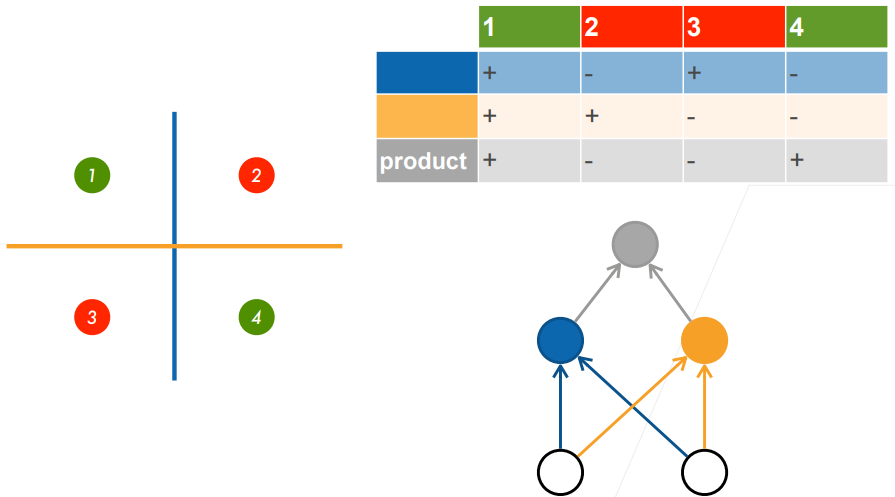
图4:多层感知机拟合XOR函数
由上图可知,多层感知机可以实现将非线性可分的数据集进行划分。
2.1、多层感知机的定义
多层感知机(MLP,Multilayer Perceptron)也叫人工神经网络(ANN,Artificial Neural Network),除了输入输出层,它中间可以有多个隐藏层,最简单的MLP只含一个隐藏层,即三层的结构,如下图:
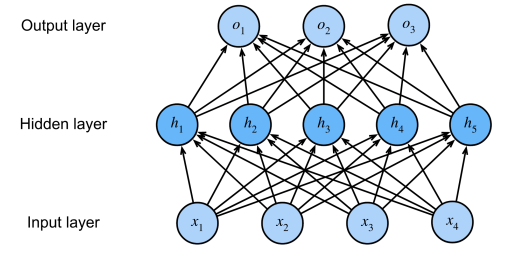
图5:多层感知机
其中,隐藏层的层数以及每一层感知机的数量都是超参数。
对于单分类的多层感知机,其公式形式如下:
- 输入 x ∈ R n x\in\R^n x∈Rn
- 隐藏层h的参数 W 1 ∈ R m × n , b 1 ∈ R m W_1\in\R^{m×n},b_1\in\R^m W1∈Rm×n,b1∈Rm
- 输出层o的参数 W 2 ∈ R 1 × m , b 2 ∈ R W_2\in\R^{1×m},b_2\in\R W2∈R1×m,b2∈R
h = σ ( W 1 x + b 1 ) o = W 2 T h + b 2 . (10) h=\sigma(W_1x+b_1)\\ o=W_2^Th+b_2.\tag{10} h=σ(W1x+b1)o=W2Th+b2.(10)
对于多分类的多层感知机,其公式形式如下:
- 输入 x ∈ R n x\in\R^{n} x∈Rn
- 隐藏层h的参数 W 1 ∈ R m × n , b 1 ∈ R m W_1\in\R^{m×n},b_1\in\R^m W1∈Rm×n,b1∈Rm
- 输出层o的参数 W 2 ∈ R k × m , b k ∈ R W_2\in\R^{k×m},b_k\in\R W2∈Rk×m,bk∈R
h = σ ( W 1 x + b 1 ) o = W 2 T h + b 2 y = s o f t m a x ( o ) . (11) h=\sigma(W_1x+b_1)\\ o=W_2^Th+b_2\\ y=softmax(o).\tag{11} h=σ(W1x+b1)o=W2Th+b2y=softmax(o).(11)
2.2、感知机中的激活函数
(10)(11)中 σ ( x ) \sigma(x) σ(x)为对单个元素的激活函数。为什么需要对每个元素使用激活函数?
现在,我们假设没有使用 σ ( x ) \sigma(x) σ(x)激活函数,那么式子(11)就需要用如下式子表达:
h = W 1 x + b 1 o = W 2 T h + b 2 y = s o f t m a x ( o ) . (12) h=W_1x+b_1\\ o=W_2^Th+b_2\\ y=softmax(o).\tag{12} h=W1x+b1o=W2Th+b2y=softmax(o).(12)
随后我们将(12)展开:
O = ( W 1 x + b 1 ) W 2 T + b 2 = W 1 W 2 T x + W 2 T b 1 + b 2 = x W + b . (13) O=(W_1x+b_1)W_2^T+b_2=W_1W_2^Tx+W_2^Tb_1+b_2=xW+b.\tag{13} O=(W1x+b1)W2T+b2=W1W2Tx+W2Tb1+b2=xW+b.(13)
可以看到,尽管我们加入多层感知机,但是最后实际上也只是单层感知机的效果。事实上,如果不加入激活函数,那无论线性嵌套多少隐藏层,都是线性的。为了解决上述问题,因此在多层感知机中必须使用激活函数。激活函数不是本文的重点,不再赘述。
2.3、多隐藏层的感知机
在实际拟合函数时,一层隐藏层的模型可能很难拟合复杂的函数,因此便引入了多隐藏层的感知机模型。

图6:多隐藏层的感知机模型
其公式形式如下:
h 1 = σ ( W 1 x + b 1 ) h 2 = σ ( W 2 h 1 + b 2 ) h 3 = σ ( W 3 h 2 + b 3 ) o = W 4 h 3 + b 4 . (14) h_1=\sigma(W_1x+b_1)\\ h_2=\sigma(W_2h_1+b_2)\\ h_3=\sigma(W_3h_2+b_3)\\ o=W_4h_3+b_4.\tag{14} h1=σ(W1x+b1)h2=σ(W2h1+b2)h3=σ(W3h2+b3)o=W4h3+b4.(14)3、从零实现多层感知机
在本节,我们将构造一个多层感知机来预测之前
softmax回归中的Fashion-MNIST数据集。3.1、读取数据集
首先,我们先使用之前定义的
load_data_fashion_mnist函数来读取数据集。import torch from torch import nn from d2l import torch as d2l batch_size = 256 train_iter, test_iter = d2l.load_data_fashion_mnist(batch_size)- 1
- 2
- 3
- 4
- 5
- 6
3.2、初始化参数
回想一下,Fashion-MNIST中的每个图像由 28×28=784个灰度像素值组成。 所有图像共分为10个类别。 忽略像素之间的空间结构, 我们可以将每个图像视为具有784个输入特征 和10个类的简单分类数据集。 首先,我们将实现一个具有单隐藏层的多层感知机,它包含256个隐藏单元。 注意,我们可以将这两个变量都视为超参数。 通常,我们选择2的若干次幂作为感知层所包含的感知机个数。 因为内存在硬件中的分配和寻址方式,因此这样做往往可以在计算上更高效。
我们用几个张量来表示我们的参数。 注意,对于每一层我们都要记录一个权重矩阵和一个偏置向量。 跟以前一样,我们要为损失关于这些参数的梯度分配内存。
num_inputs, num_outputs, num_hiddens = 784, 10, 256 W1 = nn.Parameter(torch.randn( num_inputs, num_hiddens, requires_grad=True) * 0.01) b1 = nn.Parameter(torch.zeros(num_hiddens, requires_grad=True)) W2 = nn.Parameter(torch.randn( num_hiddens, num_outputs, requires_grad=True) * 0.01) b2 = nn.Parameter(torch.zeros(num_outputs, requires_grad=True)) params = [W1, b1, W2, b2]- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
3.3、激活函数
在这里,我们选择使用Relu激活函数。
def relu(X): a = torch.zeros_like(X) return torch.max(X, a)- 1
- 2
- 3
3.4、定义模型
因为我们忽略了空间结构,所以我们使用reshape将每个⼆维图像转换为⼀个长度为num_inputs的向量。 只需几行代码就可以实现我们的模型。
def net(X): X = X.reshape((-1, num_inputs)) H = relu(X@W1 + b1) # 这里“@”代表矩阵乘法 return (H@W2 + b2)- 1
- 2
- 3
- 4
3.5、损失函数
我们直接使用内置的交叉熵损失函数。
loss = nn.CrossEntropyLoss(reduction='none')- 1
上面的代码实际上等价于我们的自定义函数
cross_entropy。注意:如果使用我们的自定义函数,那么net中应该return softmax(H@W2 + b2)),因为在CrossEntropyLoss中已经内嵌softmax激活函数,因此不需要我们再关心激活函数。def cross_entropy(y_hat, y): return -torch.log(y_hat[range(len(y_hat)), y]) loss = cross_entropy- 1
- 2
- 3
- 4
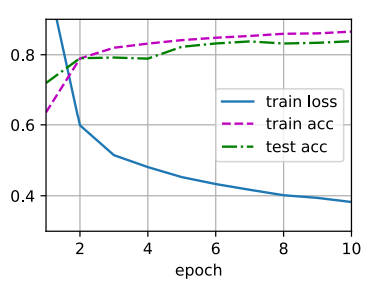
3.6、训练模型
多层感知机的训练过程与softmax回归的训练过程完全相同。可以直接调用d2l包的train_ch3函 数(参⻅深度学习:softmax回归 ),将迭代周期数设置为10,并将学习率设置为0.1.
num_epochs, lr = 10, 0.1 updater = torch.optim.SGD(params, lr=lr) d2l.train_ch3(net, train_iter, test_iter, loss, num_epochs, updater)- 1
- 2
- 3
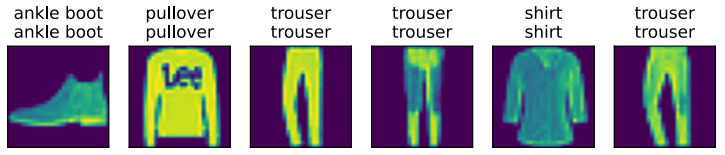
3.7、预测
使用我们训练好的模型来预测一下图片类别。
d2l.predict_ch3(net, test_iter)- 1
4、总结
本文介绍了感知机的原理以及无法拟合非线性函数的原因,随后我们提出多层感知机模型,与单层感知机相比,多层感知机可以通过增加隐藏层数量和感知机数量来拟合复杂的非线性函数。在最后,我们还从零开始实现了一个多层感知机模型。
5、参考资料
1、动手学深度学习 Release2.0.0-beta0
2、神经网络与深度学习_邱锡鹏
-
相关阅读:
zip压缩包密码怎么解开,zip压缩包权限限制怎么解除?
MFC知识点
BigDecimal保留两位小数失败问题
【C++】:类和对象(1)
FireMonkey 做界面的一个小技巧
应用聚类算法,预测中国足球在亚洲处于什么水平
【图像融合】差异的高斯:一种简单有效的通用图像融合方法[用于融合红外和可见光图像、多焦点图像、多模态医学图像和多曝光图像](Matlab代码实现)
R语言ggplot2可视化斜率图、对比同一数据对象前后(before、after)两个状态的差异(Slope Chart)
什么是js中的作用域
C#实现观察者模式
- 原文地址:https://blog.csdn.net/qq_35149975/article/details/126382951